









1 序言
近期抽空重整了一遍Transformer(论文下载)。
距离Transformer提出差不多有四年了,也算是一个老生常谈的话题,关于Transformer的讲解有相当多的线上资源可以参考,再不济详读一遍论文也能大致掌握,但是如果现在要求从零开始写出一个Transformer,可能这并不是很轻松的事情。笔者虽然之前也已经数次应用,但是主要还是基于Tensorflow和keras框架编写,然而现在Tensorflow有些问题,这将在本文的第三部分Tensorflow 实现与问题中详细说明。考虑到之后可能还是主要会在PyTorch的框架下进行开发,正好趁过渡期空闲可以花时间用PyTorch实现一个Transformer的小demo,一方面是熟悉PyTorch的开发,另一方面也是加深对Transformer的理解,毕竟将来大约是会经常需要使用,并且在其基础上进行改良的。
事实上很多事情都是如此,看起来容易,做起来就会发现有很多问题,本文在第一部分Transformer模型详解及注意点中将记录笔者在本次Transformer实现中做的一些值得注意的点;第二部分将展示PyTorch中Transformer模型的实现代码,以及如何使用该模型完成一个简单的seq2seq预测任务;第三部分同样会给出Tensorflow中Transformer模型的实现代码,以及目前Tensorflow的一些问题。
本文不再赘述Transformer的原理,这个已经有很多其他文章进行了详细说明,因此需要一些前置的了解知识,可以通过上面的论文下载 链接阅读原文。
目录
2 Transformer模型详解及注意点
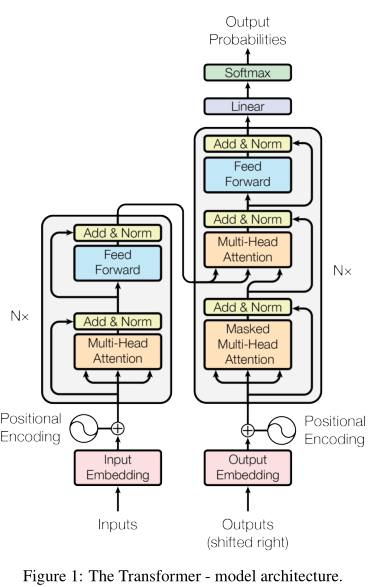
上图是Transformer的结构图解, 当中大致包含如下几个元素:
- Position Encoding: 位置编码;
- Position-wise Feed-Forward Networks: 即图中的Feed Forward模块, 这个其实是一个非常简单的模块, 简单实现就是一个只包含一个隐层的神经网络;
- Multihead Attention 与 Scaled Dot-Product Attention: 注意力机制;
- Encoder 与 Decoder: 编码器与解码器(核心部件);
- 关于上述部件在本文3.1节中的transformer.py代码中都有相应的类与其对应, 并且笔者已经做了非常详细的注释(英文), 以下主要就实现上的细节做说明, 可结合本文3.1节中的transformer.py代码一起理解;
-
Position-wise Feed-Forward Networks正如上述是一个非常简单的三层神经网络: F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 {\rm FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2隐层中使用的是ReLU激活函数(即 max ( 0 , x ) \max(0,x) max(0,x)), 但是要确保的是该模块的输入与输出的维度是完全相同的;
-
关于Position Encoding的理解:
- Transformer中的Sinusoidal Position Encoding:
P
E
(
p
o
s
,
2
i
)
=
sin
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
{\rm PE}({\rm pos},2i)=\sin\left(\frac{\rm pos}{10000^{\frac{2i}{d_{\rm model}}}}\right)\\{\rm PE}({\rm pos},2i+1)=\cos\left(\frac{\rm pos}{10000^{\frac{2i}{d_{\rm model}}}}\right)
PE(pos,2i)=sin(10000dmodel2ipos)PE(pos,2i+1)=cos(10000dmodel2ipos)
- p o s \rm pos pos是位置的索引值, 即 0 , 1 , 2 , . . . , N − 1 0,1,2,...,N-1 0,1,2,...,N−1, N为序列长度;
- i i i是每个位置的Position Encoding的维度中的位置, 如将每个位置编码成64位的嵌入向量, 则 i i i取值范围就是 0 , 1 , 2 , . . . , 31 0,1,2,...,31 0,1,2,...,31, 2 i 2i 2i与 2 i + 1 2i+1 2i+1分别表示奇数位与偶数位;
- p o s + k {\rm pos}+k pos+k位置的encoding可以通过 p o s \rm pos pos位置的encoding线性表示得到: P E ( p o s + k , 2 i ) = sin ( w i ( p o s + k ) ) = sin ( w i p o s ) cos ( w i k ) + cos ( w i p o s ) sin ( w i k ) P E ( p o s + k , 2 i + 1 ) = cos ( w i ( p o s + k ) ) = cos ( w i p o s ) cos ( w i k ) − sin ( w i p o s ) sin ( w i k ) w i = 1 1000 0 2 i d m o d e l {\rm PE}({\rm pos}+k,2i)=\sin(w_i({\rm pos}+k))=\sin(w_i{\rm pos})\cos(w_ik)+\cos(w_i{\rm pos})\sin(w_ik)\\{\rm PE}({\rm pos}+k,2i+1)=\cos(w_i({\rm pos}+k))=\cos(w_i{\rm pos})\cos(w_ik)-\sin(w_i{\rm pos})\sin(w_ik)\\w_i=\frac{1}{10000^{\frac{2i}{d_{\rm model}}}} PE(pos+k,2i)=sin(wi(pos+k))=sin(wipos)cos(wik)+cos(wipos)sin(wik)PE(pos+k,2i+1)=cos(wi(pos+k))=cos(wipos)cos(wik)−sin(wipos)sin(wik)wi=10000dmodel2i1化简得: P E ( p o s + k , 2 i ) = cos ( w i k ) P E ( p o s , 2 i ) + sin ( w i k ) P E ( p o s , 2 i + 1 ) P E ( p o s + k , 2 i + 1 ) = cos ( w i k ) P E ( p o s , 2 i + 1 ) − sin ( w i k ) P E ( p o s , 2 i ) {\rm PE}({\rm pos}+k,2i)=\cos(w_ik){\rm PE}({\rm pos},2i)+\sin(w_ik){\rm PE}({\rm pos,2i+1})\\{\rm PE}({\rm pos}+k,2i+1)=\cos(w_ik){\rm PE}({\rm pos,2i+1})-\sin(w_ik){\rm PE}({\rm pos,2i}) PE(pos+k,2i)=cos(wik)PE(pos,2i)+sin(wik)PE(pos,2i+1)PE(pos+k,2i+1)=cos(wik)PE(pos,2i+1)−sin(wik)PE(pos,2i)
- 可以看到其实Sinusoidal Position Encoding是呈周期性变化的;
- BERT中的Position Encoding由嵌入层训练得到, 而非Transformer中的数学公式给定;
class BertEmbeddings(nn.Module): def __init__(self, config): super().__init__() self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id) # (vocab_size, hidden_size) self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size) # (512, hidden_size) self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size) # (2, hidden_size) # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load # any TensorFlow checkpoint file self.LayerNorm = BertLayerNorm(config.hidden_size, eps=config.layer_norm_eps) self.dropout = nn.Dropout(config.hidden_dropout_prob)
- 关于multihead attention与scaled dot-product attention输入张量形状说明:
- scaled dot-product attention:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V {\rm Attention}(Q, K, V) = {\rm softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQK⊤)Vq: 即查询矩阵 Q Q Q, 形状为(batch_size, n_head, len_q, d_q);k: 即键矩阵 K K K, 形状为(batch_size, n_head, len_k, d_k);v: 即值矩阵 V V V, 形状为(batch_size, n_head, len_v, d_v);mask: 掩码矩阵, 形状应当为(batch_size, n_head, len_q, len_k), 不过其实只要(len_q, len_k)即可, 因为另外两个维度可以直接用unsqueeze或extend来复制扩充;- 注意:
d_q与d_k的大小必须相等;len_k与len_v大小必须相等;- 论文中为了便于处理还另外假设了
d_q = d_k = d_v = d_model / n_head = 8, 并且d_model = 512,n_head = 8;
- multihead attention: 假设该模块的输入输出维度分别为标量值
d_input,d_output;
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) {\rm MultiHead}(Q, K, V) = {\rm Concat}({\rm head}_1, ... , {\rm head}_h)W^O \\ {\rm head}_i = {\rm Attention}(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)- 其中:
- W i Q ∈ R d m o d e l × d q W_i^Q \in \mathcal{R}^{d_{\rm model} × d_q} WiQ∈Rdmodel×dq
- W i K ∈ R d m o d e l × d k W_i^K \in \mathcal{R}^{d_{\rm model} × d_k} WiK∈Rdmodel×dk
- W i V ∈ R d m o d e l × d v W_i^V \in \mathcal{R}^{d_{\rm model} × d_v} WiV∈Rdmodel×dv
- W O ∈ R h d v × d m o d e l W^O \in \mathcal{R}^{hd_v × d_{\rm model}} WO∈Rhdv×dmodel
- h h h是多头注意力的头数;
- 注意一定有 d q = d k d_q = d_k dq=dk成立;
- As is mentioned in paper, h = 8 h = 8 h=8 and d k = d v = d m o d e l h = 64 d_k = d_v = \frac{d_{\rm model}}{h} = 64 dk=dv=hdmodel=64 is set as default.
q: 即查询矩阵 Q Q Q, 形状为(batch_size, len_q, d_q);k: 即键矩阵 Q Q Q, 形状为(batch_size, len_k, d_k);v: 即值矩阵 Q Q Q, 形状为(batch_size, len_v, d_v);mask: 掩码矩阵, 同scaled dot-product attention中的描述;- 注意:
len_k,len_v应当被padding到等长, 即长度应为scaled dot-product attention中的len_k = len_v;d_input等于 d m o d e l d_{\rm model} dmodeld_output等于d_q(以及d_k和d_v, 正如scaled dot-product attention中所提, 它们是相等的);- 特别地, 代码实现时可以设置
d_input = d_output, 这样可以便于进行残差连接的计算(因为残差连接需要将输入加到输出上再归一化后得到最终输出);
- 其中:
- 关于multihead attention与scaled dot-product attention输出张量形状说明:
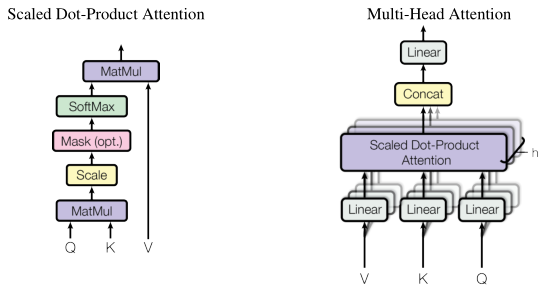
- scaled dot-product attention是multihead attention的一部分, 详细结构可以查看paper中的图👆;
- 一般scaled dot-product attention会有两部分输出, 一个即
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
⊤
d
k
)
V
{\rm Attention}(Q, K, V) = {\rm softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
Attention(Q,K,V)=softmax(dkQK⊤)V的完整输出
output, 另一个是只输出 s o f t m a x \rm softmax softmax值而不与 V V V相乘的结果, 称为scores;scores: 形状为(batch_size, n_head, seq_len, seq_len), 如果存在mask则会将scores上对应位置的值替换为0;output: 形状为(batch_size, n_head, seq_len, d_v),d_v是上一点中输入中提到的符号;
- multihead attention会将scaled dot-product attention的输出
scores保持原样输出, 对于output会作另外的处理:scores: 形状为(batch_size, n_head, seq_len, seq_len);output: 形状为(batch_size, seq_len, d_input),d_input是上一点中输入中提到的符号; 与scaled dot-product attention有差别, 原因是在multihead attention中会将scaled dot-product attention的output调换n_head与seq_len的位置后, 将最后两个维度压缩成一个维度, 然后用一个全连接层对最后一维线性转换输出;
3 PyTorch 实现与demo
3.1 Transformer模型实现
- 下面的代码transformer.py中详细实现了Transformer中的各个部件;
- 记录了当中每一步的张量形状(shape);
- 最后在主函数部分给出了各个模块调用的一个demo;
transformer.py
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
# PyTorch implementation for *Attention is all you need*
# Paper download: https://arxiv.org/abs/1706.03762.pdf
import torch
import numpy
class PositionalEncoding(torch.nn.Module):
"""Section 3.5: Implementation for Positional Encoding"""
def __init__(self, d_input: int, d_output: int, n_position: int) -> None:
"""
Transformer takes the position index of element in a sequence as input features.
Positional Encoding can be formulated as below:
$$
{\rm PE}({\rm pos}, 2i) = \sin\left(\frac{\rm pos}{10000^{\frac{2i}{d_{\rm model}}}}\right) \\
{\rm PE}({\rm pos}, 2i+1) = \cos\left(\frac{\rm pos}{10000^{\frac{2i}{d_{\rm model}}}}\right)
$$
where:
- $\rm pos$ is the position index of element.
- $i$ is the index of embedding vector of `PositionalEncoding`.
:param d_input : Input dimension of `PositionalEncoding` module.
:param d_output : Output dimension of `PositionalEncoding` module.
:param n_position : Total number of position, that is the length of sequence.
"""
super(PositionalEncoding, self).__init__()
def _generate_static_positional_encoding():
sinusoid_table = numpy.array([[pos / numpy.power(10000, (i - i % 2) / d_output) for i in range(d_output)] for pos in range(n_position)])
sinusoid_table[:, 0::2] = numpy.sin(sinusoid_table[:, 0::2])
sinusoid_table[:, 1::2] = numpy.cos(sinusoid_table[:, 1::2])
return torch.FloatTensor(sinusoid_table).unsqueeze(0) # Unsequeeze: wrap position encoding tensor with '[' and ']'.
self.linear = torch.nn.Linear(in_features=d_input, out_features=d_output)
self.register_buffer('pos_table', _generate_static_positional_encoding())
# print(self.pos_table.shape) # (1, `n_position`, `d_output`)
def forward(self, input: torch.FloatTensor) -> torch.FloatTensor:
"""
Add static postional encoding table to input tensor for output tensor.
:param input: The shape is (*, `n_position`, `d_input`)
:return position_encoding: The shape is (*, `n_position`, `d_output`)
"""
x = self.linear(input.float()) # (*, `n_position`, `d_output`)
position_encoding = x + self.pos_table[:, :x.shape[1]].clone().detach()
return position_encoding # (*, `n_position`, `d_output`)
class PositionWiseFeedForwardNetworks(torch.nn.Module):
"""Section 3.3: Implementation for Position-wise Feed-Forward Networks"""
def __init__(self, d_input: int, d_hidden: int) -> None:
"""
The Position-wise Feed-Forward Networks can be formulated as below:
$$
{\rm FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2
$$
Note:
- Input dimension is the same as output dimension, which is set as $d_{\rm model}=512$ in paper.
- Hidden dimenstion is set as $\d_{ff}=2048$ in paper.
:param d_input : Input dimension, default 512 in paper, which is the size of $d_{\rm model}$
:param d_hidden : Hidden dimenstion, default 2048 in paper.
"""
super(PositionWiseFeedForwardNetworks, self).__init__()
self.linear_1 = torch.nn.Linear(in_features=d_input, out_features=d_hidden)
self.linear_2 = torch.nn.Linear(in_features=d_hidden, out_features=d_input)
def forward(self, input: torch.FloatTensor) -> torch.FloatTensor:
"""
:param input : Shape is (*, `d_input`).
:return output : Shape is (*, `d_input`).
"""
x = self.linear_1(input)
x = torch.nn.ReLU()(x) # Relu(x) = max(0, x)
output = self.linear_2(x)
return output
class ScaledDotProductAttention(torch.nn.Module):
"""Section 3.2.1: Implementation for Scaled Dot-Product Attention"""
def __init__(self) -> None:
super(ScaledDotProductAttention, self).__init__()
def forward(self, q: torch.FloatTensor, k: torch.FloatTensor, v: torch.FloatTensor, mask: torch.LongTensor=None) -> (torch.FloatTensor, torch.FloatTensor):
"""
The Scaled Dot-Product Attention can be formulated as below:
$$
{\rm Attention}(Q, K, V) = {\rm softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
$$
:param q : This is $Q$ above, whose shape is (batch_size, n_head, len_q, $d_q$)
:param k : This is $K$ above, whose shape is (batch_size, n_head, len_k, $d_k$)
:param v : This is $V$ above, whose shape is (batch_size, n_head, len_v, $d_v$)
:param mask : The value in `scores` will be replaced with 1e-9 if the corresponding value in mask, whose shape is (len_q, len_k), is 0.
Note:
- $d_q$ = $d_k$ holds and let $d_q$ = $d_k$ = d_output.
- `len_k = len_v` holds.
:return scores : (batch_size, n_head, len_q, len_k)
:return output : (batch_size, n_head, len_q, $d_v$)
"""
# batch_size: batch size of training input.
# n_head : The number of multi-heads.
# d_output : The dimension of $Q$, $K$, $V$.
d_q, d_k = q.shape[-1], k.shape[-1] # `d_k` is d_output.
assert d_q == d_k # Assumption: $d_q$ = $d_k$
scores = torch.matmul(q, k.transpose(2, 3)) / (d_k ** 0.5) # (batch_size, n_head, len_q, d_output) * (batch_size, n_head, d_output, len_k) -> (batch_size, n_head, len_q, len_k)
if mask is not None:
scores = scores.masked_fill(mask.unsqueeze(0).unsqueeze(0)==0, 1e-9)
scores = torch.nn.Softmax(dim=-1)(scores) # (batch_size, n_head, len_q, len_k) -> (batch_size, n_head, len_q, len_k)
output = torch.matmul(scores, v) # (batch_size, n_head, len_q, len_k) * (batch_size, n_head, len_k, $d_v$) -> (batch_size, n_head, len_q, $d_v$)
return output, scores
class MultiHeadAttention(torch.nn.Module):
"""Section 3.2.2: Implementation for Multi-Head Attention"""
def __init__(self, d_input: int, d_output: int, n_head: int) -> None:
"""
The Multi-Head Attention can be formulated as below:
$$
{\rm MultiHead}(Q, K, V) = {\rm Concat}({\rm head}_1, ... , {\rm head}_h)W^O \\
{\rm head}_i = {\rm Attention}(QW_i^Q, KW_i^K, VW_i^V)
$$
where:
- $W_i^Q \in \mathcal{R}^{d_{\rm model} × d_q}$
- $W_i^K \in \mathcal{R}^{d_{\rm model} × d_k}$
- $W_i^V \in \mathcal{R}^{d_{\rm model} × d_v}$
- $W^O \in \mathcal{R}^{hd_v × d_{\rm model}}$
- $h$ is the total number of heads.
- Note that $d_q = d_k$ holds.
- As is mentioned in paper, $h = 8$ and $d_k = d_v = \frac{d_{\rm model}}{h} = 64$ is set as default.
Below we set:
- `d_input` = $d_{\rm model}$
- `d_output` = $d_q$ = $d_k$ = $d_v$
- Usually, `d_input` = `d_output` is assumed so that residual connection is easy to calculate.
:param d_input : Input dimension of `MultiHeadAttention` module.
:param d_output : Output dimension of `MultiHeadAttention` module.
:param n_head : Total number of heads.
"""
super(MultiHeadAttention, self).__init__()
self.linear = torch.nn.Linear(in_features=n_head * d_output, out_features=d_input) # $W^O \in \mathcal{R}^{hd_v × d_{\rm model}}$
self.linear_q = torch.nn.Linear(in_features=d_input, out_features=n_head * d_output) # $W^Q \in \mathcal{R}^{d_{\rm model} × hd_q}$
self.linear_k = torch.nn.Linear(in_features=d_input, out_features=n_head * d_output) # $W^K \in \mathcal{R}^{d_{\rm model} × hd_k}$
self.linear_v = torch.nn.Linear(in_features=d_input, out_features=n_head * d_output) # $W^V \in \mathcal{R}^{d_{\rm model} × hd_v}$
self.n_head = n_head
self.d_output = d_output
self.scaled_dot_product_attention = ScaledDotProductAttention()
def forward(self, q: torch.FloatTensor, k: torch.FloatTensor, v: torch.FloatTensor, mask: torch.LongTensor=None) -> (torch.FloatTensor, torch.FloatTensor):
"""
$$
{\rm MultiHead}(Q, K, V) = {\rm Concat}({\rm head}_1, ... , {\rm head}_h)W^O \\
{\rm head}_i = {\rm Attention}(QW_i^Q, KW_i^K, VW_i^V)
$$
where:
- $d_q = d_k$ holds.
- `d_input` = $d_q$ = $d_k$ = $d_v$
:param q : This is $Q$ above, whose shape is (`batch_size`, `len_q`, $d_q$)
:param k : This is $K$ above, whose shape is (`batch_size`, `len_k`, $d_k$)
:param v : This is $V$ above, whose shape is (`batch_size`, `len_v`, $d_v$)
:param mask : The value in `scores` will be replaced with 1e-9 if the corresponding value in mask, whose shape is (len_q, len_k), is 0.
Note that `len_k` = `len_v` holds.
:return scores : (batch_size, n_head, len_q, len_k)
:return output : (batch_size, len_q, d_input)
"""
batch_size, len_q, len_k, len_v = q.shape[0], q.shape[1], k.shape[1], v.shape[1]
assert len_k == len_v # Assumption: seq_len = `len_k` = `len_v`
q = self.linear_q(q).contiguous().view(batch_size, len_q, self.n_head, self.d_output) # (batch_size, len_q, d_input) -> (batch_size, len_q, n_head * d_output) -> (batch_size, len_q, n_head, d_output)
k = self.linear_k(k).contiguous().view(batch_size, len_k, self.n_head, self.d_output) # (batch_size, len_k, d_input) -> (batch_size, len_k, n_head * d_output) -> (batch_size, len_k, n_head, d_output)
v = self.linear_v(v).contiguous().view(batch_size, len_v, self.n_head, self.d_output) # (batch_size, len_v, d_input) -> (batch_size, len_v, n_head * d_output) -> (batch_size, len_v, n_head, d_output)
q = q.transpose(1, 2) # (batch_size, len_q, n_head, d_output) -> (batch_size, n_head, len_q, d_output)
k = k.transpose(1, 2) # (batch_size, len_k, n_head, d_output) -> (batch_size, n_head, len_k, d_output)
v = v.transpose(1, 2) # (batch_size, len_v, n_head, d_output) -> (batch_size, n_head, len_v, d_output)
output, scores = self.scaled_dot_product_attention(q=q, k=k, v=v, mask=mask)# (batch_size, n_head, len_q, d_output), (batch_size, n_head, len_q, len_k)
output = output.transpose(1, 2).contiguous().view(batch_size, len_q, -1) # (batch_size, n_head, len_q, d_output) -> (batch_size, len_q, n_head, d_output) -> (batch_size, len_q, n_head * d_output)
output = self.linear(output) # (batch_size, len_q, n_head * d_output) -> (batch_size, len_q, d_input)
return output, scores # (batch_size, len_q, d_input), (batch_size, n_head, len_q, len_k)
class Encoder(torch.nn.Module):
"""Section 3.1: Implementation for Encoder"""
def __init__(self, d_input: int, d_output: int, d_hidden: int, n_head: int, n_position: int) -> None:
"""
This is an implementation for one-time Encoder, which is repeated for six times in paper.
:param d_input : Input dimension of `Encoder` module.
:param d_output : Output dimension of `Encoder` module.
:param d_hidden : Hidden dimension of `PositionWiseFeedForwardNetworks` module.
:param n_head : Total number of heads.
:param n_position : Total number of position, that is the length of sequence.
"""
super(Encoder, self).__init__()
self.position_encoding = PositionalEncoding(d_input=d_input, d_output=d_output, n_position=n_position)
self.multi_head_attention = MultiHeadAttention(d_input=d_output, d_output=d_output, n_head=n_head)
self.layer_norm_1 = torch.nn.LayerNorm(d_output)
self.layer_norm_2 = torch.nn.LayerNorm(d_output)
self.position_wise_feed_forward_networks = PositionWiseFeedForwardNetworks(d_input=d_output, d_hidden=d_hidden)
def forward(self, input: torch.FloatTensor, mask: torch.LongTensor=None) -> torch.FloatTensor:
"""
See https://i-blog.csdnimg.cn/blog_migrate/ed51fe43ec08e59295801c167b3719bb.png
:param input : Shape is (batch_size, `n_position`, `d_input`)
:param mask : Shape is (`n_position`, `n_position`)
:return output : Shape is (batch_size, `n_position`, `d_output`)
"""
q = self.position_encoding(input=input) # (*, n_position, d_input) -> (*, n_position, d_output)
k, v = q.clone(), q.clone() # $Q$, $K$, $V$ are just the same in Encoder, but it is a little different in Decoder.
residual_1 = q.clone() # `.clone()` is used for safety.
output_1, scores = self.multi_head_attention(q=q, k=k, v=v, mask=mask)
x = self.layer_norm_1(output_1 + residual_1) # Add & Norm: residual connection.
residual_2 = x.clone() # `.clone()` is used for safety.
output_2 = self.position_wise_feed_forward_networks(input=x) # Feed Forward
output = self.layer_norm_2(output_2 + residual_2) # Add & Norm: residual connection.
return output
class Decoder(torch.nn.Module):
"""Section 3.1: Implementation for Decoder"""
def __init__(self, d_input: int, d_output: int, d_hidden: int, n_head: int, n_position: int) -> None:
super(Decoder, self).__init__()
self.position_encoding = PositionalEncoding(d_input=d_input, d_output=d_output, n_position=n_position)
self.multi_head_attention_1 = MultiHeadAttention(d_input=d_output, d_output=d_output, n_head=n_head)
self.multi_head_attention_2 = MultiHeadAttention(d_input=d_output, d_output=d_output, n_head=n_head)
self.layer_norm_1 = torch.nn.LayerNorm(d_output)
self.layer_norm_2 = torch.nn.LayerNorm(d_output)
self.layer_norm_3 = torch.nn.LayerNorm(d_output)
self.position_wise_feed_forward_networks = PositionWiseFeedForwardNetworks(d_input=d_output, d_hidden=d_hidden)
def generate_subsequence_mask(self, subsequence):
"""
The subsequence mask is defined as a lower-triangle matrix with value 1.
"""
seq_len = subsequence.shape[1]
ones_tensor = torch.ones((seq_len, seq_len), dtype=torch.int, device=subsequence.device)
subsequence_mask = 1 - torch.triu(ones_tensor, diagonal=1) # Note that the value on diagonal is 1.
return subsequence_mask
def forward(self, encoder_output: torch.FloatTensor, target: torch.FloatTensor, mask: torch.LongTensor=None) -> torch.FloatTensor:
"""
See https://i-blog.csdnimg.cn/blog_migrate/ed51fe43ec08e59295801c167b3719bb.png
:param encoder_output : Output of Encoder, whose shape is (batch_size, `n_position`, `d_output_encoder`)
:param target : Target tensor in dataset, whose shape is (batch_size, `n_position`, `d_input_decoder`)
:return output : Shape is (batch_size, `n_position`, `d_output`)
"""
q = self.position_encoding(input=target) # (*, n_position, d_input) -> (*, n_position, d_output)
k, v = q.clone(), q.clone() # $Q$, $K$, $V$ are just the same in Encoder, but it is a little different in Decoder.
residual_1 = q.clone() # `.clone()` is used for safety.
output_1, _ = self.multi_head_attention_1(q=q, k=k, v=v, mask=self.generate_subsequence_mask(target))
x = self.layer_norm_1(output_1 + residual_1) # Add & Norm: residual connection.
residual_2 = x.clone() # `.clone()` is used for safety.
output_2, _ = self.multi_head_attention_2(q=x, k=encoder_output, v=encoder_output, mask=mask)
x = self.layer_norm_2(output_2 + residual_2) # Add & Norm: residual connection.
residual_3 = x.clone() # `.clone()` is used for safety.
output_3 = self.position_wise_feed_forward_networks(input=x) # Feed Forward
output = self.layer_norm_3(output_3 + residual_3) # Add & Norm: residual connection.
return output
class Transformer(torch.nn.Module):
"""Attention is all you need: Implementation for Transformer"""
def __init__(self, d_input_encoder: int, d_input_decoder: int, d_output_encoder: int, d_output_decoder: int, d_output: int, d_hidden_encoder: int, d_hidden_decoder: int, n_head_encoder: int, n_head_decoder: int, n_position_encoder: int, n_position_decoder) -> None:
"""
:param d_input_encoder : Input dimension of Encoder.
:param d_input_decoder : Input dimension of Decoder.
:param d_output_encoder : Output dimension of Encoder.
:param d_output_decoder : Output dimension of Decoder.
:param d_output : Final output dimension of Transformer.
:param d_hidden_encoder : Hidden dimension of linear layer in Encoder.
:param d_hidden_decoder : Hidden dimension of linear layer in Decoder.
:param n_head_encoder=4 : Total number of heads in Encoder.
:param n_head_decoder=4 : Total number of heads in Decoder.
:param n_position_encoder : Sequence Length of Encoder Input, e.g. max padding length of Chinese sentences.
:param n_position_decoder : Sequence Length of Encoder Input, e.g. max padding length of English sentences.
"""
super(Transformer, self).__init__()
self.encoder = Encoder(d_input=d_input_encoder, d_output=d_output_encoder, d_hidden=d_hidden_encoder, n_head=n_head_encoder, n_position=n_position_encoder)
self.decoder = Decoder(d_input=d_input_decoder, d_output=d_output_decoder, d_hidden=d_hidden_decoder, n_head=n_head_decoder, n_position=n_position_decoder)
self.linear = torch.nn.Linear(in_features=d_output_decoder, out_features=d_output)
def forward(self, source, target) -> torch.FloatTensor:
"""
See https://i-blog.csdnimg.cn/blog_migrate/ed51fe43ec08e59295801c167b3719bb.png
"""
encoder_output = self.encoder(source)
decoder_output = self.decoder(encoder_output, target)
x = self.linear(decoder_output)
output = torch.nn.Softmax(dim=-1)(x)
return output
def size(self):
size = sum([p.numel() for p in self.parameters()])
print('%.2fKB' % (size * 4 / 1024))
if __name__ == '__main__':
# -----------------------------------------------------------------
# Positional Encoding
# pe = PositionalEncoding(d_input=37, d_output=64, n_position=50)
# x = torch.Tensor(50, 37)
# print(pe(x).shape) # 1 50 64
# x = torch.Tensor(128, 50, 37)
# print(pe(x).shape) # 128 50 64
# -----------------------------------------------------------------
# Scaled Dot-Product Attention
# sdpa = ScaledDotProductAttention()
# q = torch.Tensor(128, 8, 25, 64)
# k = torch.Tensor(128, 8, 50, 64)
# v = torch.Tensor(128, 8, 50, 32)
# mask = torch.Tensor(25, 50)
# output, scores = sdpa(q, k, v, mask=mask)
# print(scores.shape) # 128, 8, 25, 50
# print(output.shape) # 128, 8, 25, 32
# -----------------------------------------------------------------
# Multi-Head Attention
# mha = MultiHeadAttention(64, 64, 8)
# q = torch.Tensor(128, 50, 64)
# k = torch.Tensor(128, 50, 64)
# v = torch.Tensor(128, 50, 64)
# mask = torch.Tensor(50, 50)
# output, scores = mha(q, k, v, mask)
# print(scores.shape) # 128, 8, 50, 50
# print(output.shape) # 128, 50, 64
# -----------------------------------------------------------------
# Transformer
params = dict(
d_input_encoder=37,
d_input_decoder=12,
d_output_encoder=64,
d_output_decoder=64,
d_output=12,
d_hidden_encoder=128,
d_hidden_decoder=128,
n_head_encoder=4,
n_head_decoder=4,
n_position_encoder=10,
n_position_decoder=7,
)
batch_size = 128
model = Transformer(**params)
model.size()
batch_x = torch.randn(batch_size, params.get('n_position_encoder'), params.get('d_input_encoder'))
batch_y = torch.randn(batch_size, params.get('n_position_decoder'), params.get('d_input_decoder'))
pred = model(batch_x, batch_y)
print(pred.shape)
print(pred[0][0])
3.2 示例demo
- 本demo是一个通过
babel库生成不同日期格式的字符串, 然后分别给这些伪造的日期格式字符串标注上标准的日期格式, 通过训练Transformer模型来进行进行两者之间的预测;- 请3.1中的transformer.py与本节中dataset.py, train.py, test.py, utils.py置于同一目录, 并在该目录下创建名为checkpoint的空文件夹;
- 代码目录结构:
../transformer.py
../dataset.py
../train.py
../test.py
../utils.py
../checkpoint/
dataset.py
- 伪造数据生成代码:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
import torch
import numpy
import random
from datetime import datetime
from babel.dates import format_date
from torch.nn.functional import one_hot
class PseudoDateDataset(torch.utils.data.Dataset):
def __init__(self, size: int, pad_token: str='<pad>', unk_token: str='<unk>') -> None:
"""
:param size : Size of dataset.
:param pad_token: Token of padding words.
:param unk_token: Token of stopping words.
"""
human_vocabulary = set()
machine_vocabulary = set()
self.dataset = []
for _ in range(size):
human_readable_date, machine_readable_date = self.generate_pseudo_date()
self.dataset.append((human_readable_date, machine_readable_date))
human_vocabulary.update(tuple(human_readable_date))
machine_vocabulary.update(tuple(machine_readable_date))
self.human_vocabulary = dict(zip(sorted(human_vocabulary) + [unk_token, pad_token], list(range(len(human_vocabulary) + 2))))
self.machine_vocabulary = {token: index for index, token in enumerate(sorted(machine_vocabulary) + [pad_token])}
self.inverse_machine_vocabulary = {index: token for token, index in self.machine_vocabulary.items()}
self.human_unk = self.human_vocabulary.get(unk_token) # Get the id of '<unk>' token in human vocabulary.
self.machine_unk = self.machine_vocabulary.get(unk_token) # Get the id of '<unk>' token in machine vocabulary.
self.machine_pad = self.machine_vocabulary.get(pad_token) # Get the id of '<pad>' token in machine vocabulary.
self.pad_token = pad_token
self.unk_token = unk_token
def generate_pseudo_date(self, builtin_ratio: float=.8, builtin_dist: list=[.2, .2, .2, .4], locale: str='en_US') -> (str, str):
"""
Generate a pair of human-readable date string and machine-readable date string.
:param builtin_ratio : Possibility of selecting datetime format from `builtin_datetime_formats` rather than `custom_datetime_formats`
:param built_dist : Possibility distribution of selecting different datetime formats in `builtin_datetime_formats` (short, medium, long, full)
:param locale : Language of datetime, e.g. 'en_US', 'zh_CN', default 'en_US' means American English.
:return human_readable_date : Such as 'Wednesday, October 26, 2107'.
:return machine_readable_date : Datetime in format 'yyyy-MM-dd'
"""
# Randomly generate a human-readable date format
def _generate_datetime_format(builtin_ratio: float, builtin_dist: list) -> str:
builtin_datetime_formats = [
'short', # d/MM/YY
'medium', # MMM d, YYYY
'long', # MMMM, d, YYYY
'full', # EEEE, MMMM d, YYYY
]
custom_datetime_formats = [ # Some common human readable datetime formats could be customly enumerated.
'{month}/{day}/{year}'.format,
'{year}/{month}/{day}'.format,
'{month} {day}, {year}'.format,
'{year}.{month}.{day}'.format,
'{day} {month}, {year}'.format,
'{year}, {day} {month}'.format,
]
year_formats = ['Y', 'YY', 'YYY', 'YYYY'] # 2020 20 2020 2020
month_formats = ['M', 'MM', 'MMM', 'MMMM'] # 2 02 Feb February
day_formats = ['d', 'dd'] # 2 02
weekday_formats = ['E', 'E', 'EEE', 'EEEE'] # Sat Sat Sat Saturday
if random.random() < builtin_ratio:
return numpy.random.choice(a=builtin_datetime_formats, p=builtin_dist)
return random.choice(custom_datetime_formats)(year=random.choice(year_formats), month=random.choice(month_formats), day=random.choice(day_formats))
random_timestamp = int(random.random() * time.time()) + 86400 # Randomly generate a timestamp: note that `datetime.datetime.fromtimestamp` receive timestamp larger than 86399.
random_date = datetime.fromtimestamp(random_timestamp).date() # Randomly generate a date.
datetime_format = _generate_datetime_format(builtin_ratio=builtin_ratio, builtin_dist=builtin_dist)
human_readable_date = format_date(random_date, format=datetime_format, locale=locale).lower().replace(',', '')
machine_readable_date = random_date.isoformat()
return human_readable_date, machine_readable_date
def __getitem__(self, idx: int) -> (torch.LongTensor, torch.LongTensor, dict):
human_readable_date, machine_readable_date = self.dataset[idx] # Fetch tuple in dataset.
human_readable_vector = list(map(lambda x: self.human_vocabulary.get(x, self.human_unk), human_readable_date))
machine_readable_vector = [self.machine_pad] + list(map(lambda x: self.machine_vocabulary.get(x, self.machine_unk), machine_readable_date)) + [self.machine_pad]
human_readable_tensor = one_hot(torch.tensor(human_readable_vector), num_classes=len(self.human_vocabulary))
machine_readable_tensor = one_hot(torch.tensor(machine_readable_vector), num_classes=len(self.machine_vocabulary))
raw = {'human_readable_date': human_readable_date, 'machine_readable_date': machine_readable_date}
return human_readable_tensor, machine_readable_tensor, raw
def __len__(self) -> int:
return len(self.dataset)
if __name__ == '__main__':
from utils import collate_fn
dataset = PseudoDateDataset(size=1000)
padding_tensor = torch.FloatTensor(numpy.zeros(len(dataset.human_vocabulary)))
padding_tensor[dataset.human_vocabulary.get(dataset.pad_token)] = 1
dataloader = torch.utils.data.DataLoader(
dataset=dataset,
batch_size=4,
shuffle=True,
num_workers=0,
collate_fn=collate_fn(padding_tensor),
)
for step, (batch_x, batch_y, batch_raw) in enumerate(dataloader):
pass
train.py
- 模型训练代码:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import sys
import torch
import numpy
from tqdm import tqdm
from utils import *
from dataset import PseudoDateDataset
from transformer import Transformer
def train(model: torch.nn.Module, loss_function: torch.nn.modules.loss.MSELoss, optimizer: torch.optim.Adam, dataloader: torch.utils.data.DataLoader, epoch: int, gpu_available: bool=False):
"""
Transformer training demo.
:param model : Transformer model.
:param loss_function : Loss function in torch.
:param optimizer : Optimizer in torch.
:param dataloader : Dataloader extending `torch.utils.data.Dataset`
:param epoch : Current epoch.
:param gpu_available : Is GPU avaliable?
"""
def _calc_accuracy(y_pred: torch.FloatTensor, y_true: torch.FloatTensor) -> float:
y_pred = numpy.argmax(y_pred, axis=2)
y_true = numpy.argmax(y_true, axis=2)
correct = (y_pred == y_true).astype(numpy.int)
return correct.sum() / (y_pred.shape[0] * y_pred.shape[1])
pbar = tqdm(total=len(dataloader), bar_format='{l_bar}{r_bar}', dynamic_ncols=True)
pbar.set_description('Epoch {}'.format(epoch))
for step, (batch_x, batch_y, _) in enumerate(dataloader):
if gpu_available:
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
y_pred = model(batch_x, batch_y[:, :-1, :])
accuracy = _calc_accuracy(
y_pred = y_pred.detach().cpu().numpy(),
y_true = batch_y[:, 1:, :].detach().cpu().numpy(),
)
loss = loss_function(y_pred, batch_y[:, 1:, :])
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix(**{'loss':loss.detach().cpu().item(), 'accuracy':accuracy})
pbar.update()
save_checkpoint('checkpoint', epoch, model, optimizer)
pbar.close()
if __name__ == '__main__':
gpu_id = '0'
batch_size = 4
n_epoch = 5
dataset = PseudoDateDataset(size=1000)
padding_tensor = torch.FloatTensor(numpy.zeros(len(dataset.human_vocabulary)))
padding_tensor[dataset.human_vocabulary.get(dataset.pad_token)] = 1
dataloader = torch.utils.data.DataLoader(
dataset=dataset,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn(padding_tensor),
)
params = dict(
d_input_encoder=37,
d_input_decoder=12,
d_output_encoder=64,
d_output_decoder=64,
d_output=12,
d_hidden_encoder=128,
d_hidden_decoder=128,
n_head_encoder=4,
n_head_decoder=4,
n_position_encoder=50,
n_position_decoder=50,
)
model = Transformer(**params)
if gpu_id is not None:
os.environ["CUDA_VISIBLE_DEVICES"] = gpu_id
n_gpus = torch.cuda.device_count()
model = model.cuda()
# model = torch.nn.DataParallel(model, device_ids=[i for i in range(n_gpus)])
loss_function = torch.nn.MSELoss()
# loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
model = load_model('checkpoint', None, model)
optimizer = load_optimizer('checkpoint', None, optimizer)
try:
training_epoch = find_last_checkpoint_epoch('checkpoint')
print('train form epoch {}'.format(training_epoch + 1))
except Exception as e:
print('train from the very begining, {}'.format(e))
training_epoch = -1
for epoch in range(training_epoch + 1, n_epoch):
train(
model=model,
loss_function=loss_function,
optimizer=optimizer,
dataloader=dataloader,
epoch=epoch,
gpu_available=False if gpu_id is None else True,
)
test.py
- 模型评估代码:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import torch
import numpy
from matplotlib import pyplot as plt
from utils import *
from dataset import PseudoDateDataset
from transformer import Transformer
def test(model: torch.nn.Module, x: torch.FloatTensor, y_true: torch.FloatTensor) -> torch.LongTensor:
"""
Transformer testing demo.
:param model : Transformer model.
:param x : Input tensor.
:param y_true : Ground truth tensor.
"""
x = x.unsqueeze(0)
y_true = y_true.unsqueeze(0).unsqueeze(0)
encoder_output = model.encoder(x)
y_pred = y_true.clone()
for step in range(14):
decoder_output = model.decoder(encoder_output, y_pred)
y = model.linear(decoder_output)
y = torch.nn.Softmax(dim=-1)(y)
y_pred = torch.cat((y_true, y), dim=1)
return y_pred.squeeze(0)
if __name__ == '__main__':
dataset = PseudoDateDataset(size=10000)
params = dict(
d_input_encoder=37,
d_input_decoder=12,
d_output_encoder=64,
d_output_decoder=64,
d_output=12,
d_hidden_encoder=128,
d_hidden_decoder=128,
n_head_encoder=4,
n_head_decoder=4,
n_position_encoder=50,
n_position_decoder=50,
)
model = Transformer(**params)
try:
training_epoch = find_last_checkpoint_epoch('checkpoint')
print('Load model with epoch {}'.format(training_epoch))
except Exception as e:
print('No models found in checkpoint: {}'.format(e))
model = load_model('checkpoint', None, model)
model.eval()
x, y, raw = dataset[0]
pred = test(model, x, y[0])
pred = numpy.argmax(pred.detach().numpy(), axis=1)[1:]
pred = [dataset.inverse_machine_vocabulary[p] for p in pred]
pred_str = ''.join(pred)
human_readable_date = raw['human_readable_date']
machine_readable_date = raw['machine_readable_date']
print('[{}] --> [{}], answer: [{}]'.format(human_readable_date, pred_str, list(machine_readable_date)))
utils.py
- 工具函数:
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import os
import torch
from functools import wraps
from typing import Callable
def collate_fn(padding_tensor: torch.FloatTensor) -> Callable:
"""
A function defined for augment `collate_fn` in `torch.utils.data.DataLoader`.
Note that human-readable date tensor is needed to be padded.
:param padding_tensor : Tensor used to pad at the end of the human-readable date tensor.
:return _collate_fn : The returned object is a function.
"""
def _collate_fn(batch):
_padding_tensor = padding_tensor.view(-1, 1)
_batch_human_readable_tensor, _batch_machine_readable_tensor, batch_raw = zip(*batch)
_max_length_human = max(_human_readable_tensor.shape[0] for _human_readable_tensor in _batch_human_readable_tensor)
_batch_human_readable_tensor_padded = []
for _human_readable_tensor in _batch_human_readable_tensor:
_padded_length = _max_length_human - _human_readable_tensor.shape[0]
_padded_tensor = _padding_tensor.expand(_padding_tensor.shape[0], _padded_length).transpose(0, 1)
_batch_human_readable_tensor_padded.append(torch.vstack((_human_readable_tensor, _padded_tensor)).unsqueeze(0))
batch_human_readable_tensor = torch.vstack(_batch_human_readable_tensor_padded).float()
batch_machine_readable_tensor = torch.vstack(list(map(lambda tensor: tensor.unsqueeze(0), _batch_machine_readable_tensor))).float()
return batch_human_readable_tensor, batch_machine_readable_tensor, batch_raw
return _collate_fn
def find_last_checkpoint_epoch(checkpoint_dir: str) -> int:
"""
Find the largest epoch in checkpoint directory.
:param checkpoint_dir : Directory path for saving checkpoints.
"""
epochs = []
for name in os.listdir(checkpoint_dir):
if os.path.splitext(name)[-1] == '.pth':
epochs.append(int(name.strip('ckpt_epoch_.pth')))
if len(epochs) == 0:
raise IOError('No checkpoint found in {}'.format(checkpoint_dir))
return max(epochs)
def save_checkpoint(checkpoint_dir: str, epoch: int, model: torch.nn.DataParallel, optimizer: torch.optim.Adam=None) -> None:
"""
Save a model to checkpoint directory marked with epoch.
:param checkpoint_dir : Directory path for saving checkpoints.
:param epoch : The epoch of the model.
:param model : The model to save.
:param optimizer : The optimizer used to optimize the model.
"""
checkpoint = {}
checkpoint['epoch'] = epoch
if isinstance(model, torch.nn.DataParallel):
model_state_dict = model.module.state_dict()
else:
model_state_dict = model.state_dict()
checkpoint['model'] = model_state_dict
if optimizer is not None:
optimizer_state_dict = optimizer.state_dict()
checkpoint['optimizer'] = optimizer_state_dict
else:
checkpoint['optimizer'] = None
torch.save(checkpoint, os.path.join(checkpoint_dir, 'ckpt_epoch_%02d.pth' % epoch))
def load_checkpoint(checkpoint_dir: str, epoch: int=None) -> torch.nn.Module:
"""
Load the checkpoint model with default largest epoch.
:param checkpoint_dir : Directory path for saving checkpoints.
:param epoch : The epoch of the model.
"""
if epoch is None:
epoch = find_last_checkpoint_epoch(checkpoint_dir)
checkpoint = torch.load(os.path.join(checkpoint_dir, 'ckpt_epoch_%02d.pth' % epoch))
return checkpoint
def load_model(checkpoint_dir: str, epoch: int, model: torch.nn.Module) -> torch.nn.Module:
"""
Load model from checkpoint directory.
:param checkpoint_dir : Directory path for saving checkpoints.
:param epoch : The epoch of the model.
:param model : Initial model.
"""
try:
checkpoint = load_checkpoint(checkpoint_dir, epoch)
model_state_dict = checkpoint['model']
if isinstance(model, torch.nn.DataParallel):
model.module.load_state_dict(model_state_dict)
else:
model.load_state_dict(model_state_dict)
except Exception as e:
print('Fail to load model: {}'.format(e))
return model
def load_optimizer(checkpoint_dir: str, epoch: int, optimizer: torch.optim.Adam) -> torch.optim.Adam:
"""
Load optimizer from checkpoint directory.
:param checkpoint_dir : Directory path for saving checkpoints.
:param epoch : The epoch of the model.
:param optimizer : Initial optimizer.
"""
try:
checkpoint = load_checkpoint(checkpoint_dir, epoch)
optimizer_state_dict = checkpoint['optimizer']
optimizer.load_state_dict(optimizer_state_dict)
except Exception as e:
print('Fail to load optimizer: {}'.format(e))
return optimizer
if __name__ == '__main__':
pass
4 Tensorflow 问题与实现
4.1 问题
- 关于Tensorflow中的实现笔者将之前写过的代码搬过来, 但是Tensorflow更新到
2.x.x版本后之前很多的函数都已经不再通用了, 如更新后的部分区别如下:
tf.get_default_graph()改为tf.compat.v1.get_default_graph()tf.Session()改为tf.compat.v1.Session()tf.nn.relu_layer改为tf.compat.v1.nn.relu_layertf.nn.xw_plus_b改为tf.compat.v1.nn.xw_plus_btf.placeholder改为tf.compat.v1.placeholder
-
诸如此类, 都可以尝试用这种尝试在
tf后面加上compat.v1进行修改尝试, 但是仍然有相当数量的方法无法调用, 事实上不仅仅是更新到2.x.x版本后出现这些问题, 即便是1.x.x中的不同版本也经常会遇到方法不兼容的问题, 之前遇到过的最胃疼的事情就是别人用Tensorflow编写的模块无法直接使用, 原因就是版本不匹配, 而且很离谱的是更新到2.x.x版本后竟然开发团队没有兼容方法, 反而是简单直接把老方法置入到一个compat.v1模块里, 也真的是够偷懒的; -
下面的代码是Tensorflow 1.9.0版本可行的示例, 虽然可能无法在其他版本上跑通, 但是其中笔者也已经做了非常详细的注释, 对于学习Tensorflow中模型搭建的学习可能仍然是很有帮助的;
-
总之本节只是提供代码思路, 没有像上一节的可以跑通的demo, 笔者现在感觉Tensorflow的势头可能真的不如PyTorch了, 但是总归还是都得会用的, 至少需要的时候能很快拿得起来;
4.2 实现
- thesis_transformer.py中是Transformer类的实现, 其中包含Encoder与Decoder两个部件的逻辑;
- thesis_transformer_modules.py中是Transformer模型中小部件的实现, 其中包含诸如Positional Encoding以及注意力机制等;
- thesis_transformer_utils.py中是一些简单函数;
thesis_transformer.py
# -*- coding: UTF-8 -*-
# Author: 囚生
# Transformer类实现
import os
import time
import tensorflow as tf
from tqdm import tqdm
from thesis_transformer_utils import *
from thesis_transformer_modules import *
class Transformer():
def __init__(self,vocabulary, # 词汇表
embeddings=None, # 词向量矩阵
d_model=512, # 词向量维度
dropout=0.3, # dropout的阈值
num_blocks=6, # encoder/decoder块数
num_heads=8, # 多头注意力机制头数
d_hidden=2048, # 前馈传播隐层节点数
maxlen1=100, # 来源句子最大长度
maxlen2=100, # 目标句子最大长度
lr=0.003, # 初始学习率
warmup_steps=4000, # 起热步数
padding_token="<pad>", # 新参数: 用于padding的token标记
): # 类构造函数
""" 类构造参数 """
self.token2idx = vocabulary.copy() # "单词——索引"键值对字典
self.idx2token = {idx:token for token,idx in vocabulary.items()} # "索引——单词"键值对字典
self.vocab_size = len(self.idx2token) # 这个本身也是hparams配置文件中预定义的数值, 默认为32000, 这里就根据传入的词汇表构建了
self.dropout = dropout # 模型dropout阈值: 默认2048
self.num_blocks = num_blocks # encoder/decoder块数: 默认6
self.num_heads = num_heads # 多头注意力机制头数: 默认8
self.d_hidden = d_hidden # 前馈传播隐层节点数: 默认2048
self.maxlen1 = maxlen1 # 来源句子最大长度: 默认100
self.maxlen2 = maxlen2 # 目标句子最大长度: 默认100
self.lr = lr # 初始学习率: 默认0.003
self.warmup_steps = warmup_steps # 起热步数: 默认4000
self.padding_token = padding_token # 新参数: 用于padding的token标记(默认为"<pad>")
if embeddings is None: # 若没有传入词向量参数
self.d_model = d_model # 词向量模型维度
self.embeddings = initiate_embeddings( # 随机生成词向量
vsize=self.vocab_size,
edim=self.d_model,
padding=True,
)
else: # 若传入词向量参数
self.d_model = embeddings.shape[-1] # 默认最后一维是词向量模型维度
self.embeddings = embeddings # 直接使用传入的词向量即可
def encode(self,xs, # xs由三个变量构成
training=True,
): # 编码器算法
with tf.variable_scope("encoder",reuse=tf.AUTO_REUSE): # 创建名为encoder的变量区域
x,seqlens,sents1 = xs # x:整型张量(N,T1)可能是原句的token2id后的结果, seqlens:整型张量(N,), sents1:字符串张量(N,) 目前我理解T1是句子的最大长度, x应该是已经被等长padding
src_masks = tf.equal(x,0) # 找到x中为零的部分(可以理解为被padding的部分)
""" 词嵌入操作 """
encoder = tf.nn.embedding_lookup(self.embeddings,x) # 选取这部分的值: (N,T1,d_model), d_model默认为512
encoder *= self.d_model**0.5 # scale: 论文中写过要把词向量乘以sqrt(d_model) #
encoder = tf.layers.dropout(encoder,self.dropout,training=training)
""" 分块操作 """
for i in range(self.num_blocks): # 遍历6个encoder
with tf.variable_scope("num_blocks_{}".format(i),reuse=tf.AUTO_REUSE):
encoder = multihead_attention( # 自注意力机制
queries=encoder, # encoder作为查询矩阵
keys=encoder, # encoder作为键矩阵
values=encoder, # encoder作为值矩阵
key_masks=src_masks, # 键矩阵mask
num_heads=self.num_heads, # 多头数量
dropout=self.dropout, # dropout阈值
training=training, # 是否训练
causality=False, # 是否做future-blind的mask
scope="multihead_attention", # 变量控制域名
querymask=False, # 是否做query-mask
) # 然后下一步进行全连接
encoder = feed_forward(encoder,[self.d_hidden,self.d_model])
memory = encoder
return memory,sents1,src_masks # memory: (N,T1,d_model)
def decode(self,ys,memory,src_masks,
training=True,
): # 解码器算法
with tf.variable_scope("decoder",reuse=tf.AUTO_REUSE):
decInput,y,seqlens,sents2 = ys # decInput:整型张量(N,T2), y:大概率是句子中单词id构成的整型张量(N,T2), seqlens:整型张量(N,), sents2:字符串张量(N,)
tgt_masks = tf.equal(decInput,0) # 同encoder: (N,T2)
decoder = tf.nn.embedding_lookup(self.embeddings,decInput) # 同encoder: (N,T2,d_model)
decoder *= self.d_model**0.5 # 同encoder: scale操作
decoder += positional_encoding(decoder,self.maxlen2) # decoder的特有操作: 直接加上位置编码的张量
decoder = tf.layers.dropout(decoder,self.dropout,training=training)
"""
同encoder: 分块操作,
1. 注意次数的casuality为True, 即在decoder中是要进行future-blinding的mask操作的
2. 注意此处有两次注意力机制, 这是decoder与encoder的区别
"""
for i in range(self.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i),reuse=tf.AUTO_REUSE):
decoder = multihead_attention( # 同encoder: 但注意causality=True, 因此这被称为masked self-attention
queries=decoder,
keys=decoder,
values=decoder,
key_masks=tgt_masks,
num_heads=self.num_heads,
dropout=self.dropout,
training=training,
causality=True,
scope="self_attention",
querymask=False,
)
decoder = multihead_attention( # decoder的特有操作: 引入encoder的输出结果, 称为Vanilla attention
queries=decoder,
keys=memory,
values=memory,
key_masks=src_masks,
num_heads=self.num_heads,
dropout=self.dropout,
training=training,
causality=False,
scope="vanilla_attention",
querymask=False,
) # 同encoder: 接下来全连接操作
decoder = feed_forward(decoder,[self.d_hidden,self.d_model])
""" 最后一步: 线性映射(embedding权重共享) """
weights = tf.transpose(self.embeddings) # (d_model,vocab_size), 默认(512,30000)
logits = tf.einsum("ntd,dk->ntk",decoder,weights) # 三维矩阵乘以二维矩阵: (N,T2,vocab_size)
y_hat = tf.to_int32(tf.argmax(logits,axis=-1)) # 在logits的最后一维找到最大值的索引
return logits,y_hat,y,sents2 # logits:浮点型张量(N,T2,vocab_size), y_hat:整型张量(N,T2), y:整型张量(N,T2), sents2: 字符串张量(N,)
def train(self,xs,ys, # 两个参数分别为encoder与decoder的输入
): # Transformer训练一次的情况
""" 前馈传播 """
memory,sents1,src_masks = self.encode(xs) # 获得encoder的输出
logits,preds,y,sents2 = self.decode(ys,memory,src_masks) # 获得decoder的输出
"""
训练计划:
1. 对y进行one-hot编码
2. 计算decoder输出与one-hot后的y的交叉熵值
3. 找到y中没有被padding的部分(即句子原本的样子)的数值nonpadding, y应该就是句子中单词换成id后的结果
4. 计算损失函数值: ∑(交叉熵*nonpadding)/∑(nonpadding) ???
"""
y_onehot = label_smoothing(tf.one_hot(y,depth=self.vocab_size)) # 使用one-hot对y进行编码: y是一个整型张量(N,T2)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits,labels=y_onehot)
nonpadding = tf.to_float(tf.not_equal(y,self.token2idx[self.padding_token]))
loss = tf.reduce_sum(cross_entropy*nonpadding)/(tf.reduce_sum(nonpadding)+1e-7)
""" 寻找最优点 """
global_step = tf.train.get_or_create_global_step() # 这个函数我暂时搞不清楚有什么用, 大概是初始化一个全局步数
lr = noam_scheme(self.lr,global_step,self.warmup_steps) # 计算当轮学习率
optimizer = tf.train.AdamOptimizer(lr) # 优化器: adam
train_op = optimizer.minimize(loss,global_step=global_step) # 使用优化器来优化损失函数
""" 可能是对训练过程中的变量进行绘图 """
tf.summary.scalar("lr",lr)
tf.summary.scalar("loss",loss)
tf.summary.scalar("global_step",global_step)
summaries = tf.summary.merge_all() # 合并所有的summary
return loss,train_op,global_step,summaries # loss:损失值(标量), train_op:训练操作, global_step:当前训练步数(标量), summaries: training summary node
def eval(self,xs,ys,
): # 模型评估: 自回归预测
decInput,y,y_seqlen,sents2 = ys # 取出ys的元素
decInput = tf.ones((tf.shape(xs[0])[0],1),tf.int32)*self.token2idx["<s>"]
ys = (decInput,y,y_seqlen,sents2) # 对decInput项修正一下(原本是(N,T2)): 具体操作是把它变成(N,1)的向量, 值全部为token标记"<s>"的索引值
memory,sents1,src_masks = self.encode(xs,False) # 非训练情况下对xs进行encode
print("正在构建推理图...")
for i in tqdm(range(self.maxlen2),ncols=50): # 对每个单词进行操作
logits,y_hat,y,sents2 = self.decode(ys,memory,src_masks,False)
if tf.reduce_sum(y_hat,1)==self.token2idx["<pad>"]: break # y_hat:(N,T2), 归约求和为(N,), 恰好<pad>则退出循环(???)
decInput_ = tf.concat((decInput,y_hat),1) # 合并decInput与y_hat在第1维度上
ys = (decInput_,y,y_seqlen,sents2) # 更新ys
""" 模拟一个随机样例 """
n = tf.random_uniform((),0,tf.shape(y_hat)[0]-1,tf.int32) # 随机生成一个均匀分布的张量
sent1 = sents1[n] # 取出一些句子
prediction = convert_idx_to_token_tensor(y_hat[n],self.idx2token)# 把y_hat[n]的索引通过idx2token转换为真实的句子
sent2 = sents2[n] # 取出一些句子
""" 开心的汇总绘图 """
tf.summary.text("sent1", sent1)
tf.summary.text("prediction", prediction)
tf.summary.text("sent2", sent2)
summaries = tf.summary.merge_all() # 合并所有的summary
return y_hat,summaries # y_hat: (N,T2)
if __name__ == "__main__":
vocabulary = {'a': 1, 'b': 2, 'c': 3}
t = Transformer(vocabulary)
thesis_transformer_modules.py
# -*- coding: UTF-8 -*-
# Author: 囚生
# 与transformer类实现有关的模块
import numpy as np
import tensorflow as tf
def ln(inputs, # 一个有至少两维的张量, 第0维度是batch-size
epsilon=1e-8, # 用于防止除零错误的极小数
scope="ln" # 变量范围
): # 网络层标准化: https://arxiv.org/abs/1607.06450
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
inputs_shape = inputs.get_shape() # 获取输入的形状
params_shape = inputs_shape[-1:] # 获取最后一维的数值
mean,variance = tf.nn.moments(inputs,[-1],keep_dims=True) # 在最后一个维度上计算均值方差
""" 创建了两个向量, beta为偏差值初始化为零, gamma为权重值初始化为1 """
beta= tf.get_variable("beta",params_shape,initializer=tf.zeros_initializer())
gamma = tf.get_variable("gamma",params_shape,initializer=tf.ones_initializer())
normalized = (inputs-mean)/((variance+epsilon)**(.5)) # 去中心化并且标准差归为1
outputs = gamma*normalized+beta # 对标准化后的结果做一个线性变换(事实上初始化情况下并没有对outputs有任何改变)
return outputs
def initiate_embeddings(vsize,edim,padding=True): # 初始化词向量矩阵: 所谓零padding即为把第一行给全部换成0
"""
1. 注意第0行被默认设置为全零
2. vsize为标量V: 词汇表的大小, 一般为30000左右
3. edim为词向量维度E, 默认512,
返回值为权重矩阵, 形状为(V,E)
"""
with tf.variable_scope("shared_weight_matrix"):
embeddings = tf.get_variable("weight_mat",
dtype=tf.float32,
shape=(vsize,edim),
initializer=tf.contrib.layers.xavier_initializer(),
)
if padding: embeddings = tf.concat((tf.zeros(shape=[1,edim]),embeddings[1:,:]),0)
return embeddings
def mask(inputs, # 输入为三维张量: (N*h,T_q,T_k)
key_masks=None, # 键值mask三维张量: (N,1,T_k)
type_=None, # 字符串类型: key|query|future
queries=None, # 这是被注释掉的代码(query-mask)需要使用的参数: 查询矩阵Q
keys=None, # 这是被注释掉的代码(query-mask)需要使用的参数: 键矩阵K
): # 将键K,查询Q通过mask转化为输入input
padding_num = -2**32+1 # 用于padding的一个较大的负数
if type_ in ("k","key","keys"): # 对键矩阵的处理
""" 处理key_masks """
h = tf.shape(inputs)[0]//tf.shape(key_masks)[0] # 计算扩展维数
key_masks = tf.to_float(key_masks) # 先把参数key_mask转化为float形式
key_masks = tf.tile(key_masks,[h,1]) # 扩展key_mask: (h*N,seqlen)
key_masks = tf.expand_dims(key_masks,1) # 在第1维度进行扩展: (h*N,1,seqlen)
outputs = inputs + key_masks*padding_num # 直接在input上
elif type_ in ("q","query","queries"): # 对查询矩阵的处理: 这部分代码被注释了, 我觉得留下也未尝不可
""" 生成masks """
query_masks = tf.sign(tf.reduce_sum(tf.abs(queries),axis=-1)) # 对query字符串取绝对值后归约求和: (N,T_q)
query_masks = tf.expand_dims(masks,-1) # 在masks最后扩张一个维度(N,T_q,1)
query_masks = tf.tile(masks,[1,1,tf.shape(keys)[1]]) # 扩展masks: (N,T_q,T_k)
outputs = inputs*masks # 直接乘也太真实了
elif type_ in ("f","future","right"): # future-blind是什么东西也不懂
diag = tf.ones_like(inputs[0,:,:]) # 构造一个全一矩阵: (T_q,T_k)
tril = tf.linalg.LinearOperatorLowerTriangular(diag).to_dense() # 不太懂什么意思(T_q,T_k)
tril = tf.expand_dims(tril,0) # 在第一维度上扩展维度
future_masks = tf.tile(tril,[tf.shape(inputs)[0],1,1]) # 得到masks: (N,T_q,T_k)
paddings = tf.ones_like(future_masks)*padding_num # 生成零padding张量
outputs = tf.where(tf.equal(future_masks,0),paddings,inputs) # 把future_mask中是零的部分换成padding, 不是零的部分input本身
else: raise Exception("Invalid param: type_ !")
return outputs
def scaled_dot_product_attention(Q,K,V,key_masks, # Q:(N,T_q,d_k), K:[N,T_k,d_k], V:[N,T_k,d_v]
causality=False, # 是否对future-blinding进行mask
dropout=0., # dropout阈值
training=True, # 训练标记
scope="scaled_dot_product_attention", # 变量范围
querymask=False, # 是否进行query-mask: 源代码中关于query-mask的部分都被注释了
): # 单个注意力机制
"""
公式: Attention(Q,K,V) = softmax(QK'/sqrt(d_k))*V
scaled_dot_product_attention:
1.点积: dot_qk = Q·K'
2.单位化: scaled_dot_qk = dot_qk/sqrt(d_k)
3.Mask: ???
4.Softmax: softmax_scaled_dot_qk = softmax(scaled_dot_qk)
5.点积: Attention = softmax_scaled_dot_qk·V
其中Q与K的维度是d_k, V的维度是d_v
"""
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
d_k = Q.get_shape().as_list()[-1] # 取最后一维作为d_k
outputs = tf.matmul(Q,tf.transpose(K,[0,2,1])) # dot(Q,K'): (N,T_q,T_k)
outputs /= (d_k**0.5) # dot(Q,K')/sqrt(d_k): 这里d_k好像就是64
outputs = mask(outputs,key_masks=key_masks,type_="key") # 对键K的输出进行mask
if causality: outputs = mask(outputs,type_="future") # 是否进行future-blind的mask?
outputs = tf.nn.softmax(outputs) # 对输出进行softmax操作
attention = tf.transpose(outputs,[0,2,1]) # 对输出转置
tf.summary.image("attention",tf.expand_dims(attention[:1],-1)) # 做个图吗?
if querymask: # 这部分在mask函数被注释了, 因此这里的参数与普通的mask函数有所区别
mask(inputs=outputs,queries=Q,keys=K,type_="query")
outputs = tf.layers.dropout(outputs,rate=dropout,training=training)
outputs = tf.matmul(outputs, V) # 加权求和(context-vectors): 将输出点乘V即可, 形状为(N,T_q,d_v)
return outputs # 返回值: (N,T_q,d_v)
def multihead_attention(queries,keys,values,key_masks,
num_heads=8,
dropout=0.,
training=True,
causality=False,
scope="multihead_attention",
querymask=False,
): # 多头注意力算法: 注意本算法中设定T_k==T_v, 返回值形状为(N,T_q,C)
"""
公式: MultiHead(Q,K,V) = Concat(head_1,...,head_h)·W_O
其中head_i = Attention(Q·Wi_Q,K·Wi_K,V·Wi_V)
单个注意力函数有d_model维度的K,V,Q,
然后我们创造h组不同的(Ki,Vi,Qi),
分别学习线性映射到d_k, d_k, d_v维度,
"""
d_model = queries.get_shape().as_list()[-1] # 取最后一个维度的作为d_model:
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
""" 线性映射: """
Q = tf.layers.dense(queries,d_model,use_bias=True) # (N,T_q,d_model)
K = tf.layers.dense(keys,d_model,use_bias=True) # (N,T_k,d_model)
V = tf.layers.dense(values,d_model,use_bias=True) # (N,T_v,d_model)
""" 分割与合并 """
Q_ = tf.concat(tf.split(Q,num_heads,axis=2),axis=0) # (h*N,T_q,d_model/h)
K_ = tf.concat(tf.split(K,num_heads,axis=2),axis=0) # (h*N,T_k,d_model/h)
V_ = tf.concat(tf.split(V,num_heads,axis=2),axis=0) # (h*N,T_k,d_model/h)
""" 得到注意力层的输出 """
outputs = scaled_dot_product_attention(Q_,K_,V_,key_masks,causality,dropout,training,"scaled_dot_product_attention",querymask)
outputs = tf.concat(tf.split(outputs,num_heads,axis=0),axis=2) # 对outputs在第0维度上分成8份后再在第2维度上拼接: (N,T_q,d_model)
outputs += queries # 残差连接?(不懂)
outputs = ln(outputs) # 标准化
return outputs # 返回值: (N,T_q,C)
def feed_forward(inputs,num_units, # inputs: 一个三维张量(N,T,C), num_units: 一个拥有两个整数的列表, 分别表示两个隐层的节点数量
scope="positionwise_feedforward",
): # 前向传播: 返回值为与inputs形状相同
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
""" 两层网络: 输入层, 输出层 """
outputs = tf.layers.dense(inputs,num_units[0],activation=tf.nn.relu)
outputs = tf.layers.dense(outputs,num_units[1])
outputs += inputs # 残差连接: F(x)+x, 这样使得求导时出现常数1, 避免了梯度消失的问题
outputs = ln(outputs) # 层正则化
return outputs
def positional_encoding(inputs,maxlen, # inputs:三维张量(N,T,E), maxlen:不小于T的标量
masking=True, # 是否用0来padding
scope="positional_encoding", # 张量控制域
): # 解码器中特有的操作, 对输入序列的位置进行编码, 返回值与inputs同形
E = inputs.get_shape().as_list()[-1] # 静态: 取出inputs的最后一维数值E
N,T = tf.shape(inputs)[0],tf.shape(inputs)[1] # 动态: 去除inputs的前两维的数值N, T
with tf.variable_scope(scope,reuse=tf.AUTO_REUSE):
position_index = tf.tile(tf.expand_dims(tf.range(T),0),[N,1]) # position indices: 对一个T维向量在第0维上扩张N次: (N,T)
""" PE函数的第一部分: 得到用于求预先的一段奇奇怪怪的数字(我猜想是作为位置的一种特征), 形状是(maxlen,E) """
position_encoder = np.array([[pos/np.power(10000,(i-i%2)/E) for i in range(E)] for pos in range(maxlen)])
""" PE函数的第二部分: 偶数列求余弦, 奇数列求正弦 """
position_encoder[:,0::2] = np.sin(position_encoder[:,0::2]) # 奇数列
position_encoder[:,1::2] = np.cos(position_encoder[:,1::2]) # 偶数列
position_encoder = tf.convert_to_tensor(position_encoder,tf.float32)
outputs = tf.nn.embedding_lookup(position_encoder,position_index)# 找到对应position_index索引中的postition_encoder对应位置的向量
if masking: outputs = tf.where(tf.equal(inputs,0),inputs,outputs)# 对输入进行mask: 为零的部分保留, 不为零的部分换为outputs的对应位置数值
return tf.to_float(outputs) # outputs转为浮点型: (N,T,E)
def noam_scheme(init_lr,global_step, # 两个标量: 原始的学习率与全局步数
warmup_steps=4000., # 在该阶段内, 学习率慢慢增长直到达到init_lr
): # 学习率(步长)自然是要衰减的: 返回一个学习率
step = tf.cast(global_step+1,dtype=tf.float32)
return init_lr*(warmup_steps**0.5)*tf.minimum(step*warmup_steps**-1.5,step**-0.5)
def label_smoothing(inputs, # 输入为三维张量(N,T,V), N为样本数, T是最大序列长度, V是词汇表大小
epsilon=.1, # 平滑率
):
V = inputs.get_shape().as_list()[-1] # 取最后一维channel, 其实就是词汇表大小
return ((1-epsilon)*inputs) + (epsilon/V) # 平滑一下呗
if __name__ == "__main__":
pass
thesis_transformer_utils.py
# -*- coding: UTF-8 -*-
# Author: 囚生
# 与Transformer类实现有关的工具函数
import re
import os
import json
import numpy as np
import tensorflow as tf
from tensorflow.python import pywrap_tensorflow
def convert_idx_to_token_tensor(inputs,idx2token, # inputs:一维整型索引张量, idx2token:字典
): # 将整型张量变为字符串张量, 返回一维字符串张量
f = lambda x: " ".join(idx2token[index] for index in x)
return tf.py_func(f,[inputs],tf.string)
def pad(x,
maxlen=100,
): # 返回值: 数组(len(x),maxlen)
padded = []
for seq in x:
seq += [0]*(maxlen-len(seq))
padded.append(seq)
array = np.array(padded,np.int32)
assert array.shape==(len(x),maxlen),"Failed to make an array"
return array
def train_generator(sents1,sents2,token2idx,
): # 训练数据生成器
token2idx = eval(token2idx.decode("UTF-8"))
hp = get_hparams()
for sent1,sent2 in zip(sents1,sents2):
x = [token2idx.get(token,token2idx[hp.stopword_token]) for token in sent1.decode("UTF-8").split()] + [token2idx[hp.end_token]]
y = [token2idx[hp.start_token]] + [token2idx.get(token,token2idx[hp.stopword_token]) for token in sent2.decode("UTF-8").split()] + [token2idx[hp.end_token]]
decoder_input = y[:-1] # 没想明白decoder的输入不需要结尾的</s>
y = y[1:] # 没想明白为什么输出又不要开头的"<s>"
x_seqlen,y_seqlen = len(x),len(y) # 而且我也不明白为什么x没有开头的"<s>"
yield (x,x_seqlen,sent1),(decoder_input,y,y_seqlen,sent2)
def get_batch(sents1,sents2,token2idx,
batch_size=128,
shuffle=False,
): # 训练数据批量生产
f = lambda x: x.encode("UTF-8")
shapes = (
([None],(),()),
([None],[None],(),()),
)
types = (
(tf.int32,tf.int32,tf.string),
(tf.int32,tf.int32,tf.int32,tf.string),
)
paddings = (
(0,0,""),
(0,0,0,""),
)
dataset = tf.data.Dataset.from_generator(
train_generator,
output_shapes=shapes,
output_types=types,
args=(np.array(sents1),np.array(sents2),str(token2idx).encode("UTF-8")), # train_generator的参数
)
if shuffle: dataset = dataset.shuffle(128*batch_size) # 用于训练模式: 一般验证模式不需要洗牌
dataset = dataset.repeat() # 设置为可永久迭代
dataset = dataset.padded_batch(batch_size,shapes,paddings).prefetch(1)
total = len(sents1)
num_batches = total//batch_size + int(total%batch_size!=0) # 计算总batch数量
return dataset,num_batches
def postprocess(hypotheses,idx2token): # 得到翻译结果: 参数为encoder的预测输出及词汇表字典
temp = []
for h in hypotheses:
sent = "".join(idx2token[idx] for idx in h)
sent = sent.split("</s>")[0].strip()
temp.append(sent.strip())
return temp
def get_hypotheses(num_batches,num_samples,session,output,idx2token): # 生成目标句子
hypotheses = [] # 存储句子
for i in range(num_batches):
op = session.run(output)
hypotheses.extend(op.tolist())
hypotheses = postprocess(hypotheses,idx2token)
return hypotheses[:num_samples]
def save_variable_specs(filepath,
): # 存储变量信息到文件: 如name, shape, 全部参数数量
params = [] # 存储参数的列表
num_params = 0 # 记录参数的变量数量
for variable in tf.global_variables(): # 遍历全局所有变量
num_param = 1 # 记录当前参数的变量数量
for i in range(len(variable.shape)): num_param *= variable.shape[i]
num_params += num_param
params.append("{}==={}".format(variable.name,variable.shape))
with open(filepath,"w") as f:
f.write("num_params: {}\n".format(num_params))
f.write("\n".join(params))
if __name__ == "__main__":
pass
5 结语
本文主要是以PyTorch实现与案例为主,并且对在实现中的注意点进行了总结,Tensorflow因为存在各种问题只是提供代码编写的思路以及样本demo,希望能够对你有所帮助。

















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









