







字数溢出,分了一半出来
上半段:LLM+RL
文章目录
- 8 [RL4LLM] 理解 reasoning model Tokenizer 的 chat template,vllm inference
- 9 [RL4LLM] PPO workflow 及 OpenRLHF、veRL 初步介绍,ray distributed debugger
- 9 [RL4LLM] 深入 PPO-clip 目标函数细节(及重要性采样)
- 10 [RL4LLM] GRPO loss/objective 分析 及可能的 biases 分析(DAPO,Dr. GRPO)
- 11 [RL4LLM] deepseek v3 工具调用的 bug 以及理解 chat_template 的 function calling
- 12 [veRL] 性能优化 use_remove_padding (flash attn varlen)变长序列处理
- 13 [veRL] log probs from logits 与 entropy from logits 的高效计算
- 14 [RL4LLM] base vs. instruct model,个性化(custom)chat template(make prefix)
8 [RL4LLM] 理解 reasoning model Tokenizer 的 chat template,vllm inference
- 链接:https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/r1-k1.5/reasoning_model_chat_template_and_inference.ipynb
- video: https://www.bilibili.com/video/BV1LKXSYqE3T
目前的 AI = 数据(data) + 算法(algorithm) + 架构(infra)
- 不要排斥基础,觉得简单就不关注相关的细节。越是复杂的系统,越要从基础从原理,分解从模块来看。
- 不只是 tokenize,还有 chat template,什么时候轮到 llm 输出,如何区分 user 和 assistant(包括这期要介绍的 reasoning tokenizer,所谓的 reasoning tokens & answer tokens);
- fancy 和 powerful 的 llm,似乎 tokenizer 很 low level,显得很没有意思,甚至繁琐;
- chat temaplte (for chat models, 目前的 reasoning models 首先也得是一个 chat models)
- 添加特殊 token id,标记身份(user/assistant/tool);
- System: 建立初始的身份认知;
- tool_call,tool_response(也是一种身份)
- 添加 system prompt,如果用户没有显示地传入的话
- 解析历史对话:循环解析的过程
- 添加特殊 token id,标记身份(user/assistant/tool);
from transformers import AutoTokenizer
import re
import torch
models = [
"deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
"Qwen/Qwen2.5-1.5B-Instruct",
"Qwen/Qwen2.5-Math-1.5B",
"Qwen/Qwen2.5-1.5B",
"Qwen/QwQ-32B-Preview"
]
这里面 DeepSeek-R1-Distill-Qwen-1.5B是对Qwen2.5-Math-1.5B做的蒸馏,而非Qwen2.5-1.5B-Instruct,论文里明确说了:

def hf_tokenizer(name_or_path):
tokenizer = AutoTokenizer.from_pretrained(name_or_path)
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
print(f'tokenizer.pad_token_id is None. Now set to {tokenizer.eos_token_id}')
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print(f'tokenizer.pad_token is None. Now set to {tokenizer.eos_token}')
return tokenizer
这里添加一下padding model
tokenizer
- DeepSeek-R1-Distill-Qwen-1.5B 由 Qwen2.5-Math-1.5B 蒸馏而来,而不是 Qwen/Qwen2.5-1.5B-Instruct;
- 复用了词表,重新定义了一些特殊的 token id;
下面的代码验证了这个事情:
def test_tokenizer(tokenizer, text):
tokens = tokenizer.encode(text)
print(f'{text}, tokens: {tokens}')
for name_or_path in models:
tokenizer = hf_tokenizer(name_or_path)
print(f'{name_or_path}, tokenizer.pad_token: {tokenizer.pad_token}, tokenizer.pad_token_id: {tokenizer.pad_token_id}')
test_tokenizer(tokenizer, "hello world")
print('-' * 100)
输出:
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B, tokenizer.pad_token: <|end▁of▁sentence|>, tokenizer.pad_token_id: 151643
hello world, tokens: [151646, 14990, 1879]
----------------------------------------------------------------------------------------------------
Qwen/Qwen2.5-1.5B-Instruct, tokenizer.pad_token: <|endoftext|>, tokenizer.pad_token_id: 151643
hello world, tokens: [14990, 1879]
----------------------------------------------------------------------------------------------------
Qwen/Qwen2.5-Math-1.5B, tokenizer.pad_token: <|endoftext|>, tokenizer.pad_token_id: 151643
hello world, tokens: [14990, 1879]
----------------------------------------------------------------------------------------------------
Qwen/Qwen2.5-1.5B, tokenizer.pad_token: <|endoftext|>, tokenizer.pad_token_id: 151643
hello world, tokens: [14990, 1879]
----------------------------------------------------------------------------------------------------
Qwen/QwQ-32B-Preview, tokenizer.pad_token: <|endoftext|>, tokenizer.pad_token_id: 151643
hello world, tokens: [14990, 1879]
----------------------------------------------------------------------------------------------------
两个词表都是一致的,ds大概是150k+的一个词表量
distill_tokenizer = hf_tokenizer('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B')
print(distill_tokenizer.decode(151646))
qwen_math_tokenizer = hf_tokenizer('Qwen/Qwen2.5-Math-1.5B')
print(qwen_math_tokenizer.decode(151646))
qwen_chat_tokenizer = hf_tokenizer('Qwen/Qwen2.5-1.5B-Instruct')
print(qwen_chat_tokenizer.decode(151646))
qwen_base_tokenizer = hf_tokenizer('Qwen/Qwen2.5-1.5B')
print(qwen_base_tokenizer.decode(151646))
qwen_reason_tokenizer = hf_tokenizer('Qwen/QwQ-32B-Preview')
print(qwen_base_tokenizer.decode(151646))
输出结果:
- 这里很有趣的地方是使用了全角字符,这样可能是为了区分其他llm的词表,以确保互联网上不存在这样的字符。
<|begin▁of▁sentence|>
<|object_ref_start|>
<|object_ref_start|>
<|object_ref_start|>
<|object_ref_start|>
distill_tokenizer.encode('<|User|>') # [151646, 151644]
qwen_math_tokenizer.encode('<|User|>'), qwen_chat_tokenizer.encode('<|User|>'), qwen_base_tokenizer.encode('<|User|>')
# 输出:([27, 130957, 1474, 130957, 29],
# [27, 130957, 1474, 130957, 29],
# [27, 130957, 1474, 130957, 29])
Qwen的词表大概是130k+👆
另一个有趣的事情:
# what is <|end▁of▁sentence|>
# https://chat.deepseek.com/a/chat/s/569c8476-7b64-48fa-865b-9e01718b961b
# what is <|im_end|>
# https://chat.qwen.ai/c/da88d4f3-c279-4851-acbb-d3f051c11e86
distill_tokenizer.decode(151643) # '<|end▁of▁sentence|>'
这个是说<|end▁of▁sentence|>这个字符ds是看不到的,你去问它what is <|end▁of▁sentence|>,它是无法回答的,同理QWEN是<|im_end|>,这个qwen也是看不到的:
chat template
AutoTokenizer.from_pretrained('meta-llama/Llama-3.1-8B').chat_template
- jinja template
- llma-3.1-8b是一个base模型,它是没有chat_model的
from jinja2 import Environment, FileSystemLoader
# 创建 Jinja2 环境
env = Environment(loader=FileSystemLoader("."))
# 模板 1: 使用标准语法 {% ... %}
template1 = env.from_string("""
{% if True %}
Hello
{% endif %}
""")
# 模板 2: 使用去除空白字符的语法 {% - ... -%}
template2 = env.from_string("""
{%- if True -%}
Hello
{%- endif -%}
""")
# 渲染模板
result1 = template1.render()
result2 = template2.render()
# 打印结果
print("使用标准语法 {% ... %} 的结果:")
print(repr(result1)) # repr 用于显示换行符和空白字符
print("\n使用去除空白字符的语法 {% - ... -%} 的结果:")
print(repr(result2))
"""
使用标准语法 {% ... %} 的结果:
'\n\n Hello\n'
使用去除空白字符的语法 {% - ... -%} 的结果:
'Hello'
"""
这里{%- if True -%}里的减号是用来去除空格的
# We do not recommend using base language models for conversations. Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
# https://huggingface.co/Qwen/Qwen2.5-1.5B
print(qwen_base_tokenizer.chat_template)
输出结果:
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- 'You are a helpful assistant.' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- else %}
{{- '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + message.content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}
这里注意👆:qwen的base model提供了chat template,但官方文档里说了不建议使用
distill tokenizer
print(distill_tokenizer.chat_template)
qwen的chat_template甚至没有换行:
{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}{%- for message in messages %}{%- if message['role'] == 'system' %}{% set ns.system_prompt = message['content'] %}{%- endif %}{%- endfor %}{{bos_token}}{{ns.system_prompt}}{%- for message in messages %}{%- if message['role'] == 'user' %}{%- set ns.is_tool = false -%}{{'<|User|>' + message['content']}}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is none %}{%- set ns.is_tool = false -%}{%- for tool in message['tool_calls']%}{%- if not ns.is_first %}{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{%- set ns.is_first = true -%}{%- else %}{{'\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}{%- endif %}{%- endfor %}{%- endif %}{%- if message['role'] == 'assistant' and message['content'] is not none %}{%- if ns.is_tool %}{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}{%- set ns.is_tool = false -%}{%- else %}{% set content = message['content'] %}{% if '</think>' in content %}{% set content = content.split('</think>')[-1] %}{% endif %}{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}{%- endif %}{%- endif %}{%- if message['role'] == 'tool' %}{%- set ns.is_tool = true -%}{%- if ns.is_output_first %}{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- set ns.is_output_first = false %}{%- else %}{{'\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}{%- endif %}{%- endif %}{%- endfor -%}{% if ns.is_tool %}{{'<|tool▁outputs▁end|>'}}{% endif %}{% if add_generation_prompt and not ns.is_tool %}{{'<|Assistant|><think>\n'}}{% endif %}
格式化后:
{% if not add_generation_prompt is defined %}
{% set add_generation_prompt = false %}
{% endif %}
{% set ns = namespace(is_first=false, is_tool=false, is_output_first=true, system_prompt='') %}
{%- for message in messages %}
{%- if message['role'] == 'system' %}
{% set ns.system_prompt = message['content'] %}
{%- endif %}
{%- endfor %}
{{bos_token}}{{ns.system_prompt}}
{%- for message in messages %}
{%- if message['role'] == 'user' %}
{%- set ns.is_tool = false -%}
{{'<|User|>' + message['content']}}
{%- endif %}
{%- if message['role'] == 'assistant' and message['content'] is none %}
{%- set ns.is_tool = false -%}
{%- for tool in message['tool_calls']%}
{%- if not ns.is_first %}
{{'<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}
{%- set ns.is_first = true -%}
{%- else %}
{{'\n' + '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n' + '```json' + '\n' + tool['function']['arguments'] + '\n' + '```' + '<|tool▁call▁end|>'}}
{{'<|tool▁calls▁end|><|end▁of▁sentence|>'}}
{%- endif %}
{%- endfor %}
{%- endif %}
{%- if message['role'] == 'assistant' and message['content'] is not none %}
{%- if ns.is_tool %}
{{'<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>'}}
{%- set ns.is_tool = false -%}
{%- else %}
{% set content = message['content'] %}
{% if '</think>' in content %}
{% set content = content.split('</think>')[-1] %}
{% endif %}
{{'<|Assistant|>' + content + '<|end▁of▁sentence|>'}}
{%- endif %}
{%- endif %}
{%- if message['role'] == 'tool' %}
{%- set ns.is_tool = true -%}
{%- if ns.is_output_first %}
{{'<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}
{%- set ns.is_output_first = false %}
{%- else %}
{{'\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>'}}
{%- endif %}
{%- endif %}
{%- endfor -%}
{% if ns.is_tool %}
{{'<|tool▁outputs▁end|>'}}
{% endif %}
{% if add_generation_prompt and not ns.is_tool %}
{{'<|Assistant|><think>\n'}}
{% endif %}
注意最后加了一个<think>,这件事在huggingface上还添加了一个帖子:

qwen tokenizer
print("\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>")
输出:
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
# default system prompt
print(qwen_chat_tokenizer.chat_template)
输出:
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- else %}
{{- '<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + message.content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}
然后是reason的template
print(qwen_reason_tokenizer.chat_template)
输出结果:
{%- if tools %}
{{- '<|im_start|>system\n' }}
{%- if messages[0]['role'] == 'system' %}
{{- messages[0]['content'] }}
{%- else %}
{{- 'You are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step.' }}
{%- endif %}
{{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }}
{%- for tool in tools %}
{{- "\n" }}
{{- tool | tojson }}
{%- endfor %}
{{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }}
{%- else %}
{%- if messages[0]['role'] == 'system' %}
{{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }}
{%- else %}
{{- '<|im_start|>system\nYou are a helpful and harmless assistant. You are Qwen developed by Alibaba. You should think step-by-step.<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- for message in messages %}
{%- if (message.role == "user") or (message.role == "system" and not loop.first) or (message.role == "assistant" and not message.tool_calls) %}
{{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }}
{%- elif message.role == "assistant" %}
{{- '<|im_start|>' + message.role }}
{%- if message.content %}
{{- '\n' + message.content }}
{%- endif %}
{%- for tool_call in message.tool_calls %}
{%- if tool_call.function is defined %}
{%- set tool_call = tool_call.function %}
{%- endif %}
{{- '\n<tool_call>\n{"name": "' }}
{{- tool_call.name }}
{{- '", "arguments": ' }}
{{- tool_call.arguments | tojson }}
{{- '}\n</tool_call>' }}
{%- endfor %}
{{- '<|im_end|>\n' }}
{%- elif message.role == "tool" %}
{%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' }}
{{- message.content }}
{{- '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
{%- endif %}
{%- endfor %}
{%- if add_generation_prompt %}
{{- '<|im_start|>assistant\n' }}
{%- endif %}
支持一些工具调用👆
1.5b的模型官方不建议修改system template
apply chat template
basic_messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, how are you?"},
# {"role": "assistant", "content": "I'm doing great. How can I help you today?"}
]
distill_tokenizer.apply_chat_template(basic_messages, tokenize=False)
输出:'<|begin▁of▁sentence|>You are a helpful assistant.<|User|>Hello, how are you?'
# https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
distill_tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
输出:'<|begin▁of▁sentence|>You are a helpful assistant.<|User|>Hello, how are you?<|Assistant|><think>\n'
qwen_chat_tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
输出:'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nHello, how are you?<|im_end|>\n<|im_start|>assistant\n'
qwen_reason_tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
输出:'<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nHello, how are you?<|im_end|>\n<|im_start|>assistant\n'
vllm inference
gsm8k_inference_test = "Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market?"
gt_ans = '18'
distill_tokenizer.apply_chat_template([gsm8k_inference_test], add_generation_prompt=True, tokenize=False)
输出:'<|begin▁of▁sentence|><|Assistant|><think>\n'
instruction = "Let's think step by step and output the final answer within \\boxed{}."
chat_test = [{'role': 'user', 'content': f'{gsm8k_inference_test} {instruction}'}]
chat_test
"""
[{'role': 'user',
'content': "Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market? Let's think step by step and output the final answer within \\boxed{}."}]
"""
distill_tokenizer.apply_chat_template(chat_test, add_generation_prompt=True, tokenize=False)
输出结果:"<|begin▁of▁sentence|><|User|>Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market? Let's think step by step and output the final answer within \\boxed{}.<|Assistant|><think>\n"
prompt_ids = distill_tokenizer.apply_chat_template(chat_test, add_generation_prompt=True, tokenize=True)
from vllm import LLM, SamplingParams
llm = LLM(model='deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',
max_model_len=32768)
sampling_params = SamplingParams(
temperature=0.6, max_tokens=32768)
response = llm.generate(prompt_token_ids=prompt_ids, sampling_params=sampling_params)[0]
print(response.outputs[0].text)
输出结果:
Alright, let's tackle this problem step by step. So, Janet has ducks that lay 16 eggs every day. Hmm, okay, that's a lot! She eats three eggs for breakfast every morning and bakes muffins for her friends with four eggs each day. Then, she sells the rest at the farmers' market for $2 per egg. I need to figure out how much money she makes every day from selling the eggs.
First, let me break down the information given:
1. **Duck eggs per day:** 16
2. **Eggs eaten for breakfast:** 3 per day
3. **Eggs used for muffins:** 4 per day
4. **Selling price per egg:** $2
So, the plan is to subtract the eggs Janet eats and uses for muffins from the total eggs laid each day. The remaining eggs will be what she sells, and then we can multiply that by the selling price to get her daily earnings.
Let me write this down in a more structured way:
Total eggs per day = 16
Eggs eaten for breakfast = 3
Eggs used for muffins = 4
So, the eggs available for selling = Total eggs - Eggs eaten - Eggs used for muffins
That is:
Eggs for selling = 16 - 3 - 4
Let me compute that:
16 - 3 is 13, and then 13 - 4 is 9. So, 9 eggs are left for selling.
Now, she sells each egg for $2. So, the total revenue from selling the eggs would be:
Total revenue = Eggs for selling × Selling price per egg
Which is:
Total revenue = 9 × $2
Calculating that, 9 times 2 is 18. So, she makes $18 each day from selling the eggs.
Wait, let me double-check my calculations to make sure I didn't make a mistake.
Total eggs: 16
Eggs eaten for breakfast: 3, so 16 - 3 = 13
Eggs used for muffins: 4, so 13 - 4 = 9
Yes, 9 eggs left.
9 eggs × $2 = $18. That seems right.
Alternatively, I can check by adding up the eggs used:
3 breakfast + 4 muffins = 7 eggs
So, 7 eggs are eaten or used, and 16 - 7 = 9 eggs left. Yep, same result.
So, 9 × $2 is definitely $18.
I don't think I've missed anything here. She starts the day with 16 eggs, uses 7 of them, sells the rest, and that's the amount she makes. So, the answer should be $18.
**Final Answer**
\boxed{18}
</think>
Janet's ducks lay 16 eggs per day. She eats 3 eggs for breakfast and uses 4 eggs for baking muffins. The remaining eggs are sold at the farmers' market for $2 each.
1. Total eggs per day: 16
2. Eggs eaten for breakfast: 3
3. Eggs used for muffins: 4
4. Eggs available for selling: \(16 - 3 - 4 = 9\)
The revenue from selling the remaining eggs is calculated as:
\[ 9 \text{ eggs} \times \$2 \text{ per egg} = \$18 \]
Thus, Janet makes \(\boxed{18}\) dollars every day at the farmers' market.
9 [RL4LLM] PPO workflow 及 OpenRLHF、veRL 初步介绍,ray distributed debugger
链接:https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/r1-k1.5/infra/overall_basics.ipynb
RL4LLM roadmap
- 从 trl 开始学起,框架较为基础和简单;
- 深入地学习 GRPO,基于 1.5B 复现 R1,复现 aha moments;
- https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb(春节期间对GRPO的复现的一个项目)
- 大致也基本能搞清楚 RLHF 阶段的 PPO 算法原理,二者在公式上主要只有 adv(advantage)的估计方法不同;
- 深入地学习 GRPO,基于 1.5B 复现 R1,复现 aha moments;
- 后续可以陆陆续续迁移到更现代更多工程性能优化的 RL4LLM 的框架上
- 比如 veRL 和 OpenRLHF
- 假如都是零基础,优先 veRL 吧,除非继承而来的项目是 OpenRLHF;
- veRL:2409.19256,3.8k stars;
- https://github.com/Jiayi-Pan/TinyZero
- https://github.com/agentica-project/deepscaler
- https://github.com/Unakar/Logic-RL
- OpenRLHF:2405.11143,5k stars;
论文里的图,很清晰:
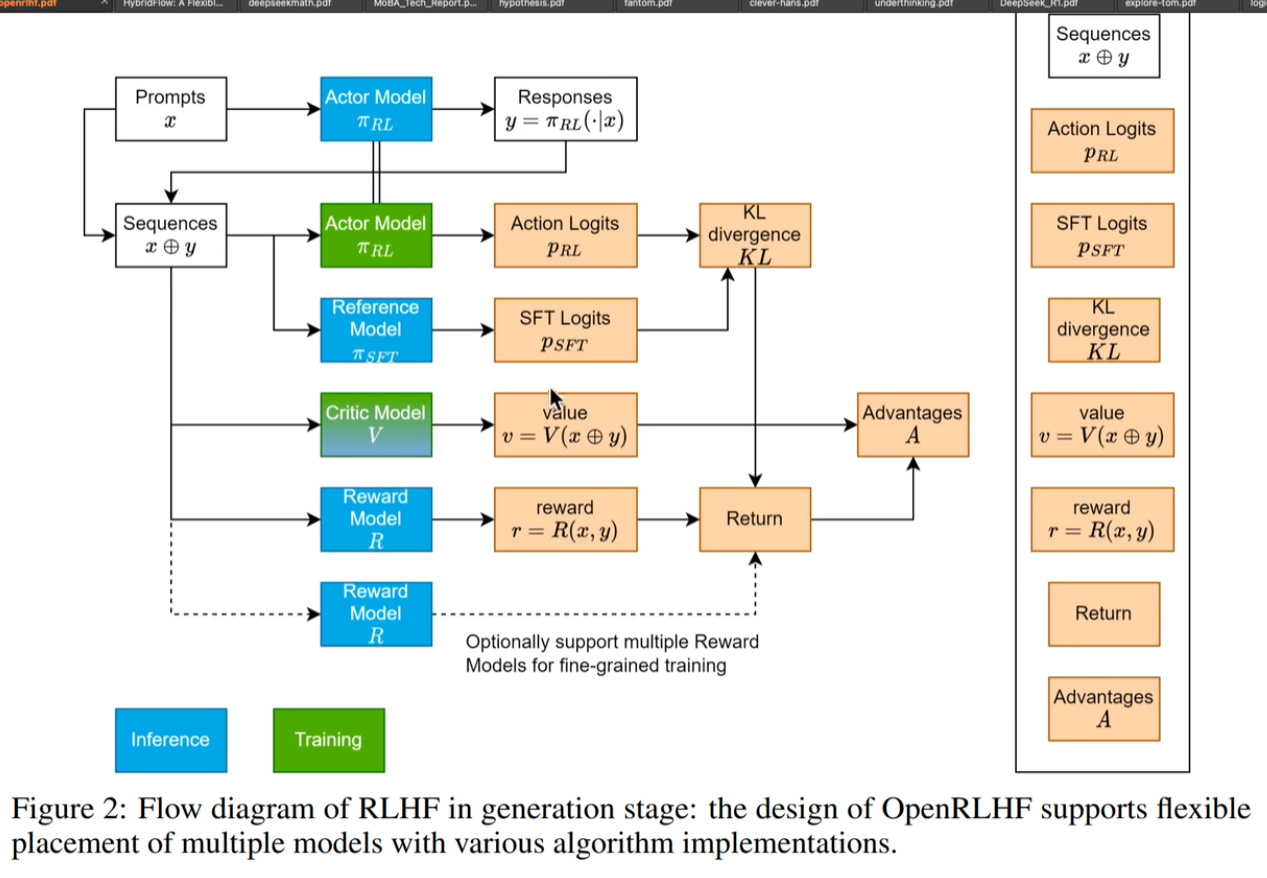
TRL ppo trainer
- https://github.com/huggingface/trl/blob/main/trl/trainer/ppo_trainer.py
- make experiences
- forward
- queries: `[4, 56]`
- reponses: `[4, 53]`($\pi_{\theta_{old}}$)
- logprobs: `[4, 53]` ($\pi_{\theta_{old}}$)
- ref_logprobs: `[4, 53]`($\pi_{ref}$)
- values: `[4, 53]`
- scores: `[4]` (last token's, the whole query + reponse)
- 计算 rewards (token 级别)
- $r_t = r_{T} - \beta (\log\pi_\theta-\log\pi_{ref})$
- 内循环;
- KL 项是 k1 近似;
- 计算 advantage & return
- GAE:
- $\delta_t=r_t+\gamma V(s_{t+1})-V(s_t)$
- $A_t=\sum_{k=0}^T(\gamma\lambda)^k\delta_{t+k}$
- return: advantage + value
- ppo update ($\pi_\theta$)
adv(advantage) estimator
- GAE
- GRPO
- RLOO
- REINFORCE++
- ReMax
verl/trainer/ppo/ray_trainer.py/compute_advantage
verl/trainer/ppo/core_algos.py
https://verl.readthedocs.io/en/latest/examples/config.html
- compute_gae_advantage_return
token_level_rewards,values- A t G A E = ∑ ℓ T − t ( γ λ ) ℓ δ t + ℓ , δ t = r t + γ V ( s t + 1 ) − V ( s t ) A_t^{GAE}=\sum_{\ell}^{T-t}(\gamma\lambda)^{\ell}\delta_{t+\ell}, \quad \delta_t=r_t+\gamma V(s_{t+1})-V(s_t) AtGAE=∑ℓT−t(γλ)ℓδt+ℓ,δt=rt+γV(st+1)−V(st)
- return: r e t t = V ( s t ) + A t G A E ret_t=V(s_t)+A_t^{GAE} rett=V(st)+AtGAE
- compute_grpo_outcome_advantage
token_level_rewards- A i = r i − μ σ + ϵ A_i=\frac{r_i-\mu}{\sigma+\epsilon} Ai=σ+ϵri−μ
- compute_rloo_outcome_advantage
token_level_rewards- A i = R i − 1 n − 1 ∑ k ≠ i R k A_i=R_i-\frac1{n-1}\sum_{k\neq i}R_k Ai=Ri−n−11∑k=iRk
- compute_reinforce_plus_plus_outcome_advantage
token_level_rewards-
A
t
=
G
t
−
μ
σ
,
G
t
=
∑
k
=
t
T
γ
k
−
t
r
k
A_t=\frac{G_t-\mu}{\sigma}, \quad G_t=\sum_{k=t}^T\gamma^{k-t}r_k
At=σGt−μ,Gt=∑k=tTγk−trk
- return: accumulate discounted reward
- compute_remax_outcome_advantage(Reward-Maximization with Baseline)
token_level_rewards,reward_baselines-
A
t
=
G
t
−
b
,
G
t
=
∑
k
=
t
T
r
k
A_t=G_t-b, \quad G_t=\sum_{k=t}^Tr_k
At=Gt−b,Gt=∑k=tTrk
- no discounted return
9 [RL4LLM] 深入 PPO-clip 目标函数细节(及重要性采样)
https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/basics_insights_of_RL/importance_sampling.ipynb
https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/basics_insights_of_RL/PPO_clip.ipynb
https://huggingface.co/blog/deep-rl-ppo
强化学习 (online) 和传统监督学习(offline)一个很大的区别就是“训练数据是当场采集出来的”,一边造数据,一边训模型,然后用新的模型接着造数据,训模型。
import numpy as np
import matplotlib.pyplot as plt
P P O c l i p = min ( r ( θ ) A , clip ( r ( θ ) , 1 − ϵ , 1 + ϵ ) A ) PPO_{clip}=\min(r(\theta)A, \text{clip}(r(\theta), 1-\epsilon, 1+\epsilon)A) PPOclip=min(r(θ)A,clip(r(θ),1−ϵ,1+ϵ)A)
- 策略更新比率(ratio): r ( θ ) = π θ ( a ∣ s ) π θ old ( a ∣ s ) r(\theta)=\frac{\pi_\theta(a|s)}{\pi_{\theta_\text{old}}(a|s)} r(θ)=πθold(a∣s)πθ(a∣s)
- Advantage(优势函数)本身不直接参与梯度计算
- PPO 的 clip 操作,会导致这条数据没有梯度,这条训练数据就起不到贡献了
-
A
>
0
A\gt 0
A>0(
r
(
θ
)
>
(
1
+
ϵ
)
r(\theta) > (1+\epsilon)
r(θ)>(1+ϵ)),截断为
A
(
1
+
ϵ
)
A(1+\epsilon)
A(1+ϵ),gradient 为 0
- r ( θ ) < 1 − ϵ r(\theta) < 1-\epsilon r(θ)<1−ϵ,取值为 A r Ar Ar,未被截断,gradient 为 A;
- A < 0 A\lt 0 A<0( r ( θ ) < ( 1 − ϵ ) r(\theta) < (1-\epsilon) r(θ)<(1−ϵ)),截断为 A ( 1 − ϵ ) A(1-\epsilon) A(1−ϵ),gradient 为 0
-
A
>
0
A\gt 0
A>0(
r
(
θ
)
>
(
1
+
ϵ
)
r(\theta) > (1+\epsilon)
r(θ)>(1+ϵ)),截断为
A
(
1
+
ϵ
)
A(1+\epsilon)
A(1+ϵ),gradient 为 0
clip
-
A
>
0
A>0
A>0 时(鼓励
π
(
a
t
∣
s
t
)
\pi(a_t|s_t)
π(at∣st) 提升 likelihood ratio),
r
≥
1
+
ϵ
r\geq 1+\epsilon
r≥1+ϵ,则取为
(
1
+
ϵ
)
A
(1+\epsilon)A
(1+ϵ)A(梯度为0)
- 目标函数此时没有梯度,不会继续增加 likelihood
- A < 0 A<0 A<0 时(抑制 π ( a t ∣ s t ) \pi(a_t|s_t) π(at∣st) 降低 likelihood ratio), r ≤ 1 − ϵ r \leq 1-\epsilon r≤1−ϵ,则取值为 ( 1 − ϵ ) A (1-\epsilon)A (1−ϵ)A(梯度为0)
- 还有一个问题,为什么不可以只取
clip
(
r
,
1
−
ϵ
,
1
+
ϵ
)
A
\text{clip}(r, 1-\epsilon, 1+\epsilon)A
clip(r,1−ϵ,1+ϵ)A
- A > 0 A\gt 0 A>0, r < ( 1 − ϵ ) r \lt (1-\epsilon) r<(1−ϵ) 时(初始就已经偏离很大),有 A r < A ( 1 − ϵ ) Ar \lt A(1-\epsilon) Ar<A(1−ϵ),min 操作使得目标函数为 A r Ar Ar 继续保持梯度,提升 r r r(往上升)
- A < 0 A\lt 0 A<0, r > ( 1 + ϵ ) r \gt (1+\epsilon) r>(1+ϵ) 时(初始就已经偏离很大),有 A r < A ( 1 + ϵ ) Ar \lt A(1+\epsilon) Ar<A(1+ϵ), min 操作使得目标函数为 A r Ar Ar 继续保持梯度,降低 r r r(往下拉)
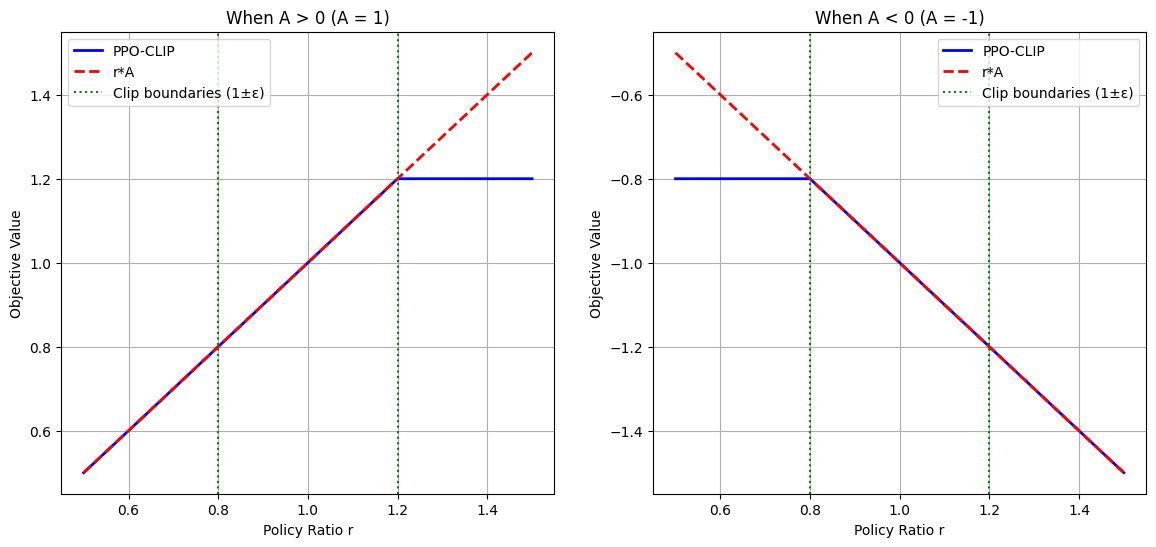
def ppo_clip(r, A, eps=0.2):
return np.minimum(r * A, np.clip(r, 1-eps, 1+eps) * A)
fig, axs = plt.subplots(1, 2, figsize=(14, 6))
# Set basic parameters
eps = 0.2
r_values = np.linspace(0.5, 1.5, 1000) # r uniformly distributed from 0.5 to 1.5
# First case: A > 0 (A = 1)
A = 1
ppo_values = ppo_clip(r_values, A, eps)
original_values = r_values * A # Original policy gradient objective
axs[0].plot(r_values, ppo_values, 'b-', linewidth=2, label='PPO-CLIP')
axs[0].plot(r_values, original_values, 'r--', linewidth=2, label='r*A')
# Draw clipping boundaries
axs[0].axvline(x=1-eps, color='g', linestyle=':', label='Clip boundaries (1±ε)')
axs[0].axvline(x=1+eps, color='g', linestyle=':')
axs[0].set_title('When A > 0 (A = 1)')
axs[0].set_xlabel('Policy Ratio r')
axs[0].set_ylabel('Objective Value')
axs[0].legend()
axs[0].grid(True)
# Second case: A < 0 (A = -1)
A = -1
ppo_values = ppo_clip(r_values, A, eps)
original_values = r_values * A # Original policy gradient objective
axs[1].plot(r_values, ppo_values, 'b-', linewidth=2, label='PPO-CLIP')
axs[1].plot(r_values, original_values, 'r--', linewidth=2, label='r*A')
# Draw clipping boundaries
axs[1].axvline(x=1-eps, color='g', linestyle=':', label='Clip boundaries (1±ε)')
axs[1].axvline(x=1+eps, color='g', linestyle=':')
axs[1].set_title('When A < 0 (A = -1)')
axs[1].set_xlabel('Policy Ratio r')
axs[1].set_ylabel('Objective Value')
axs[1].legend()
axs[1].grid(True)
期望计算
E x ∼ p [ f ( x ) ] = ∫ p ( x ) f ( x ) d x = ∫ q ( x ) p ( x ) q ( x ) f ( x ) d x = E x ∼ q [ p ( x ) q ( x ) f ( x ) ] \begin{split} \mathbb E_{x\sim p}[f(x)]=\int p(x)f(x)dx\\ =\int q(x)\frac{p(x)}{q(x)}f(x)dx\\ =\mathbb E_{x\sim q}\left[\frac{p(x)}{q(x)}f(x)\right] \end{split} Ex∼p[f(x)]=∫p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Ex∼q[q(x)p(x)f(x)]
-
Importance sampling (IS) is a Monte Carlo technique for the approximation of intractable distributions and integrals with respect to them.
- 最开始引入 IS 要解决的问题是不好对 x ∼ p ( x ) x\sim p(x) x∼p(x) 直接进行采样,而好对 x ∼ q ( x ) x\sim q(x) x∼q(x) 进行采样(这是我们认为设计和选择的)
- https://allenwind.github.io/blog/10466/
-
二者均值一样,不代表方差一样;
- V a r x ∼ p [ f ] = E x ∼ p [ f 2 ] − . . . Var_{x\sim p}[f]=E_{x\sim p}[f^2] - ... Varx∼p[f]=Ex∼p[f2]−...
- V a r x ∼ q [ p q f ] = E x ∼ q [ ( p q f ) 2 ] − . . . = E x ∼ p [ p q f 2 ] − . . . Var_{x\sim q}[\frac pq f]=E_{x\sim q}\left[\left(\frac{p}{q}f\right)^2\right] - ...=E_{x\sim p}[\frac pq f^2]-... Varx∼q[qpf]=Ex∼q[(qpf)2]−...=Ex∼p[qpf2]−...
- 如果 p q \frac pq qp 差异很大的话,后者的方差就会很大;
-
x ∼ q x\sim q x∼q: sampling
-
w n = p ( x n ) q ( x n ) w_n=\frac{p(x_n)}{q(x_n)} wn=q(xn)p(xn): imporance weight
-
在 RL4LLM 的训练中,引入重要性采样,使得 on-policy 的算法(数据利用率较低)可以变得相对地 off-policy
- 考虑如下的 policy gradient
= E ( s t , a t ) ∼ π θ [ A θ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ∇ log p θ ( a t n ∣ s t n ) ] \begin{split} &= E_{(s_t, a_t) \sim \pi_\theta} [A^\theta(s_t, a_t) \nabla \log p_\theta(a_t^n | s_t^n)]\\ &= E_{(s_t, a_t) \sim \pi_{\theta'}} \left[ \frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)} A^{\theta'}(s_t, a_t) \nabla \log p_\theta(a_t^n | s_t^n) \right] \end{split} =E(st,at)∼πθ[Aθ(st,at)∇logpθ(atn∣stn)]=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)∇logpθ(atn∣stn)] - generate 的样本,可以 update policy 多次;
- 重要性采样需要大量样本才能做到无偏替代
J P P O ( θ ) = E q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) [ 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ϵ , 1 + ϵ ) A t ) ] \mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim P(Q), o \sim \pi_{\theta_{old}}(O|q)} \left[ \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left( \frac{\pi_{\theta}(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})} A_t, \text{clip} \left( \frac{\pi_{\theta}(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})}, 1-\epsilon, 1+\epsilon \right) A_t \right) \right] JPPO(θ)=Eq∼P(Q),o∼πθold(O∣q) ∣o∣1t=1∑∣o∣min(πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ϵ,1+ϵ)At)
- 考虑如下的 policy gradient
-
https://zhuanlan.zhihu.com/p/17657567877
- 先普及两个 RLHF 算法中的重要参数:rollout_batch_size 和 train_batch_size,前者代表一次性生成多少条训练数据(response 和 reward),后者代表每次用多少条数据来更新模型,前者是后者的 N 倍。
- 随着训练框架的不断优化, RLHF 的训练数据并没有那么难生产了,尤其是像 OpenRLHF 这种框架,引入了 vllm 来生产 response,效率极高。我们完全可以令 N = 1 / 2 / 4 这种很小的值,且每条训练数据仅使用一次。事实上,由于重要性采样需要大量样本才能做到无偏替代,这个 N 值还真不能很大,越大就越容易训崩。
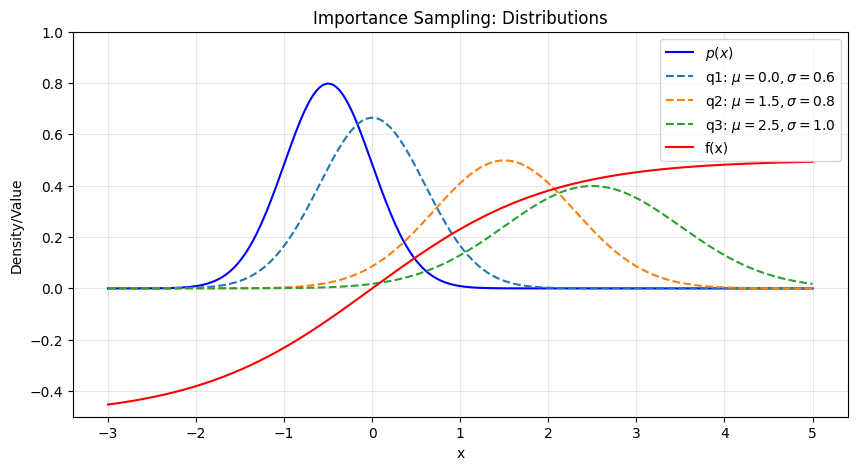
import numpy as np
import matplotlib.pyplot as plt
from math import sqrt, pi, exp
np.random.seed(1234)
mu_p, sigma_p = -0.5, 0.5
def p(x):
return 1/(sqrt(2*pi)*sigma_p) * exp(-((x - mu_p)**2)/(2*sigma_p**2))
def q(x, mu, sigma):
return 1/(sqrt(2*pi)*sigma) * exp(-((x - mu)**2)/(2*sigma**2))
def f(x):
return 1 / (1 + exp(-x)) - 0.5
# Define several different q distributions with varying distances from p
q_params = [
(0.0, 0.6, "q1: $\mu=0.0, \sigma=0.6$"), # Closer to p
(1.5, 0.8, "q2: $\mu=1.5, \sigma=0.8$"), # Original q
(2.5, 1.0, "q3: $\mu=2.5, \sigma=1.0$"), # Further from p
]
xs = np.linspace(-3, 5, 300)
pxs = [p(x) for x in xs]
fxs = [f(x) for x in xs]
plt.figure(figsize=(10,5))
plt.plot(xs, pxs, label='$p(x)$', color='blue')
for mu, sigma, label in q_params:
qxs = [q(x, mu, sigma) for x in xs]
plt.plot(xs, qxs, label=label, linestyle='--')
plt.plot(xs, fxs, label='f(x)', color='red')
plt.ylim(-0.5, 1)
plt.legend()
plt.title('Importance Sampling: Distributions')
plt.xlabel('x')
plt.ylabel('Density/Value')
plt.grid(alpha=0.3)
# Calculate ground truth by direct sampling from p
samples = np.random.normal(loc=mu_p, scale=sigma_p, size=1000000)
mean_fp = np.mean([f(x) for x in samples])
print(f'Ground truth expectation under p(x): {mean_fp:.6f}')
# Ground truth expectation under p(x): -0.116002
# Importance sampling with varying sample sizes
sample_sizes = [10, 100, 1000, 10000, 100000]
results = {label: [] for _, _, label in q_params}
true_value = mean_fp
plt.figure(figsize=(10,6))
for mu, sigma, label in q_params:
for size in sample_sizes:
samples = np.random.normal(loc=mu, scale=sigma, size=size)
weights = np.array([p(x) / q(x, mu, sigma) for x in samples])
mean_is = np.mean(weights * np.array([f(x) for x in samples]))
results[label].append(mean_is)
print(f"Distribution {label}, Sample size {size}: {mean_is:.6f}")
plt.plot(sample_sizes, results[label], 'o-', label=label)
plt.axhline(y=true_value, color='r', linestyle='-', label='True expectation')
plt.xscale('log')
plt.grid(True, which="both", ls="--", alpha=0.3)
plt.xlabel('Number of Samples')
plt.ylabel('Estimated Expectation')
plt.title('Importance Sampling Estimates vs. Sample Size')
plt.legend()
plt.tight_layout()
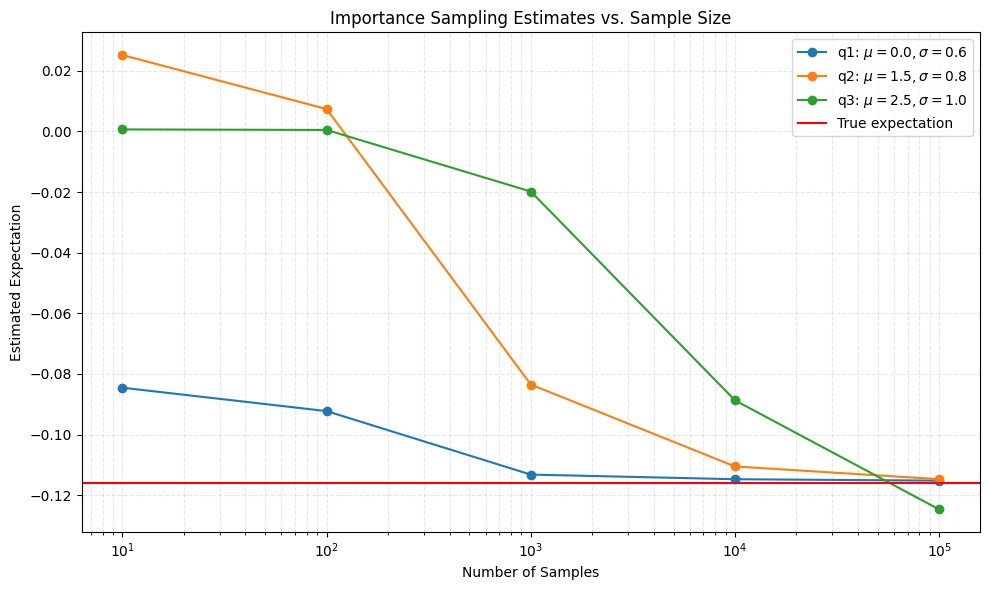
输出:
Distribution q1: $\mu=0.0, \sigma=0.6$, Sample size 10: -0.084525
Distribution q1: $\mu=0.0, \sigma=0.6$, Sample size 100: -0.092245
Distribution q1: $\mu=0.0, \sigma=0.6$, Sample size 1000: -0.113189
Distribution q1: $\mu=0.0, \sigma=0.6$, Sample size 10000: -0.114711
Distribution q1: $\mu=0.0, \sigma=0.6$, Sample size 100000: -0.115185
Distribution q2: $\mu=1.5, \sigma=0.8$, Sample size 10: 0.025215
Distribution q2: $\mu=1.5, \sigma=0.8$, Sample size 100: 0.007397
Distribution q2: $\mu=1.5, \sigma=0.8$, Sample size 1000: -0.083480
Distribution q2: $\mu=1.5, \sigma=0.8$, Sample size 10000: -0.110500
Distribution q2: $\mu=1.5, \sigma=0.8$, Sample size 100000: -0.114701
Distribution q3: $\mu=2.5, \sigma=1.0$, Sample size 10: 0.000679
Distribution q3: $\mu=2.5, \sigma=1.0$, Sample size 100: 0.000508
Distribution q3: $\mu=2.5, \sigma=1.0$, Sample size 1000: -0.019807
Distribution q3: $\mu=2.5, \sigma=1.0$, Sample size 10000: -0.088690
Distribution q3: $\mu=2.5, \sigma=1.0$, Sample size 100000: -0.124670
10 [RL4LLM] GRPO loss/objective 分析 及可能的 biases 分析(DAPO,Dr. GRPO)
- video: https://www.bilibili.com/video/BV1LgXbY5EFD
- code: https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/r1-k1.5/grpo_loss.ipynb
最近清华新加坡提出了一个DAPO,DrGRPO之类的东西
- DAPO:
- https://dapo-sia.github.io
- Dr. GRPO
- https://github.com/sail-sg/understand-r1-zero
1 思维误区:损失为零无法优化
loss = 0
loss 为 0 为什么还可以反向传播,更新梯度;
- loss 为 0,不意味着 gradient 为 0
-
f
(
w
)
=
(
w
−
1
)
2
−
1
f(w)=(w-1)^2-1
f(w)=(w−1)2−1,在
w
=
0
w=0
w=0 时,
f
(
w
)
=
0
f(w)=0
f(w)=0,但其实其 gradient 为 -2
- 梯度 * 学习率 才是 learning 的本质;
- w − η ⋅ g = 0 − ( 0.1 ∗ − 2 ) = 0.2 w-\eta\cdot g=0-(0.1*-2)=0.2 w−η⋅g=0−(0.1∗−2)=0.2
-
f
(
w
)
=
(
w
−
1
)
2
−
1
f(w)=(w-1)^2-1
f(w)=(w−1)2−1,在
w
=
0
w=0
w=0 时,
f
(
w
)
=
0
f(w)=0
f(w)=0,但其实其 gradient 为 -2
- loss 不再是一个好的 monitor 指标,而是 reward
但是实际上在损失的设计上,一般都是以零为下界的,即便是引入一些正则项,分项的损失基本上都是以零为主。
一个非常经典的关于GRPO的帖子:
- https://github.com/huggingface/trl/issues/2608#issuecomment-2609844003
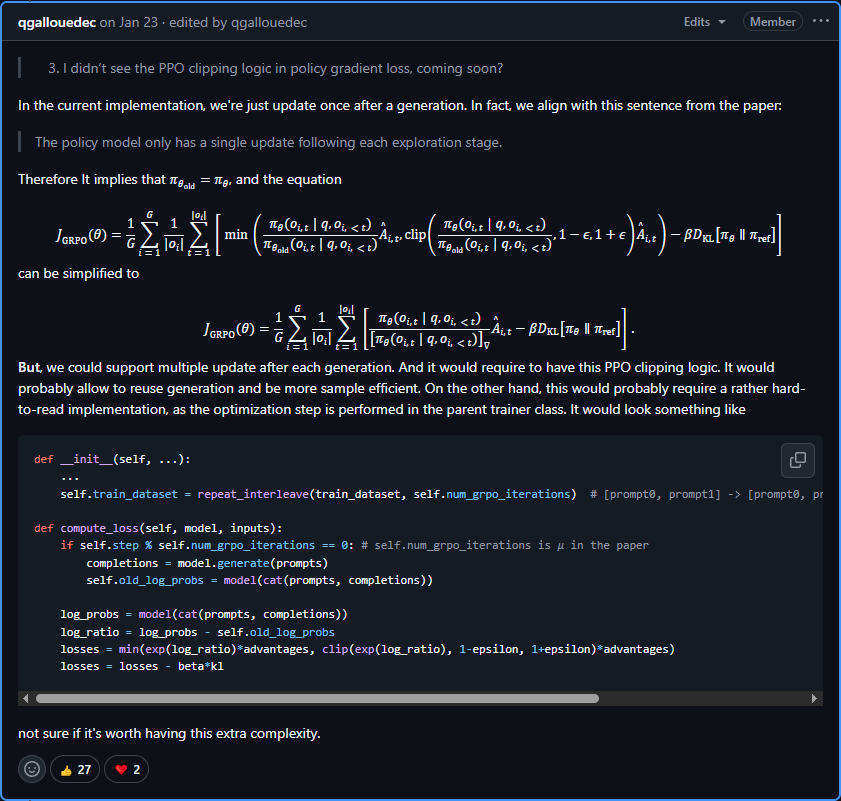
注意上面第二个式子GRPO的loss, π \pi π除以 π \pi π(分母是detach的),不是1吗,并不是这样的,看下面的例子:
import torch
# 情况1: x - x (梯度为0)
x = torch.tensor([3.0], requires_grad=True)
y1 = x - x
y1.backward() # 反向传播计算梯度
print("Gradient for x - x:", x.grad.item()) # 输出 0.0
# 清除梯度,准备下一个示例
x.grad.zero_()
# 情况2: x - x.detach() (梯度为1)
y2 = x - x.detach() # 分离第二个x,使其视为常数
y2.backward() # 反向传播计算梯度
print("Gradient for x - x.detach():", x.grad.item()) # 输出 1.0
这是loss上的一个特点,所谓detach就是不计算梯度(应该就是可以理解为是常数),这样虽然看起来是1,但其实并不是,分母是一个常数而已。
loss = β k l \beta kl βkl
GitHub Issue: Why does the loss start at 0 when I train GRPO, and then possibly increase?
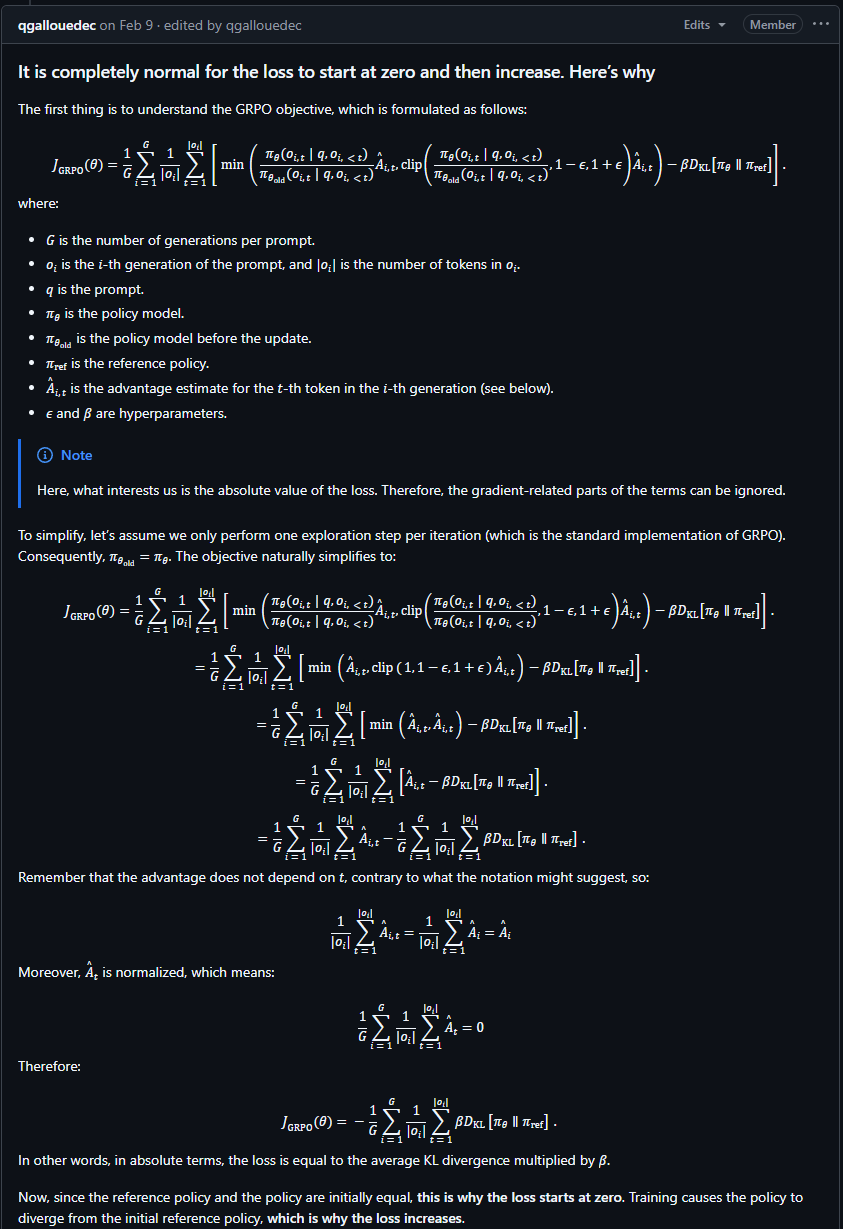
-
这是另一个问题帖
-
trl grpo
-
β
=
0.04
\beta = 0.04
β=0.04(default,
GRPOConfig) - 这个值其实是比较大的,math 用 0.001??
-
β
=
0.04
\beta = 0.04
β=0.04(default,
-
抛开 kl
- 一个 prompt 多个 generations(为一个 group)
- 每个 generation 对应的 loss = -advantage (likelihood ratio = 1, π θ = π θ o l d \pi_\theta=\pi_{\theta_{old}} πθ=πθold)
- 一个 group 的 mean loss = - mean advantage = 0
- 注意图中的J都是梯度上升,求和式前都少了一个负号
- 一个 prompt 多个 generations(为一个 group)
-
kl 的位置
- 定义在 advantage 计算 reward 时
- 定义在外部
- grpo 原始公式是定义在外部的;
- the GRPO implementation does not include the KL-divergence as part of the reward function. Instead, it directly incorporates the KL-divergence into the loss function, arguing that this approach simplifies the computation and avoids unnecessary complexity.

J
G
R
P
O
(
θ
)
=
E
q
∼
P
(
Q
)
,
{
o
i
}
i
=
1
G
∼
π
θ
o
l
d
(
O
∣
q
)
[
1
G
∑
i
=
1
G
1
∣
o
i
∣
∑
t
=
1
∣
o
i
∣
min
(
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
o
l
d
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
A
^
i
,
t
,
clip
(
π
θ
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
π
θ
o
l
d
(
o
i
,
t
∣
q
,
o
i
,
<
t
)
,
1
−
ε
,
1
+
ε
)
A
^
i
,
t
)
−
β
D
K
L
(
π
θ
∣
∣
π
r
e
f
)
]
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q \sim P(Q), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\varepsilon, 1+\varepsilon \right) \hat{A}_{i,t} \right) - \beta D_{KL} (\pi_\theta || \pi_{ref}) \right]
JGRPO(θ)=Eq∼P(Q),{oi}i=1G∼πθold(O∣q)
G1i=1∑G∣oi∣1t=1∑∣oi∣min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t)−βDKL(πθ∣∣πref)
- first averaging the losses by token within each sample and then aggregating the losses across samples.
- each sample is assigned an equal weight in the final loss computation
- 对比看下 DAPO 的公式(12)
- If you are using the GRPO trainer then the old policy is in effect updated every step, this means you just use a detached version of the current policy.
- 公式中的 π θ o l d \pi_{\theta_{old}} πθold 是 π θ \pi_\theta πθ 的 detach 版(不参与计算图,视为常数);
- r = π θ π θ o l d = 1 r=\frac{\pi_\theta}{\pi_{\theta_{old}}}=1 r=πθoldπθ=1,
- clip ( 1 , 1 − ϵ , 1 + ϵ ) = 1 \text{clip}(1, 1-\epsilon, 1+\epsilon)=1 clip(1,1−ϵ,1+ϵ)=1
- A ^ i , t = r ~ i = r i − μ σ \hat A_{i,t}=\tilde r_i=\frac{r_i-\mu}{\sigma} A^i,t=r~i=σri−μ (z score) (token 级别的 adv = output 级别的 reward 组内 z-score 而来)
J G R P O ( θ ) = 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ min ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ) − β D K L ( π θ ∣ ∣ π r e f ) = 1 G ∑ i G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ A ^ i , t − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = 1 G ∑ i G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ A ^ i − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = 1 G ∑ i G 1 ∣ o i ∣ ∣ o i ∣ ⋅ A ^ i − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = 1 G ∑ i G A ^ i − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = 1 G ∑ i G r i − μ σ − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = ∑ i r i − G μ G − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = 0 − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] = − 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ β D k l [ π θ ∣ π r e f ] \begin{split} \mathcal{J}_{GRPO}(\theta)&= \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \min \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})} \hat{A}_{i,t}, \text{clip} \left( \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}, 1-\varepsilon, 1+\varepsilon \right) \hat{A}_{i,t} \right) - \beta D_{KL} (\pi_\theta || \pi_{ref}) \\ &=\frac1G\sum_i^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\hat A_{i,t} -\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=\frac1G\sum_i^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\hat A_i -\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=\frac1G\sum_i^G\frac1{|o_i|} {|o_i|}\cdot \hat A_i -\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=\frac1G\sum_i^G\hat A_i-\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=\frac1G\sum_i^G\frac{r_i-\mu}{\sigma}-\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=\frac{\sum_i r_i-G\mu}{G}-\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &= 0 -\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}]\\ &=-\frac1G\sum_{i=1}^G\frac1{|o_i|}\sum_{t=1}^{|o_i|}\beta D_{kl}[\pi_\theta|\pi_{ref}] \end{split} JGRPO(θ)=G1i=1∑G∣oi∣1t=1∑∣oi∣min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t)−βDKL(πθ∣∣πref)=G1i∑G∣oi∣1t=1∑∣oi∣A^i,t−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=G1i∑G∣oi∣1t=1∑∣oi∣A^i−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=G1i∑G∣oi∣1∣oi∣⋅A^i−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=G1i∑GA^i−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=G1i∑Gσri−μ−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=G∑iri−Gμ−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=0−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]=−G1i=1∑G∣oi∣1t=1∑∣oi∣βDkl[πθ∣πref]
所以其实advantage前面的系数( π / π \pi/\pi π/π)计算上就是 1 1 1,最终的真实loss就是 − β K L -\beta KL −βKL,这个结论很重要
KL散度变大说明模型在尝试一些偏离模型原有的方向,以获得提升,类似模拟退火中的跳出局部最优,这有时是好事,但KL散度不宜过高。
这里再强调一下策略KL散度的一个计算(deepseekmath的eq4):
D K L [ π θ ∥ π r e f ] = π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − log π r e f ( o i , t ∣ q , o i , < t ) π θ ( o i , t ∣ q , o i , < t ) − 1 \mathbb{D}_{KL}[\pi_\theta\|\pi_{ref}]=\frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})}-\log\frac{\pi_{ref}(o_{i,t}|q,o_{i,<t})}{\pi_\theta(o_{i,t}|q,o_{i,<t})}-1 DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1
GRPO的梯度?
回顾PG中常用的公式:
f
′
(
x
)
=
f
(
x
)
∇
log
f
(
x
)
f'(x)=f(x)\nabla\log f(x)
f′(x)=f(x)∇logf(x)
这个公式其实很显然成立:因为 ∇ log f ( x ) = f ′ ( x ) f ( x ) \nabla \log f(x)=\frac{f'(x)}{f(x)} ∇logf(x)=f(x)f′(x),这样写完全是为了方便计算实现以及一些推导。

- For example for GRPO, if all outputs
{
o
i
}
i
=
1
G
\{o_i\}^G_{i=1}
{oi}i=1G of a particular prompt are correct and receive the same reward 1, the resulting advantage for this group is zero. A zero advantage results in no gradients for policy
updates, thereby reducing sample efficiency.(GRPO的特点:如果advantage是0,即全对或者全错,那么是不会产生有效的gradient,即这轮就是无任何更新,下面的DAPO的创新之一就是解决了这个问题) - deepseelmath disscussion 部分:他们认为所有的PGLoss都可以统一在一个范式下的,不管PPO、GRPO还是之后可能出现的种种
token级别的PG损失(即DAPO)
- grpo: generation-level loss, dapo: token-level pg loss
- grpo: 先部分(generation)去平均,再在 group 级别取平均
- dapo: group 里,所有的 generations,所有的tokens 取平均
- ga (gradient accumulation)
- https://unsloth.ai/blog/gradient
GRPO的一个bias:
- 假如advantage > 0,即模型答对了,则倾向于简短的答案
- 加入advantage < 0,即模型答错了,则倾向于更长的答案
- 带有更低标准差的问题在更新迭代中会得到更高的权重,所谓标准差低,表示这种问题是简单的,回答10次9次都对,标准差高的问题就是回答不稳定的问题。这种现象也不太好,因为难的问题才是更重要的问题。
2 关于Dr. GRPO
A i = R i − 1 N ∑ j = 1 N R j A_i=R_i-\frac1N\sum_{j=1}^N R_j Ai=Ri−N1j=1∑NRj
-
R
i
=
θ
+
ϵ
i
R_i=\theta+\epsilon_i
Ri=θ+ϵi,带入上式得
- A i = θ + ϵ i − 1 N ∑ j ( θ + ϵ i ) = ϵ i − 1 N ∑ ϵ j A_i=\theta+\epsilon_i-\frac1N\sum_j (\theta+\epsilon_i)=\epsilon_i-\frac1N\sum \epsilon_j Ai=θ+ϵi−N1∑j(θ+ϵi)=ϵi−N1∑ϵj
E [ A i ∣ ϵ i ] = E [ ϵ i − 1 N ∑ ϵ j ∣ ϵ i ] = ϵ i − 1 N ϵ i − 1 N ∑ j ≠ i N 0 = N − 1 N ϵ i \begin{split} \mathbb E[A_i|\epsilon_i]&=\mathbb E [\epsilon_i - \frac1N\sum\epsilon_j | \epsilon_i]\\ &=\epsilon_i - \frac1N\epsilon_i-\frac1N\sum_{j\neq i}^N 0\\ &=\frac{N-1}N\epsilon_i \end{split} E[Ai∣ϵi]=E[ϵi−N1∑ϵj∣ϵi]=ϵi−N1ϵi−N1j=i∑N0=NN−1ϵi
3 per_device_train_batch_size & num_generations
https://github.com/huggingface/trl/pull/2776
-
(
num_processes * per_device_batch_size) must be divisible byG.per_device_batch_size刻画的是 gpu device 粒度 generations 的数量num_processes是 gpu 进程的数量;num_processes * per_device_batch_size/G: prompts 吞吐量
-
https://github.com/huggingface/trl/blob/main/trl/trainer/grpo_trainer.py#L571-L598
- ensures each prompt is repeated across multiple processes. This guarantees that identical prompts are distributed to different GPUs, allowing rewards to be computed and normalized correctly within each prompt group. Using the same seed across processes ensures consistent prompt assignment, preventing discrepancies in group formation.
- repeats the batch multiple times to allow reusing generations across multiple updates. Refer to _prepare_inputs to see how the generations are stored and reused.
- In the following figure, the values are the prompt indices. The first row shows the first sampled batch, the
second row shows the second sampled batch, and so on. - 3 个 gpus,num_generations = 3,per_device_train_batch_size = 4
- 3*4 / 3 = 4
GPU0 GPU1 GPU2 P0 P00 P01 P02 P1 P10 P11 P12 P2 P20 P21 P22 P3 P30 P31 P32 - 进一步还考虑到了
grad_accum= 3,累加 batch forward,统一 backward
目前来说,还是有很多争议的地方,到头肯定还是哪个work用哪个
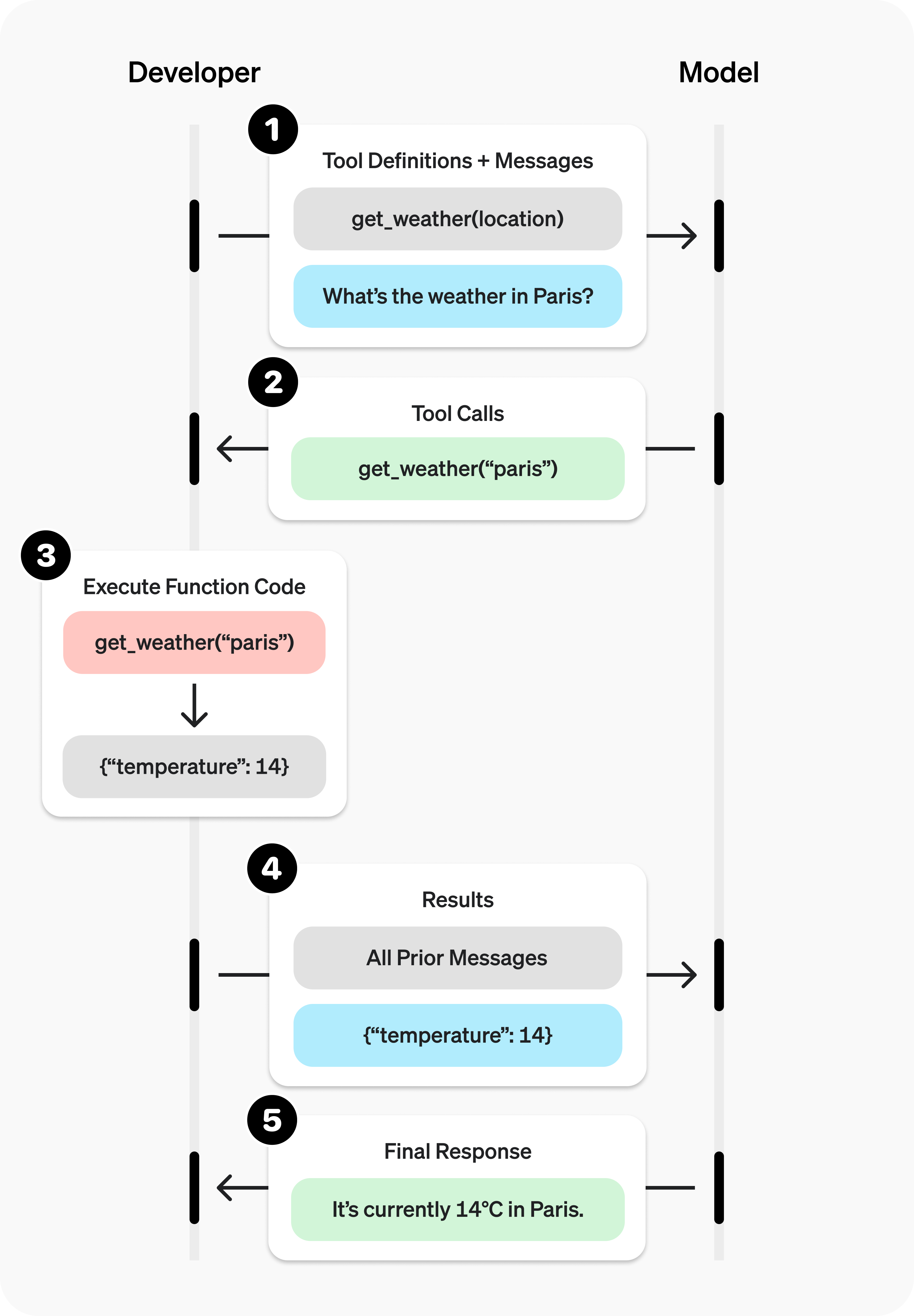
11 [RL4LLM] deepseek v3 工具调用的 bug 以及理解 chat_template 的 function calling
video: https://www.bilibili.com/video/BV1dsdWYuEXw
code: https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/tokenizer/v3.ipynb
这边链接里的issue说了v3有个重复调用工具的BUG,示例是关于一个调用天气的工具,即时在message里添加了已经调用了工具的标记,v3还是会问天气。
- https://github.com/deepseek-ai/DeepSeek-V3/issues/15
- deepseek v3 (0324): “Increased accuracy in Function Calling, fixing issues from previous V3 versions”
- https://huggingface.co/deepseek-ai/DeepSeek-V3-0324
- repetitive function call
- 从 token 或者 chat_template 的角度理解 tool use / function calling,使用(inference)以及 training
- System prompt: 有哪些工具,参数是什么 。。
- User prompt:
What's the weather like today in New York? <tool>get_current_template(location='New York, NY', format='F')</tool><output>73 degrees Fahrenheit</output>
这个是工具使用的一个样例,其实训练时都是这么做的。
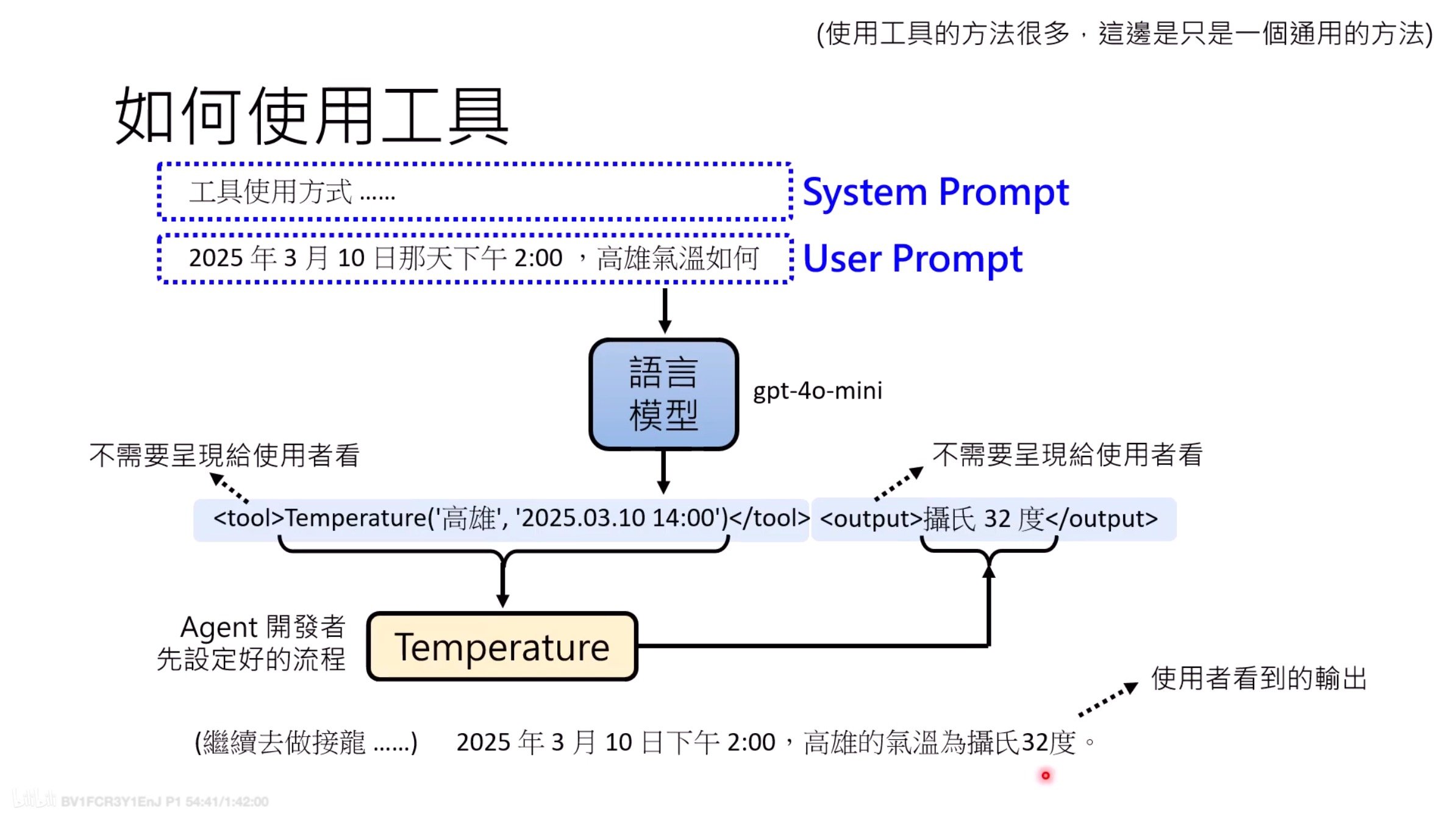
from transformers import AutoTokenizer
import re
import torch
model_id = 'deepseek-ai/DeepSeek-V3'
model_id_0324 = 'deepseek-ai/DeepSeek-V3-0324'
T1 = AutoTokenizer.from_pretrained(model_id)
T2 = AutoTokenizer.from_pretrained(model_id_0324)
注:v3-0324是更好的版本,在官方文档里说修了重复调用工具的BUG
也就是说下面的代码中,T1是有问题的版本,T2是修复后的,我们需要对比看看哪里改进了
v3 的chat template
即T1.chat_template,如下所示:
{# 设置默认变量 #}
{% if add_generation_prompt is not defined %}
{% set add_generation_prompt = false %}
{% endif %}
{# 定义命名空间变量 #}
{% set ns = namespace(
is_first=false,
is_tool=false,
is_output_first=true,
system_prompt='',
is_first_sp=true
) %}
{# 拼接 system prompt #}
{% for message in messages %}
{% if message['role'] == 'system' %}
{% if ns.is_first_sp %}
{% set ns.system_prompt = ns.system_prompt + message['content'] %}
{% set ns.is_first_sp = false %}
{% else %}
{% set ns.system_prompt = ns.system_prompt + '\n' + message['content'] %}
{% endif %}
{% endif %}
{% endfor %}
{{ bos_token }}{{ ns.system_prompt }}
{# 遍历消息内容 #}
{% for message in messages %}
{# 用户消息处理 #}
{% if message['role'] == 'user' %}
{% set ns.is_tool = false %}
{{ '<|User|>' + message['content'] }}
{# 助手消息(带工具调用) #}
{% elif message['role'] == 'assistant' and message['content'] is none %}
{% set ns.is_tool = false %}
{% for tool in message['tool_calls'] %}
{% if not ns.is_first %}
{{ '<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n```json\n' + tool['function']['arguments'] + '\n```<|tool▁call▁end|>' }}
{% set ns.is_first = true %}
{% else %}
{{ '\n<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n```json\n' + tool['function']['arguments'] + '\n```<|tool▁call▁end|>' }}
{{ '<|tool▁calls▁end|><|end▁of▁sentence|>' }}
{% endif %}
{% endfor %}
{# 助手正常回复内容 #}
{% elif message['role'] == 'assistant' and message['content'] is not none %}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>' }}
{% set ns.is_tool = false %}
{% else %}
{{ '<|Assistant|>' + message['content'] + '<|end▁of▁sentence|>' }}
{% endif %}
{# 工具输出处理 #}
{% elif message['role'] == 'tool' %}
{% set ns.is_tool = true %}
{% if ns.is_output_first %}
{{ '<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{% set ns.is_output_first = false %}
{% else %}
{{ '\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{% endif %}
{% endif %}
{% endfor %}
{# 工具输出结尾处理 #}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' }}
{% endif %}
{# 生成助手响应起始标记 #}
{% if add_generation_prompt and not ns.is_tool %}
{{ '<|Assistant|>' }}
{% endif %}
用流程简图表示为:
初始化变量
│
├── 收集 system prompt
│
├── 遍历 messages:
│ ├── system → 拼接 prompt
│ ├── user → 加 <|User|>
│ ├── assistant:
│ │ ├── 若调用 tool → 生成 tool_call 块
│ │ └── 否则 → 加 <|Assistant|>
│ └── tool → 输出 tool_output 块
│
└── 最后判断是否需要加 <|Assistant|> 结束
工具调用的思考过程在<|Assistant|>标签内,实际调用的函数及参数则在<|tool_outputs_begin|>...<|tool_outputs_end|>之内。0324版本加了tool_call块,工具是包含在assistant之中的,下面的流程图画的很明显。
v3-0324 的 chat template
来看T2.chat_template
{# 设置默认值 #}
{% if add_generation_prompt is not defined %}
{% set add_generation_prompt = false %}
{% endif %}
{# 初始化状态变量 #}
{% set ns = namespace(
is_first=false,
is_tool=false,
is_output_first=true,
system_prompt='',
is_first_sp=true,
is_last_user=false
) %}
{# 拼接所有 system prompt #}
{% for message in messages %}
{% if message['role'] == 'system' %}
{% if ns.is_first_sp %}
{% set ns.system_prompt = ns.system_prompt + message['content'] %}
{% set ns.is_first_sp = false %}
{% else %}
{% set ns.system_prompt = ns.system_prompt + '\n' + message['content'] %}
{% endif %}
{% endif %}
{% endfor %}
{{ bos_token }}{{ ns.system_prompt }}
{# 遍历所有消息 #}
{% for message in messages %}
{# 处理用户消息 #}
{% if message['role'] == 'user' %}
{% set ns.is_tool = false %}
{% set ns.is_first = false %}
{% set ns.is_last_user = true %}
{{ '<|User|>' + message['content'] + '<|Assistant|>' }}
{# 处理 Assistant 调用工具的情况 #}
{% elif message['role'] == 'assistant' and message['tool_calls'] is defined and message['tool_calls'] is not none %}
{% set ns.is_last_user = false %}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' }}
{% endif %}
{% set ns.is_first = false %}
{% set ns.is_tool = false %}
{% set ns.is_output_first = true %}
{% for tool in message['tool_calls'] %}
{% set tool_call_str = '<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n```json\n' + tool['function']['arguments'] + '\n```<|tool▁call▁end|>' %}
{% if not ns.is_first %}
{% if message['content'] is none %}
{{ '<|tool▁calls▁begin|>' + tool_call_str }}
{% else %}
{{ message['content'] + '<|tool▁calls▁begin|>' + tool_call_str }}
{% endif %}
{% set ns.is_first = true %}
{% else %}
{{ '\n' + tool_call_str }}
{% endif %}
{% endfor %}
{{ '<|tool▁calls▁end|><|end▁of▁sentence|>' }}
{# Assistant 正常回复内容(无工具调用) #}
{% elif message['role'] == 'assistant' %}
{% set ns.is_last_user = false %}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>' }}
{% set ns.is_tool = false %}
{% else %}
{{ message['content'] + '<|end▁of▁sentence|>' }}
{% endif %}
{# 工具的输出内容 #}
{% elif message['role'] == 'tool' %}
{% set ns.is_last_user = false %}
{% set ns.is_tool = true %}
{% if ns.is_output_first %}
{{ '<|tool▁outputs▁begin|><|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{% set ns.is_output_first = false %}
{% else %}
{{ '\n<|tool▁output▁begin|>' + message['content'] + '<|tool▁output▁end|>' }}
{% endif %}
{% endif %}
{% endfor %}
{# 如果有残留的 tool 输出状态,则收尾结束 #}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' }}
{% endif %}
{# 最终是否生成 Assistant 提示起始符 #}
{% if add_generation_prompt and not ns.is_last_user and not ns.is_tool %}
{{ '<|Assistant|>' }}
{% endif %}
初始化变量(增加 is_last_user 等)
│
├── 收集 system prompt
│
├── 遍历 messages:
│ ├── system → 拼接 prompt
│ ├── user → 加 <|User|>,标记 is_last_user=True
│ ├── assistant:
│ │ ├── 若调用 tool_call:
│ │ │ └── 判断是否有 content(处理更细)
│ │ └── 若普通内容 → 加 <|Assistant|>
│ └── tool:
│ └── 多个 tool_output 串联,闭合处理
│
└── 若最后是 user 且无 tool 调用 → 加 <|Assistant|> 提示生成回复
`apply_chat_template
设置一段message
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's the weather in Paris?"},
{
"role": "assistant",
# "content": "Let me check the weather for you.",
"content": "",
"tool_calls": [
{
"type": "function",
"function": {
"name": "get_weather",
"arguments": '{ "location": "Paris" }'
}
}
]
},
{
"role": "tool",
"content": '{ "temperature": "15C", "condition": "Sunny" }',
"tool_call_id": "call_1"
},
{
"role": "assistant",
"content": "It's 15°C and sunny in Paris right now."
}
]
然后调用T1:T1.apply_chat_template(messages, tokenize=False)
输出:
<|begin▁of▁sentence|>You are a helpful assistant.
<|User|>What\'s the weather in Paris?
<|Assistant|>Let me check the weather for you.<|end▁of▁sentence|>
<|tool▁outputs▁begin|>
<|tool▁output▁begin|>{ "temperature": "15C", "condition": "Sunny" }<|tool▁output▁end|>
<|tool▁outputs▁end|>It\'s 15°C and sunny in Paris right now.<|end▁of▁sentence|>
注意,T1只有tool_outputs,但没有tool_call,而在下面的T2里则是多了tool_call,这就是为什么v3会重复调用BUG的问题。
同理:T2.apply_chat_template(messages, tokenize=False)
输出:
<|begin▁of▁sentence|>You are a helpful assistant.
<|User|>What\'s the weather in Paris?
<|Assistant|>Let me check the weather for you.
<|tool▁calls▁begin|>
<|tool▁call▁begin|>function<|tool▁sep|>get_weather\n```json\n{ "location": "Paris" }\n```<|tool▁call▁end|>
<|tool▁calls▁end|><|end▁of▁sentence|>
<|tool▁outputs▁begin|>
<|tool▁output▁begin|>{ "temperature": "15C", "condition": "Sunny" }<|tool▁output▁end|>
<|tool▁outputs▁end|>It\'s 15°C and sunny in Paris right now.<|end▁of▁sentence|>
- 两个 highlights
- v3 chat tempalte 解析 messages 时 丢了 tool_call 的部分
- tool_call 和 tool_output 是一体的,统一作为 <|Assistant|> 的输出
实验表明,即使把message中的content设置为空字符串,T1的apply_chat_template的显示结果还是不会有tool_call,还是有问题的。
因为回头看v3的chat template里这一段
{# 助手消息(带工具调用) #}
{% elif message['role'] == 'assistant' and message['content'] is none %}
{% set ns.is_tool = false %}
{% for tool in message['tool_calls'] %}
{% if not ns.is_first %}
{{ '<|Assistant|><|tool▁calls▁begin|><|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n```json\n' + tool['function']['arguments'] + '\n```<|tool▁call▁end|>' }}
{% set ns.is_first = true %}
{% else %}
{{ '\n<|tool▁call▁begin|>' + tool['type'] + '<|tool▁sep|>' + tool['function']['name'] + '\n```json\n' + tool['function']['arguments'] + '\n```<|tool▁call▁end|>' }}
{{ '<|tool▁calls▁end|><|end▁of▁sentence|>' }}
{% endif %}
{% endfor %}
{# 助手正常回复内容 #}
{% elif message['role'] == 'assistant' and message['content'] is not none %}
{% if ns.is_tool %}
{{ '<|tool▁outputs▁end|>' + message['content'] + '<|end▁of▁sentence|>' }}
{% set ns.is_tool = false %}
{% else %}
{{ '<|Assistant|>' + message['content'] + '<|end▁of▁sentence|>' }}
{% endif %}
也就是说,如果message['content'] is none,理论上是会输出tool_call块的才对,但是做下来并不是这样,这个条件分支其实很奇怪
12 [veRL] 性能优化 use_remove_padding (flash attn varlen)变长序列处理
- https://verl.readthedocs.io/en/latest/perf/perf_tuning.html
use_remove_padding=Truefor sequence packing (i.e., data packing and remove padding).- rmpad
- https://github.com/volcengine/verl/blob/main/tests/model/test_transformer.py
- 在verl源码库中的
./tests/model/test_transformers.py,这是一个测试用例
这里主要是看一下重要的参数use_remove_padding 的用法
这个参数是直接移除一些无用padding,提高token效率。
这个好像是dynamic batchsize的基础
- Enable
use_remove_padding=Truefor sequence packing (i.e., data packing and remove padding)
from flash_attn.bert_padding import unpad_input, pad_input, index_first_axis, rearrange
def unpad_input(hidden_states, attention_mask, unused_mask=None):input_ids_rmpad, indices, * = unpad_input(input_ids.unsqueeze(-1), attention_mask)- (4, 128) => (4, 128, 1), attention_mask.sum() == 301
- input_ids_rmpad.shape() == (1, 301)
- indices.shape == (301)
- 记录了每个有效 token 在原始 (batch, seqlen) 张量中的位置。
origin_logits_rmpad, origin_logits_indices, *_ = unpad_input(origin_logits, attention_mask)- origin_logits.shape == (4, 128, 32000)
- origin_logits_rmpad.shape == (301, 32000)
- index_first_axis
- 根据提供的索引 (indices),从输入张量 (x) 的第一个维度(axis=0)中高效地选取指定的行/元素。
这边说的一个意思是他的attn用的是flash_attn实现的,因此在调用模型的时候需要指定:
model = AutoModelForCausalLM.from_config(
config=config,
torch_dtype=torch.bfloat16
attn_implementation = 'flash_attention_2')
总之verl注意力的底层实现基本都是基于flash_attn库实现的。
在这个测试脚本的源码中会注意到,它对prompt是从左边加padding,response则是从右边做padding
flash_attn中提供了一个重要函数unpad_input,测试脚本中attention_mask中有效的token是318(可以通过attention_mask.sum()可以得知,经过unpad_input后刚好也是318,就是把所有的0都干掉了(position_id是0的即padding),这里也注意一种很好的写法:
a, b, *_ = unpad(...),很好理解,只需要函数返回的前2个数值,其余的都不要了。
一个issue:https://github.com/Dao-AILab/flash-attention/issues/11#issuecomment-1156681278
The most performant approach is to do the unpadding (i.e. remove padding tokens) before the first encoder block and add back the padding after the last encoder block, so that unpadding / padding is only called once (instead of 24 times if you have 24 layers). This has the added benefit of speeding up all other layers (LayerNorm, FFN, etc.) since they don’t need to operate on padding tokens.
AutoModelForCausalLM.from_config(xx, attn_implementation='flash_attention_2')logits_rmpad = model(input_ids_rmpad, position_ids=position_ids_rmpad, ...)
这是一件很神奇的事情:
使用input_ids_rmpad和position_ids_rmpad调用模型不受影响的核心原因有:
- Flash Attention 2的变长序列支持(flash_attn_varlen):
- 代码中指定了attn_implementation=‘flash_attention_2’
- Flash Attention 2原生支持变长序列处理,无需传统的方形注意力矩阵
- 有效信息完整保留:
- unpad_input函数只移除填充部分,保留所有有效token
- indices变量记录了每个token在原始批次中的位置信息
- 移除填充后形状从(batch_size, seqlen)变为(1, total_nnz)(
number of nonzero),但信息不丢失
- 位置编码的精确对齐:
- position_ids_rmpad保存了每个有效token的正确位置ID
- 确保模型内部的旋转位置编码(rotary embedding)能够正常工作
- 这使得移除填充后的位置信息与原始位置信息一致
- Transformer架构的特性:
- Transformer对每个token的处理本质上是并行的
- 只要提供正确的位置信息和token关系,不需要处理无意义的填充
nnz指的是number of nonzero
一个示例(就是把上面那个test_transformers.py的简化一下了)
- input_ids:
[[句子A token1, 句子A token2, PAD, PAD],[句子B token1, 句子B token2, 句子B token3, PAD]]
- attention_mask:
[[1, 1, 0, 0],[1, 1, 1, 0]](1 代表有效 token,0 代表 PAD)
- position_ids:
[[0, 1, 0, 0],[0, 1, 2, 0]](简化表示,实际可能不同,但 PAD 位通常无效)
qwen2.5-0.5b-Instruct
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from flash_attn.bert_padding import unpad_input, pad_input, index_first_axis, rearrange
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dtype = torch.bfloat16 if device.type == "cuda" else torch.float32
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=dtype,
attn_implementation="flash_attention_2",
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
print(tokenizer.pad_token) # <|endoftext|>
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # Use EOS if pad token is not set
注意上面实现要指定注意力实现是flash_attn_2,我们设置一个prompt作为设置:
prompts = [
"你好,请给我介绍一下大型语言模型。",
"今天天气怎么样?"
]
2.1 original process
inputs_padded = tokenizer(prompts, return_tensors="pt", padding=True, truncation=True, max_length=64).to(device)
input_ids = inputs_padded['input_ids']
attention_mask = inputs_padded['attention_mask']
batch_size, seqlen = input_ids.shape
input_ids
"""
tensor([[108386, 37945, 104169, 109432, 101951, 102064, 104949, 1773],
[100644, 104307, 104472, 11319, 151643, 151643, 151643, 151643]],
device='cuda:0')
"""
print(tokenizer.decode(input_ids[0])) # 你好,请给我介绍一下大型语言模型。
print(tokenizer.decode(input_ids[1])) # 今天天气怎么样?<|endoftext|><|endoftext|><|endoftext|><|endoftext|>
这里就是填充了4个0👆👇(<endoftext>)
其中attention_mask形如:
tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 0, 0]], device='cuda:0')
再看position_ids:
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1) # Use 1 for masked positions (consistent with tests)
"""
tensor([[0, 1, 2, 3, 4, 5, 6, 7],
[0, 1, 2, 3, 1, 1, 1, 1]], device='cuda:0')
"""
然后调用模型(不使用unpad,与下面unpad的结果对比):
with torch.no_grad():
outputs_standard = model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
use_cache=False
)
origin_logits = outputs_standard.logits
origin_logits.shape, origin_logits
输出的logits形如:
(torch.Size([2, 8, 151936]),
tensor([[[ 7.0000, 6.5625, 1.6328, ..., -2.9375, -2.9375, -2.9375],
[ 8.5000, 5.6875, 4.3438, ..., -2.9688, -2.9688, -2.9688],
[ 3.8438, 6.8125, 2.4062, ..., -4.2812, -4.2812, -4.2812],
...,
[ 4.5625, 7.0312, -1.0703, ..., -3.5938, -3.5938, -3.5938],
[ 5.3125, 10.9375, 3.1094, ..., -3.3281, -3.3281, -3.3281],
[ 5.7188, 10.0000, 7.3750, ..., -5.7812, -5.7812, -5.7812]],
[[ 2.8438, 8.2500, 2.7812, ..., -2.8281, -2.8281, -2.8281],
[ 6.3750, 8.8125, 6.2188, ..., -4.0312, -4.0312, -4.0312],
[11.9375, 9.6875, 7.9375, ..., -3.2344, -3.2344, -3.2344],
...,
[ 0.4297, -3.3750, 5.2188, ..., -0.2324, -0.2334, -0.2324],
[ 0.4297, -3.3750, 5.2188, ..., -0.2324, -0.2334, -0.2324],
[ 0.4297, -3.3750, 5.2188, ..., -0.2324, -0.2334, -0.2324]]],
device='cuda:0', dtype=torch.bfloat16))
2.2 unpad
input_ids_unpad, indices, *_ = unpad_input(input_ids.unsqueeze(-1), attention_mask)
input_ids_unpad = input_ids_unpad.squeeze(-1) # Back to (total_tokens,)
position_ids_reshaped = rearrange(position_ids.unsqueeze(-1), "b s ... -> (b s) ...") # (b*s, 1)
position_ids_unpad = index_first_axis(position_ids_reshaped, indices) # (total_tokens, 1)
position_ids_unpad = position_ids_unpad.squeeze(-1) # (total_tokens,)
position_ids_reshaped:
tensor([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[0],
[1],
[2],
[3],
[1],
[1],
[1],
[1]], device='cuda:0')
index_first_axis(position_ids_reshaped, indices):
tensor([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[0],
[1],
[2],
[3]], device='cuda:0')
input_ids_unpad:
tensor([108386, 37945, 104169, 109432, 101951, 102064, 104949, 1773, 100644,
104307, 104472, 11319], device='cuda:0')
indices:
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], device='cuda:0')
position_ids_unpad:
tensor([0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3], device='cuda:0')
同样调用模型:
with torch.no_grad():
input_ids_unpad_batch = input_ids_unpad.unsqueeze(0) # (1, total_tokens)
position_ids_unpad_batch = position_ids_unpad.unsqueeze(0) # (1, total_tokens)
outputs_unpad = model(
input_ids=input_ids_unpad_batch,
position_ids=position_ids_unpad_batch, # Pass unpadded position_ids
use_cache=False
)
logits_unpad = outputs_unpad.logits.squeeze(0)
logits_unpad.shape # torch.Size([12, 151936])
logits_re_padded = pad_input(logits_unpad,
indices, batch_size, seqlen)
logits_re_padded
输出logits_re_padded为:
tensor([[[ 7.0000, 6.5625, 1.6328, ..., -2.9375, -2.9375, -2.9375],
[ 8.5000, 5.6875, 4.3438, ..., -2.9688, -2.9688, -2.9688],
[ 3.8438, 6.8125, 2.4062, ..., -4.2812, -4.2812, -4.2812],
...,
[ 4.5625, 7.0312, -1.0703, ..., -3.5938, -3.5938, -3.5938],
[ 5.3125, 10.9375, 3.1094, ..., -3.3281, -3.3281, -3.3281],
[ 5.7188, 10.0000, 7.3750, ..., -5.7812, -5.7812, -5.7812]],
[[ 2.8438, 8.2500, 2.7812, ..., -2.8281, -2.8281, -2.8281],
[ 6.3750, 8.8125, 6.2188, ..., -4.0312, -4.0312, -4.0312],
[11.9375, 9.6875, 7.9375, ..., -3.2344, -3.2344, -3.2344],
...,
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]]],
device='cuda:0', dtype=torch.bfloat16)
attention_mask同理为:
tensor([[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 0, 0, 0]], device='cuda:0')
mask_expanded = attention_mask.unsqueeze(-1).bool()
mask_expanded
"""
tensor([[[ True],
[ True],
[ True],
[ True],
[ True],
[ True],
[ True],
[ True]],
[[ True],
[ True],
[ True],
[ True],
[False],
[False],
[False],
[False]]], device='cuda:0')
"""
valid_origin_logits = torch.masked_select(origin_logits, mask_expanded)
valid_re_padded_logits = torch.masked_select(logits_re_padded, mask_expanded)
valid_origin_logits # tensor([ 7.0000, 6.5625, 1.6328, ..., -4.5000, -4.5000, -4.5000], device='cuda:0', dtype=torch.bfloat16)
valid_re_padded_logits # tensor([ 7.0000, 6.5625, 1.6328, ..., -4.5000, -4.5000, -4.5000], device='cuda:0', dtype=torch.bfloat16)
13 [veRL] log probs from logits 与 entropy from logits 的高效计算
关注两个算子(log & entropy from logits)
log probs from logits
不管是PPO还是GRPO里,都有许多 log p 的计算,包括KL散度以及优势函数的计算,都用到了log p的计算。
-
定义:
- (model) logits: z z z, true label: y y y
- 标准的交叉熵损失,pytorch中
reduction='None',计算的是真实标签 y y y对应的负对数概率:
CrossEntropyLoss ( z , y ) = − log p ( y ∣ z ) = − log ( exp ( z y ) ∑ i exp ( z i ) ) \text{CrossEntropyLoss}(z,y)=-\log p(y|z)=-\log\left(\frac{\exp(z_y)}{\sum_i\exp(z_i)}\right) CrossEntropyLoss(z,y)=−logp(y∣z)=−log(∑iexp(zi)exp(zy))
- log p = - crossentropyloss
log p ( y ∣ z ) = log ( exp ( z y ) ∑ i exp ( z i ) ) = − CrossEntropyLoss ( z , y ) \log p(y|z)=\log\left(\frac{\exp(z_y)}{\sum_i\exp(z_i)}\right) = -\text{CrossEntropyLoss}(z,y) logp(y∣z)=log(∑iexp(zi)exp(zy))=−CrossEntropyLoss(z,y)
-
log p_y = z_y - logsumexp(z) (这是假定你的flash_attn不支持crossentropyloss的情况下的权宜之计)
-
softmax: z = ( z 1 , . . . , z k ) ⇒ p = ( p 1 , . . . , p k ) z=(z_1,...,z_k)\Rightarrow p=(p_1,...,p_k) z=(z1,...,zk)⇒p=(p1,...,pk)
- p j = exp ( z j ) ∑ i exp ( z i ) p_j=\frac{\exp(z_j)}{\sum_i \exp(z_i)} pj=∑iexp(zi)exp(zj)
-
log-softmax
- log p j = log exp ( z j ) ∑ i exp ( z i ) = log exp ( z j ) − log ∑ i exp ( z i ) = z j − log ∑ i exp ( z i ) \log p_j=\log\frac{\exp(z_j)}{\sum_i \exp(z_i)}=\log \exp(z_j)-\log \sum_i\exp(z_i)=z_j-\log\sum_{i}\exp(z_i) logpj=log∑iexp(zi)exp(zj)=logexp(zj)−log∑iexp(zi)=zj−log∑iexp(zi)
- log p j = z j − logsumepx ( z ) \log p_j=z_j-\text{logsumepx}(z) logpj=zj−logsumepx(z)
-
z y z_y zy通过
torch.gather实现 -
logsumexp有专门的数值稳定性计算优化
- logsumexp ( z ) = z max + log ( ∑ j exp ( z j − z max ) ) \text{logsumexp}(z)=z_{\max}+\log(\sum_j\exp(z_j-z_{\max})) logsumexp(z)=zmax+log(∑jexp(zj−zmax))
- 最大的 z 对应的 exp 项就变成了 exp ( 0 ) = 1 \exp(0)=1 exp(0)=1,避免了overflow
-
内存的角度:
- log softmax:
[bsz, seq_len, vocab_size] - z_y - logsumexp(z):
- z_y:
[bsz, seq_len] - logsumexp(z):
[bsz, seq_len]
- z_y:
- log softmax:
-
总之源码实现上就是避免了logsoftmax的计算,可能是出于数值稳定性的考虑。
entropy from logits
在PPOActor的源码里除了log p from logits外,还有一个entropy from logits的函数(veRL.F.entropy_from_logits)
虽然希望entropy相对高(有一定多样性),但不希望爆炸高(出现乱码)
- (trl)
ppo_trainer.py:
#logits.shape: (total_tokens, vocab_size)
def entropy_from_logits(logits: torch.Tensor):
"""Calculate entropy from logits."""
pd = torch.nn.functional.softmax(lgoits, dim=-1)
entropy = torch.logsumexp(logits, dim=-1) - torch.sum(pd * logits, dim=-1)
return entropy
# return: (total_tokens, ), token 级别的熵
H = − ∑ v p ( v ) log p ( v ) H=-\sum_v p(v)\log p(v) H=−v∑p(v)logp(v)
-
v v v 是词表上的tokenid, p ( v ) p(v) p(v)就是概率密度分布
-
在 llm 中,就是 generation 生成序列的每个位置 π θ ( ⋅ ∣ q , o < t ) \pi_\theta(\cdot|q,o_{<t}) πθ(⋅∣q,o<t)都对应一个词表维度的概率分布
p ( v ) = exp ( logits v ) ∑ v ′ exp ( logits v ′ ) = exp ( logits v ) Z p(v)=\frac{\exp(\text{logits}_v)}{\sum_{v'}\exp(\text{logits}_{v'})}=\frac{\exp(\text{logits}_v)}{Z} p(v)=∑v′exp(logitsv′)exp(logitsv)=Zexp(logitsv)
- 则有:
log p ( v ) = logits v − Z \log p(v)=\text{logits}_v -Z logp(v)=logitsv−Z
-
log Z 刚好就是 logsumexp
-
进一步:
H = − ∑ v p ( v ) log p ( v ) = − ∑ v p ( v ) ( logits v − log Z ) = log Z − ∑ v p ( v ) logits v H=-\sum_{v} p(v) \log p(v) = -\sum_v p(v) (\text{logits}_v - \log Z)=\log Z - \sum_{v} p(v)\text{logits}_v H=−v∑p(v)logp(v)=−v∑p(v)(logitsv−logZ)=logZ−v∑p(v)logitsv
14 [RL4LLM] base vs. instruct model,个性化(custom)chat template(make prefix)
- https://www.bilibili.com/video/BV1JZLcz4EUC
- https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/tokenizer/base_instruct.ipynb
- https://github.com/chunhuizhang/llm_rl/blob/main/tutorials/tokenizer/template_make_prefix.ipynb
这一期主要是讲关于如何让completion模型来QA
completion vs. chat
- Q/A, U/A, User/Assistant
- base model 没有身份(role)的概念;
- 严格意义上的语言模型,next token prediction(词语接龙)
- 怎么去回答 QA 的问题,prompt 中定义身份,(设置 max response,以及 stop words 等);
prompt = f"Q: {question}\nA:"
# 也可以尝试 few-shot,提供一些例子
prompt = f"""
Q: 西班牙的首都是哪里?
A: 马德里
Q: 德国的首都是哪里?
A: 柏林
Q: {question}
A:
"""
prompt = f"<|im_start|>system\n{system_prompt}<|im_end|>\n"
prompt += f"<|im_start|>user\n{question}<|im_end|>\n"
prompt += "<|im_start|>assistant\n" # 模型将从这里开始生成
from transformers import AutoTokenizer
base_tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen2.5-3B')
instruct_tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen2.5-3B-Instruct')
print(base_tokenizer.chat_template)
def make_prefix(numbers, target, template_type):
# NOTE: also need to change reward_score/countdown.py
if template_type == 'base':
# follow deepseek-r1-zero
"""This works for any base model"""
prefix = f"""A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
User: Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
Assistant: Let me solve this step by step.
<think>"""
elif template_type == 'qwen-instruct':
"""This works for Qwen Instruct Models"""
prefix = f"""<|im_start|>system\nYou are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.<|im_end|>\n<|im_start|>user\n Using the numbers {numbers}, create an equation that equals {target}. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.<|im_end|>\n<|im_start|>assistant\nLet me solve this step by step.\n<think>"""
return prefix
numbers = [ 44, 19, 35 ]
target = 99
base_prompt = make_prefix(numbers, target, 'base')
print(base_prompt)
"""
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
User: Using the numbers [44, 19, 35], create an equation that equals 99. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
Assistant: Let me solve this step by step.
<think>
"""
instruct_prompt = make_prefix(numbers, target, 'qwen-instruct')
print(instruct_prompt)
"""
<|im_start|>system
You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.<|im_end|>
<|im_start|>user
Using the numbers [44, 19, 35], create an equation that equals 99. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.<|im_end|>
<|im_start|>assistant
Let me solve this step by step.
<think>
"""
base model inference
from vllm import LLM, SamplingParams
sampling_params = SamplingParams(
temperature=0.6,
max_tokens=1024
)
base_llm = LLM(model='Qwen/Qwen2.5-3B', max_model_len=1024)
base_resp = base_llm.generate(base_prompt, sampling_params)[0]
print(base_resp.outputs[0].text)
"""
We need to use the numbers 44, 19, and 35 exactly once to create an equation that equals 99. We can use basic arithmetic operations like addition, subtraction, multiplication, and division. Let's start by looking for patterns or combinations of the numbers that could add up to 99. One way to approach this is to try different operations or combinations of the numbers. </think>
The final answer is: <answer> 44 + 35 + 19 = 99 </answer>
"""
test_resp = base_llm.generate('The captail of China is', sampling_params)[0]
print(test_resp.outputs[0].text)
"""
Beijing.____
A. The capital of China is Beijing.
B. Beijing is the capital of China.
C. The capital of China is Beijing.
D. Beijing is the capital of China.
Answer:
D
The most abundant element in the Earth's crust is ____
A. Oxygen
B. Silicon
C. Aluminum
D. Iron
Answer:
A
Which of the following explanations of the emphasized words in the sentences is incorrect?
A. The reason why loyal ministers and virtuous officials dare not speak, and the reason why fools and traitors dare to speak, is because they are afraid of being punished. Punishment: Punishment.
B. If you want to know the truth, I will tell you. Know: Understand.
C. In the morning, I cross the river and settle in the west, and by nightfall, I am in the east. Cross: Cross.
D. The reason why the old man was able to survive and not perish is the same as me. Pity: Like.
Answer:
A
The starting point of human life is ____
A. Fertilized egg
B. Embryo
C. Infant
D. Newborn
Answer:
A
The solution set for the inequality x^{2}-2x-3>0 is ____
A. (-1, 3)
B. (-∞, -1) ∪ (3, +∞)
C. (-3, 1)
D. (-∞, -3) ∪ (1, +∞)
Answer:
B
The following table shows the number of naval and air force officers and engineers in the North China Military District from 1948 to 1949. This table reflects that the People's Liberation Army ____. | Year | Number of Naval and Air Force Officers and Engineers | | --- | --- | | 1948 | 2,804 | | 1949 | 3,363 |
A. Gradually expanded its scale
B. Won many victories in the southern theater
C. Had a relatively strong combat capability
D. Effectively thwarted the Nationalist army's rearward defense strategy
Answer:
C
"""
test_resp = base_llm.generate('My name is', sampling_params)[0]
print(test_resp.outputs[0].text)
"""
Tom. I am a student. I am in Class Two, Grade Eight. This is my friend, Jack. He is a student, too. He is in Class One, Grade Eight. My Chinese teacher is Mr. Zhang. He is a good teacher. He likes us very much. My English teacher is Miss. Wang. She is very young. She is good with us. She likes us, too. We like them. 根据短文内容,判断正误(正确的写"正确",错误的写"错误")。 (1). 2. Miss. Wang is a good Chinese teacher. (2). 3. Tom is in Class Two, Grade Eight. (3). 4. Mr. Zhang is Tom's English teacher. (4). 5. Jack and Tom are in the same class. (5). 1. Jack is a student, too.
【小题1】错误 【小题2】正确 【小题3】正确 【小题4】错误 【小题5】错误
根据汉语意思完成句子。 【 1 】 这个房间是用空气新鲜的木材做的。 This room is made of ___________. 【 2 】 我们必须阻止人们在森林里砍伐树木。 We must _______________ people from cutting down trees in the forest. 【 3 】 请不要把纸屑扔在地板上。 Please don't ___________ the paper on the floor. 【 4 】 环保对我们来说非常重要。 It is ___________ for us to protect the environment. 【 5 】 为了保护我们美丽的地球,我们不能乱扔垃圾。 We can't ___________ rubbish because we must protect our beautiful earth.
【 1 】 fresh air 【 2 】 stop 【 3 】 throw away 【 4 】 important 【 5 】 throw away
阅读下面的文字,完成下列小题。 雪山 谢大立 10月25日,是红军长征胜利70周年的日子。 一大早,我们一行就匆匆地赶到了雪山脚下。 1936年10月,红军三大主力在甘肃会宁胜利会师,宣告长征胜利结束。但是,虽然红军主力在陕北会师,但还有几支红军队伍在雪山、草地里艰难行军,这一路上,究竟会有多少红军战死在这崇山峻岭中,又有多少红军战士被饥饿折磨得骨瘦如柴,这一切,已永远地被埋葬在万古长青的雪山之上了。 1936年10月,是红军长征胜利70周年的日子。 一大早,我们一行就匆匆地赶到了雪山脚下。 1936年10月,红军三大主力在甘肃会宁胜利会师,宣告长征胜利结束。但是,虽然红军主力在陕北会师,但还有几支红军队伍在雪山、草地里艰难行军,这一路上,究竟会有多少红军战死在这崇山峻岭中,又有多少红军战士被饥饿折磨得骨瘦如柴,这一切,已永远地被埋葬在万古长青的雪山之上了。 1936年10月,是红军长征胜利70周年的日子。 一大早,我们一行就匆匆地赶到了雪山脚下。 1936年10月,红军三大主力在甘肃会宁胜利会师,宣告长征胜利结束。但是,虽然红军主力在陕北会师,但还有几支红军队伍在雪山、草地里艰难行军,这一路上,究竟会有多少红军战死在这崇山峻岭中,又有多少红军战士被饥饿折磨得骨瘦如柴,这一切,已永远地被埋葬在万古长青的雪山之上了。 1936年10月,是红军长征胜利70周年的日子。 一大早,我们一行就匆匆地赶到了雪山脚下。 1936年10月,红军三大主力在甘肃会宁胜利会师,宣告长征胜利结束。但是,虽然红军主力在陕北会师,但还有几支红军队伍在雪山、草地里艰难行军,这一路上,究竟会有多少红军战死在这崇山峻岭中,又有多少红军战士被饥饿折磨得骨瘦如柴,这一切,已永远地被埋葬在万古长青的雪山之上了。 1936年10月,是红军长征胜利70周年的日子。 一大早,我们一行就匆匆地赶到了雪山脚下。 1936年10月,红军三大主力在甘肃会宁胜利会师,宣告长征胜利结束。但是,虽然红军主力在陕北会师,但还有几支红军队伍在雪山、
"""
test_resp = base_llm.generate('Long long ago, there', sampling_params)[0]
print(test_resp.outputs[0].text)
"""
was a little girl who loved to play in the house. She picked up everything. She put it away, and then she picked it up again. She put it away, and then she picked it up again. Finally, her mother said, "I'm going to put a sign on the door. Then you won't be able to come in any more." "What sign, Mom?" "It'll say, 'Out of Order'," said her mother. "Oh," said the little girl. Then she went and hid under the bed. A few minutes later, her mother called her, "Come in here." The little girl came out from under the bed. "What's wrong, Mom?" "I put the sign on the door," said her mother, "and I can't open it." 【小题1】The little girl picked up everything because she wanted to put it away. 【小题2】The little girl put it away because her mother asked her to do so. 【小题3】The little girl was very angry with her mother. 【小题4】The mother didn't want to play with the little girl. 【小题5】The mother could not open the door because the sign was on it. 【小题1】T 【小题2】F 【小题3】T 【小题4】T 【小题5】T
阅读下面的文章,完成后面题目。 《红楼梦》中女性形象的复杂性 一、《红楼梦》中女性形象的复杂性 《红楼梦》中人物众多,女性形象更是丰富多彩。 《红楼梦》中女性形象的复杂性,主要表现在以下方面: 1.女性的阶级性。阶级是社会上最本质、最直接的差别。《红楼梦》中女性形象的阶级性,主要表现在她们所处的社会地位的不同。《红楼梦》中女性形象的阶级性,是决定其性格的重要因素,也是决定其命运的重要因素。 2.女性的性别特征。《红楼梦》中女性形象的性别特征,主要表现在其在性别方面所特有的差异上。 3.女性的文学性。文学性是指作品中人物形象所具有的审美价值和艺术魅力。《红楼梦》中女性形象的文学性,主要表现在以下方面:①《红楼梦》中女性形象的典型性。②《红楼梦》中女性形象的艺术性。 4.女性的象征性。《红楼梦》中女性形象的象征性,主要表现在两个方面:①女性形象的隐喻性。②女性形象的隐喻性。 《红楼梦》中女性形象的复杂性,是个性与共性的统一。个性是指《红楼梦》中女性形象所具有的特殊性。共性是指《红楼梦》中女性形象所具有的普遍性,即《红楼梦》中女性形象所具有的共有的品格、气质、思想、性格等。 总之,《红楼梦》中女性形象的复杂性,是个性与共性的统一,是人物形象与社会现实的统一,是人物形象与民族心理的统一。 (选自《红楼梦论丛》,有改动) 1.下列对《红楼梦》中女性形象复杂性的理解,不正确的一项是 A.《红楼梦》中女性形象的复杂性,主要表现在她们所处的社会地位的不同。 B.《红楼梦》中女性形象的阶级性,是决定其性格和命运的重要因素。 C.《红楼梦》中女性形象的性别特征,主要表现在其在性别方面所特有的差异上。 D.《红楼梦》中女性形象的文学性,主要表现在其典型性和艺术性。 2.下列对《红楼梦》中女性形象复杂性的理解,不正确的一项是 A.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与社会现实的统一。 B.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与民族心理的统一。 C.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象个性与共性的统一。 D.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与《红楼梦》中社会现实的统一。 3.下列对《红楼梦》中女性形象复杂性的理解,不正确的一项是 A.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与《红楼梦》中民族心理的统一。 B.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与《红楼梦》中社会现实的统一。 C.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与《红楼梦》中文学性的统一。 D.《红楼梦》中女性形象的复杂性,是《红楼梦》中人物形象与《红楼梦》中阶级
"""
test_resp = base_llm.generate(instruct_prompt, sampling_params)[0]
print(test_resp.outputs[0].text)
"""
First, I need to find a way to use the numbers 35 and 19 to get close to 99. I can start by adding 35 and 19, which gives me 54. Then, I can subtract 54 from 99, which gives me 45. Now, I need to find a way to get from 45 to 44. I can subtract 45 by 1, which gives me -1. But that doesn't work because I can't use -1 as a number in my equation. So, I need to find another way to get from 45 to 44. I can divide 45 by 1.1, which gives me 40.90909090909091. Then, I can subtract 40.90909090909091 by 0.9090909090909091, which gives me 40. Now, I need to find a way to get from 40 to 44. I can multiply 40 by 1.1, which gives me 44. But that doesn't work because I can't use 1.1 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add 40 by 0.4, which gives me 40.4. Then, I can subtract 40.4 by 0.4, which gives me 40. But that doesn't work because I can't use 40 as a number in my equation. So, I need to find another way to get from 40 to 44. I can add
"""
basics
- prompt vs. response
- prompt: resp.prompt, resp.prompt_token_ids
- response:
resp.outputs[0].text,resp.outputs[0].token_ids
make_prefix(TinyZero)- https://github.com/Jiayi-Pan/TinyZero/blob/main/examples/data_preprocess/countdown.py#L57-L66
prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False) # '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.' prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True) # '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|><think>\n' # custom prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True) # '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|>' # custom no think prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True) # '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|><think>\n</think>'- load the parquet dataset
- https://github.com/Jiayi-Pan/TinyZero/blob/main/verl/utils/dataset/rl_dataset.py#L128
- default
- https://github.com/volcengine/verl/blob/main/verl/utils/dataset/rl_dataset.py#L169
- prompt_with_chat_template = self.tokenizer.apply_chat_template(chat, add_generation_prompt=True, tokenize=False)
- generate & reward func
- reward func
sequences = torch.cat((valid_prompt_ids, valid_response_ids)) sequences_str = self.tokenizer.decode(sequences) score = compute_score_fn(solution_str=sequences_str, ground_truth=ground_truth)
from transformers import AutoTokenizer
import re
import torch
model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
basic_messages = [
{"role": "user", "content": "3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}."}
]
tokenizer.apply_chat_template(basic_messages, tokenize=False)
tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
vllm inference
用ollama在ds上让它思考9.11和9.9哪个更大,有时候是没有think的
from vllm import LLM, SamplingParams
sampling_params = SamplingParams(
temperature=0.6,
max_tokens=32768
)
llm = LLM(model=model_id, max_model_len=32768)
prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
prompt
resp = llm.generate(prompt, sampling_params=sampling_params)[0]
print(resp.prompt)
print(resp.prompt_token_ids)
assert tokenizer.encode(resp.prompt) == resp.prompt_token_ids
tokenizer.decode(151646), tokenizer.decode(7810)
len(resp.outputs[0].token_ids), len(tokenizer.encode(resp.outputs[0].text))
custom chat template
prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False)
resp = llm.generate(prompt, sampling_params=sampling_params)[0]
print(resp.outputs[0].text)
"""
**
</think>
To determine which number is bigger between **3.11** and **3.9**, follow these steps:
1. **Compare the whole number part** of both numbers. Both have **3** as the whole number.
2. **Compare the decimal parts**:
- **0.11** (from 3.11)
- **0.9** (from 3.9, which can be written as 3.90)
3. **Convert 3.9 to two decimal places**: 3.90
4. **Compare 0.11 and 0.90**:
- **0.11** is less than **0.90**
5. **Conclusion**: Since 0.11 is less than 0.90, **3.90** is larger than **3.11**.
**Final Answer**: \boxed{3.9}
"""
prompt = tokenizer.apply_chat_template(basic_messages, tokenize=False, add_generation_prompt=True)
resp = llm.generate(prompt, sampling_params=sampling_params)[0]
prompt = '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|>'
resp = llm.generate(prompt, sampling_params=sampling_params)[0]
print(resp.outputs[0].text)
"""
<think>
Alright, so I've got this problem here: 3.11 and 3.9, and I need to figure out which one is bigger. Hmm, okay. Let me think about how to approach this. I'm pretty sure that when comparing decimals, you start from the left and compare each digit one by one. So, first, I should look at the whole number part of both numbers.
Both 3.11 and 3.9 have the same whole number part, which is 3. That means the whole numbers are equal, so I can't say one is bigger just yet. I need to look at the decimal parts.
The first decimal place after the decimal point is the tenths place. In 3.11, the tenths place is 1, and in 3.9, the tenths place is 9. Since 9 is greater than 1, that means 3.9 is larger than 3.11. Wait, let me make sure I'm doing this right.
So, if I write both numbers aligned by their decimal points:
3.11
3.9
I can think of 3.9 as 3.90 to make the comparison easier. Now, comparing 3.11 and 3.90. The first digit after the decimal is 1 vs. 9. Since 9 is bigger, 3.90 is bigger than 3.11. Yeah, that makes sense.
Another way to think about it is to subtract the smaller number from the larger one. If the result is positive, then the first number is bigger. So, 3.90 minus 3.11 is 0.79, which is positive, so 3.90 is indeed bigger.
Wait, but what if the numbers were, say, 3.11 and 3.99? Then, the tenths place is 1 vs. 9, so 3.99 would still be bigger. But in this case, since the tenths place is only 1 for 3.11, it's clear that 3.9 has a higher tenths place.
I also remember that when comparing decimals, you can add a zero to the shorter number to make them the same length. So, 3.9 becomes 3.90, and then comparing 3.11 and 3.90 is straightforward.
Is there any chance I might have made a mistake here? Maybe if I misaligned the decimals or added incorrectly. Let me try another approach. I can convert both numbers to fractions.
3.11 is equal to 311/100, right? Because 3.11 is 3 + 11/100. Similarly, 3.9 is 39/10, which is 390/100. So, comparing 311/100 and 390/100, since 390 is greater than 311, 3.9 is bigger.
Wait, let me check that. 390 divided by 100 is 3.9, and 311 divided by 100 is 3.11. So, yes, 3.9 is bigger. I think that's solid.
Alternatively, I could think about money. If I have $3.11 and someone else has $3.90, which is more money? Well, $3.90 is more than $3.11 because 90 cents is more than 11 cents. That's a practical way to remember.
So, another confirmation: when money is involved, the decimal places represent cents. So, 3.11 is 3 dollars and 11 cents, and 3.90 is 3 dollars and 90 cents. Clearly, 90 cents is more than 11 cents, so 3.90 is more than 3.11.
Is there any other way to think about this? Maybe using number lines. If I imagine a number line starting at 3.00, then 3.11 is somewhere between 3.00 and 4.00, and 3.90 is even closer to 4.00. Since 3.90 is closer to 4.00, it must be larger than 3.11.
Wait, but how far is each from 3.00? 3.11 is 0.11 away, and 3.90 is 0.90 away. So, clearly, 3.90 is further along the number line, which means it's bigger.
I think I'm overcomplicating it. The straightforward way is to look at the tenths place. Since 9 is greater than 1, 3.9 is bigger than 3.11.
But just to make sure, let me compare each place step by step. Starting from the left, the units place is the same: 3 in both. Then, moving to the tenths place: 1 vs. 9. Since 9 is bigger, we don't need to check the next decimal places.
If the tenths place were equal, we would move to the hundredths place, but since they are different, we can stop there.
Alternatively, I can also think in terms of fractions. 3.11 is 3 and 11/100, and 3.9 is 3 and 90/100. So, 90/100 is definitely larger than 11/100, so 3.9 is larger.
Wait, just to make sure I'm not missing something, sometimes in decimal comparisons, the number of digits can affect the comparison. For example, if one number has more decimal places, does that mean it's automatically bigger? Well, no, because the more decimal places a number has, the more precise it is. But in this case, both numbers have two decimal places, so the extra digit beyond the decimal point doesn't affect the comparison.
So, 3.11 and 3.90, both have two decimal places, so the difference must be in the tenths place. Therefore, 3.90 is larger than 3.11.
I think I've thought through this from multiple angles now: comparing digit by digit, converting to fractions, thinking about money, using a number line, and even considering the difference from the whole number. All these methods consistently show that 3.9 is bigger than 3.11.
Just to recap, the process is:
1. Compare the whole number parts. Both are 3, so equal.
2. Move to the tenths place: 1 vs. 9. 9 is larger, so 3.9 is bigger.
3. If needed, check the hundredths place, but since they are equal, we can stop here.
So, I can confidently say that 3.9 is bigger than 3.11.
**Final Answer**
The larger number is \boxed{3.9}.
</think>
To determine which number is larger between 3.11 and 3.9, we can follow these steps:
1. Compare the whole number parts. Both numbers have 3 as the whole number part, so they are equal.
2. Move to the tenths place. In 3.11, the tenths place is 1, and in 3.9, the tenths place is 9. Since 9 is greater than 1, 3.9 is larger.
Thus, the larger number is \boxed{3.9}.
"""
no think
有时候没有think标签
- https://www.bilibili.com/video/BV1ugRxYeEt4/
prompt = '<|begin▁of▁sentence|><|User|>3.11 and 3.9 which is bigger? Please reason step by step, and put your final answer within \\boxed{}.<|Assistant|><think>\n</think>'
prompt
resp = llm.generate(prompt, sampling_params=sampling_params)[0]
print(resp.outputs[0].text)
"""
To determine which number is larger between **3.11** and **3.9**, follow these steps:
1. **Compare the whole number parts**: Both numbers have the same whole number part, which is **3**.
2. **Compare the decimal parts**:
- **0.11** (from 3.11)
- **0.90** (from 3.9, which can be written as **0.90** to have the same number of decimal places)
3. **Compare the tenths place**:
- **1** (from 3.11)
- **9** (from 3.9)
Since **9** is greater than **1**, the tenths place of **3.9** is larger than that of **3.11**.
4. **Conclusion**: Because the tenths place of **3.9** is larger, **3.9** is the larger number.
**Final Answer**: \boxed{3.9}
"""

















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









