






作者 | Weijian Sun 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/717288142
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
这篇博客文章旨在介绍将深度学习应用于自动驾驶的规划任务(主要讨论motion planning)以及业务落地过程中面临到的实际问题。我将简单介绍一下在推动DLP(deep learning planning)工程化落地时参考过的一些文献,以及已经被笔者验证过可行性的相关方案,给大家提供一些解决问题的思路。希望能够抛砖引玉,对DLP领域的工程师们有所帮助。
原文:
medium.com/@weijian.suen/combat-the-limitations-of-imitation-learning-in-dlp-deep-learning-planning-5ea0b5f890cb
随着自动驾驶技术的迭代,上游的感知与预测任务已逐渐被数据驱动的模型方案所取代。但与感知和预测任务相比,运动规划最具挑战性的方面在于对于闭环测试的必要性依赖,这一过程通过MDP(Markov Decision Process)将规划轨迹持续迭代的应用到后续步骤的规划闭环中。这个迭代循环引入了下游控制器的响应以及来自现实世界的扰动反馈,从而评估规划系统的自校正能力以及从不利情况中恢复的能力。相比之下,感知与预测任务使用的开环测试方式仅涉及对当前以及后续步骤的预测,而不将反馈纳入下一个状态。早期学术界有不少端到端的工作直接将模仿学习应用到运动规划的问题上,并进行了开环评估。但其有效性受到了广泛质疑[1,2],因为大量工作表明在开环测试中表现良好的规划模型在闭环测试中不一定表现良好[1,3,4](往往会频繁偏离导航路径或与其他障碍物或道路边界发生碰撞)。
在讨论解决方案之前,我将介绍一下模仿学习的局限性,这些局限性在学术界早有定论,也正是这些局限性导致模仿学习的方法在应用于运动规划任务时表现不佳。
目录
模仿学习的问题与局限性
1. 分布漂移 (distribution/covariate shift)
2. 因果混淆与学习捷径(Causal Confusion and Learning Shortcuts)
3. 环境自洽(Scene Compliance/Respects Driving Constraints)
解决问题的方案
1. 在模仿学习的框架内
1.1 DAgger
1.2 CCIL
1.3 在模仿中应用随机失活(Dropout - Behavior Clone)
1.4 引入扰动的数据增广(Perturbation-based Augmentations)
1.5 碰撞相关的损失函数(Auxiliary Loss for Collision Avoidance)
1.6 在行为模仿中引入目标先验证(Goal-conditioned Behavioral Cloning)
1.7 混合高斯(Mixture of Gaussians)
1.8 隐变量模型(Latent Variable Models)
2. 超越简单的行为模仿
2.1 强化学习(Reinforcement Learning)
2.2 逆强化学习(Inverse Reinforcement Learning)
2.3 生成对抗式模仿学习(Generative Adversarial Imitation Learning)模仿学习的局限性
1. 分布漂移 (Distribution/Covariate shift)
当简单的将监督学习应用于MDP(马尔可夫决策过程)时,会出现分布偏移(distribution shift)[5,6,7],因为在MDP中最后一步的动作可能会影响下一个状态的观测值。模仿学习假设训练和测试数据是独立的,并且分布相同(i,i,d)。这在闭环的运动规划任务中是不成立的,因为学习到的策略会影响未来的输入(state)。早期就有相关工作[5,6]表明,这一过程会导致复合误差(compounding errors)和遗憾界限(regret bound),在任务的时间范围内呈二次增长。
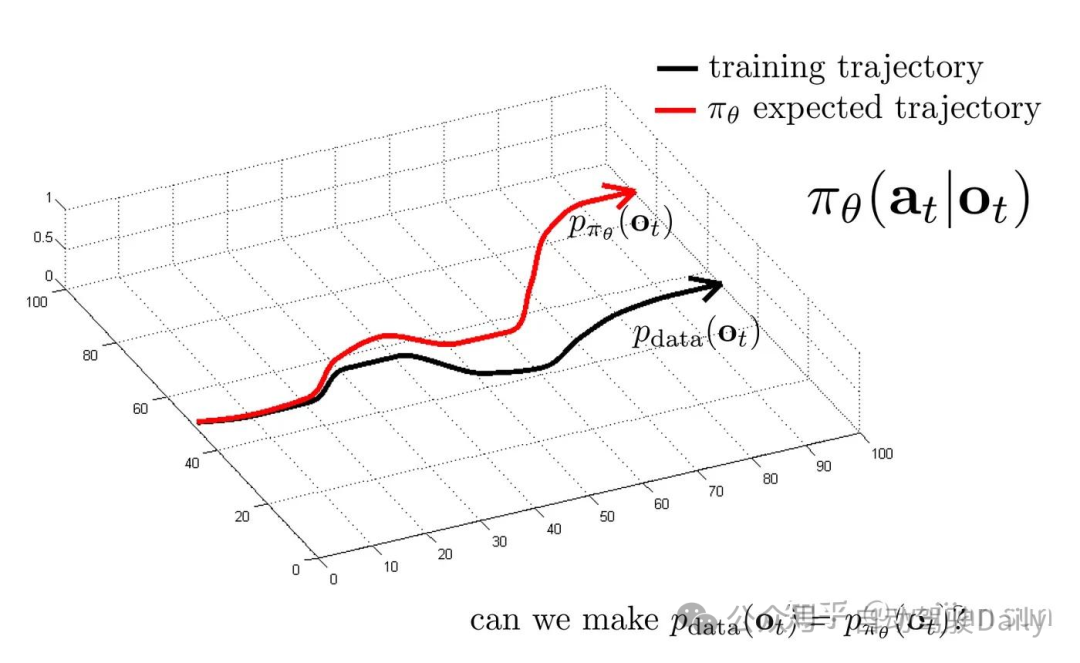
复合误差(compounding errors)[5,6]的定义:由于策略学习本质上处理多步骤过程,而简单的监督学习方法是学习对单个状态的响应,因此事件开始时的一个小分歧可能会产生复合效应,使我们的系统进入它从未观察到的状态,由于这类状态和数据在训练样本中不存在,因此模型也不知道如何修正回来。这解释了为何通过模仿学习训练的模型应用到闭环规划时自车一旦偏离目标路径往往会越偏越远(也就是你们所说的“一进入闭环ego就跑飞了”)。
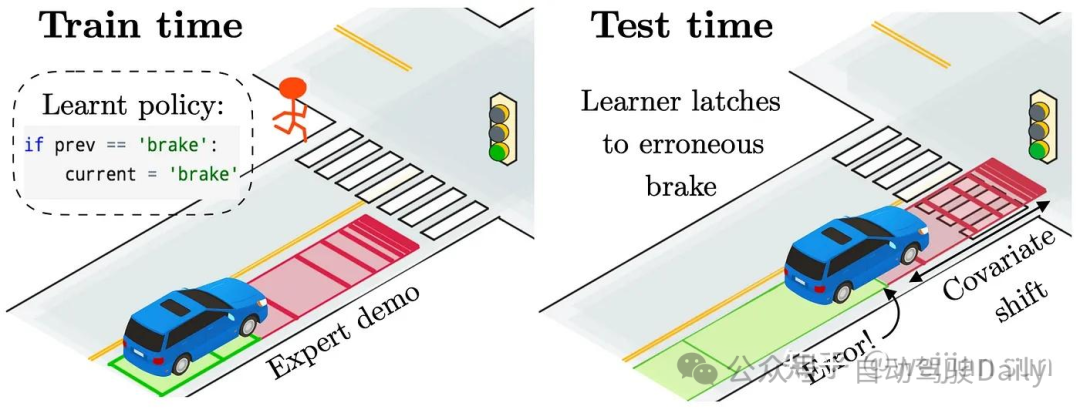
上图[7]说明了自动驾驶中反馈驱动下导致分布漂移的一个常见示例。在训练时,模型学习到之前的动作(刹车)几乎可以一直用来准确地预测当前的动作。在测试时,当模型错误地选择了“制动”时,它会继续选择“制动”,从而形成一个糟糕的反馈循环,导致它与专家数据也就是训练数据产生分歧。
2. 因果混淆与学习捷径(Causal Confusion and Learning Shortcuts)
当模型无法区分环境中行为的因果关系时,在模型的学习过程中往往会产生因果混淆(Causal Confusion)[9]。这是因为模型过度依赖于专家行为产生的结果而不是做出这些行为原因,这会很大程度上导致闭环性能不佳。
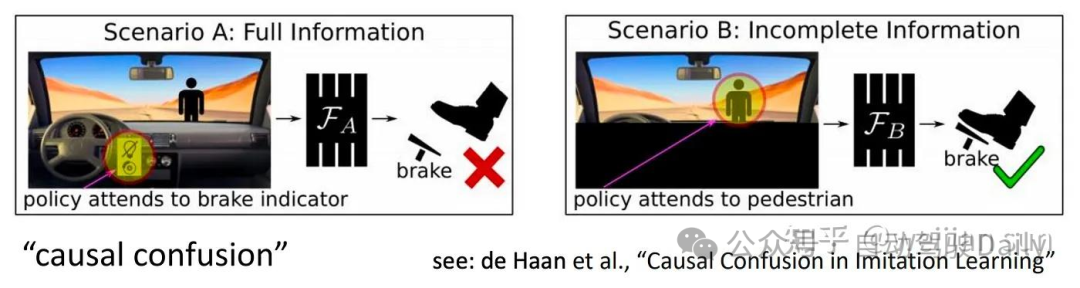
学习捷径(Learning Shortcuts)[3,8,9,10]意味着学习者通常依赖于对决策有强烈预测作用的特征。在实践中,如果在模型训练过程中在特征层面引入自车的历史信息会导致模型学习到错误的因果关系[9],这意味着网络可以通过从过去的运动趋势推断未来的规划轨迹而不是找到真正导致规划行为的根本原因来进行作弊(the “copycat” problem[8])。

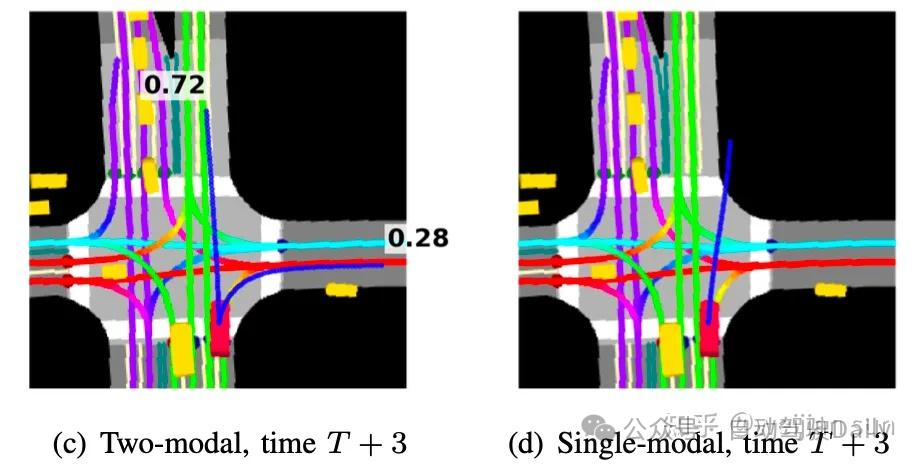
上图展示了自动驾驶场景中的一个“copycat”问题[8]。图的顶部显示了一系列观察结果,车辆在红灯前等待,绿灯亮起时开始行驶。该策略采用滑动观察窗口作为输入。在图的底部,我们显示了“copycat” 策略带来的结果,即简单地重放其之前的行动,这一策略将正确预测除一个行动外的所有行动。
研究表明[8]当满足以下两个条件时,模仿策略在访问过去的观察结果时会出现“copycat”问题:(i)专家行为随时间的变化具有很强的相关性,以及(ii)过去的专家行为很容易从观察历史中恢复。
学习捷径(Learning Shortcuts)很好的解释了为何不能简单的将基于模仿学习的轨迹预测模型应用于运动规划任务,而因果混淆(Causal Confusion)现象也说明了开环指标或开环测试对于motion planning任务意义不大(因为开环条件下无法确定模型是否学到了正确的因果关系)。
3. 轨迹不满足环境约束 Scene Compliance(respect driving constraints)
尽管工业界与学术界在将模仿学习的模型应用于轨迹预测任务上做出了许多努力,但模型输出轨迹仍远未达到最优,实际表现往往不完全遵守驾驶规则或不符合环境约束。正如早期研究[3,11]所强调的那样,纯粹的模仿学习不足以排除不希望的结果,例如与静止障碍物的碰撞或偏离可行驶路径。这些约束通常由静态地图元素组成,如道路边界约束、涉及与自车交互博弈的动态障碍物的碰撞约束以及车辆运动学模型方面的约束(以确保可行的控制器执行)。
以下问题可以解释为什么通过模仿学习输出的轨迹未能遵守环境约束:
a. 模式崩溃/模态坍塌(Mode Collapse)
试图实现多样性和覆盖率的模型在训练过程中经常出现模式崩溃[12,13]。崩溃的模型将带来不安全、不太可能或介于不同模态输出之间的输出。
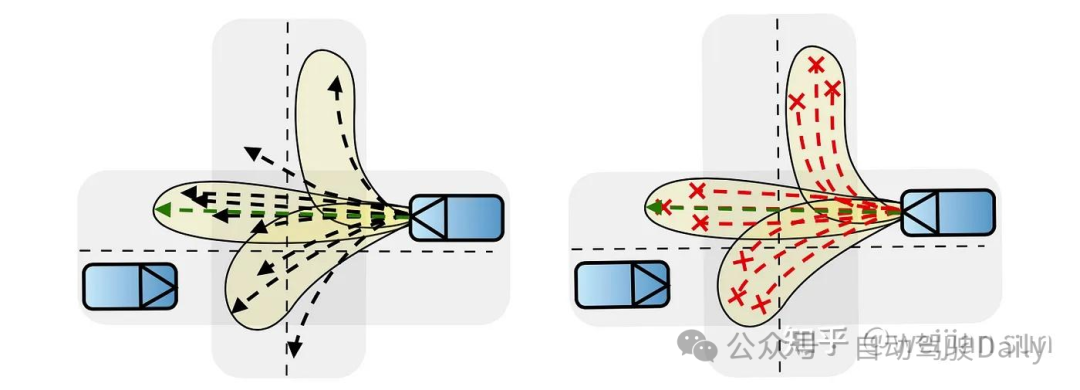
确定性模型通常通过监督回归预测自车最可能的轨迹。在连续动作空间中,如果为我们的策略选择的参数分布不是多模态(例如单高斯),则对action结果的最大似然估计(MLE)会是一个问题。对于基于模仿学习得到的模型来说,模态坍塌后的模型给出“中间模态”的轨迹肯定会与边界或其他障碍物产生碰撞。
b.隐式的学习目标(Implicit Learning Target)
基于模仿学习的运动规划模型在训练阶段通常在推断轨迹和真值轨迹之间应用损失函数(l2)。避免碰撞或偏离目标线路的训练目标是隐含的,因此不能很好地泛化到测试数据上。(在我看来,内隐学习目标问题与因果混淆有点关系,因为两者都将真正的因果排除在监督之外)
如果单从数学层面上解释这一现象,当我们用L2 loss 回归轨迹真值时,点的输出范围是[-∞, +∞]。并没有设计额外的机制来确保或约束轨迹点落在特点范围内。尽管训练后的模型在统计意义上收敛,但它仍可能在特定的case层面上失败。
解决方案1:在模仿学习的框架下
1. DAgger(Dataset Aggregation)
DAgger[6]是dataset aggregation的缩写,它可以被归纳到数据增广这一大类方案中,但和传统的数据增广策略不太一样。DAgger[6]通过让人类专家参与到闭环来解决分布漂移(distribution shift)的问题,并要求专家在闭环测试中按照学习到的策略观察时对数据进行标记。这样你就可以得到一些关于如何纠正错误的监督。
方案:使用以下算法从真正的策略分布而不是人工分布(专家数据)中收集训练数据:

局限性与问题:(i)扩展性不强,虽然它解决了分布漂移的问题,但它使用的是人类在闭环中提供标签的这一种不自然的方式,这种方式难以提供海量的数据。(ii)DAgger要求在闭环或实车闭环中执行不安全或部分训练的策略,这在现实世界中应用起来可能是危险的。(iii)策略需要在每个迭代步骤中重新训练,这在训练效率上较为低下。
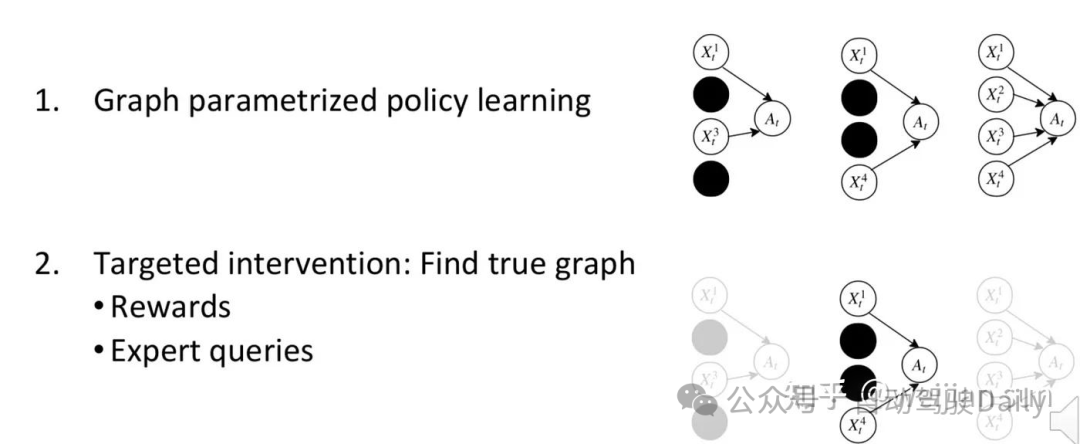
2.CCIL
CCIL[9]是通过有针对性的干预来解决因果错误识别现象(causal misidentification phenomenon):获取更多信息可能会导致更差的性能。具体来说,他们首先学习从因果关系图到策略的映射,然后实施有针对性的干预措施,通过询问专家或在环境中执行选定的政策,来有效地搜索正确的政策。
局限性与问题: 与DAgger类似,需要引入闭环环境进行交互以及在线对专家进行询问。
3.在模仿中应用随机失活(Dropout — Behavior Clone)
随机失活(Dropout)原本是在训练阶段广泛使用的一种用于避免过拟合的训练策略,但在这里的应用目的稍有不同。Dropout-BC是一种通过在训练阶段向可能导致因果混淆的输入特征上添加Dropout层来对抗因果混淆的技巧。可以有多个drop选项,其中:
ChauffeurNet[3]引入了对历史轨迹特征的dropout和模型学习损失函数的dropout。
Pluto[14]删除了仅包含当前状态的整个自我历史,并对自车当前状态采用了基于attation机制的dropout编码器。
Rethinking[15]引入了一种基于attention机制的dropout编码器对历史轨迹特征进行编码。
局限性与问题: Dropout 适用于错误的因果关系已经明确的前提下,可以简单的应用这一策略,但当虚假起因难以鉴别时,这一策略可能就失效了。
4.引入扰动的数据增广(Perturbation-based Augmentations)
扰动增广是解决分布漂移(distribution shift)的另一种数据增强策略。然而,需要仔细设计扰动策略以防止被人为扰动后的场景失真。
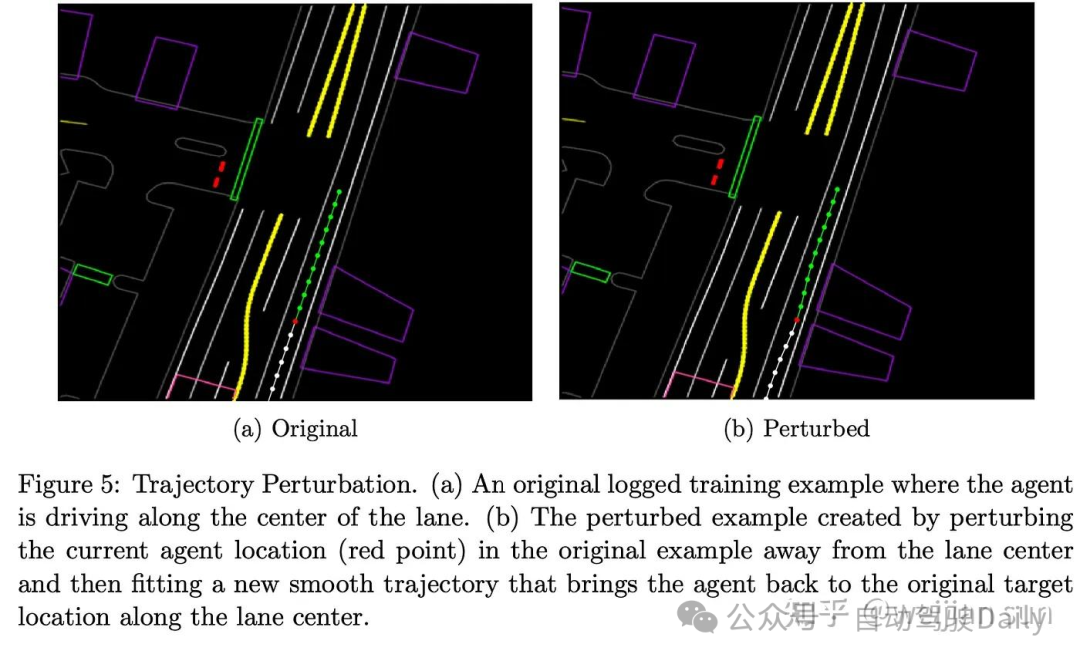
ChauffeurNet[3]引入了轨迹扰动,使模型能够从微小偏差中恢复:
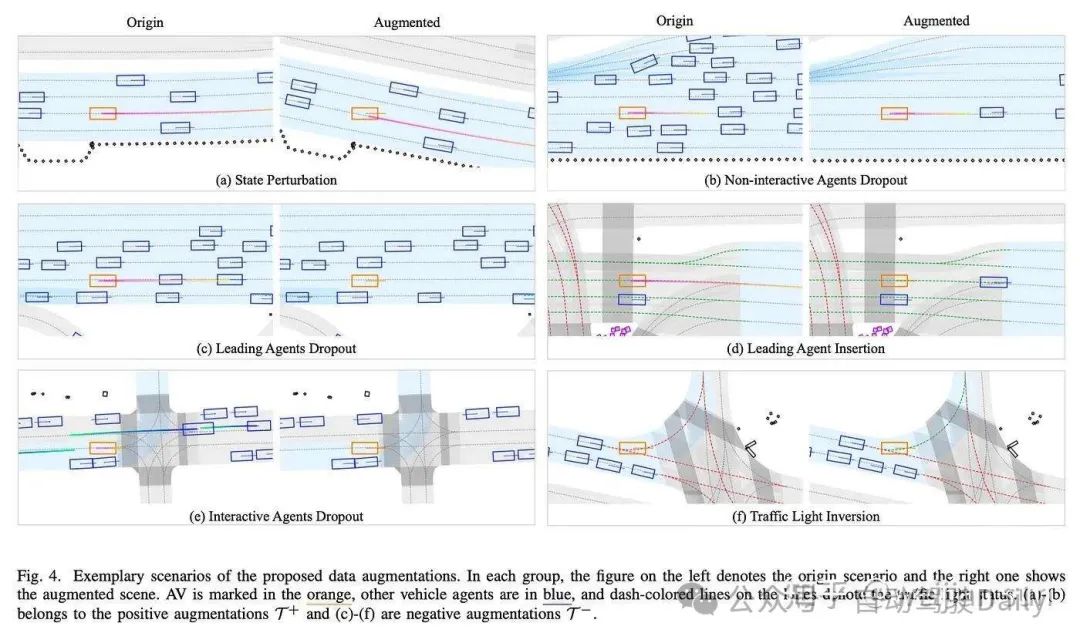
Pluto[14]提供了六个额外设计的增广策略,包括状态扰动、非交互式障碍物丢弃、前导障碍物丢弃、前导障碍物插入、交互式障碍物丢弃和交通灯信息反转。
[16] 引入反馈合成器,其基于当前状态用扰动策略生成新的状态并使用规则生成轨迹用于训练监督:
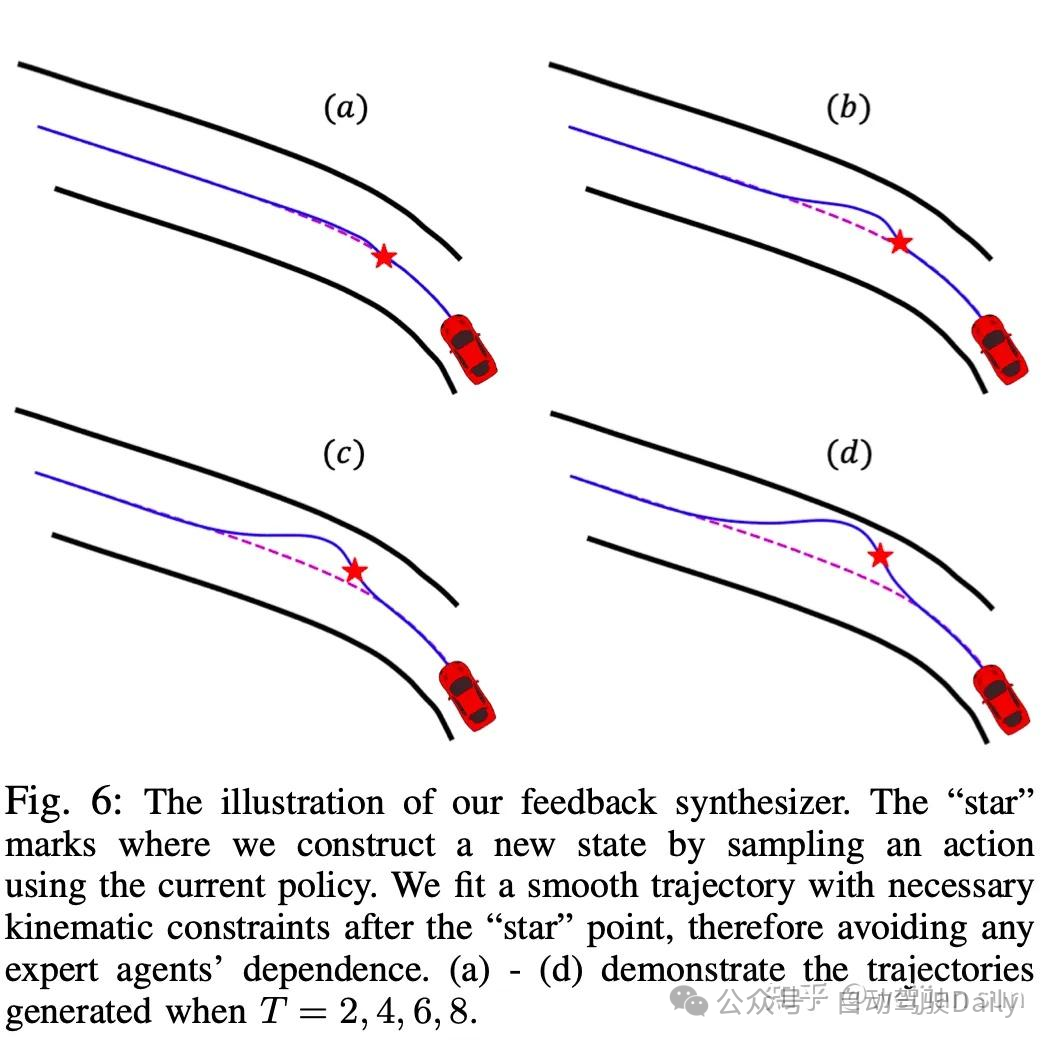
局限性与问题: 由于使用基于扰动的增广策略生成的新数据只能产生相对于原始数据的微小偏差(为了避免环境失真),因此当自车大幅度偏离目标路线或需要处理完全未见过的场景时,这一策略带来的提升是有限的(尽管这与模型的泛化能力更相关)。
5. 碰撞相关的损失函数(Auxiliary Loss for Collision Avoidance)
由于单纯的模仿学习没有明确指定规划任务中涉及的重要目标和约束,这将不可避免地会产生偏离约束的行为。为解决这一问题,可以引入额外的与碰撞相关的损失函数来辅助训练用于调节这些不必要的行为,从而产生更好的因果推理以及让输出的轨迹满足场景的环境约束。
碰撞相关的损失函数可以组织成各种风格,无论是参数化的形式还是非参数化形式,既可以通过热力图(heatmap)或生成代价体(cost volume)来构建。但最重要的是,碰撞损失函数需要是可微分的/可导,这样相应的损失才能反向传播到轨迹生成器。
(I) Distance Hinge Loss
Hinge loss 是最简单的形式,被VAD[17]、DIPP[18]和[21]等其他方案所采用,对于每个未来的时间点,我们计算规划轨迹点与其最近的地图边界线和障碍物之间的距离d。该约束旨在将规划轨迹推离道路边界,以便轨迹可以保持在可驾驶区域内。
对于用于避免障碍物的碰撞loss,如果自车与障碍物的距离小于阈值,则loss由与最接近障碍物的距离构成:
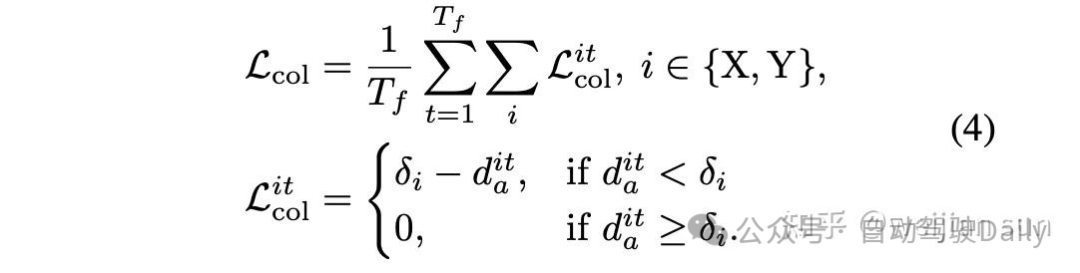
用于避免边界碰撞的损失函数由规划轨迹点与其最近的地图边界线之间的距离构成:
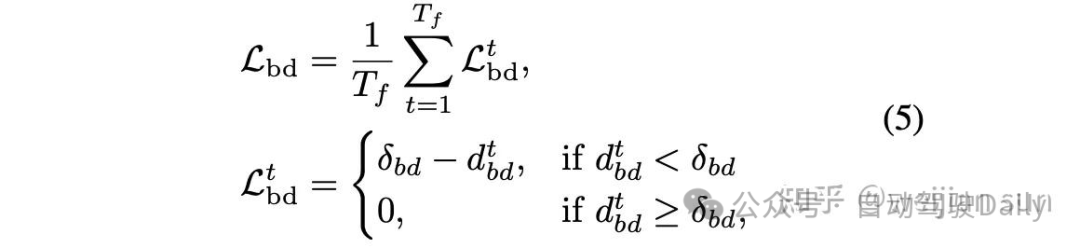
其中来自[21]的实现方式稍许有些不同:
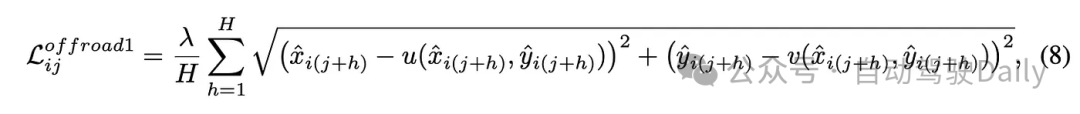
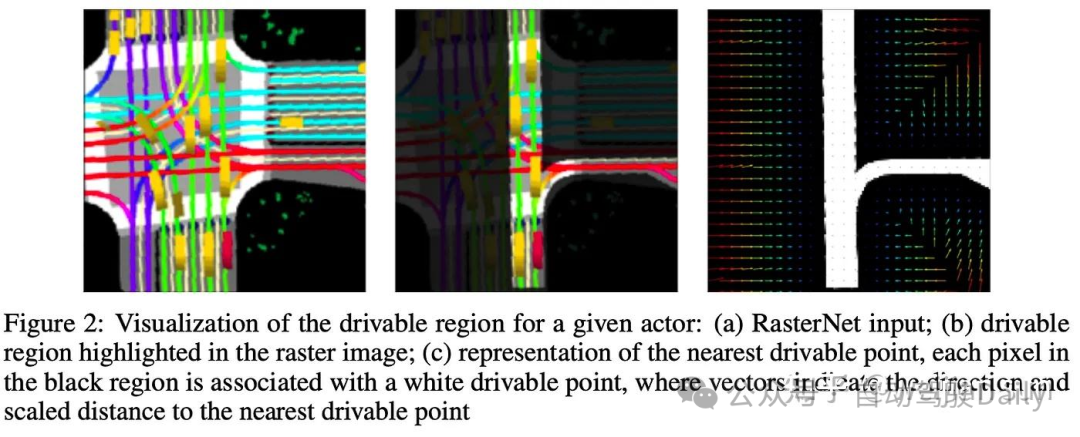
局限性与问题: 这类基于hingloss方案的一个缺点是损失函数会将轨迹点推离边界线或边界区域。因此,如果方向错误(如可能与用于模仿学习的l2损失的方向冲突),则可能会产生误导,因此实际应用带来的增益较为有限。(个人理解还是没有从问题本质出发去解决imitation的局限)
(II) Differentiable Rasterization(Ellipse Loss)
Differentiable Rasterization先将每个轨迹点渲染成图像的方法,进而通过非参形式计算碰撞。[19] 首先引入椭圆损失(Ellipse Loss)来生成符合场景的预测轨迹。SC-GAN[20]通过场景光栅化对这一方案进行了扩展。他们提出了一种方案,其中每个轨迹点都使用可微核函数(其实就是高斯核函数)转换为光栅化图像,随后使用图像空间内的障碍物掩模计算损失(ps:百度翻译的真好,连掩模都能翻译出来,虽然不知道这么翻译对不对)。

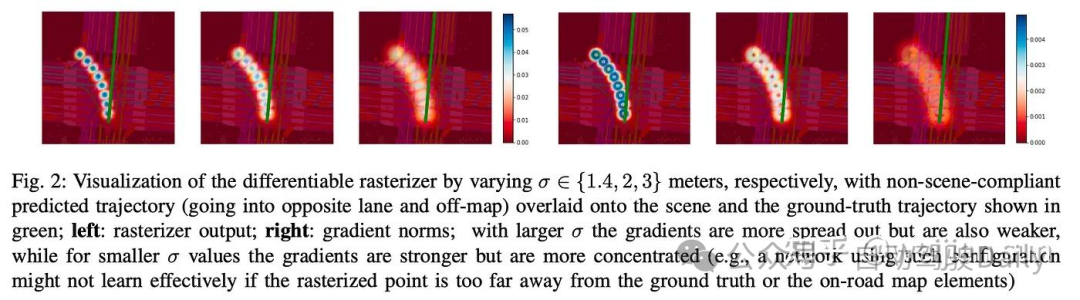
此外,[20]通过额外引入GAN的训练框架进一步提高了输出的合理性,GAN框架通过生成对抗的方式训练模型,以鼓励生成器输出更逼真的轨迹。这种范式简化了鉴别器的任务,因为不符合场景的轨迹更容易辨别,并允许梯度回流,迫使生成器输出更好、更逼真的轨迹。
局限性与问题: 需要在每个点上应用高斯核,计算效率很低下。
(III)Overlap Calculation
Overlap Calculation是另一种以非参数形式组织的碰撞loss的策略,以确保预测的轨迹符合给定的场景。ChauffeurNet[3]最早提出了这种专门的损失方法,不过该方案需要将输出的参数化轨迹先转化成非参数化的形式,然后用Mask测量预测的自车在对应时刻的bbox与每个时间步其他障碍物与道路元素的重叠。
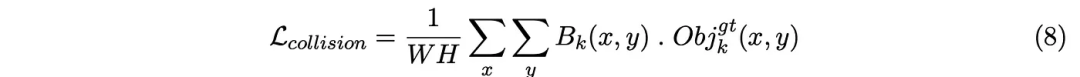
其中Bk是输出自车未来预测的似然图,Obj_gt是一个二进制掩码图,在时间步长k处,场景中的其他动态对象(其他车辆、行人等)在所有像素处都占据了一个格子。

(IV) Bilinear Interpolation on Non-parametric Cost Map
Pluto[14]通过在预先构建的成本图(cost map)上应用可微插值来计算损失并回传梯度。GAD[4]对使用Maximum Marginal Planning学习得到的代价体(cost volume)应用了类似的插值策略。
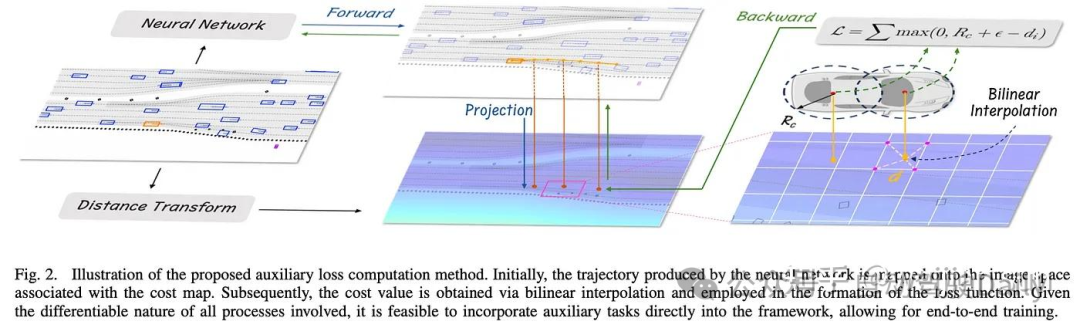
总的来讲简单的collision loss 效果较为有限,但复杂的loss设计又会在回传时带来梯度消失的问题,这个需要工程师们根据特定的问题以及参数或非参数的输入形式trade-off一下。
6. 在行为模仿中引入目标先验证(Goal-conditioned Behavioral Cloning[BC with prior information])
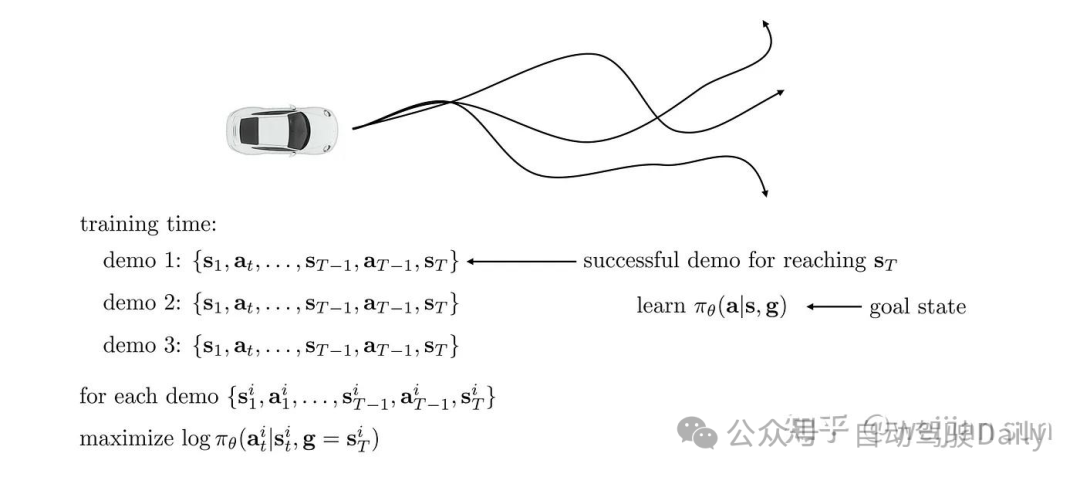
在行为模仿中引入目标先验是是解决模式崩溃(mode collapse)的方法之一。其实已经有大量的工作将先验信息引入到轨迹回归中,尽管这些工作大多研究的是轨迹预测问题而并非运动规划问题。
这些先验可以通过目标点的形式引入进来,其中TNT[49]首先从路线图中采样锚点,并基于这些锚点生成轨迹。然后对轨迹进行评分,并使用非最大抑制(NMS)来选择最终的轨迹集。
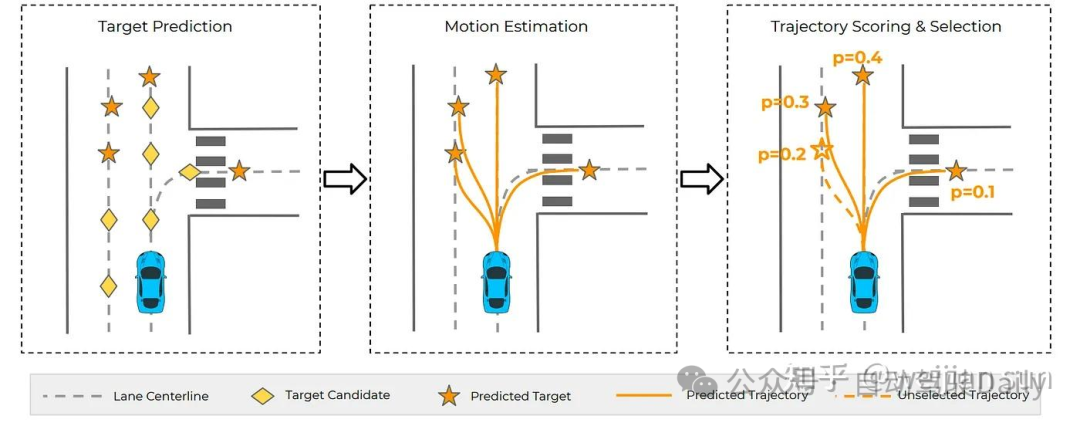
上图:TNT由三个阶段组成:(a)目标预测。(b) 带目标先验的运动估计。(c) 评分和选择,对轨迹进行排名,并使用似然分数选择最终的轨迹预测集。
与TNT不同,LaneRCNN[50]的将车道段视为先验,并输出每个车道的概率。此外,之后还有大量类似的工作,DenseTNT[51]引入了密集的目标候选点。HOME[52]使用CNN生成热图,并设计了用于目标采样的贪心算法,THOMAS[53]对其进行了改进,为了满足了多个障碍物的轨迹输出的自洽性以及与场景一致性。
此类先验信息也可以是MultiPath[54]中的通过对专家数据聚类获得锚点路径:
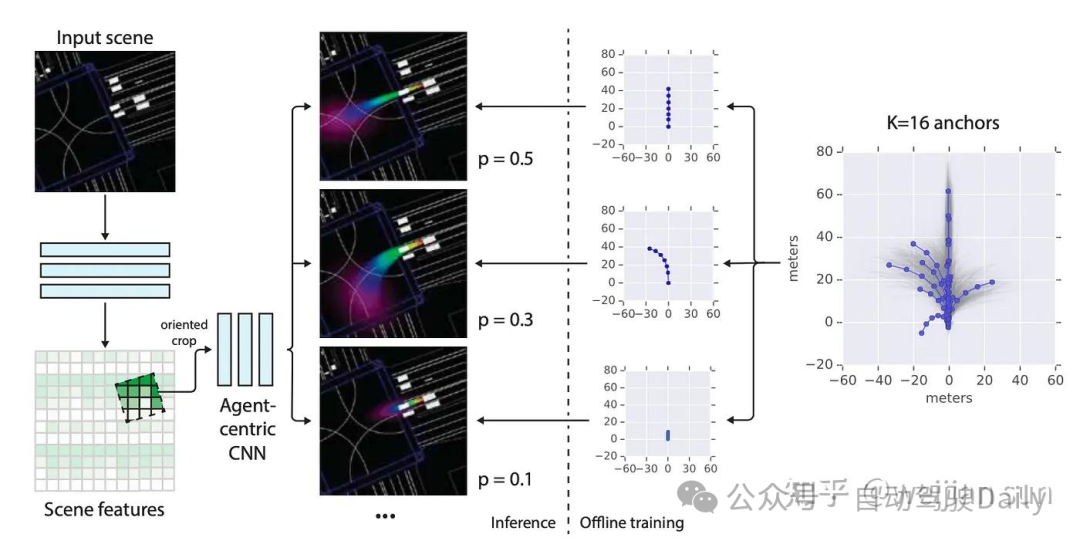
上图:MultiPath通过一组固定的锚点路径来表征不同的轨迹分布模式,再来回归相对于锚点路径的偏移。
局限性与问题:(1)在引入先验条件的模仿学习中,我们需要抽象出先验信息并对其进行定义,以便在训练数据中标记。然而,对于自动驾驶任务,一些先验可能难以抽象,因此无法明确定义,例如在纵向和横向上与其他障碍物的复杂交互行为引入多步博弈。(2) 对于多阶段任务或带先验信息的回归任务而言,上游的错误信息或误导性先验会将把错误传播到后续阶段和下游任务上(error propagation)。(3) “从n中选择1”的策略会影响模块输出的时序稳定性。
7. 混合高斯模型(Mixture of Gaussians)
模态崩溃(mode collapse)是由于简单的将单模态损失函数应用于多模态专家数据导致的。比较直接的解决办法是应用混合高斯(Mixture of Gaussians),对数据进行回归,例如混合密集网络(Mixture Density Networks)。混合密度网络通过 Mixture-of-Experts loss 学习高斯混合模型的参数来解决多模态回归任务,
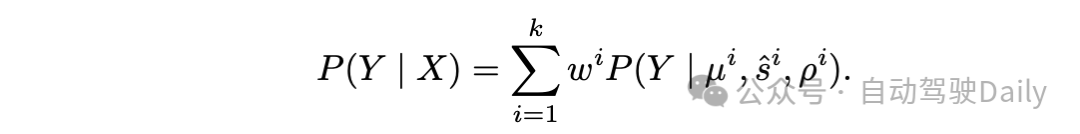
然而,在高维空间中操作时,由于数值不稳定,MDN在实践中往往难以训练。因此在实践中,往往使用hard-assign或 winner-takes-all (WTA) 的方式将轨迹分配给对应的模态,也称 Multiple-Trajectory Prediction(MTP) loss,而[55]就属于这一类。Min-of-K[55]探索多轨迹预测形式的损失函数:
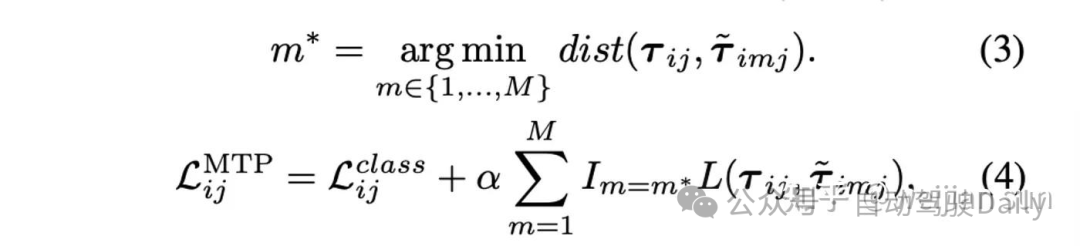
其中m*是与真值的最佳匹配的预测轨迹。
局限性与问题:(1)由于未明确定义模态,模态之间存在可交换性(exchangeability)。(2)由于可交换性导致的模糊问题,仍然可能遭受模式崩溃(mode collapse)。
8 .隐变量模型(Latent Variable Models)
隐变量模型(latent variable model) ,严格意义上这一小节讨论的内容已经超出了模仿学习的范畴了。从轨迹生成的角度来讲,最开始Rule of the Road[13]在轨迹预测领域应用VAE(Variational Auto Encoder)主要是想通过引入中间变量或通过引入latent variable z 来解决Multiple-Trajectory Prediction(MTP) loss导致回归阶段的mode可交换性(exchangeability)问题[13]。而最开始Social GAN在轨迹预测领域引入GAN网络主要想解决行人轨迹预测上Socially Plausible的问题56,后来的MotionDiffuser[57]逐渐引入了diffusion model等其他生成式模型。
首先解释一下生成式模型(generative model),生成模型描述的是创建数据的概率分布。他的底层数学原理与判别模型有较大的区别, 判别模型主要应用于预测任务,特别是当目标是连续变量时。判别模型通过建立一个数学模型来描述一个或多个自变量与因变量之间的关系,通过数据学习一个最佳的拟合曲线或表面,以便对未来的数据进行预测。生成模型则主要关注于数据的生成过程,旨在学习数据的联合概率分布,并通过这个分布生成新的数据样本。

假设我们输入数据x,想把数据分类到标签y中。生成模型学习联合概率分布p(x, y),而判别模型学习条件概率分布p(y|x)或者说是“给定x的y的概率”,从输入x到类标签的直接映射。分布p(y|x)是将给定示例x分类为类y的自然分布,这就是为什么直接建模的算法被称为判别算法。生成算法模型p(x,y),是通过应用Bayes Rule将其转换为p(y|x),然后选择最可能的标签y来进行预测。然而,分布p(x,y)也可以用于其他目的。例如,我们可以使用p(x, y)来生成可能的(x, y)。因此Generative Model 更贴近贝叶斯派(Bayesian)的理论而 Discriminative Model 更符合频派(Frequentist)的逻辑,尽管频率论和贝叶斯方法都可以用于解释判别模型或生成式模型。
生成式模型的表现往往由三个维度来衡量:
Fidelity(sample quality):拟真性,产生高质量的样本,在motion planning或trajectory prediction的任务下可以解读为轨迹是否满足环境约束。
Diversity(sample coverage):多模态,覆盖所有模式并产生不同的样本,在motion planning或trajectory prediction的任务下可解读为输出样本是否可以cover横纵向或多车交互情况下的多种可能轨迹(具备多模态的轨迹生成模型可以简单的应用于基于后决策的planning系统中)。
Sampling Efficiency:快速且低计算成本地产生样本,一般指代inference时的样本生成效率或时间复杂度。
通常认为生成式学习框架或模型无法同时满足以上三个基本标准,the Trilemma[58]:
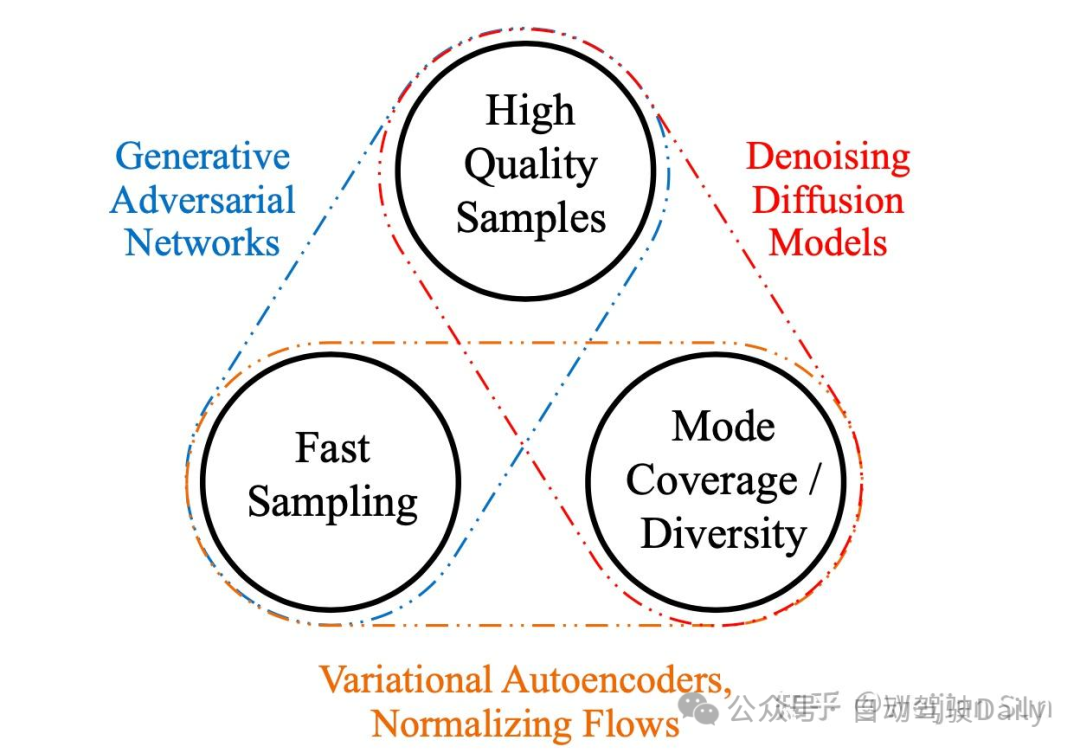
GAN可以快速生成满足fidelity的样本,但coverage较差,容易mode collapse,VAE满足coverage和efficiency,但伴随着low fidelity,而Diffusion虽然满足fidelity和diversity,从它们中采样通常需要数千次denoising,这使得它们的sample efficiency很差。
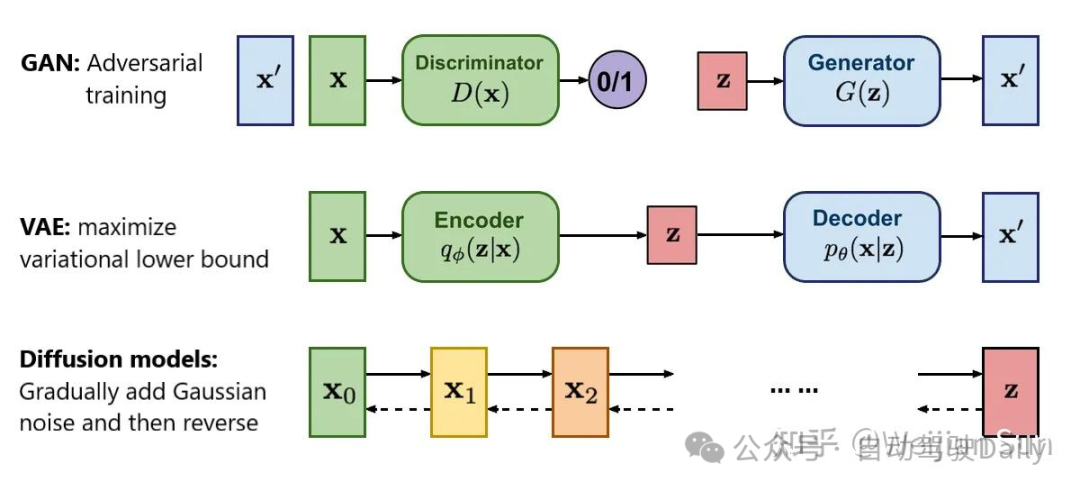
上图:这些生成模型都依赖于中间变量或隐含变量z,所以他们也叫latent variable model。
VAE
VAE的理论依据来自Auto-Encoding Variational Bayes[59],但更推荐参考Tutorial on variational autoencoders[60],这里面的解释会更为详尽。

总的来讲VAE的思想是联合优化生成模型参数θ以减少输入和输出之间的重建误差,以及优化ϕ
使q(z|x)和p(z|x)尽可能靠近:
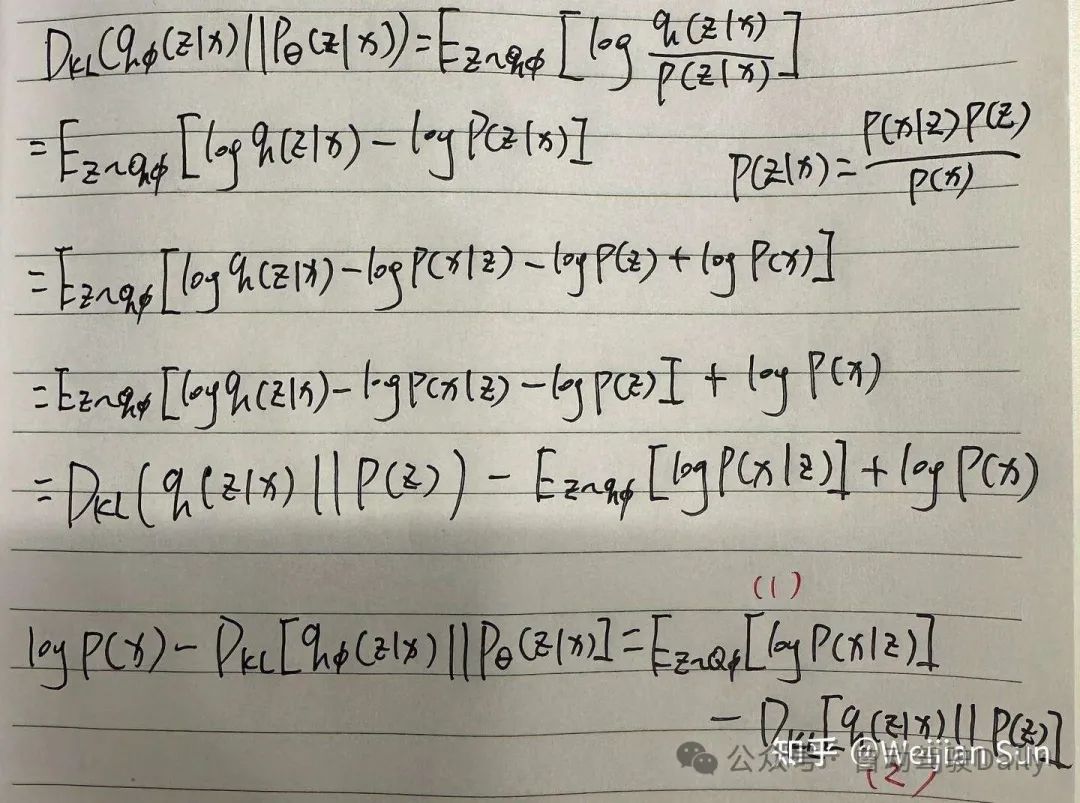
式子的右边是evidence lower bound(ELBO),右边的第一项是输入和输出之间的重建误差,第二项是约束项用于保证z的分布空间是连续可解释的。在VAE中我们要maximize log P(x)也就是要maximize ELBO。
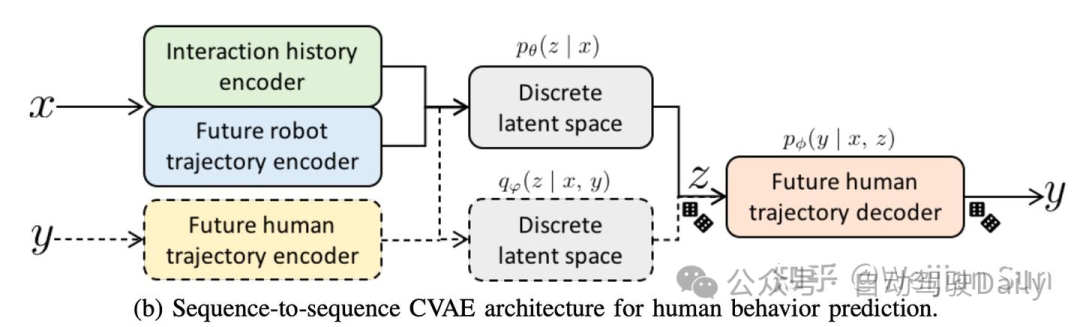
当应用于trajectory generation任务时,实际选用的是CVAE(Conditional Variational Auto Encoder),decoder 需要引入driving context为先验生成对应的轨迹,driving context往往包括自车历史,地图,他车状态等环境信息。这个时候evidence lower bound(ELBO)引入了额外的环境先验(下式中y变成了样本,x为环境先验):
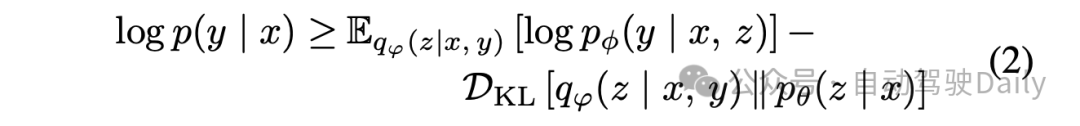
CVAE 主要是通过z的分布来表征不同的模态(横纵向,多车交互),因此可以在不定义目标先验的前期下满足diversity,通过对z的采样,可以生成multi-mode的轨迹。于winner-take-all策略相比,它的理论上限要更高,因为CVAE更关注数据的生成过程,也就是P(x, y)。尽管将CVAE应用于motion planning任务的研究还不多,但已有大量的工作拓展了CVAE在轨迹预测任务上的应用,CVAE在这一领域的应用更多的是从生成模型的角度出发,学习P(x,y)联合分布,依据环境context和agent历史生成多模态概率分布,从而使用在分布上采用得到的feature decode出对应模态的轨迹[61,62,63,64,65,66,67]。
问题与局限性:(i)基于分布采样的生成方法难以估计的误差,无法进行概率推理(例如,知道时空区域中碰撞的概率)。(ii)需要多次随机采样以获得多模态样本,不利于case复现。(iii)cvae 在fidelity方面有天然缺陷,当应用于motion planning 时,没法保证生成的轨迹满足环境约束。
为了解决随机性问题,CUAE[61]引入了Unscented Autoencoders以确定性的方式从任何学习到的分布中提取样本,比随机采样更适合自动驾驶车端的轨迹生成任务:
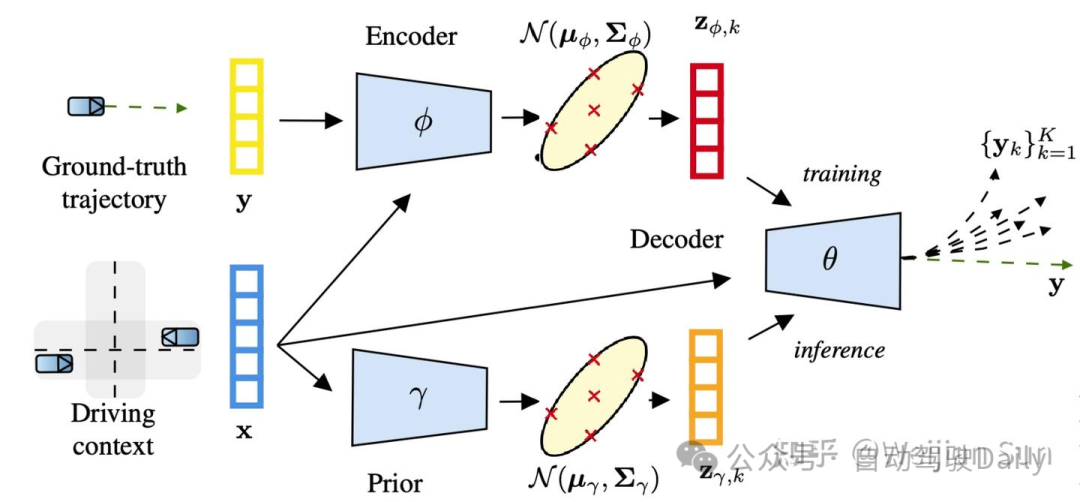
CUAE这一方案在训练和推理中并不是随机采样latent space,而是计算φ和γ分布的sigma点并对其进行变换,因此在latent space 采样的点是固定点。
GAN
GAN 其实在planning问题上有一个独立的门类,叫Generative Adversarial Imitation Learning(GAIL),以及与之等价的Guilded Cost Learing(GCL),均属于IRL的一个分支,这部分会在下一个章节里面展开讨论,但在trajectory prediction的问题上,特别是行人轨迹,在这一领域引入GAN的motivation主要想利用discriminator的机制来提升轨迹生成阶段的socially/physically plausible,同时通过生成式模型建模轨迹与环境的联合分布。
最早由SocialGan[56]引入这一思想,然后SoPhie[68]引入了attention机制,Social-BiGAT[69]拓展了GNN的backbone,而Goal-GAN[70]则是升级成two-stage的goal condition的generator。有意思的是他们大多研究的都是行人轨迹预测问题。
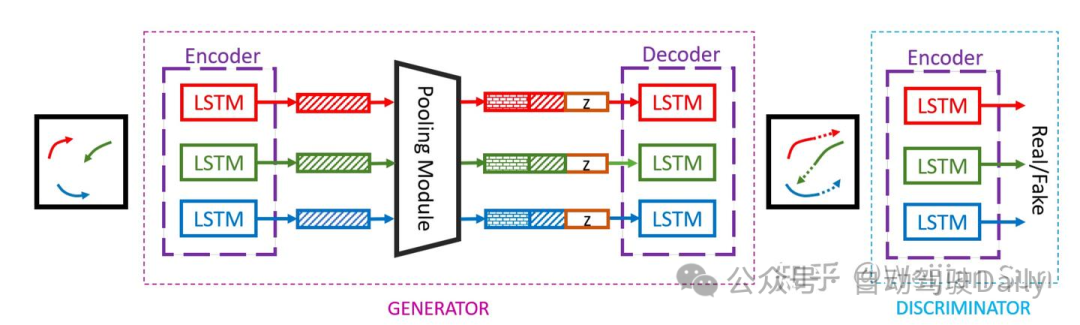
问题与局限性:(i)与irl这类reward model相比,单纯的discriminator提供的信息量太少(从label层面上来讲只有1bit),缺乏reward的精细化建模(环境约束/交互/运动学模型),因此给generator带来的增益比较有限。(ii) adversarial trainning 不稳定且训练难度较大。(iii) GAN这一大类模型存在model collapse的问题。
说到这里就不得不提及一下DESIRE[71],DESIRE是与social-gan同时期的工作(甚至要更早),它的架构是由基于CVAE的trajectory generator和基于Inverse Optimal Control(也叫Guiled Cost Learning)的evaluator构成,GCL在数学形式和GAIL已经比较相似了,但DESIRE并未引入minimax的trainning机制来将reward回传给generator并进行迭代优化,而是通过IOC学到的cost来refine CVAE生成的轨迹,这一组合机制弥补了单纯的CVAE在fidelity上的不足,同时也避免了GAN架构带来的model collapse与trainning unstable的问题(但同样,通过refine已有轨迹带来的能力上限也没有那么高)。
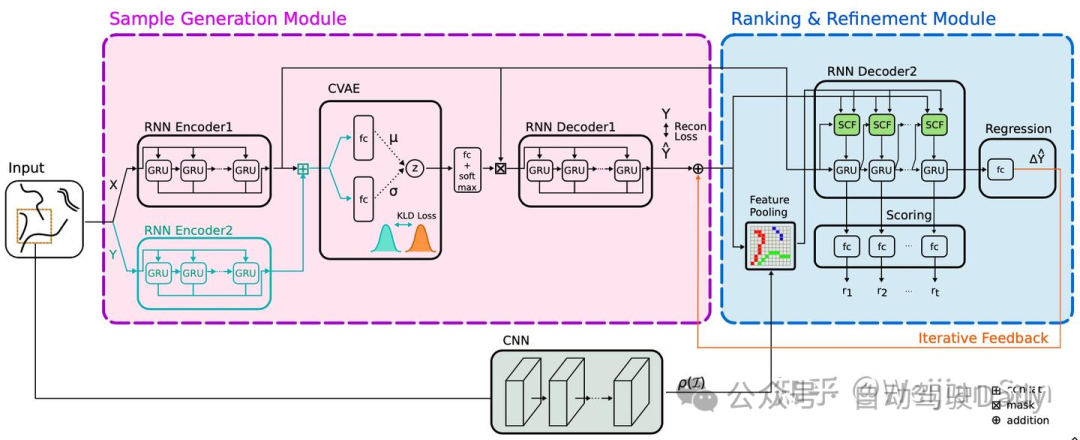
上图描述的是DESIRE的模型架构。首先DESIRE通过基于CVAE的encoder-decoder生成多个轨迹样本Yˆ(原文里面说的是合理的轨迹样本,但实际上CVAE并不能保证样本的合理性)。然后IOC模块为每条轨迹分配score,并根据score学习位移向量∆Yˆ用于轨迹的进一步refine。通过迭代refine对CVAE输出的轨迹进行修正。
Diffusion
Diffusion model从效果上可以同时满足fidelity和diversity,如果将运动规划reduce成一个生成任务,diffusion可以同时保证生成多模态并同时满足环境约束的轨迹。可以说是生成式模型中解决motion planning的最佳选择。但diffusion有一个致命缺陷,他需要成百甚至上千次的denoising来得到合理的样本,这使得这类模型在板子(Xavier,Orin,Thor)上想做到real-time(峰值50ms吧)非常困难,因此将diffusion真正用于这一任务的工作并不多。虽然在diffusion的模型领域有工作[72,58]可以将denoising的次数优化到2步左右,但相关的方法的有效性还未在trajectory generation这一任务验证过。
其中MotionDiffuser[73]应该是第一个将diffusion model用于轨迹生成任务的:
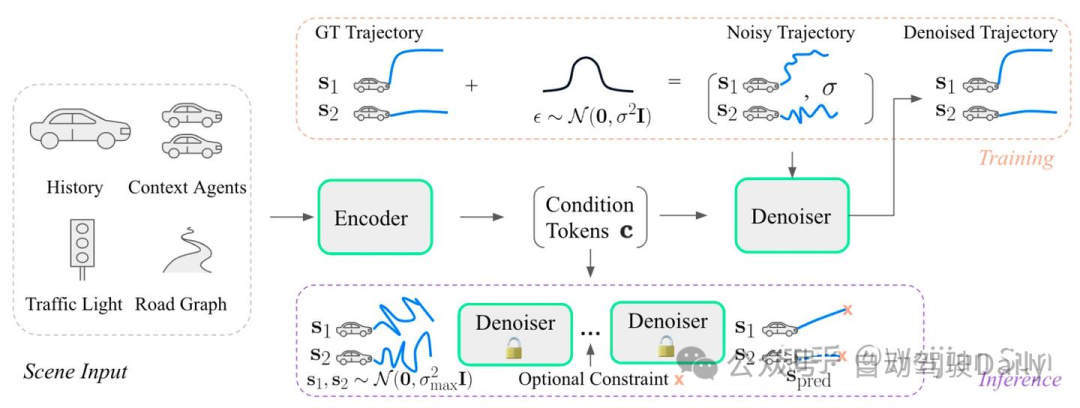
他们的数据表明在V100上,denoising step为8时耗时为101ms,当step增加到32时耗时增加到408ms。
问题与局限性:sampling efficiency是diffusion model最大的局限性,还需要学术界在基础模型领域做更多的探索。
解决方案2:超越简单的行为模仿
在本节中,我们将探讨超出模仿学习之外的奖励模型:强化学习(RL),逆向强化学习(IRL)和生成对抗式模仿学习(GAIL)这一系列。
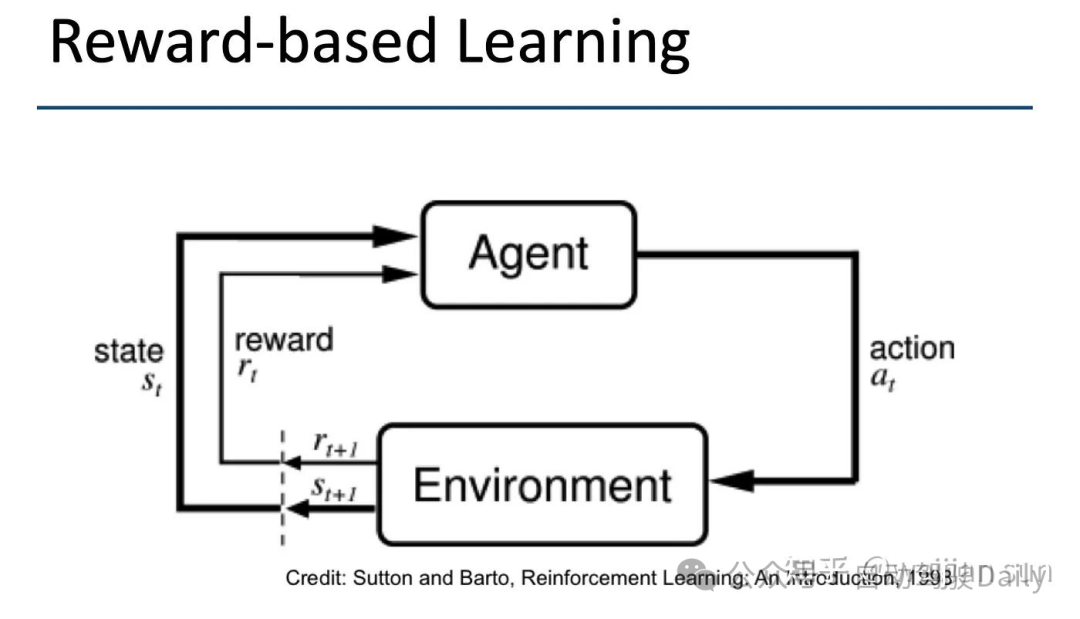
由于大部分基于奖励的方法(reward model)引入了闭环训练,因此策略(policies)可以在观察(observations)、行动(actions)和结果(outcomes)之间建立因果关系。这类机制得到的模型具有以下优势:(1)不易受到开环模仿学习中常见的分布漂移(distribution shift)和因果混淆(causal confusion)的影响,(2)由于在奖励函数中引入了环境约束与安全考量,因此在结果层面上输出更符合预期,相比模仿学习中的隐含式监督更为明确。

个人认为这类方案最有意思的一点是系统更多的由负样本驱动模型的学习,而正样本只提供基本引导。

“Evolution forged the entirety of sentient life on this planet using only one tool: the mistake.” — Robert Ford (as played by Anthony Hopkins), Westworld
1. 强化学习 RL(Reinforcement Learning)
强化学习的目标是确定闭环控制策略,以实现累积奖励的最大化,强化学习算法通常分为基于模型或无模型两类。在这两种情况下,通常假设奖励函数是已知的,并且两者通常都依赖于收集系统数据来更新学习模型(基于模型),或者直接更新学习值函数或策略(无模型)。
强化学习的问题设置类似于随机序列决策(stochastic sequential decision-making)。RL将自动驾驶策略学习问题转化为马尔可夫决策过程(MDP)。按照标准形式,我们将MDP定义为基本元组{s,a,t,r,γ,ρ}。s和a分别表示状态空间(state)和动作空间(action)。t表示转移模型(transition model)。r代表奖励函数(reward function),γ代表折扣因子(discount factor)。ρ代表初始状态分布(initial state distribution)。目标是找到一个策略π,使预期的折扣奖励总和(expected discounted sum of rewards)最大化:
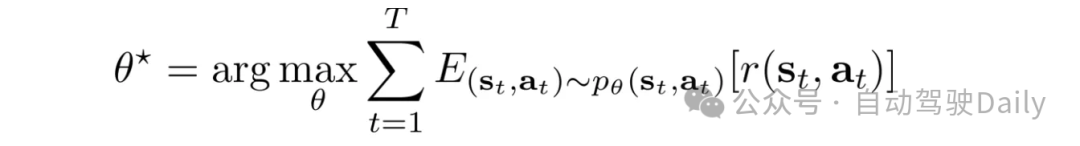
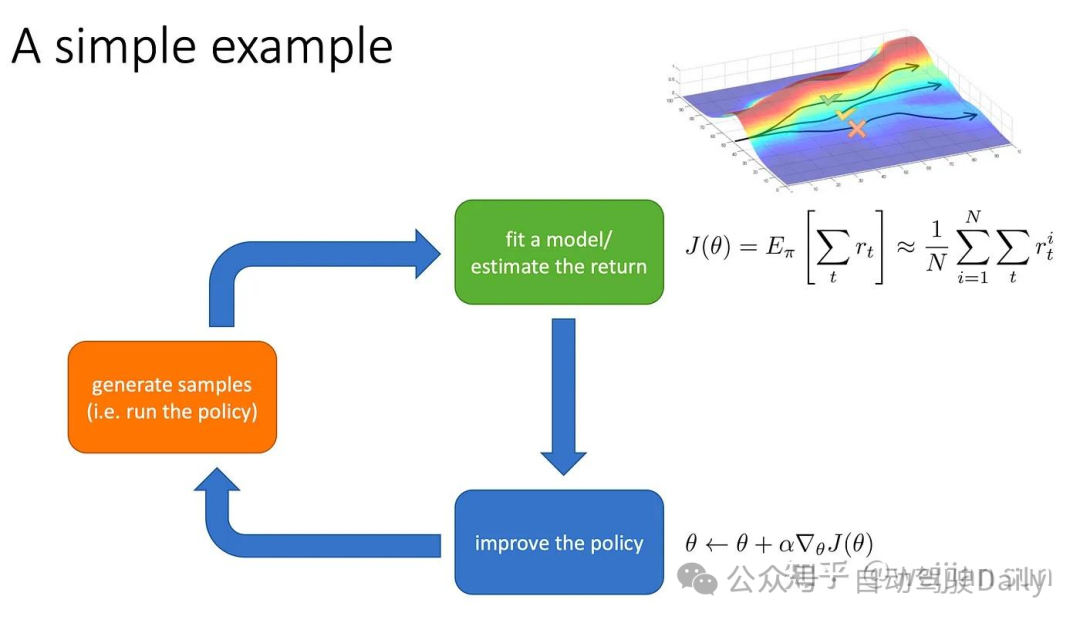
局限性与问题:(i)强化学习过度依赖于奖励函数设计,在自动驾驶领域确定一个能够准确代表真实目标的适当奖励函数是具有挑战性的。hand-crafted的奖励函数往往会输出技术上安全但不自然的行驶策略,同时当涉及到复杂的多车交互并需要遵守驾驶惯例的情况下,RL输出的规划方式可能很难取得进展。(ii)RL和其他用于自动驾驶的闭环方法通常需要引入仿真环境进行训练,而涉及到agent智能性的交互仿真仍然是一个悬而未决的问题。(iii)AV的奖励空间可能是稀疏的,这使得RL想得到合理结果所经历的学习过程非常昂贵,当我们使用次优策略进行探索时需要足够的数据量和犯错的次数来优化模型从而得到一个较优的策略。
由于上述已知问题,在运动规划中单独应用RL可能很困难,因此RL主要用于特定场景的特定任务如车道保持[22]、交叉口穿越[23]和车道变换[24]或是用于解决自动驾驶的长尾问题。然而,确实存在一些融合方案成功引入了RL,并证明了它们在自动驾驶领域大规模应用的可行性。
Waymo提出了BC-SAC[11],它将模仿学习与使用简单奖励的强化学习相结合,并证明了驾驶策略的安全性和可靠性比仅通过模仿学习的策略有了实质性的提高。在这项工作中,IL和RL提供了互补的优势:IL增加了真实感,减轻了奖励设计负担,RL提高了安全性和鲁棒性,特别是在缺乏大量数据的罕见和具有挑战性的场景中增益尤为明显。
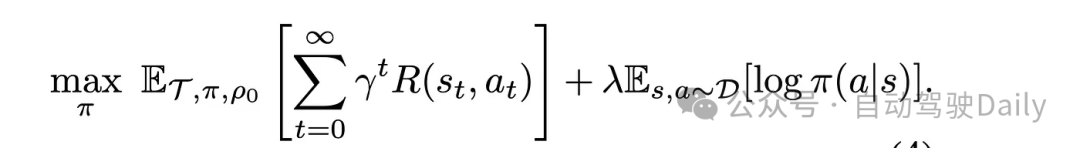
在某种程度上,BC-SAC的思想在处理分布漂移(distribution shift)方面与DAgger较为相似,但前者是通过RL损失函数来解决分布以外的情况。
2. 逆强化学习 IRL(Inverse Reinforcement Learning)
IRL的提出晚于行为克隆(BC),主要的motivation是因为模仿专家行为的学习策略可能受到几个因素的限制:
行为克隆无法理解专家行为的根本原因。
“专家”实际上可能不是最优的。
如果智能体遇到了与训练数据不一致的环境场景,那么对专家来说是最优的策略可能对智能体来说不是最优的。
那应对这些问题的另一种方法是推理并尝试学习专家用来生成其动作的潜在奖励函数(R)的表示。这种方法被称为逆强化学习(IRL)。
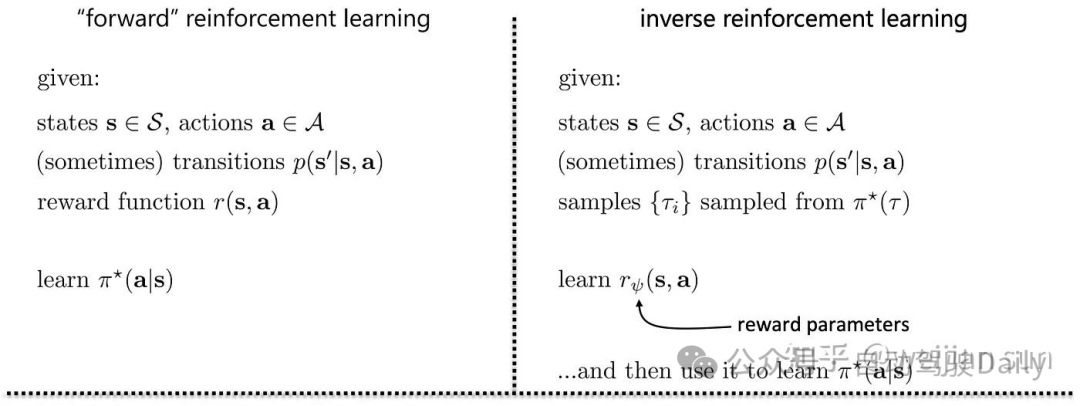
自动驾驶的IRL相关工作大多由基于规则或基于采样的轨迹生成器再加上通过IRL学习的奖励函数构成[32]。奖励函数可以从最大熵IRL(MaxEnt IRL)中学习[25],或者也可以由通过最大化边际规划(Maximum Margin Planning)通过从环境编码(context feature)中解码出的代价体(cost volume)表征[27]。
(i) 最大熵IRL(Maximum-entropy IRL)

MaxEnt IRL[25]采用线性结构化的奖励函数,在轨迹ξ上定义了选定的特征空间f(·)
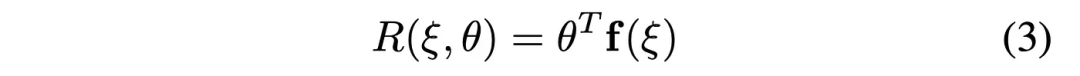
对于专家数据的估计为:
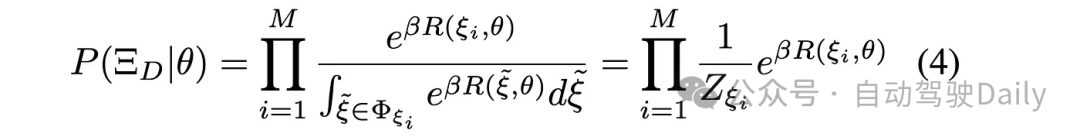
其中ξ_hat表示与ξ_i中具有相同初始和目标条件的所有轨迹的空间。目标是找到使专家轨迹的平均对数似然(averaged log-likelihood)最大化的最优θ_star:
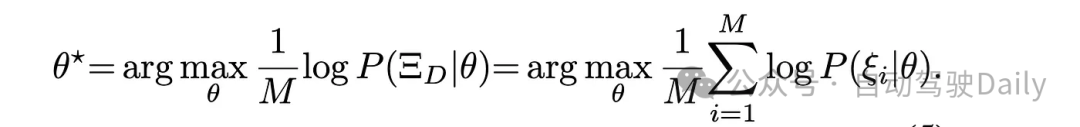
Motion.ai推出了首款在拉斯维加斯市区进行车载测试的DriveIRL[26]。所提出的方法首先通过规则采样生成了一组多样化的候选轨迹,经过一个轻量级和可解释的安全过滤器过滤,然后使用IRL学习得到的奖励函数对每个剩余的轨迹进行评分。最后再由下游的控制器跟踪最佳轨迹。
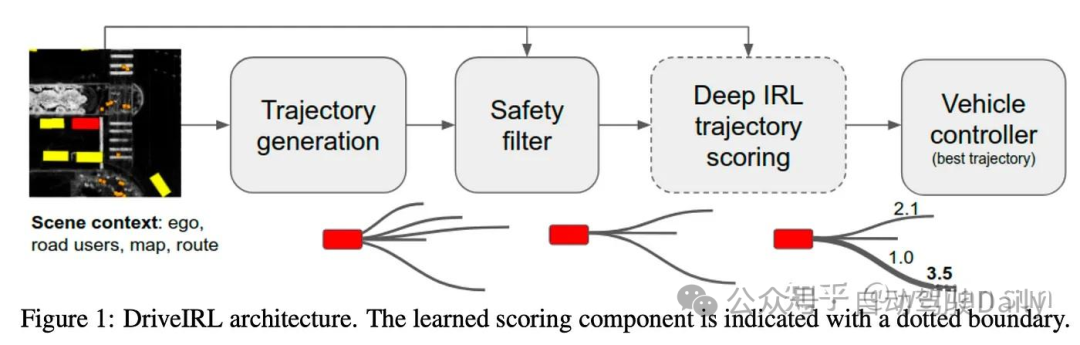
在运动规划领域,有不少工作探索了MaxEnt IRL的应用。其中有一部分来自于Chen Lv的团队。[29]在基于模型的预测方面改进了早期工作[28]。DIP[30]引入了交互式预测,而后来的工作DTPP[31]采用了树形结构的策略规划器。
局限性与问题:MaxEnt IRL不能对候选轨迹产生可解释的表征,这在自动驾驶这类将安全性作为重点考量的应用中不是特别可取。(ps:这个可解释性不足是相对于Maximum Margin Planning而言)
(ii) 最大化边际规划(Maximum Margin Planning)
最大化边际规划(Maximum Margin Planning)[27]是另一种IRL的经典方法,它使用结构化的边界损失(margin loss)来学习代价体(cost volume),该代价体(cost volume)可以通过动态规划产生专家般的路径。
标准MMP计算奖励函数向量w,使得专家策略π*最大程度地优于集合{π0,π1,..}中的策略。

这一表征方式也在两个方面得到了改进:(1)可以增加了一个松弛项来解释潜在的专家次优性,(2)可以增加了一种相似性函数,为与专家策略不同的策略提供了更多的“余地”。m(π∗,π)就是这样的一个函数,用于量化两个策略的差异程度。

上图:基于卫星彩色图像学习路径规划。顶行训练学习者沿着道路前进,而底行训练学习器“躲”在树里。从左到右,这些列描述了所呈现的单个训练示例以及该区域上的相应学习行为。cost随强度而变化。
Neural Motion Planner(NMP)[33]通过使用端到端训练的深度神经网络扩展了MMP在运动规划问题的应用,以生成用于轨迹评分的代价体(cost volume)。最终的输出表示是非参数形式的时空联合代价体(time-space cost volume)(在pytorch下是一个NxNxT的tensor,N是range,T是时刻),表示SDV在规划范围内可以取用的每个位置在对应时间点的“优度”。
Maximun Margin Loss旨在惩罚偏离人类驾驶轨迹或不安全的轨迹,并鼓励人类驾驶轨迹s̃ 的cost小于其他轨迹sˆ的cost,在NMP中的具体实现如下:
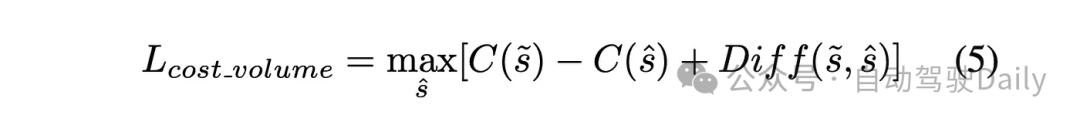
Diff度量作为一个补偿量,用于定量的衡量专家轨迹和其他候选轨迹之间的差异。它旨在反映专家轨迹有效性和候选轨迹的不足,这些优劣性反映在应对如完成规划目标、避开静态障碍和动态交互等规划任务上的具体表现。这使得evaluator能够将相称的cost分配给对应轨迹。而这些候选轨迹往往通过模型生成或通过规则进行采样获得。
对于Diff的定义:
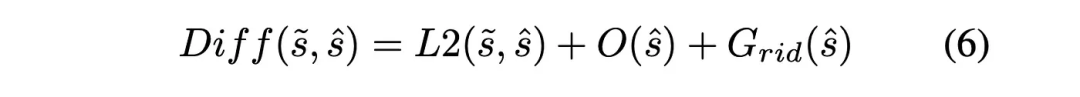
其中O(s)反映了轨迹与感知OCC的碰撞成本,G(s)反映了轨迹与预测的障碍物未来OCC的碰撞成本。模仿损失L2测量了候选轨迹sˆ和专家轨迹s̃之间的欧氏距离。
Raquel Urtasun的团队探索了一系列在自动驾驶领域应用Maximum Margin Planning的工作。从NMP这一开创性工作开始[33],DSD-Net[34]和P3[35]进行了进一步开发并结合了人工设计的cost和基于学习的cost volunme。在后续工作中,MP3[36]引入了无图方案,而ST-P3[37]探索了基于视觉的输入。此外,Differentiable ray-cast[38]和FF[39]探索了以自车free-space中心的场景表征。

然而,预测整个场景的cost volume是非常浪费资源的,因为只有某些时空区域对自车而言是可达并相关的。(假设我们需要预测+-50m范围未来3s的cost volume,如果选取resolution为0.1m/pix,那么需要构造一张大小为500x500x30的tensor)
局限性与问题:这种方法受到其计算和内存需求的限制,这反过来又限制了输出分辨率(例如,它只允许大的时间间隔和短的规划范围),因此只能评估较短时间段的轨迹如3s,对于8s的轨迹需要增大采样间隔。
为了克服这种局限性,Quad[40]引入了基于查询的cost volume,其中cost volume是隐式的设计,每条轨迹对应的cost是通过query获得的:
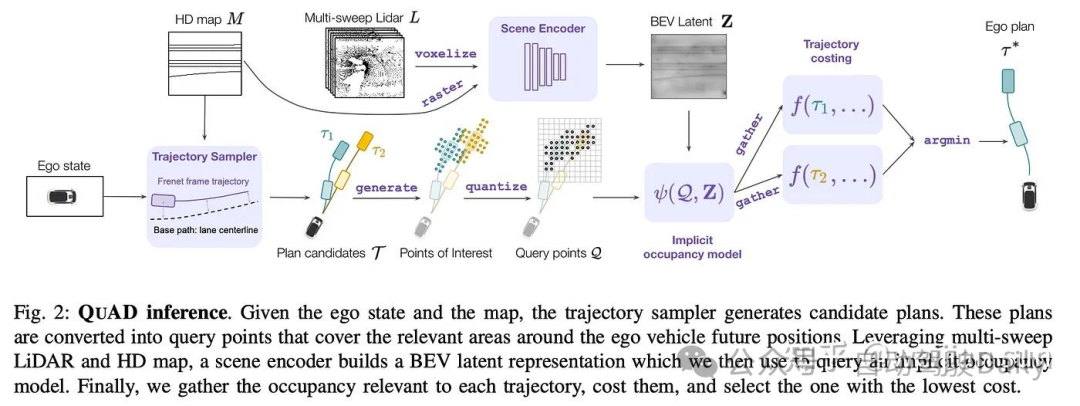
(iii) Trajectory Proposer:
当给定学习到的奖励函数后,可以通过最小化相应的成本函数来计算最终的最优轨迹。然而,这类优化问题在引入车辆动力学的情况下是NP-hard的[33]。大多数方案选择先通过采样的方式生成一堆满足车辆动力学的候选轨迹,再根据IRL学习到的cost volume或reward function找到cost最低的轨迹作为最终输出。
轨迹的采样和生成算法可大致分为基于参考线(reference line)的方案和无参考线的方案,其中由于reference line在时序上是具备稳定性的,引入了参考线方法从结果层面上更能保证模块帧间输出的一致性,带来更舒适的实车体感表现。
(a) Lattice Sampler
Lattice[41]是一种基于参考线的采样方法,它使用五次多项式(quintic polynomials)和四次多项式(quartic polynomials)来表示纵向和横向轨迹。具体来说,通过使用一组初始条件[S(t1), t1]和结束条件[S(tn), tn]求解并拼接得到轨迹。
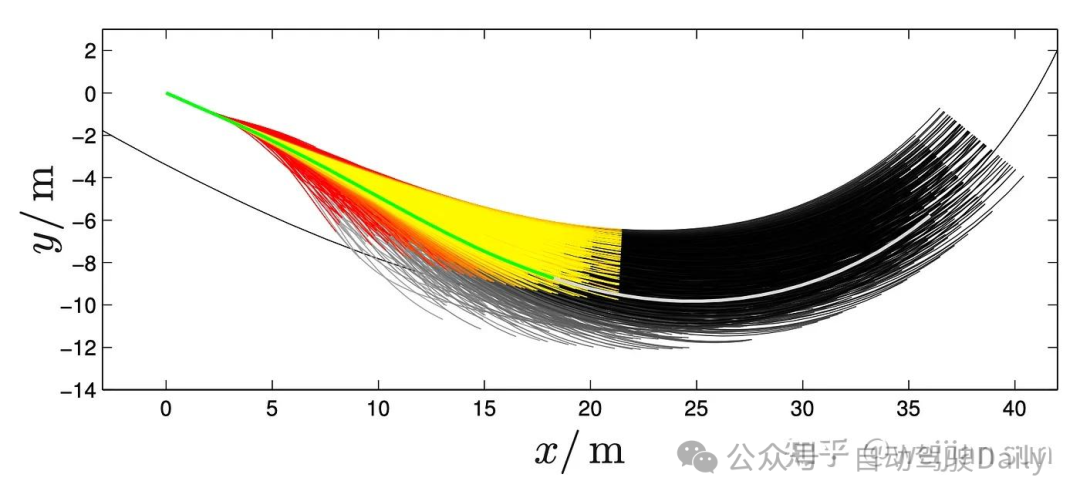
上图是在全局坐标系中得到的的轨迹集,用于基本的车道保持与速度保持功能。
对于涉及引入前方障碍物的跟车和超车情况下的运动规划行为,需要引入速度规划能力,这一般是通过在S-T图上采样实现,S-T图描绘了车辆随时间对车道的占用情况。通过分析S-T图,可以在未占用区域内对结束状态进行采样,标记为红色(用于超车)和蓝色(用于跟车),从而通过求解五次多项式来得到对应的纵向轨迹。
我强烈建议参考一下Apollo对Lattice Planner的实现来了解其中的细节(https://github.com/ApolloAuto/apollo/tree/master/modules/planning/planners/lattice)
事实上,大多数学术工作中采用的是基于Lattice的简化版本,只保留了车道保持或跟车等基本功能,如P3[35][42]和Quad[40]中的基于车道的采样器、[28]中的多项式轨迹和DriveIRL[26]中的轨迹生成器。
(b) Clothoid Curve
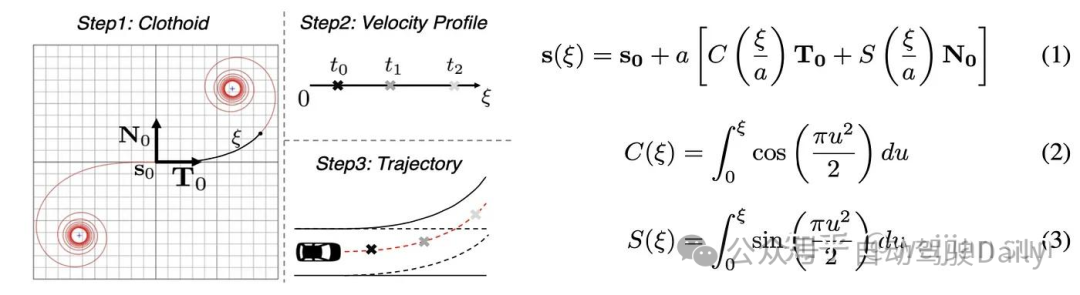
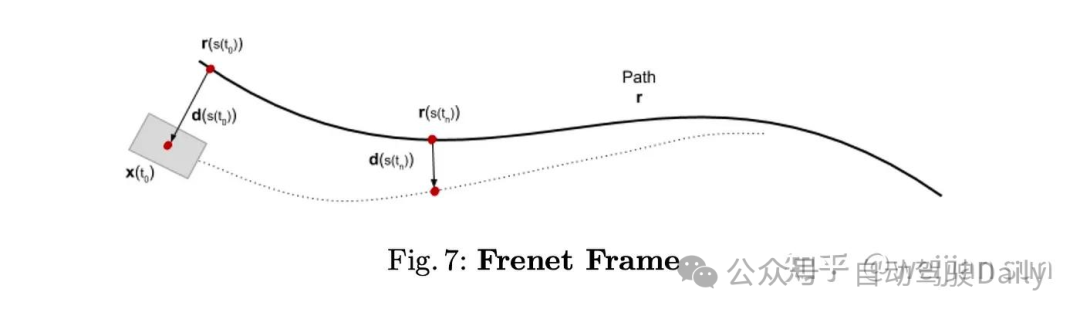
回旋曲线(Clothoid Curve),也称为欧拉螺旋或科努螺旋,可用于表示SDV的二维路径。对于自行车模型,这种线性曲率可以反映以恒定角速度与前轮角度间的关系。Clothoid的规范形式在上图中定义。S(ξ)和C(ξ)是Fresnel integral,T0和N0是该曲线的切线向量和法向量。
Clothoid Curve主要用于为无图的场景提供候选轨迹,在这类场景往往假设无法获取到reference line相关信息,无论是来自于地图或视觉车道线,NMP[33]、ST-P3[37]、FF[39]、Raycast[38]。
(c) Retrieve-based Sampler/Vocabulary
基于检索的采样器(Retrieve-based Sampler)(后来的工作VADv2[43],Hydra MDP[44]称之为词汇表(Vocabulary))是另一种无参考线的采样方法,它也不依赖于地图或车道信息来生成轨迹。最早由MP3[36]提出,用于无图驾驶。它从预先建立的专家轨迹数据集中检索一组初始状态接近ADV当前状态的轨迹。此类数据集通常使用k-means等聚类算法构建,以过滤掉高度相似的候选对象。
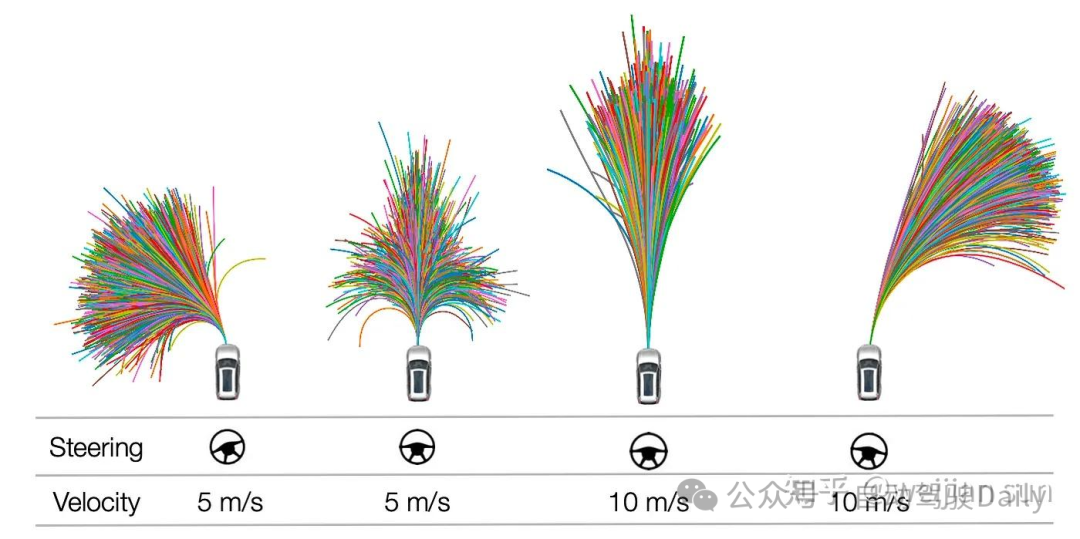
上图显示了从专家演示中检索到的轨迹集。SDV的初始状态用于查询类似开始状态的轨迹。
检索的采样器的局限性与问题: 聚类算法对连续的轨迹空间进行离散化,这类方式得到的轨迹当部署在闭环中接入控制器时,会导致频繁的抖动(jerk)(帧间稳定性较差)。
IRL的局限性与问题: IRL学习的是奖励函数(r)而不是策略(p),因此整个系统的上限受限于通过规则采样到的轨迹的质量。
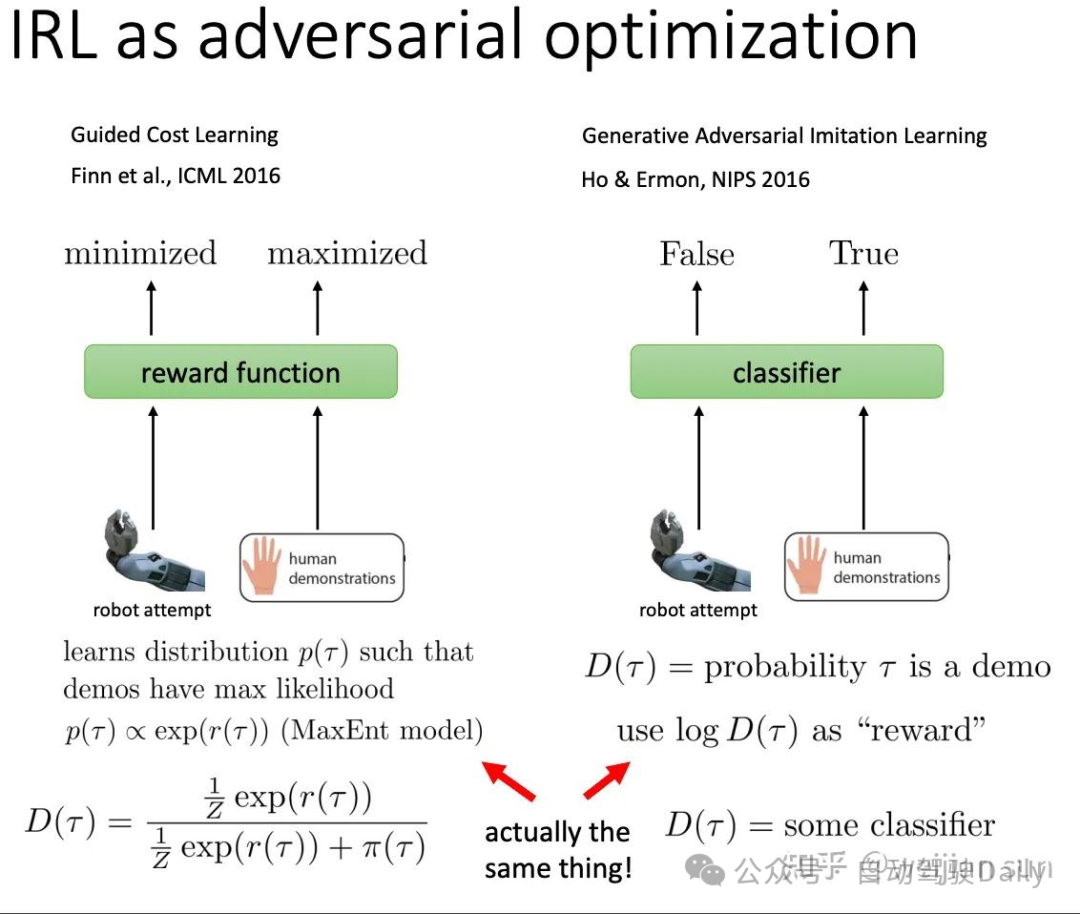
3. 生成对抗式模仿学习 GAIL & GCL
生成对抗式模仿学习(GAIL)[45]是NIPS16的相关工作,与其在数学形式上等价的Guilded Cost Learning[56](又称Inverse Optimal Control)也是是ICML16的相关工作,这两项工作基本上是同时提出的。
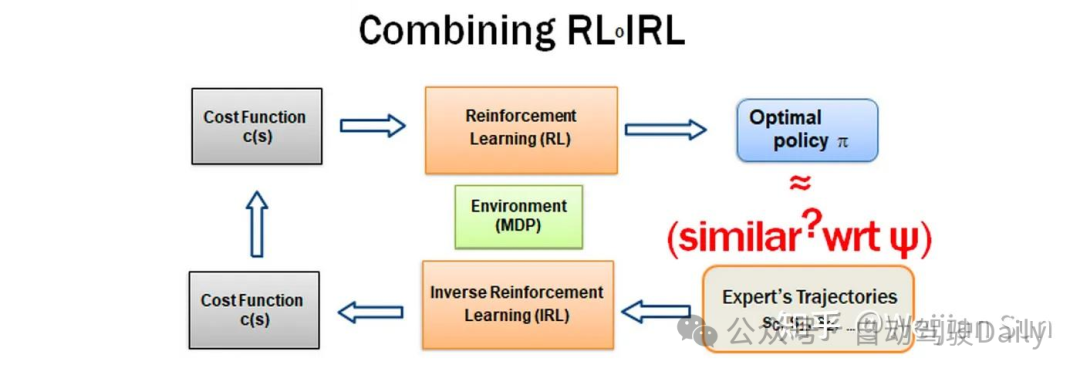
GAIL提出了一种新的通用框架将IRL于RL串联成环,用于直接从数据中提取策略。它是在IRL之后使用RL学习IRL的reward来获得policy,然后使用minimax策略迭代优化IRL与RL。确切地说,GAIL在学习policy的同时训练了一个判别器(Discriminator),这个判别器旨在将专家轨迹与学习策略中的轨迹区分开来并push生成器输出更逼真的轨迹,思路与GAN网络基本一致。
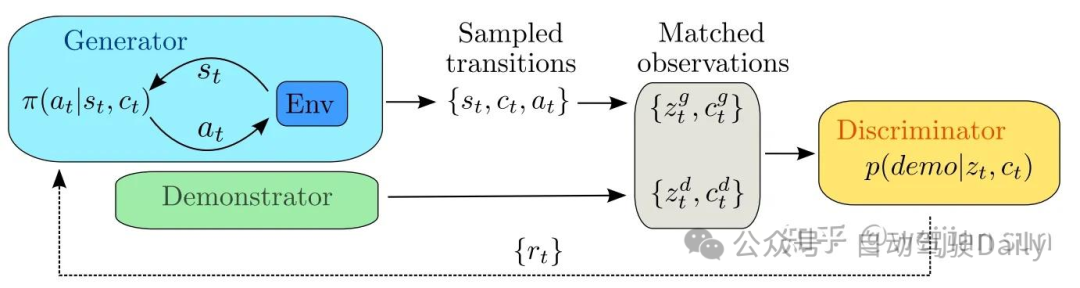
上图描述了GAIL框架,其中添加了用于生成多模态策略的context variable c。类似于GAN网络生成器中的随机变量z,GAIL同样依赖一个随机策略π(a|s,c)通过与环境产生交互生成用于表征轨迹的state-action pair。其中我们假设专家数据与生成的数据位于相同的的特征空间中。他们被一同送入Discriminator进行评估,Discriminator会给出他们为真实数据的概率。同时Discriminator为Generator的policy提供reward function并将reward回传给Generator。
当把GAIL用于motion planning时,我们需要让Generator输出一种规划策略或规划轨迹,使Discriminator无法区分这一策略或轨迹到底来自专家演示还是由Generator学习到的策略生成的行为。相关的工作[47]已经证明,与行为克隆相比,GAIL可以有效的减少复合误差(compounding error),因此具有更好的样本复杂性。
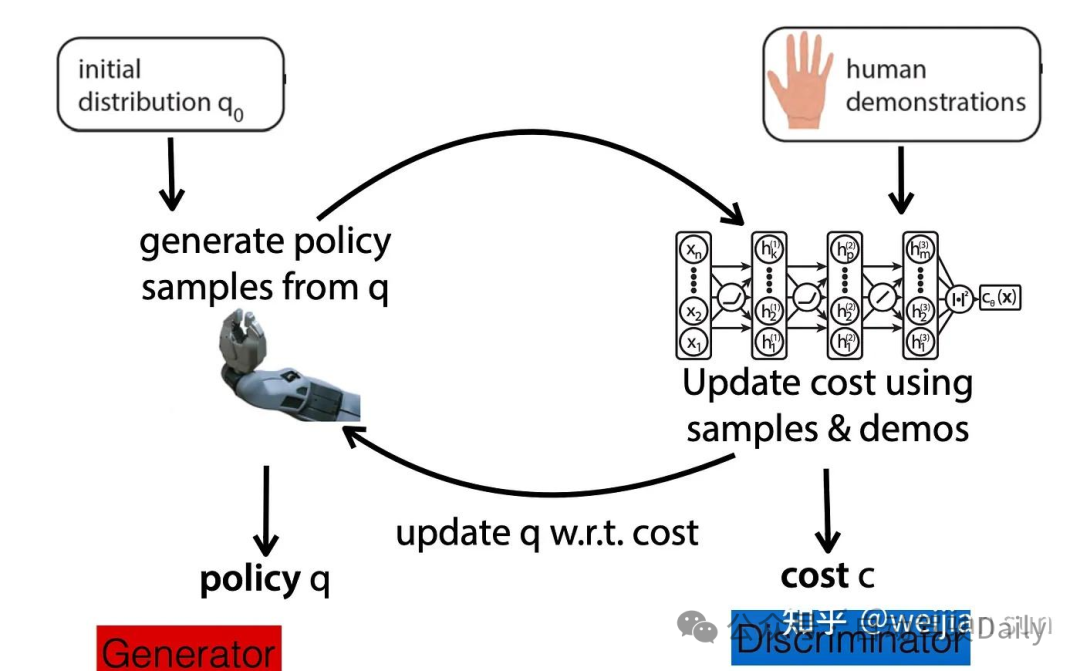
实际上,GAIL在数学上的表达公示与Guilded Cost Learing(GCL)是一致的。[46]证明了基于采样的MaxEnt IRL和GAN之间的等价性。这一的工作将GAN解释为训练MaxEnt-IRL的一种方式。我强烈建议观看Levine的课程以了解详其中的细节(https://youtu.be/ubwJh6jx4Dc?si=22GWfhV51_APiWTH).
GAD[4]这一工作通过实车闭环验证了GAIL在运动规划领域应用的可行性。但是在这一方案中,在GAN的训练中,即没有使用MaxEnt IRL也没用二元分类器做为GAN的Discriminator,而是选择了Maximum Margin Planning来回归奖励函数。同时,在他们的实现中Discriminator给出的cost 是通过在cost volume 上进行双线性插值来回传给generator的。GAD的generator与evaluator的learning target 如下:
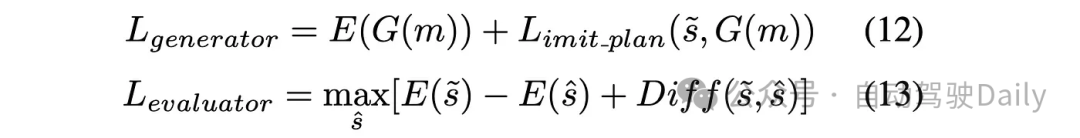
E(G(m))这一项确保了生成的轨迹符合给定的场景,并遵守其他交通参与者以及地图元素施加的额外约束。
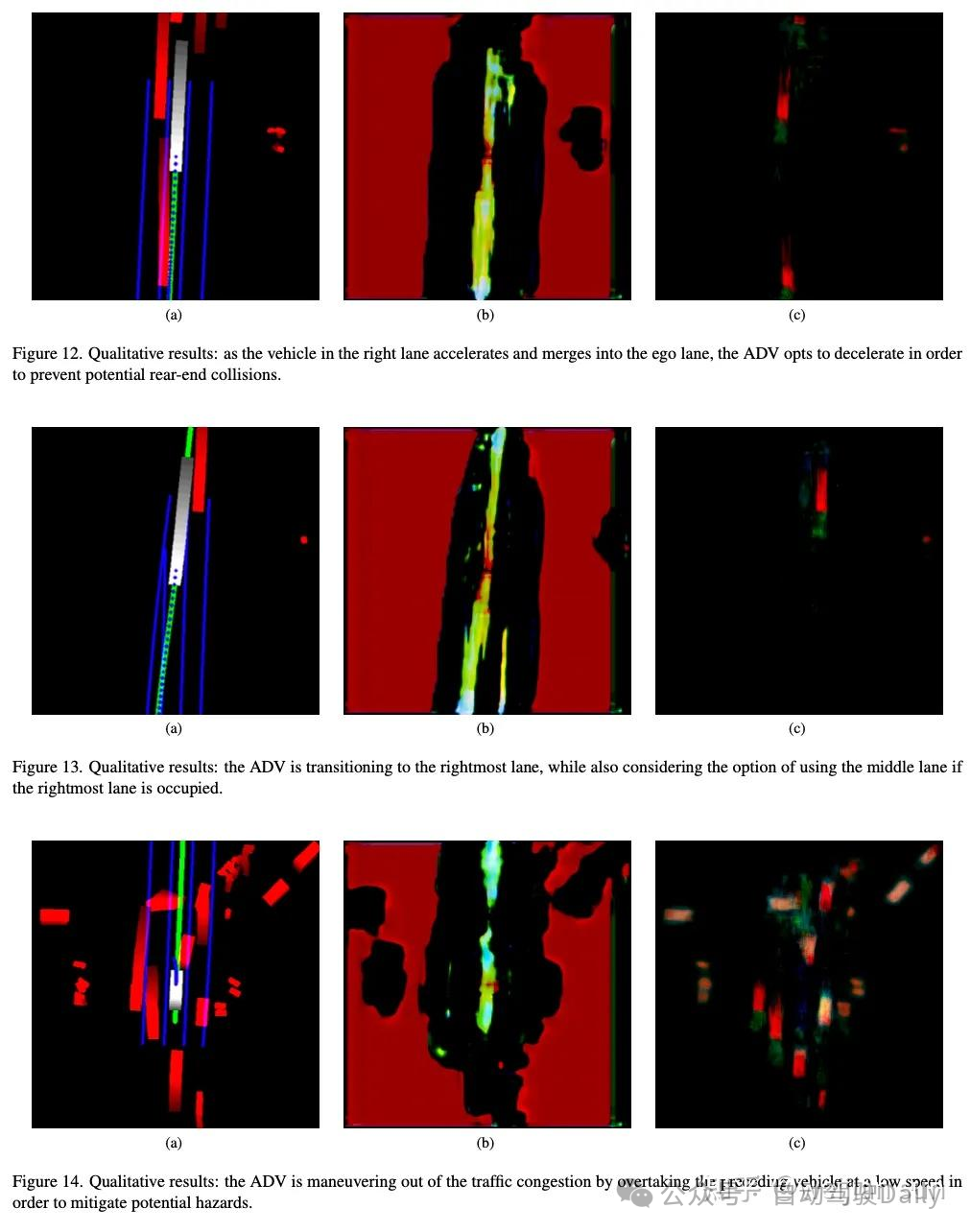
下图显示了GAD学习的cost volume和对应的cost最低的规划轨迹:
GAIL的问题与局限性:GAN的训练较为不稳定且难以收敛,需要引入较多的训练策略。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









