






作者 | 派派星 编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
论文地址:https://arxiv.org/pdf/2410.12628
论文源码:https://github.com/opendatalab/DocLayout-YOLO
项目主页:https://huggingface.co/spaces/opendatalab/DocLayout-YOLO

导读
TL;DR: 本文提出了一个名为DocLayout-YOLO的新方法,旨在通过多样化的合成数据和全局到局部的自适应感知来增强文档布局分析。
在当今数字化的世界里,文档布局分析(DLA)是理解和处理文档的关键步骤。想象一下,你手中有一堆杂乱无章的文件,DocLayout-YOLO就像一个超级助手,能够快速帮你识别出文件中的文本、标题、表格等不同区域。这项技术对于提高文档处理的自动化和准确性至关重要。
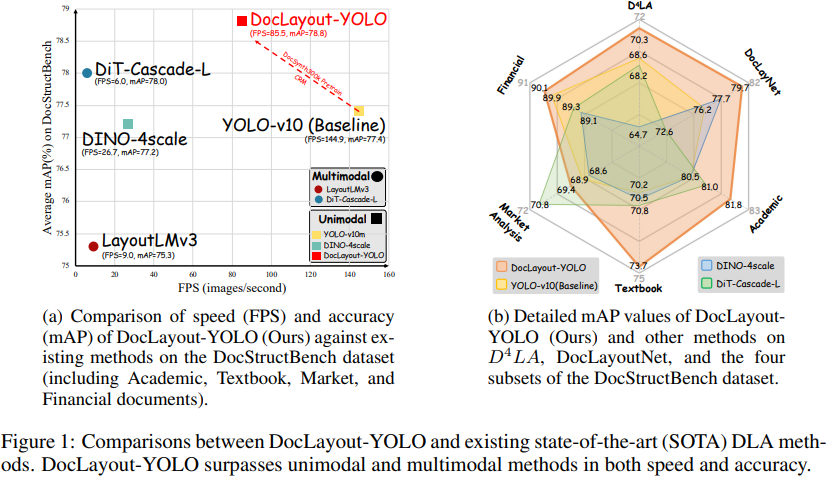
在以往的文档解析领域,研究者们一直在速度和准确性之间寻找平衡。其中:
多模态方法通过结合视觉和文本信息虽然准确度高,但处理速度慢;
而单模态方法仅依赖视觉特征,虽然处理速度快,但准确性较低。
DocLayout-YOLO的创新之处在于,它试图在保持速度优势的同时提高准确性。
那么,DocLayout-YOLO 是如何做到的呢?文章中披露了两大法宝:Mesh-candidate BestFit算法及全局到局部可控感受野模块(GL-CRM)。
DocLayout-YOLO
DocLayout-YOLO的首个创新是Mesh-candidate BestFit算法,它将文档合成问题视为一个二维装箱问题,通过这种方式生成了一个大规模、多样化的合成数据集DocSynth-300K。这个数据集的预训练显著提高了在各种文档类型上的微调性能。
第二个创新点则是全局到局部可控感受野模块(GL-CRM),这个模块能够更好地处理文档元素的多尺度变化。从全局的页面尺度到局部的语义信息,GL-CRM使得模型能够有效检测不同尺度的目标。
DocSynth-300K 合成数据集的生成方法
首先,我们先来看下 DocSynth-300K 是如何合成的。如上所述,这是一个由 Mesh-candidate BestFit 的算法生成的,通过将文档合成问题视为一个二维装箱问题,利用丰富的基础组件(文本、图像、表格)来生成一个大规模、多样化的预训练语料库。
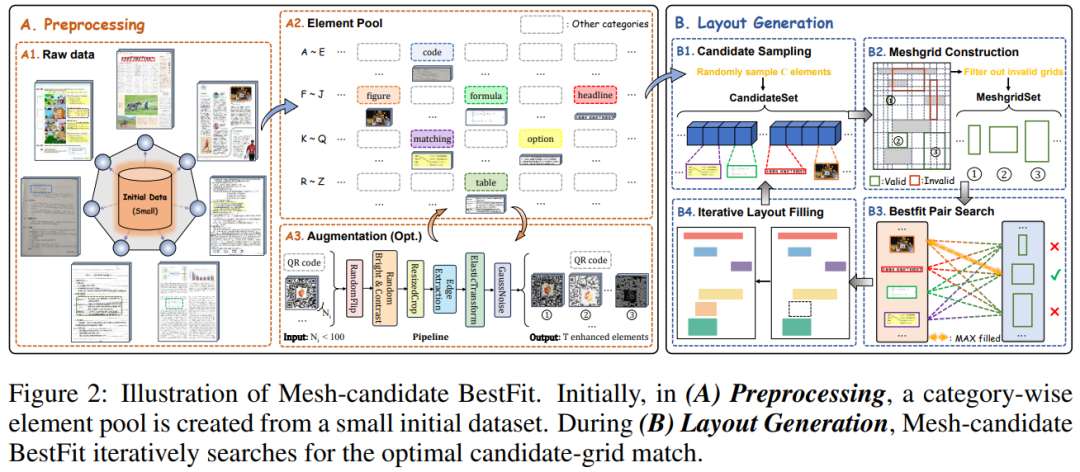
如上图所示,算法通过以下步骤来生成数据集:
预处理:从一个小的初始数据集中提取和构建一个按细粒度类别分类的元素池。为了保持同一类别内元素的多样性,设计了一个增强管道来扩大数量少于100个元素的稀有类别的数据池。
布局生成:在布局生成阶段,算法迭代地执行最佳匹配搜索,寻找候选元素和所有网格(bins)的最佳配对。找到最佳匹配对后,将候选元素插入文档中,并继续迭代搜索,直到元素数量达到阈值N(经验设置为15)。
候选采样:对于每个空白页面,基于元素大小从元素池中进行分层抽样,作为候选集。然后从候选集中随机抽取一个元素,并将其放置在页面上的某个位置。
网格构建:基于布局构建网格,并过滤掉与已插入元素重叠的无效网格。只有剩余的网格才能参与后续步骤中与候选元素的匹配。
最佳匹配对搜索:对于每个候选元素,遍历所有满足大小要求的网格,并寻找具有最大填充率的网格-候选元素对。然后从候选集中移除最优候选元素,并更新布局。
迭代布局填充:重复步骤2至3,直到没有有效的网格-候选元素对满足大小要求。最终,对所有填充的元素分别应用随机中心缩放。
最终的合成示例可以参考下图:

GL-CRM 全局到局部可控感受野模块的工作原理
GL-CRM(Global-to-Local Controllable Receptive Module)是为了更好地处理文档中不同元素的多尺度变化而设计的。它包括两个主要组件:可控感受野模块(CRM)和全局到局部设计(GL)。CRM灵活地提取和整合具有多个尺度和粒度的特征,而GL架构具有从全局上下文(整页规模)到子块区域(中等规模)再到局部语义信息的层次感知过程。
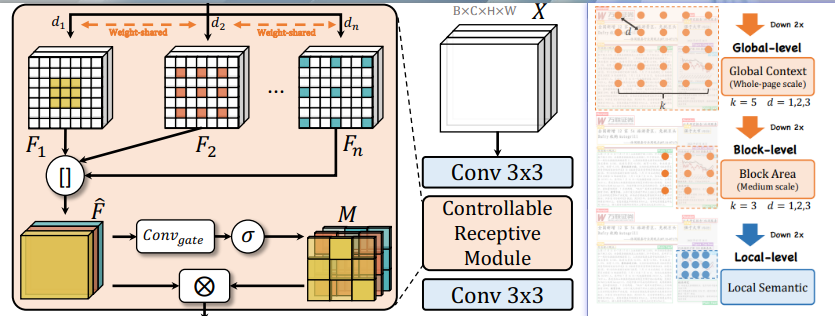
CRM:对于每一层的特征X,首先使用权重共享的卷积层w和核大小k提取特征。通过使用一组不同的扩张率d=[d1, d2, ..., dn]来捕获不同粒度的特征。然后,将这些特征融合,并允许网络自主学习如何融合不同的特征组件。
GL设计:全局级别使用较大的核和扩张率来捕获整页元素的更多纹理细节和保存局部模式。在中间阶段,特征图被下采样,纹理特征减少,此时使用较小的核和扩张率来感知中等规模的元素,如文档子块。在深层阶段,语义信息占主导地位,使用基本的瓶颈作为轻量级模块,专注于局部语义信息。
优势
DocLayout-YOLO在文档布局分析中相比其他方法具有以下优势:
速度与准确性的平衡:DocLayout-YOLO在保持速度优势的同时提高了准确性,这得益于其在预训练和模型设计中针对文档特定优化的增强。它匹配了单模态方法YOLOv10的速度,并在准确性上超越了所有现有方法,包括单模态和多模态方法。
多样化的合成数据集:通过Mesh-candidate BestFit算法生成的DocSynth-300K数据集,提供了更多样化和高质量的合成文档数据,这有助于模型在各种文档类型上进行更好的泛化。
全局到局部的感知能力:GL-CRM模块使得DocLayout-YOLO能够有效检测不同尺度的目标,从而提高了检测的准确性。
实时布局分析:DocLayout-YOLO在多样化的下游数据集上实现了高达85.5帧每秒(FPS)的推理速度,使得在多种文档上进行实时布局分析成为可能。
实验
论文中使用了两大公共数据集 D4LA 和 DocLayNet,并引入了一个复杂且具有挑战性的基准测试集DocStructBench,包含学术、教材、市场分析和财务四个类别的文档,用于验证不同文档类型上的性能。其中,精度指标采用 COCO 风格的 mAP,速度指标为每秒处理的图片数(FPS)。
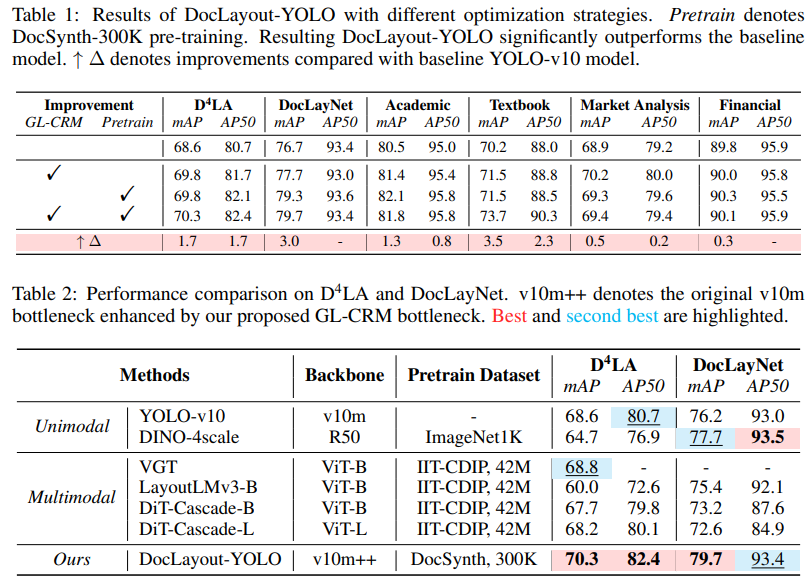
表1 显示了 DocSynth-300K 预训练和 GL-CRM 模块对 D4LA、DocLayNet、以及 DocStructBench 数据集的精度提升。实验表明:
在没有预训练和 GL-CRM 模块的情况下,模型表现较差(如在 D4LA 上 mAP 为 68.6)。
当同时启用 GL-CRM 和 DocSynth-300K 预训练时,mAP 提升至 70.3,表明两者的结合能带来最大的性能改进。
表2 主要是 D4LA 和 DocLayNet 上的性能对比
DocLayout-YOLO 与其他主流单模态和多模态方法进行对比。在 D4LA 数据集上,DocLayout-YOLO 达到 70.3 mAP,超越了多模态模型 VGT 的 68.8 和 DiT-Cascade-B 的 67.7。
在 DocLayNet 上,DocLayout-YOLO 的 mAP 为 79.7,也优于 DINO-4scale(77.7)和 DiT-Cascade-B(73.2)。
结果表明 DocLayout-YOLO 无论在单模态还是多模态方法中,都表现最佳。
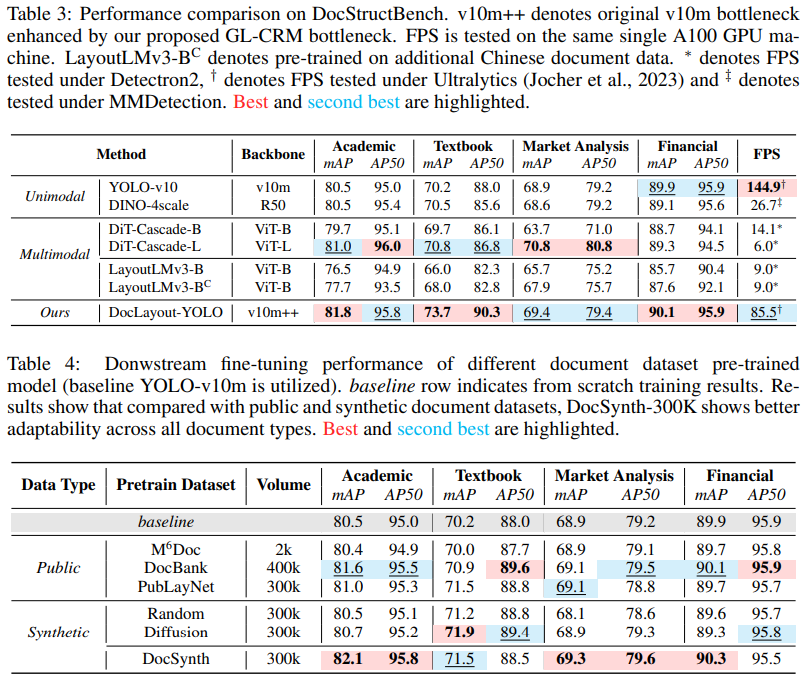
表3:DocStructBench 数据集的性能对比
在 DocStructBench 的四个子数据集(学术、教材、市场分析、财务)上,DocLayout-YOLO 在三个子数据集上表现最佳(如学术:mAP 81.8,财务:mAP 90.1),仅在市场分析文档中略逊于 DiT-Cascade-L。
DocLayout-YOLO 的推理速度(85.5 FPS)远超 DINO-4scale 和 DiT-Cascade-L。
表4:不同预训练数据集的下游微调性能
DocSynth-300K 预训练模型在所有文档类型上表现最好,超越了公共数据集 PubLayNet 和 DocBank。例如,DocSynth-300K 在财务文档上 mAP 为 90.3,而 PubLayNet 为 89.7。
这表明 DocSynth-300K 具有更强的通用性,适用于多种下游任务。

通过在下游数据集上的广泛实验,DocLayout-YOLO 的确无论在速度和准确性上都表现出色,其平均精度均值(mAP)和每秒帧数(FPS)的表现都超越了现有的方法。
应用
X-AnyLabeling 是一款基于AI推理引擎和丰富功能特性于一体的强大辅助标注工具,其专注于实际应用,致力于为图像数据工程师提供工业级的一站式解决方案,可自动快速进行各种复杂任务的标定。
作为一款与时俱进的AI标注工具,X-AnyLabeling 最新版本已无缝集成了DocLayout-YOLO模型,提供了更高精度和实时性能的文档布局分析解决方案。无论是复杂的学术文档、市场报告还是财务报表都能轻松胜任,帮助您加速数据标注流程,提高模型的精度和效率。🚀
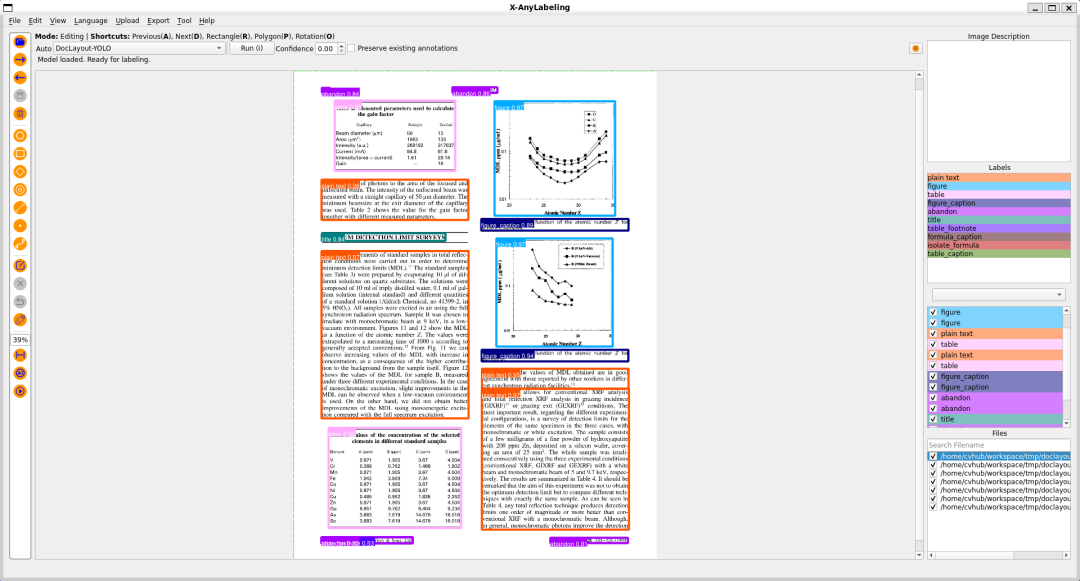
赶紧体验吧!对自定义数据集进行标注,构建并优化属于您的自定义AI模型,提升文档解析能力!
源码地址:https://github.com/CVHub520/X-AnyLabeling
安装指南:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/get_started.md
使用教程:https://github.com/CVHub520/X-AnyLabeling/blob/main/examples/optical_character_recognition/document_layout_analysis/README.md
总结
总的来说,DocLayout-YOLO 不仅在速度上与单模态方法YOLOv10相匹配,而且在准确性上超越了所有现有方法,包括单模态和多模态方法。这表明DocLayout-YOLO在文档布局分析领域具有重要的应用潜力。
最后,值得称赞的是,这项工作不仅在技术上取得了突破,作者们还提供了代码、数据和模型的开源链接,为文档布局分析领域的研究和实践提供了宝贵的资源,这使得研究者和开发者能够进一步探索和应用DocLayout-YOLO。
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 320
320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









