






点击下方卡片,关注“自动驾驶之心”公众号
随着科技浪潮推动自动驾驶迈向新高度,扩散模型的相关工作开始和自动驾驶融合。在此,我们深入剖析15项关键技术,融合学术深度与市场潜力,为您呈现一幅全面且极具吸引力的自动驾驶技术全景图,开启智能交通新时代的探索之旅。本文内容均出自『自动驾驶之心知识星球』,欢迎加入交流。这里已经汇聚了近4000名自动驾驶从业人员,每日分享前沿技术、行业动态、岗位招聘、大佬直播等一手资料!

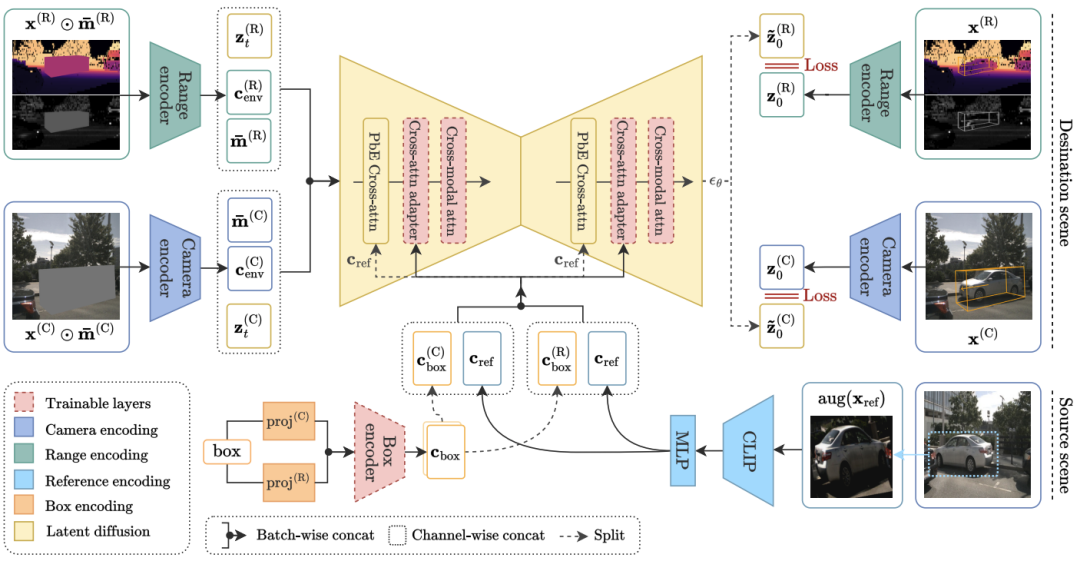
1、 题目: MObI: Multimodal Object Inpainting Using Diffusion Models
链接: https://t.zsxq.com/gREro
简介: MObI: 一种新的多模态目标修补框架
时间: 2025-01-10T23:43:33.210+0800
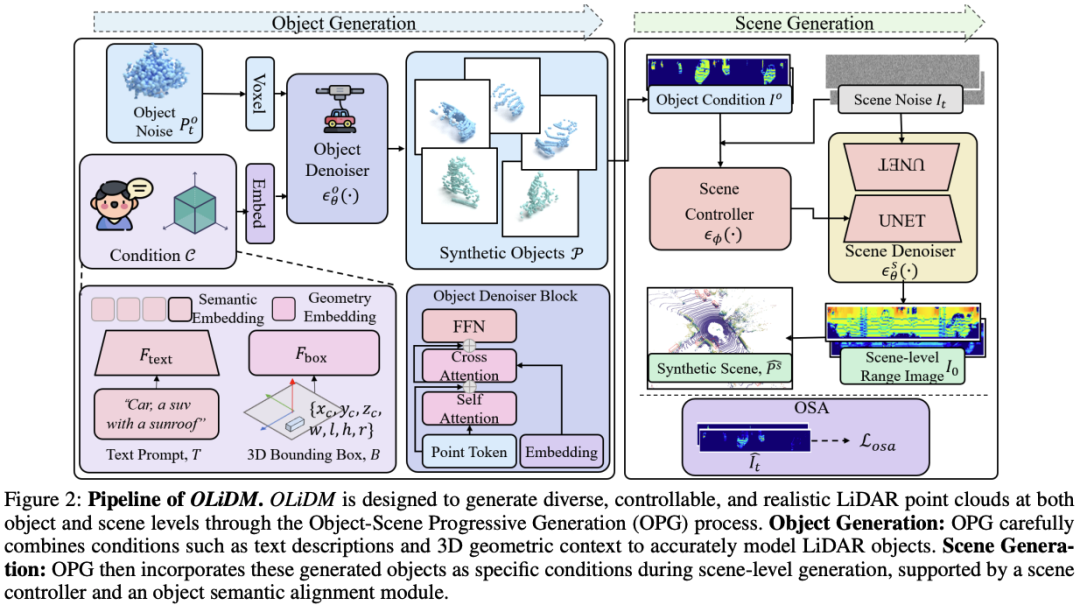
2、 题目: OLiDM: Object-aware LiDAR Diffusion Models for Autonomous Driving
链接: https://t.zsxq.com/sckRZ
简介: OLiDM: 用于自动驾驶的目标感知激光雷达扩散模型,能够在目标和场景层面生成高保真度的LiDAR数据
时间: 2024-12-24T22:04:49.879+0800
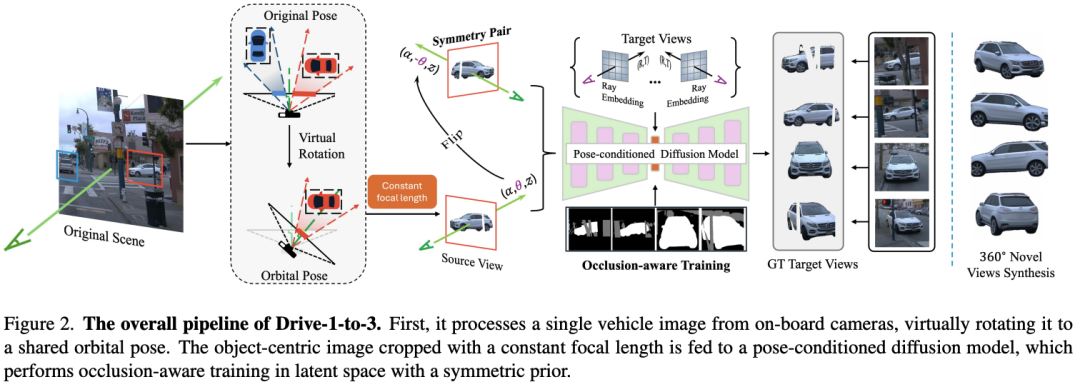
3、 题目: Drive-1-to-3: Enriching Diffusion Priors for Novel View Synthesis of Real Vehicles
链接: https://t.zsxq.com/bVqng
简介: 为自动驾驶应用采集车辆资产!Drive-1-to-3: 丰富扩散先验的实车新视图合成方法
时间: 2024-12-24T21:31:10.064+0800
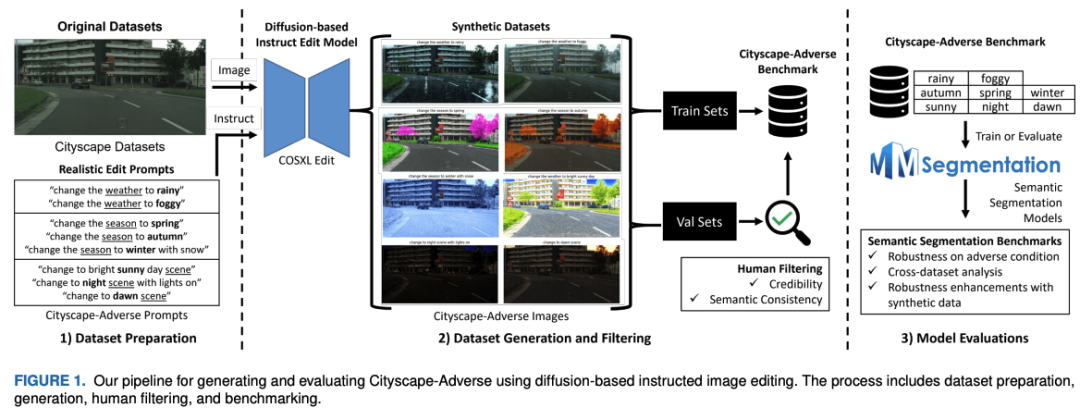
4、 题目: Cityscape-Adverse: Benchmarking Robustness of Semantic Segmentation with Realistic Scene Modifications via Diffusion-Based Image Editing
链接: https://t.zsxq.com/vxgEI
简介: 自动驾驶城市合成数据集又有新点子!Cityscape-Adverse:利用基于扩散的图像编辑来模拟八种不利条件(包括天气、光照和季节变化)的基准,同时保持原始语义标签
时间: 2024-11-04T21:42:20.465+0800
5、 题目: Planning-Aware Diffusion Networks for Enhanced Motion Forecasting in Autonomous Driving
链接: https://t.zsxq.com/ritCH
简介: 用于增强自动驾驶运动预测的规划感知扩散网络
时间: 2024-10-29T21:49:16.252+0800
6、 题目: A Comprehensive Survey on Diffusion Models and Their Applications
链接:https://t.zsxq.com/qeMkq
简介: 扩散模型及其应用全面综述
时间: 2024-08-24T10:09:09.310+0800
7、 题目: Diffusion Models in Low-Level Vision: A Survey
链接: https://t.zsxq.com/I3NiN
简介: 首个围绕低层次视觉任务中去噪扩散模型技术全面综述
时间: 2024-06-19T20:02:05.329+0800
8、 题目: Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
链接:https://t.zsxq.com/19Tk0YN2a
简介: Light the Night: 一种用于自动驾驶中非配对微光增强的多条件扩散框架
时间: 2024-04-09T22:33:56.459+0800
9、 题目: SemCity: Semantic Scene Generation with Triplane Diffusion
链接: https://t.zsxq.com/19IDwoc8f
简介: CVPR 2024
时间: 2024-03-14T07:46:56.166+0800
10、 题目: SyntheOcc: Synthesize Geometric-Controlled Street View Images through 3D Semantic MPIs
链接: https://t.zsxq.com/Rma4v
简介: SyntheOcc: 通过扩散模型生成的系统,它通过在驾驶场景中以占据标签为条件来合成真实感和几何控制的图像
时间: 2024-10-02T23:39:56.904+0800
11、 题目: StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
链接: https://t.zsxq.com/ITFnD
简介: Waymo Open Dataset和PandaSet效果超越现有方法!StreetCrafter:一种新型的可控自动驾驶街景合成视频扩散模型
时间: 2024-12-18T18:58:46.236+0800
12、 题目: DepthMaster: Taming Diffusion Models for Monocular Depth Estimation
链接:https://t.zsxq.com/IqaOV
简介: DepthMaster,一种单步扩散模型,旨在将生成特征适应于判别性深度估计任务
时间: 2025-01-07T22:51:22.837+0800
13、 题目: DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
链接: https://t.zsxq.com/ksyTW
简介: DiffMap:一种专门设计用于使用潜在扩散模型建模地图分割掩模的方法
时间: 2024-05-06T21:44:36.118+0800
14、 题目: Diffusion Models in 3D Vision: A Survey
链接: https://t.zsxq.com/GgYqH
简介: 扩散模型在3D视觉中的算法及应用全面综述
时间: 2024-10-08T21:21:17.440+0800
15、 题目:BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
链接:https://t.zsxq.com/Z6viN
简介:一种基于扩散模型的新型方法,利用地面真值物体布局作为引导,有效去除BEV噪声。其可控的BEV生成能力为自动驾驶数据增强与场景仿真提供了新思路。
『自动驾驶之心知识星球』,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知、端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入~


















 187
187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









