






点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享CVPR 2025自动驾驶方向中稿的工作,列表持续更新中!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『CVPR 2025』技术交流群
CVPR 2025录用结果出炉!!!今年,共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。这其中有很多优秀的自动驾驶工作,今天自动驾驶之心就和大家分享CVPR'25自动驾驶方向中稿的相关工作,列表持续更新中...
从中稿方向上看,论文集中在端到端、闭环仿真3DGS、多模态大模型、扩散模型这些前沿方向。预计今年工业界和学术界也是这些方向重点发力,一起加油!
相关工作已第一时间上传至《自动驾驶之心知识星球》,欢迎加入国内最专业的自动驾驶社区!技术分享、求职招聘、行业交流、前沿直播一键直达!

UniScene: Unified Occupancy-centric Driving Scene Generation
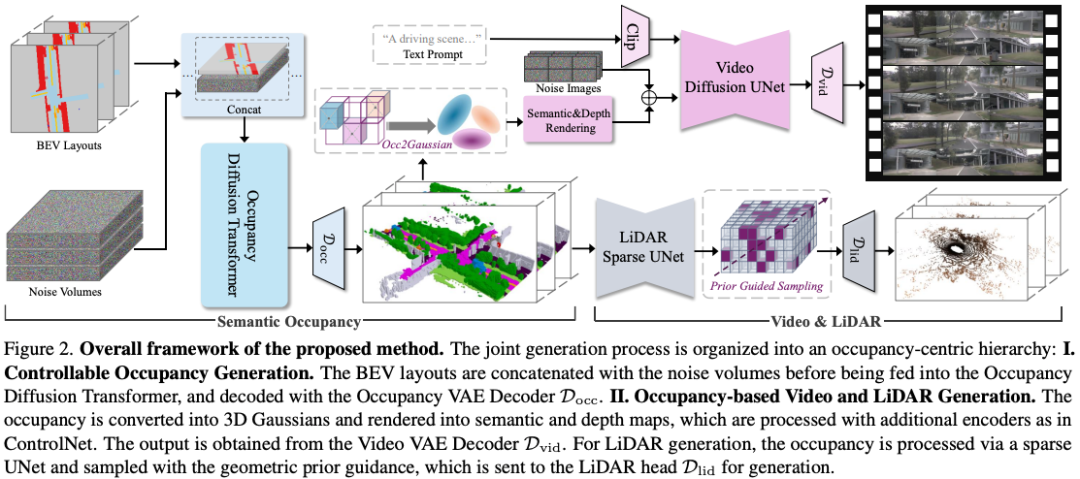
上交、中国东方理工大学宁波数字孪生研究所以及清华赵昊老师团队的工作:生成高保真、可控和带注释的训练数据对于自动驾驶至关重要。现有的方法通常直接从粗略的场景布局生成单个数据表单,这不仅无法输出各种下游任务所需的丰富数据表单,而且难以对直接布局到数据分布进行建模。本文介绍了UniScene,这是第一个在驾驶场景中生成三种关键数据形式(语义占用、视频和LiDAR)的统一框架。UniScene采用渐进式生成过程,将场景生成的复杂任务分解为两个层次步骤:(a)首先从定制的场景布局中生成语义占用,作为富含语义和几何信息的元场景表示,然后(b)根据占用情况,分别生成视频和LiDAR数据,采用基于高斯的联合渲染和先验引导稀疏建模这两种新的传输策略。这种以占用为中心的方法减少了生成负担,特别是对于复杂的场景,同时为后续生成阶段提供了详细的中间表示。大量实验表明,UniScene在占用率、视频和激光雷达生成方面优于之前的SOTA,这也确实有利于下游驾驶任务。
论文链接:https://arxiv.org/abs/2412.05435
项目主页:https://arlo0o.github.io/uniscene/
Don't Shake the Wheel: Momentum-AwarePlanning in End-to-End Autonomous Driving
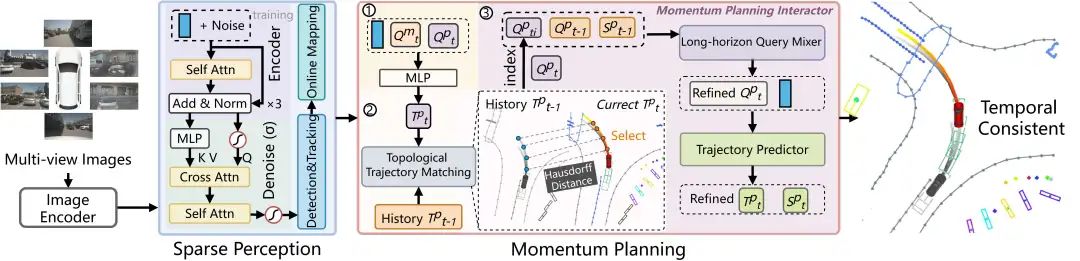
端到端的自动驾驶框架促进了感知和规划的无缝集成,但通常依赖于一次性轨迹预测,缺乏时间一致性和长期意识。这种限制可能会导致控制不稳定、不理想的偏移,以及在单帧感知中容易受到遮挡。在这项工作中,本文提出了动量感知驱动(MomAD)框架,通过引入轨迹动量和感知动量来稳定和改进轨迹预测,从而解决这些问题。MomAD由两个关键组件组成:(1)拓扑轨迹匹配(TTM),它使用豪斯多夫距离将预测与先前路径对齐,并确保时间一致性;(2)动量规划交互器(MPI),它将规划查询与历史时空上下文交叉参与。此外,编码器-解码器模块引入特征扰动以提高对感知噪声的鲁棒性。为了量化规划稳定性,本文提出了轨迹预测一致性(TPC)度量,表明MomAD在nuScenes数据集上实现了长期一致性(>3s)。本文进一步策划了具有挑战性的转弯nuScenes验证集,重点关注转弯场景,其中MomAD超越了最先进的方法,突出了其在动态驾驶条件下增强的稳定性和响应性。
项目主页:https://github.com/adept-thu/MomAD
V2X - R: Cooperative LiDAR - 4D Radar Fusion with Denoising Diffusion for 3D Object Detection
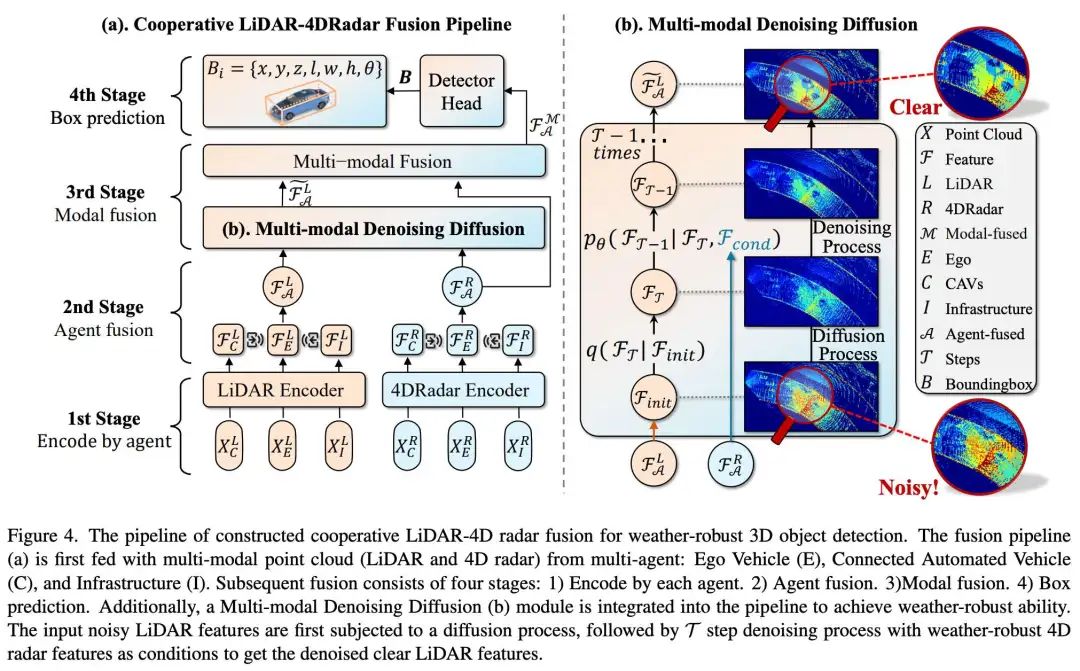
厦门大学、上交及武汉大学等团队的工作:当前的车联网(V2X)系统使用激光雷达和摄像头数据显著增强了3D目标检测。然而,这些方法在恶劣天气条件下性能会下降。Weather-robust 4D雷达提供多普勒和额外的几何信息,提高了应对这一挑战的可能性。为此介绍了V2X-R,这是第一个包含LiDAR、相机和4D雷达的仿真V2X数据集。V2X-R包含12079个场景,其中37727帧激光雷达和4D雷达点云、150908张图像和170859个带注释的3D车辆边界框。随后,本文提出了一种新的用于3D目标检测的协同LiDAR-4D雷达融合流pipeline,并采用各种融合策略来实现。为了实现天气鲁棒检测,本文在融合管道中还提出了一个多模态去噪扩散(MDD)模块。MDD利用天气鲁棒性4D雷达特征作为条件,促使扩散模型对噪声LiDAR特征进行去噪。实验表明,本文的LiDAR-4D雷达融合流水线在V2X-R数据集中表现出卓越的性能。除此之外,本文的MDD模块在雾/雪条件下将基本融合模型的性能进一步提高了5.73%/6.70%,几乎不会干扰正常性能。
论文链接:https://arxiv.org/abs/2411.08402
项目主页:https://github.com/ylwhxht/V2X-R
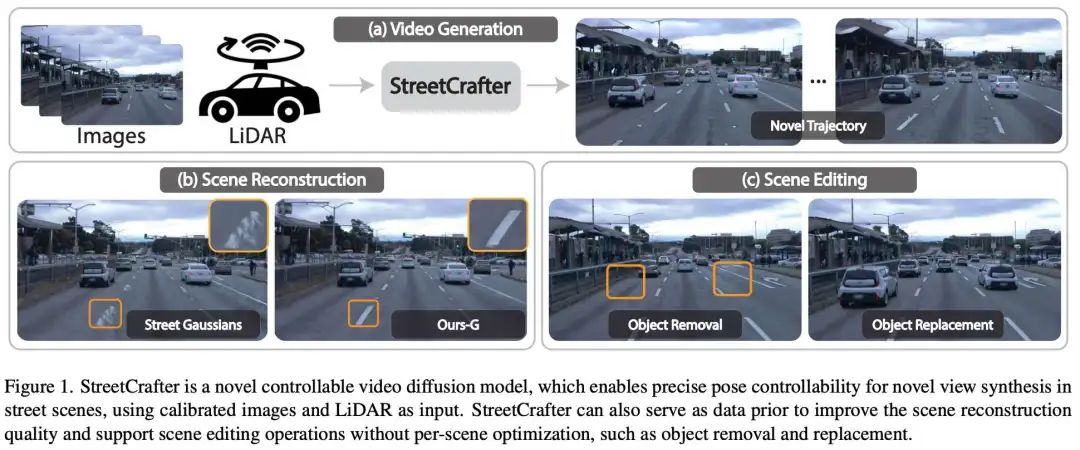
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
浙大、理想和康奈尔大学团队的工作:本文旨在解决从车辆传感器数据中合成逼真视图的问题。神经场景表示的最新进展在渲染高质量的自动驾驶场景方面取得了显著成功,新视角性能会显著下降。为了缓解这个问题,本文引入了StreetCrafter,这是一种新颖的可控视频扩散模型,它利用LiDAR点云渲染作为像素级条件,充分利用生成先验进行新颖的视图合成,同时保持精确的相机控制。此外,像素级激光雷达条件的利用使本文能够对目标场景进行精确的像素级编辑。此外,StreetCrafter的生成先验可以有效地整合到动态场景表示中,以实现实时渲染。在Waymo Open Dataset和PandaSet上的实验表明,本文的模型能够灵活控制视点变化,扩大视图合成区域以满足渲染需求,优于现有方法。
论文链接:https://arxiv.org/abs/2412.13188
项目主页:https://zju3dv.github.io/street_crafter/
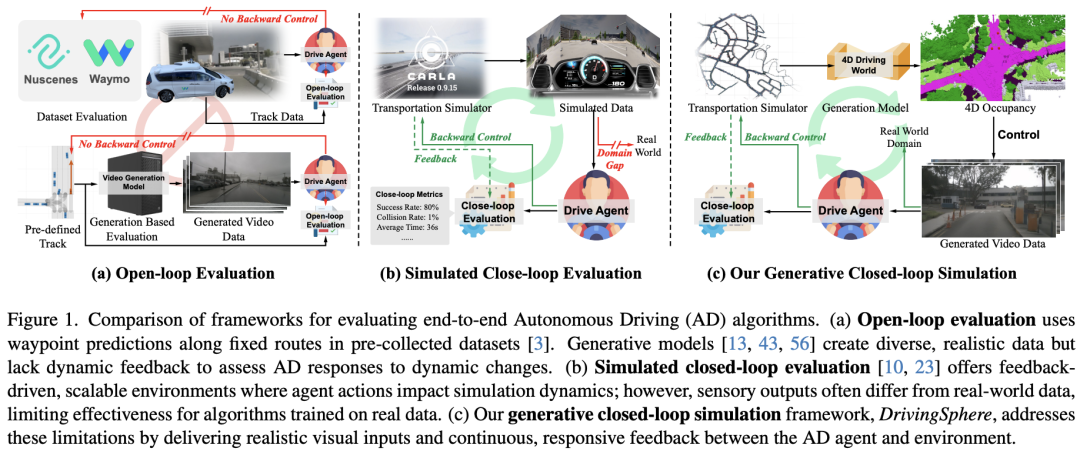
DrivingSphere: Building a High-fidelity 4D World for Closed-loop Simulation
澳门大学、理想和北理工团队的工作:自动驾驶评估需要模拟环境来密切复制实际路况,包括真实世界的感官数据和响应反馈回路。然而,许多现有的模拟需要在公共数据集或合成照片级真实感数据上预测固定路线上的航路点,即开环模拟通常缺乏评估动态决策的能力。虽然闭环仿真的最新努力提供了反馈驱动的环境,但它们无法处理视觉传感器输入或产生与现实世界数据不同的输出。为了应对这些挑战,本文提出了DrivingSphere,这是一个现实的闭环仿真框架。其核心思想是构建4D世界表示,并生成现实生活中可控的驾驶场景。具体来说,本文的框架包括一个动态环境合成模块,该模块以配备静态背景和动态对象的占用格式构建了一个详细的4D驾驶世界,以及一个视觉场景合成模块,将这些数据转换为高保真、多视图视频输出,确保空间和时间的一致性。通过提供动态和逼真的仿真环境,DrivingSphere能够对自动驾驶算法进行全面的测试和验证,最终推动更可靠的自动驾驶汽车的发展。
论文链接:https://arxiv.org/abs/2411.11252
项目主页:https://yanty123.github.io/DrivingSphere/
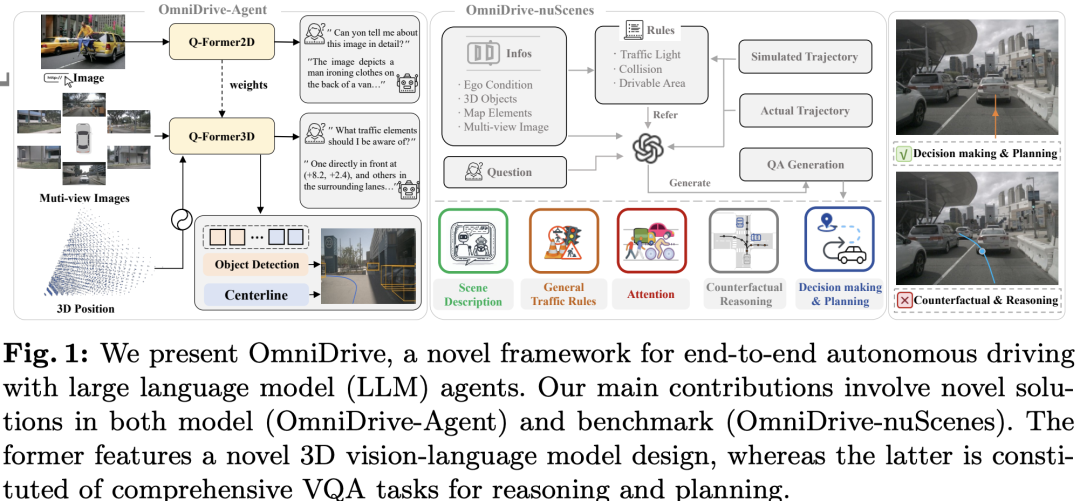
OmniDrive: A Holistic Vision - Language Dataset for Autonomous Driving with counter Factual Reasoning
北理工、英伟达和华科团队的工作:多模态大型语言模型(MLLM)的进步导致人们对基于LLM的自动驾驶代理越来越感兴趣,以利用其强大的推理能力。然而,利用MLLM强大的推理能力来改善规划行为是具有挑战性的,因为规划需要超越2D推理的完全3D态势感知。为了应对这一挑战,我们的工作提出了一个整体框架,用于在代理模型和3D驱动任务之间进行强对齐。我们的框架从一种新颖的3D MLLM架构开始,该架构使用稀疏查询将视觉表示提升并压缩为3D,然后再将其输入LLM。这种基于查询的表示允许我们联合编码动态对象和静态地图元素(例如交通车道),为3D中的感知-动作对齐提供一个压缩的世界模型。我们进一步提出了OmniDrive nuScenes,这是一种新的视觉问答数据集,通过全面的视觉问答(VQA)任务,包括场景描述、交通规则、3D基础、反事实推理、决策和规划,挑战了模型的真实3D情境感知。广泛的研究表明了所提出架构的有效性,以及VQA任务在复杂3D场景中推理和规划的重要性。
论文链接:https://arxiv.org/abs/2405.01533
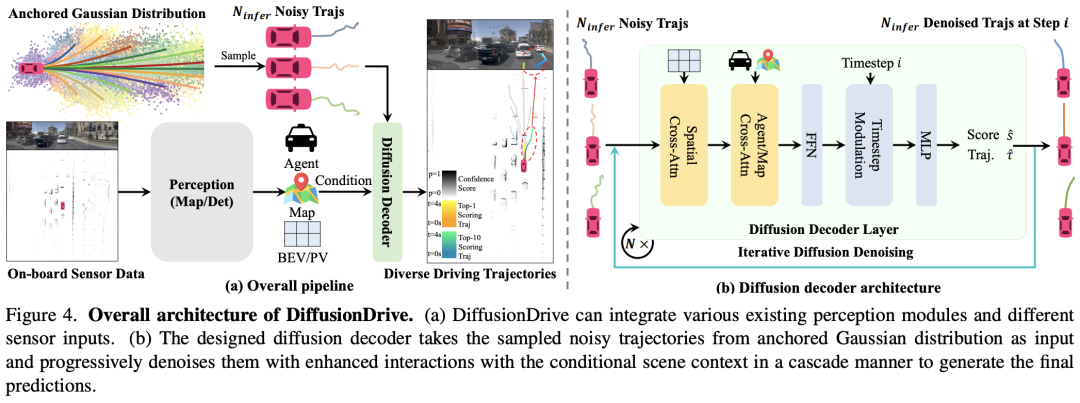
DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving
华科和地平线的工作:最近扩散模型已经成为一种强大的机器人策略学习生成技术,能够对多模式动作分布进行建模。利用其端到端自动驾驶能力是一个有前景的方向。然而,机器人扩散策略中的众多去噪步骤以及交通场景更动态、更开放的世界性质,对实时生成各种驾驶行为构成了重大挑战。为了应对这些挑战,我们提出了一种新的截断扩散策略,该策略结合了先前的多模式锚点并截断了扩散调度,使模型能够从锚定的高斯分布学习去噪到多模式驾驶动作分布。此外,我们设计了一种高效的级联扩散解码器,用于增强与条件场景上下文的交互。所提出的模型DiffusionDrive与香草扩散策略相比,降噪步骤减少了10倍,仅需2步即可提供卓越的多样性和质量。在面向规划的NAVSIM数据集上,使用对齐的ResNet-34骨干网,DiffusionDrive在NVIDIA 4090上以45 FPS的实时速度运行时,实现了88.1 PDMS的无花哨功能,创下了新纪录。对具有挑战性场景的定性结果进一步证实,DiffusionDrive可以稳健地生成各种合理的驾驶行为。
论文链接:https://arxiv.org/abs/2411.15139
开源链接:https://github.com/hustvl/DiffusionDrive
DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation
极佳、中科院、理想、北大等团队的工作:闭环仿真对于推进端到端自动驾驶系统至关重要。当代的传感器仿真方法,如NeRF和3DGS,主要依赖于与训练数据分布紧密一致的条件,这些条件在很大程度上局限于前向驾驶场景。因此,这些方法在渲染复杂的机动动作(如变道、加速、减速)时面临局限性。自动驾驶世界模型的最新进展已经证明了生成多样化驾驶视频的潜力。然而,这些方法仍然局限于2D视频生成,固有地缺乏捕捉动态驾驶环境复杂性所需的时空连贯性。本文介绍了DriveDreamer4D,它利用世界模型先验增强了4D驾驶场景表示。具体来说,我们利用世界模型作为数据机器来合成新的轨迹视频,其中明确利用结构化条件来控制交通要素的时空一致性。此外,还提出了表亲数据训练策略,以促进真实数据和合成数据的合并,从而优化4DGS。据我们所知,DriveDreamer4D是第一个利用视频生成模型来改善驾驶场景中4D重建的公司。实验结果表明,DriveDreamer4D显著提高了新轨迹视图下的生成质量,与PVG、S3Gaussian和Deformable GS相比,FID相对提高了32.1%、46.4%和16.3%。此外,DriveDreamer 4D显著增强了驱动代理的时空一致性,这得到了综合用户研究的验证,NTA-IoU度量的相对增加了22.6%、43.5%和15.6%。
论文链接:https://arxiv.org/abs/2410.13571
项目主页:https://drivedreamer4d.github.io/
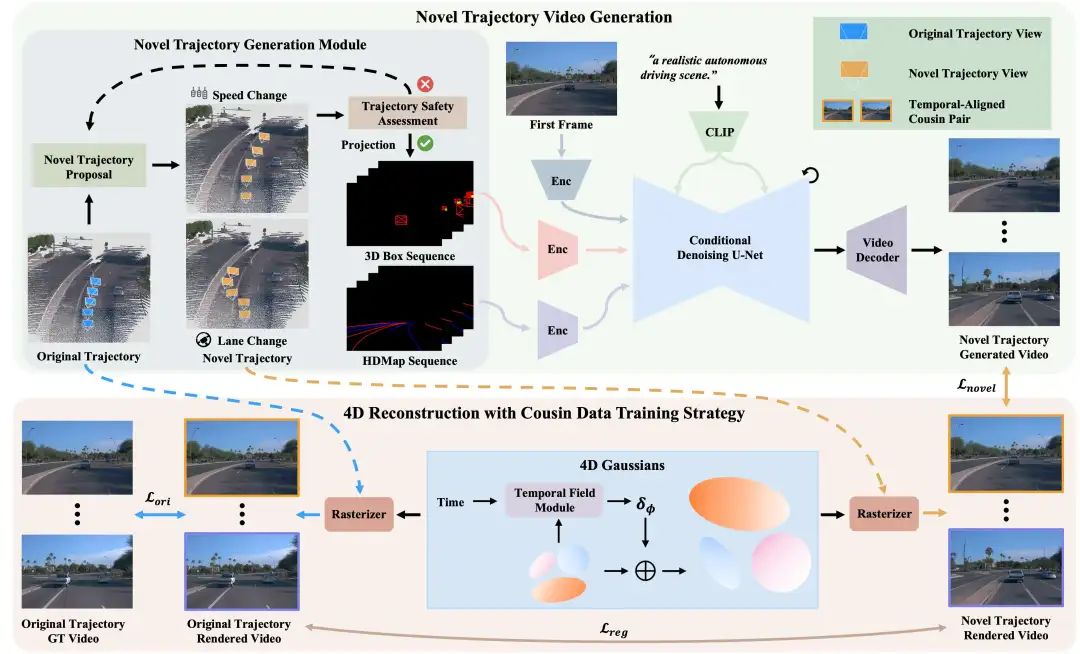
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
极佳、北大、理想等团队的工作:闭环仿真对于端到端自动驾驶至关重要。现有的传感器仿真方法(如NeRF和3DGS)基于与训练数据分布非常接近的条件重建驾驶场景。然而,这些方法在渲染新的轨迹(如车道变换)方面很困难。最近的工作表明,整合世界模型知识可以缓解这些问题。尽管这些方法很有效,但在准确表示更复杂的机动时仍然遇到困难,多车道变换就是一个值得注意的例子。因此,我们引入了ReconDreamer,它通过增量集成世界模型知识来增强驾驶场景重建。具体来说,建议使用DriveRestorer通过在线恢复来减轻伪影。这得到了渐进式数据更新策略的补充,该策略旨在确保为更复杂的机动提供高质量的渲染。据我们所知,ReconDreamer是第一种在大型机动中有效渲染的方法。实验结果表明,ReconDreamer在NTA IoU、NTL IoU和FID中的表现优于Street Gaussian,相对提高了24.87%、6.72%和29.97%。此外,ReconDreamer在大型机动渲染中超过了配备PVG的DriveDreamer4D,NTA IoU指标相对提高了195.87%,一项全面的用户研究也证实了这一点。
论文链接:https://arxiv.org/abs/2411.19548
项目主页:https://recondreamer.github.io/
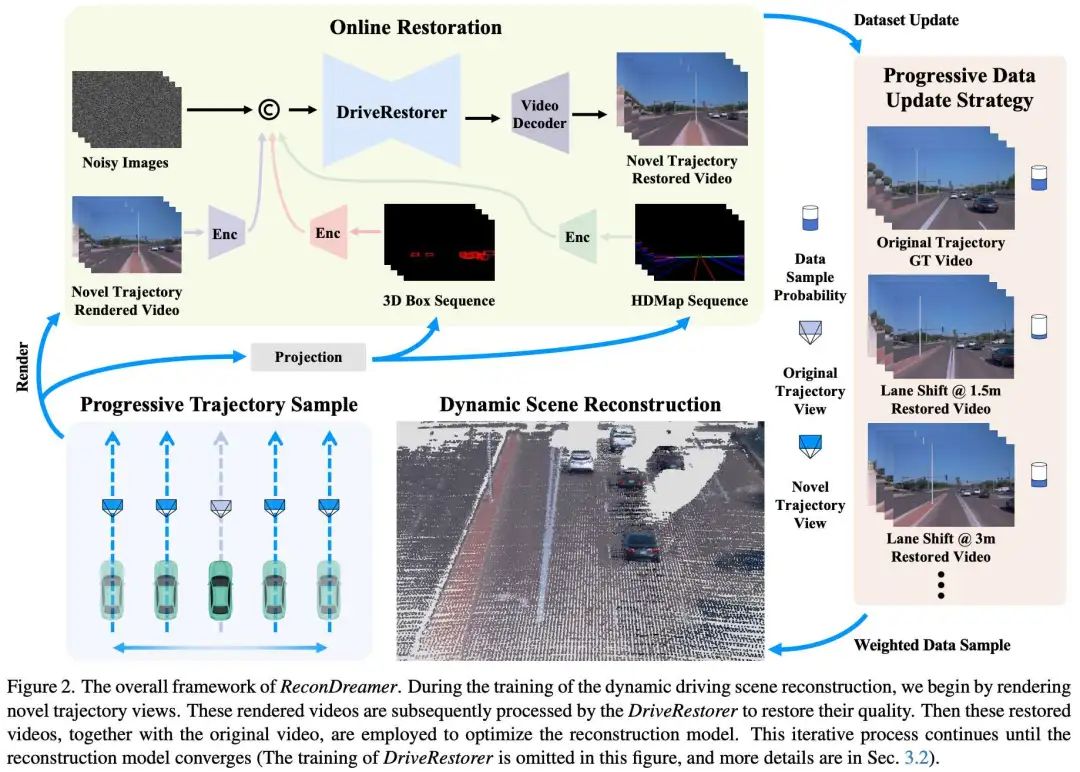
CarPlanner: Consistent Auto-regressive Trajectory Planning for Large-scale Reinforcement Learning in Autonomous Driving
浙大和菜鸟网络的工作:轨迹规划对于自动驾驶至关重要,可确保在复杂环境中安全高效地导航。虽然最近基于学习的方法,特别是强化学习(RL),在特定场景中显示出了希望,但强化学习规划者在训练效率低下和管理大规模、真实世界的驾驶场景方面遇到了困难。在本文中,我们介绍CarPlanner,一个使用RL生成多模态轨迹。自回归结构实现了高效的大规模RL训练,而一致性的结合通过在时间步长上保持连贯的时间一致性来确保稳定的策略学习。此外,CarPlanner采用了一个具有专家指导的奖励函数和不变视图模块的生成选择框架,简化了RL训练并提高了策略性能。广泛的分析表明,我们提出的强化学习框架有效地解决了训练效率和性能提升的挑战,将CarPlanner定位为自动驾驶轨迹规划的有前景的解决方案。据我们所知,我们是第一个证明基于RL的规划器可以在具有挑战性的大规模现实世界数据集nuPlan上超越基于IL和基于规则的最新技术(SOTA)的人。我们提出的CarPlanner在这个要求苛刻的数据集中超越了RL、IL和基于规则的SOTA方法。
论文链接:https://arxiv.org/abs/2502.19908
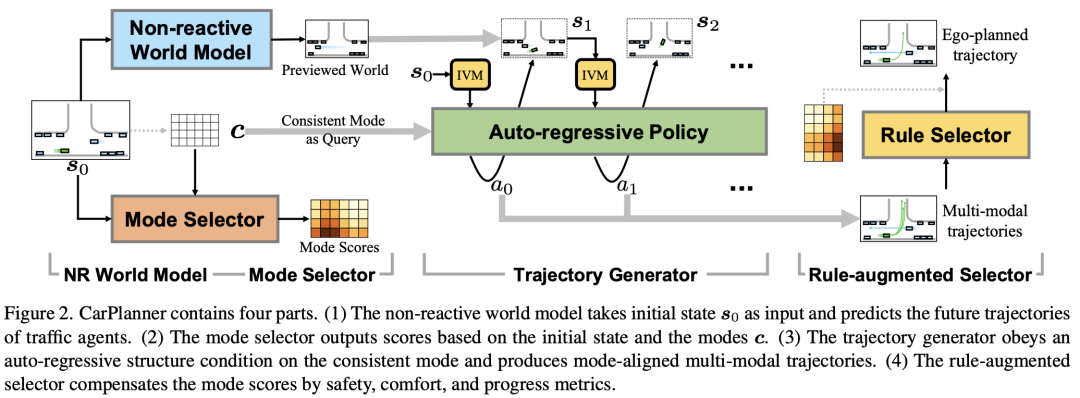
BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
博世北美研究中心和博世人工智能中心的工作:鸟瞰(BEV)表示在自动驾驶任务中起着至关重要的作用。尽管最近在纯电动汽车生成方面取得了进展,但源于传感器限制和学习过程的固有噪声在很大程度上仍未得到解决,导致非最优的纯电动汽车表示,对下游任务的性能产生不利影响。为了解决这个问题,我们提出了BEVDiffuser,这是一种新的扩散模型,它使用地面真实对象布局作为指导,有效地对BEV特征图进行去噪。BEVDiffuser可以在培训期间以即插即用的方式操作,以增强现有的BEV模型,而不需要任何架构修改。在具有挑战性的nuScenes数据集上进行的广泛实验证明了BEVDiffuser出色的去噪和生成能力,这使得现有的BEV模型得到了显著增强,3D对象检测的mAP和NDS分别显著提高了12.3%和10.1%,而不会引入额外的计算复杂性。此外,长尾目标检测以及在恶劣天气和光照条件下的显著改进进一步验证了BEVDiffuser在去噪和增强BEV表示方面的有效性。
论文链接:https://arxiv.org/abs/2502.19694
HybridGS: Decoupling Transients and Statics with 2D and 3D Gaussian Splatting
中科大、浙大和上交团队的工作:在以瞬态对象为特征的场景中生成3D高斯散斑(3DGS)的高质量新颖视图渲染具有挑战性。我们提出了一种新的混合表示方法,称为HybridGS,对每张图像中的瞬态对象使用2D高斯,对整个静态场景保持传统的3D高斯。请注意,3DGS本身更适合对假设多视图一致性的静态场景进行建模,但瞬态对象偶尔出现,不符合假设,因此我们将它们建模为来自单个视图的平面对象,用2D高斯表示。我们的小说表现从基本观点一致性的角度对场景进行了分解,使其更加合理。此外,我们提出了一种新的3DGS多视图监管方法,该方法利用来自共视区域的信息,进一步增强了瞬态和静态之间的区别。然后,我们提出了一种简单而有效的多阶段训练策略,以确保在各种设置下进行稳健的训练和高质量的视图合成。在基准数据集上的实验表明,即使在存在干扰元素的情况下,我们在室内和室外场景中也能实现新颖的视图合成。
论文链接:https://arxiv.org/abs/2412.03844
项目主页:https://gujiaqivadin.github.io/hybridgs/

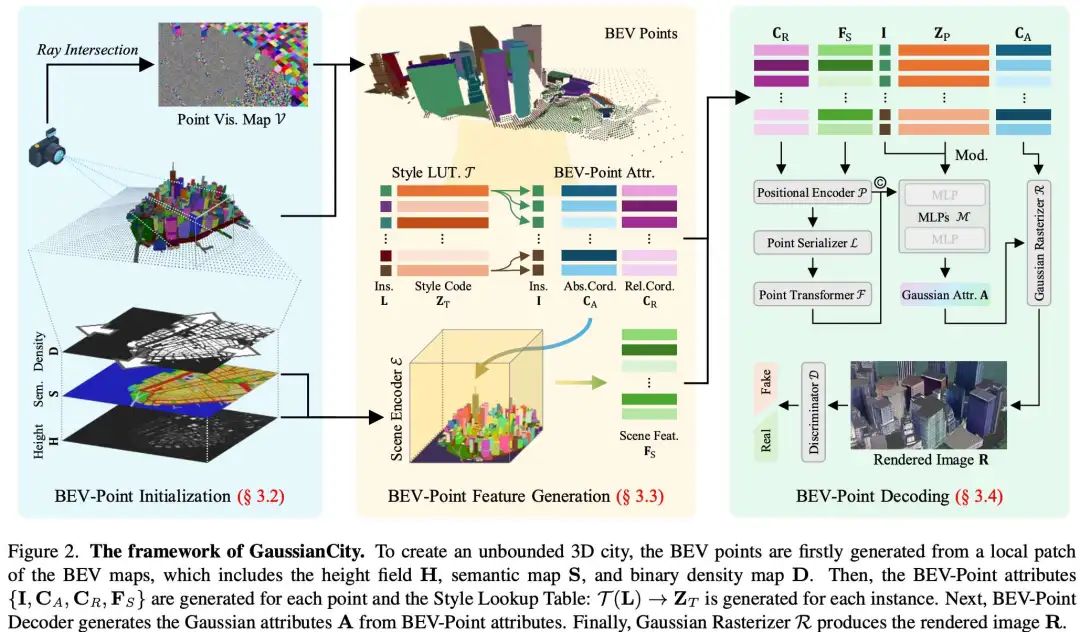
Generative Gaussian Splatting for Unbounded 3D City Generation
南洋理工大学的工作:基于NeRF的3D城市生成方法显示出有前景的生成结果,但计算效率低下。最近,3D高斯散斑(3D-GS)已成为对象级3D生成的高效替代方案。然而,将3D-GS从有限尺度的3D物体和人类适应到无限尺度的3D城市并非易事。无边界的3D城市生成需要大量的存储开销(内存不足问题),这是由于需要将点扩展到数十亿,对于跨度为10km^2的城市场景,通常需要数百GB的VRAM。在这篇论文中,我们提出了GaussianCity,这是一个生成性高斯散布框架,致力于通过单次前馈有效地合成无界的3D城市。我们的关键见解有两个:1)紧凑的3D场景表示:我们引入BEV点作为一种高度紧凑的中间表示,确保无界场景的VRAM使用量的增长保持不变,从而实现无界城市的生成。2) 空间感知高斯属性解码器:我们提出了空间感知BEV点解码器来生成3D高斯属性,该解码器利用点序列化器来整合BEV点的结构和上下文特征。大量实验表明,GaussianCity在无人机视图和街景3D城市生成方面都取得了最先进的成果。值得注意的是,与CityDreamer相比,GaussianCity表现出卓越的性能,速度提高了60倍(10.72 FPS vs.0.18 FPS)。
论文链接:https://arxiv.org/abs/2406.06526
项目主页:https://haozhexie.com/project/gaussian-city
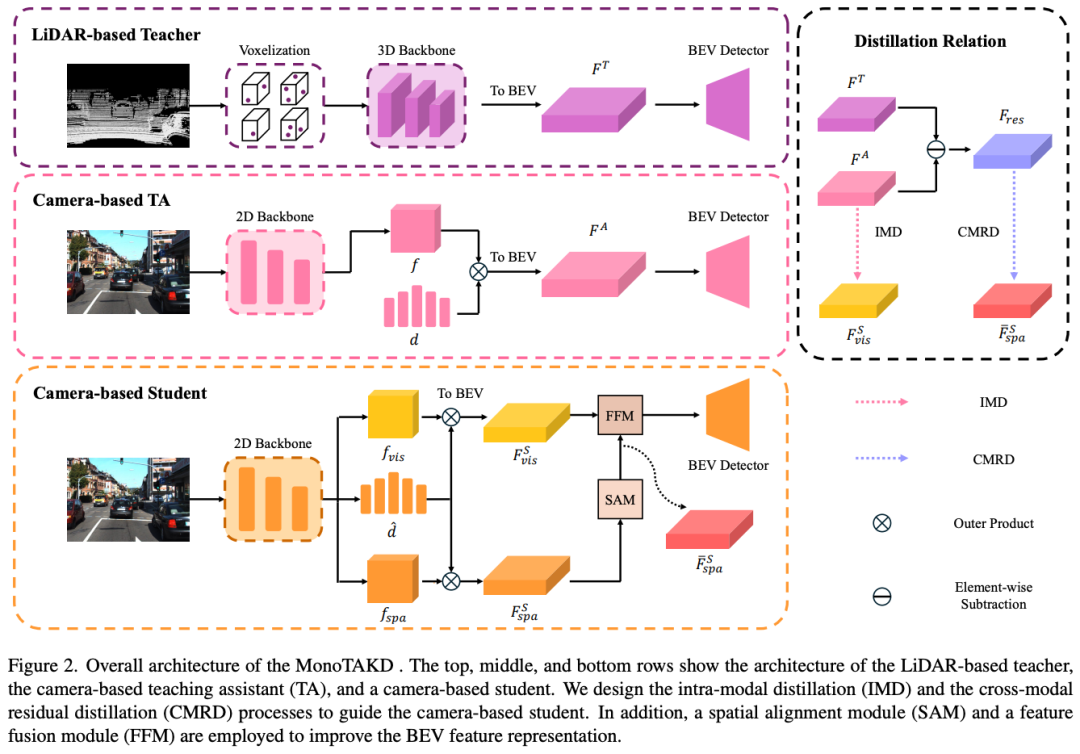
MonoTAKD: Teaching Assistant Knowledge Distillation for Monocular 3D Object Detection
台湾新竹国立阳明交通大学等团队的工作:由于单目相机传感器的成本效益和丰富的视觉环境,单目3D物体检测(Mono3D)在自动驾驶应用中具有值得注意的前景。然而,深度模糊带来了一个重大挑战,因为它需要从单个图像中提取精确的3D场景几何形状,导致在将基于LiDAR的教师模型的知识转移到基于相机的学生模型时性能不佳。为了解决这个问题,我们引入了单目教学辅助知识提取(MonoTAKD)来增强Mono3D中的3D感知。我们的方法提出了一种基于相机的强大教学辅助模型,有效地弥合了教师和学生模型不同模态之间的表示差距,解决了深度估计不准确的挑战。通过将3D空间线索定义为捕捉教师和助教模型之间差异的残差特征,我们将这些线索运用到学生模型中,提高了其3D感知能力。实验结果表明,我们的MonoTAKD在KITT3D数据集上达到了最先进的性能。此外,我们评估了nuScenes和KITTI原始数据集的性能,以展示我们的模型对多视图3D和无监督数据设置的泛化。
论文链接:https://arxiv.org/abs/2404.04910
开源链接:https://github.com/hoiliu-0801/MonoTAKD
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1267
1267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









