






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心分享一篇理想汽车最新智能ISP系统相关工作:RMFA-Net,助力提升端到端输入质量。如果您有相关工作需要分享,请在文末联系我们!
也欢迎添加小助理微信AIDriver004,加入我们的技术交流群
编辑 | 自动驾驶之心
文章:RMFA-Net: A Neural ISP for Real RAW to RGB Image Reconstruction
链接:https://arxiv.org/abs/2406.11469

问题引出
图像信号处理器(ISP)是一种专门设计的系统,用于从CMOS传感器捕获的原始数据重建RGB图像。现有ISP系统是基于传统算法的,依赖于对传感器的深入理解和复杂的调试,这限制了它们在自动驾驶和机器人等领域的适用性。虽然在基于人眼视觉的标准下,传统算法取得了较好的效果,但在视觉感知系统中无法很好适配。基于深度学习的ISP算法作为一种具有显著潜力和多功能性的方法出现。近年来,越来越多的人对开发基于学习的算法以设计高效且高性能的ISP算法产生了兴趣,这些算法可以针对特定领域的需求量身定制。

然而,现有算法并未充分考虑raw数据的特定特性,如黑电平和CFA,这可能会在处理不当时对纹理和颜色产生负面影响。此外,raw数据中的不均匀曝光也未被仔细考虑,导致对比度和亮度信息无法准确恢复。现有算法在数据处理的时候,破坏了原始数据中的高频信息,导致高频细节难以回复,同时会带来模糊等问题。本文介绍了RMFA-Net以解决这些问题。我们进行显示黑电平校正以减轻暗场景中的颜色偏移。为了保留高频信息并防止错位,我们提出了一种新的三通道分离模式。为了解决不均匀曝光的问题,我们个基于Retinex理论的设计了色调映射模块,从而最终获得更好的图像效果。
框架介绍
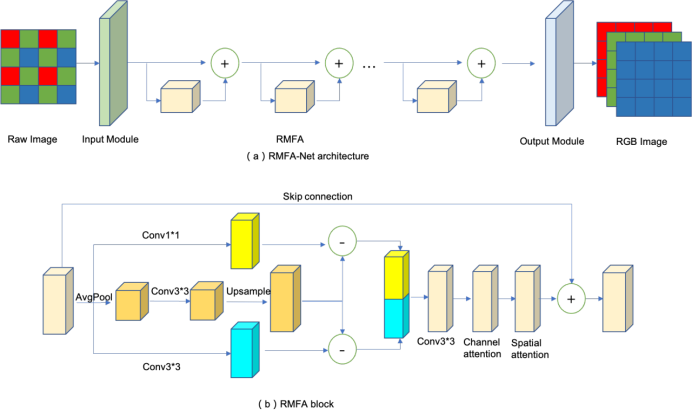
图1(a)提供了本文所提出的深度学习架构的示意图。该网络分为三个主要部分:输入模块,RMFA模块栈,以及输出模块。输入模块接受大小为256 × 256 × 3的图像作为输入,并将深度从3扩展到统一的宽度。在这一部分中,使用了两个卷积层,卷积核大小为3 × 3。需要注意的是,tanh函数被用来将结果映射到区间(−1, 1) 。第二部分由多个RMFA模块组成。第三部分是输出模块,其中使用一个卷积层,紧接着是sigmoid激活函数来生成输出。
关键组件介绍
RMFA模块
RMFA模块是我们模型的基本构建块,如图1(b)所示。其包含几个子模块:
高频信息提取分支:这个子分支专注于从输入数据中提取高频信息。它利用大小为1 × 1的卷积核来捕捉图像中的细节。通过使用较小的卷积核,网络能够有效地捕捉高频纹理并保留重建图像中的复杂细节。
低频分支:这个子分支负责捕获输入数据中的低频信息。它利用大小为3×3的较大卷积核来捕捉更广泛的特征并平滑图像。较大的卷积核允许网络捕获低频纹理,例如整体色彩和色调变化,并确保重建的图像保持视觉上的美观
色调映射模块:模块纹理模块和色调映射模块的输出首先被连接在一起。随后,使用一个卷积层将特征图的数量映射到原始深度宽度。
注意力模块。RMFA模块的最后添加了channel attention和spatial attention模块。同时添加了skip connection连接。
作为一个多功能的构建块,RMFA模块可以无缝地集成到各种架构中,增强我们模型的灵活性和适应性
3通道模式
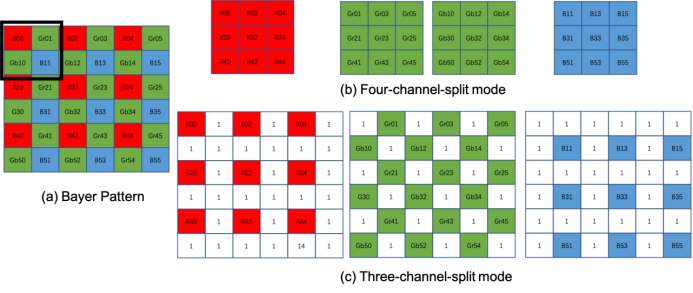
如图2所示,在之前的工作中,通常的做法是将4通道模式,在这种模式下,绿色通道进一步分为Gr和Gb通道。这种额外的分离相当于对绿色通道进行下采样,这会破坏raw数据中的高频信息。
此外,4通道模式会引起像素错位。如图2(a)中的黑框所示,四个通道中相同位置的像素实际上对应于原始raw数据中的2×2邻域。这种错位可能导致模糊,影响图像质量
本文设计了一种新方法,如图2(c)所示。我们将Bayer raw数据分为三个通道(R、G、B),每个通道保留raw数据的大小。对于未采样的像素,我们用1填充。因此,G通道的采样率保持不变,尽可能保留高频纹理信息。我们相信这种方法将更有助于网络准确地重建高频信息。
量化指标
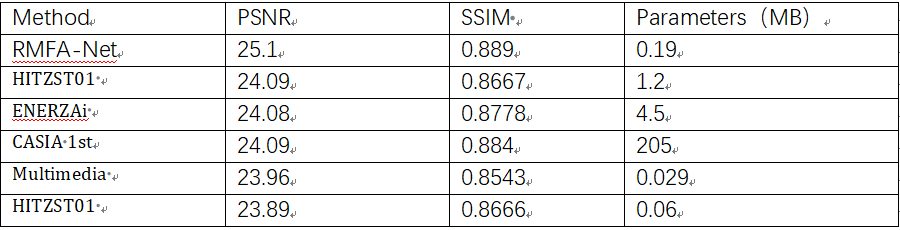
我们在公开数据集上测试我们的效果,PSNR和SSIM两个指标都超越了sota结果+1db。同时我们网络参数也控制在较小的范围内。如表1所示
总结
在本文中,我们提出了名为RMFA-Net的Neural ISP网络,这是一种用于RAW到RGB图像重建的新型深度学习模型。我们在公开数据集上证明了我们算法的有效性。其在PSNR和SSIM等图像指标超过了sota结果1个Db。RMFA-Net在重建亮度、颜色、纹理和整体图像细节方面有着更为出色的表现。
此外,我们还提供了一些额外的细节和结果,包括数据处理细节、网络结构细节、各处理模块作用对比分析等。这些额外信息进一步证明了我们方法的有效性和实用性。我们希望我们的工作能够启发未来关于Neural ISP系统的研究
引用
【1】Ignatov, A., Van Gool, L., Timofte, R.: Replacing mobile camera isp with a single deep learning model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 536–537 (2020)
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 7170
7170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









