









强化学习(一):多臂老虎机
一.基本概念和原理
1.基本概念
多臂老虎机是源于赌博学问题,顾名思义,其名字源于单臂老虎机,不同之处在于它有多个控制杆而不是一个。其实多臂老虎机也可以认为是多个单臂老虎机。每一个动作选择即是通过拉动老虎机的控制杆,得到奖金(reward),同时通过多次重复动作选择,学会将动作集中到最好的控制杆上,从而最大化你的奖金。采取不同的行动,对应的奖励也不同,强化学习的目标,就是学习一个好的策略,做出最优的选择,从而最大化奖励。
通过强化学习的角度分析如图所示:

Agent当然就是指的玩家,Environment指的是老虎机,为什么把多臂老虎机问题称为最简单的问题呢,一是因为老虎机的状态(state)只有一个不会发生变化,二是它得到的奖励是即时的,没有延迟奖励问题。
2.动作-价值方法
一般k个动作中每一个在被选择的时候都有一个期望或者平均收益,这个可以叫做这个动作的“价值”。
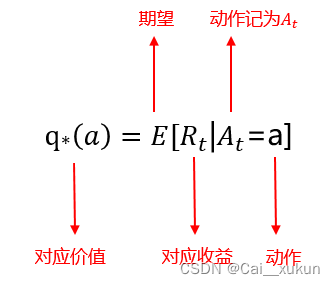
那么如何来评估动作的价值?一个行动真正的价值是选择该行动时的平均回报,采用动作-价值方法,这个动作价值函数是最简单的函数了,一个自变量是行动,一个因变量是价值。

我们采用抽样平均方法,Q是可以采样过程中不断更新变动的一个值,而q是一个真正设定的价值。通过大数定律,多次采样,分母趋于无穷,Q是可以趋近均值q的,这是一个无偏估计。
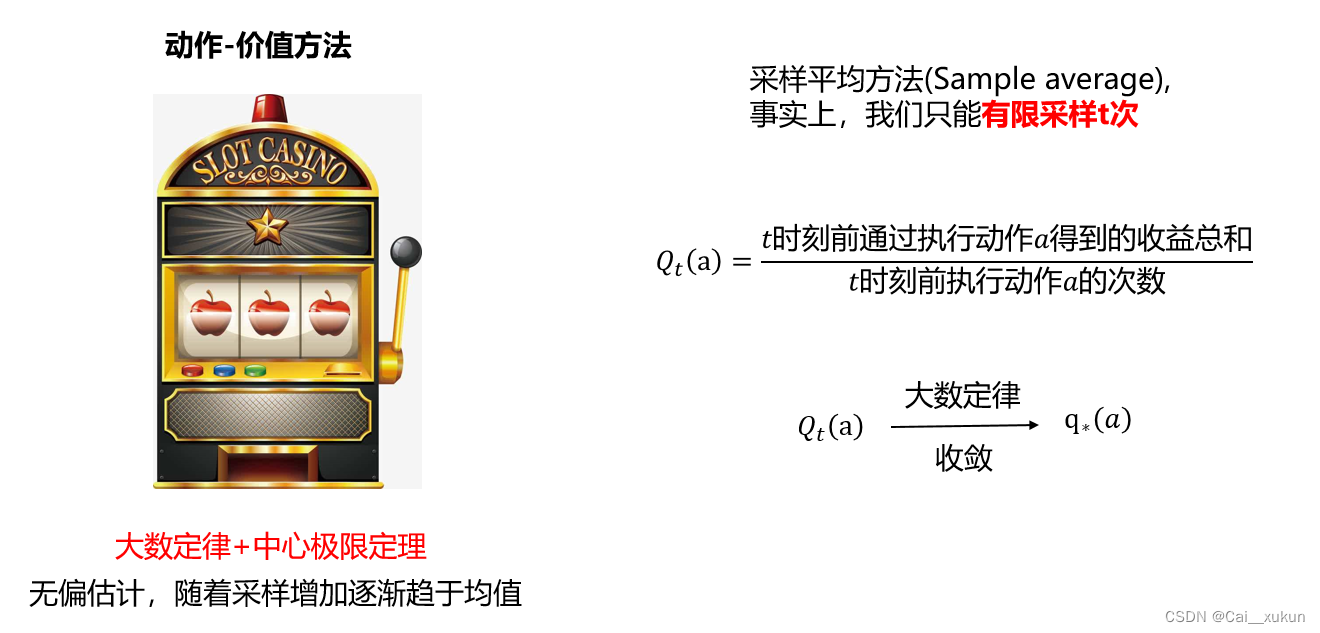
3.增量式和非平衡性问题

批量式可以有效地加快运算,但是会牺牲大量的内存,消耗更多的计算资源,开辟大量内存空间去存储。增量式优点在于开辟的内存量很小,但是计算速率没有批量式快。
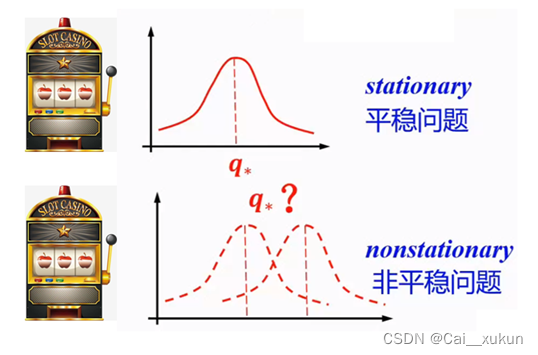
平衡问题指的是收益的概率分布不随时间变化,即保持一个稳定的q*。而非平衡问题,它的收益概率是随时间变化的,采用一个动作,环境给你的奖励并不是一个固定不变的奖励。
二.E-E困境(探索和利用)
我们先假设采用一个10臂老虎机作为测试平台,也可以理解成有十台单臂老虎机。在平衡问题下,每个老虎机各不相同,也即是环境并不相同,如何取得最大奖赏?可以考虑找到最大奖励者,然后一直拉动。但是每个动作的奖赏值是随机的,也就是说,每个摇臂以符合某种概率分布的形式存在。如图所示为10个动作的收益分布。
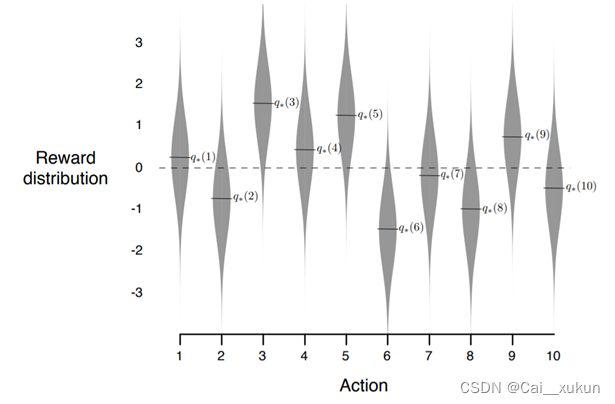
实际动作的真实值q分别从一个0均值1方差的单位正态分布生成,而收益分布从均值为q方差为1的正态分布生成。
我们拉动老虎机的测试次数是有限的,即算力资源是有限的,但是如果我们仅仅探索一轮(指遍历一次所有动作),我们无法获得真实的最大臂期望奖赏值。这样就面临一个问题,即探索-利用困境。
探索指的是多次尝试获取更多信息,这种方式能够很好估计每个臂的奖赏值,却失去很多选择最优臂的机会。利用指根据所知信息,做出最佳决定,选择当前已知奖赏值最大的那个臂,这个方式不能很好估计每个臂的奖赏值,可能无法选择最优的臂。所以要尽量保持探索和利用的平衡,来获取最大收益。
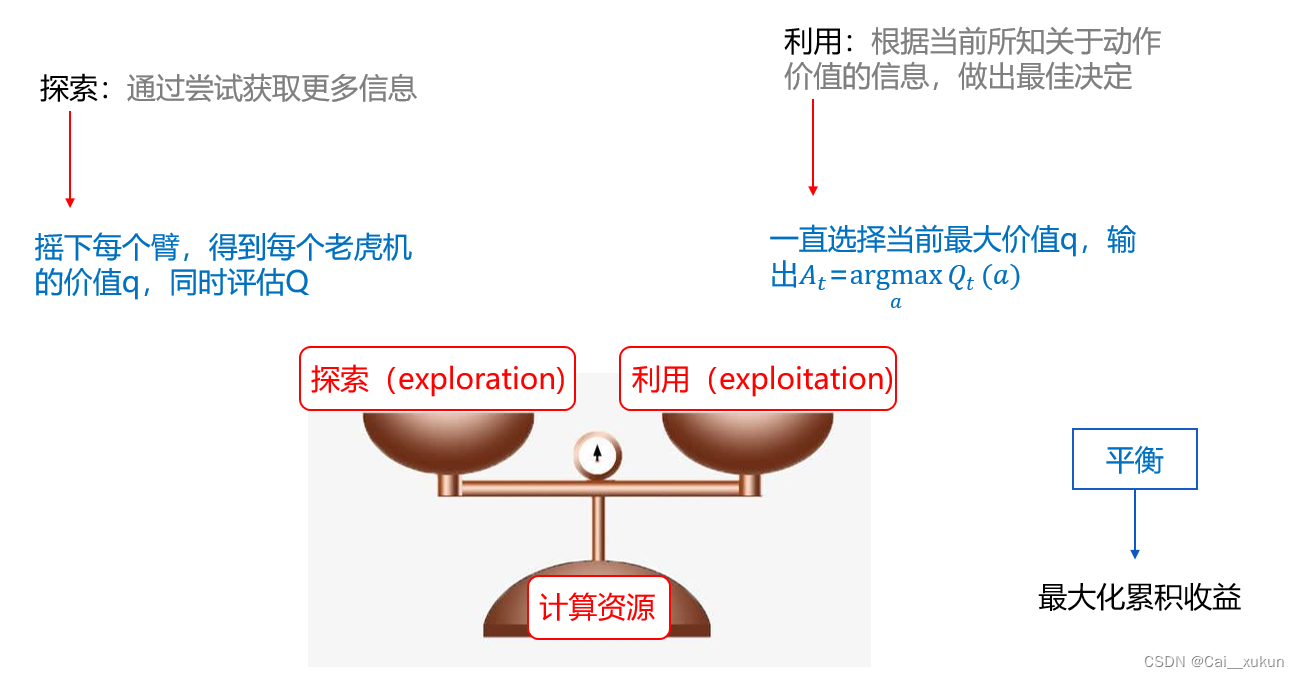
总的尝试次数有限,加强一方势必会削弱另一方。因而我们必须在这两者之间进行有效折中,才可以尽可能获得最大累计奖赏。为了解决这个困境,我们常采用很多小技巧。
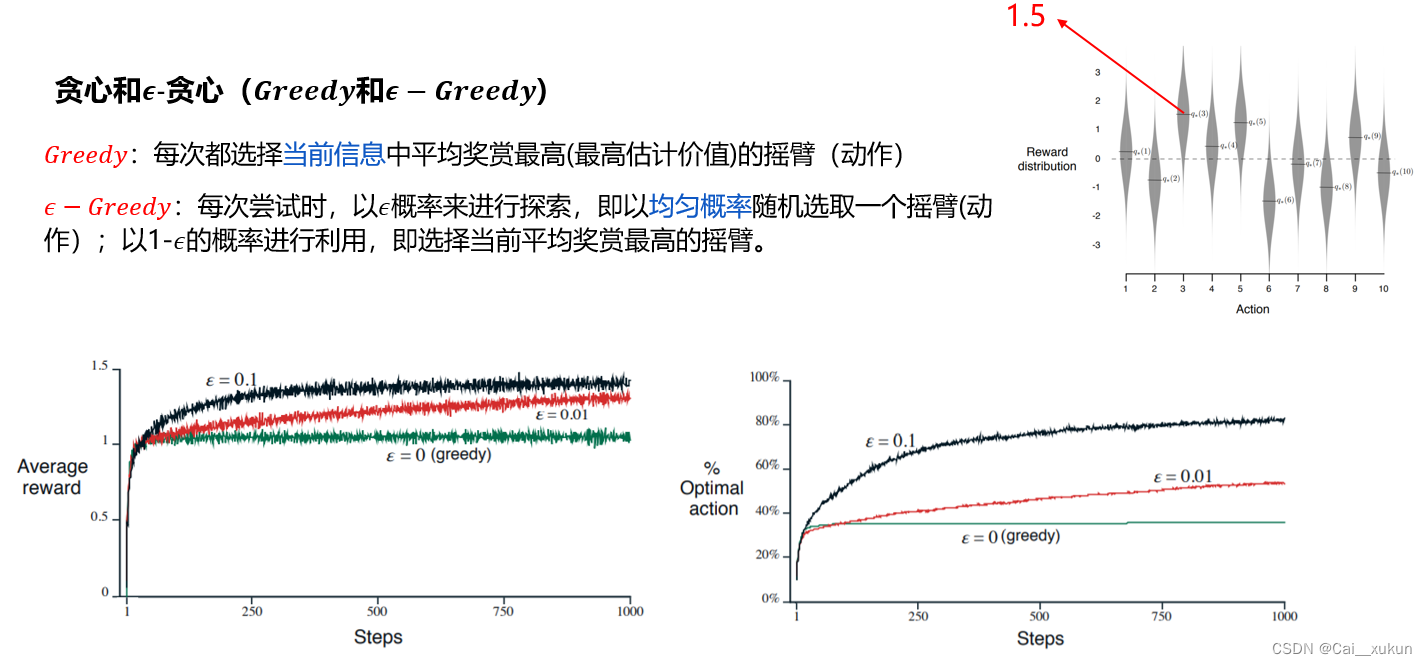
首先是贪心和e-贪心
贪心就是指一直利用,根据当前信息一直选择当前最高估计价值的动作。而e-贪心法基于一个概率来对探索和利用进行折中。每次尝试时,以e概率来进行探索,即以均匀概率随机选取一个摇臂;以1-e的概率进行利用,即选择当前平均奖赏最高的摇臂。
三.先进技术和方法解决困境
1.乐观初始值
这是一种比较讨巧的方法。
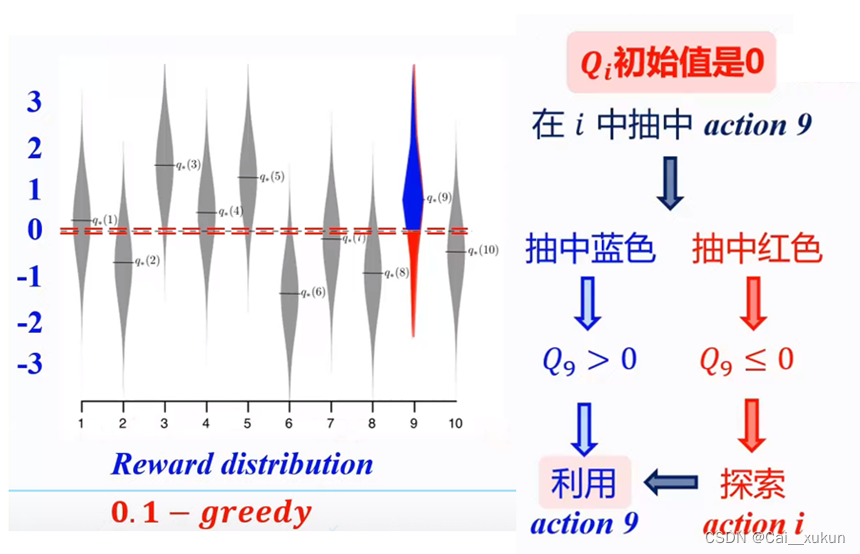
如图所示,当我们初始值为0的时候,假如我们选择了9为行动,当我们抽中蓝色部分的时候,估计值Q9>0,是高于初始值的,则会更新Q9,而其他动作初始值都是设为0,由于估计值是高于其他行动的初始值的,那么就会反复利用行动9,这是不利于探索的。而当抽中红色部分,Q9<0,估计值更新为小于0,其他行动初始值为0都是大于的,所以会进行探索,但是当探索到另一个动作抽中蓝色部分,则又会反复利用。
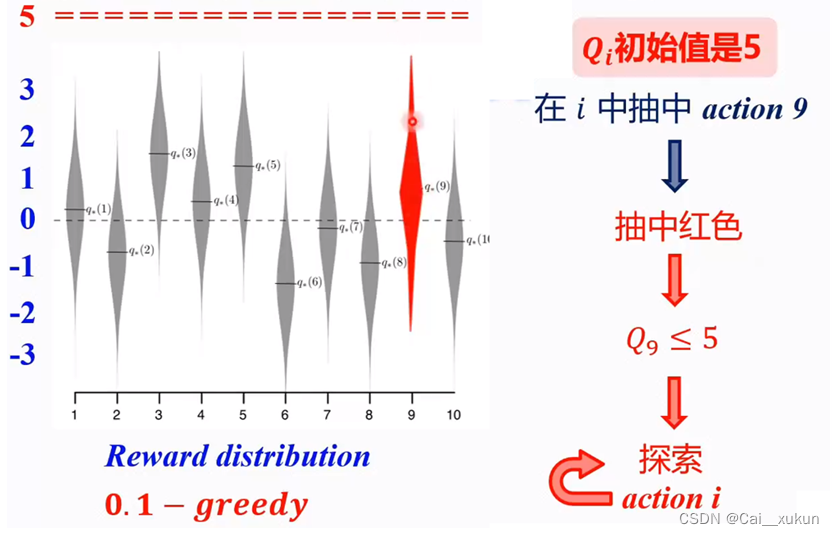
如图所示,当我们把初始值设置为5的时候,抽中行动9,则都会小于初始值,这种乐观的初始估计会鼓励试探,因为无论哪一种行动被选择,收益都会比最开始的估计值要小。
如图所示为两种方法的运行效果:
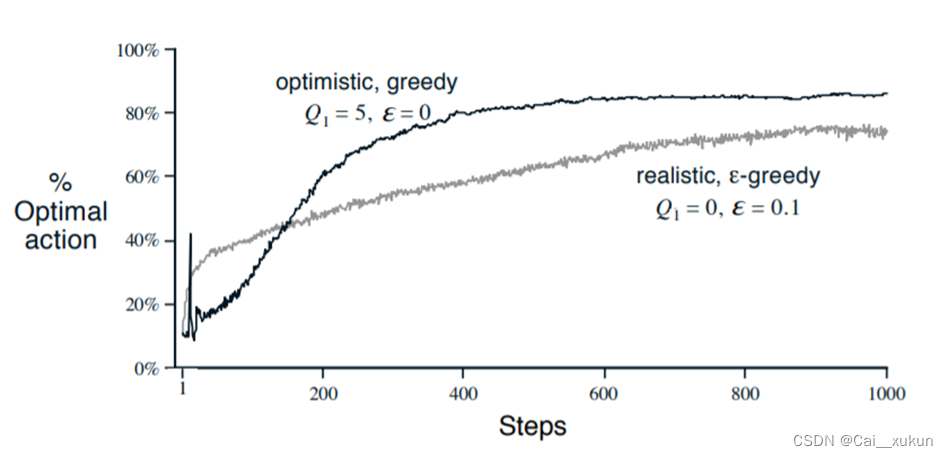
可以看到,乐观初始值的方法可以促进最优动作占比和平均收益提高,关于为什么乐观初始值的图像在接近11 Step时会有一个突然激增?因为前十次总是在试错探索,再从其中选择期望最高的,而选择期望最高的往往会是比较优的。
2.基于置信度上界的动作选择
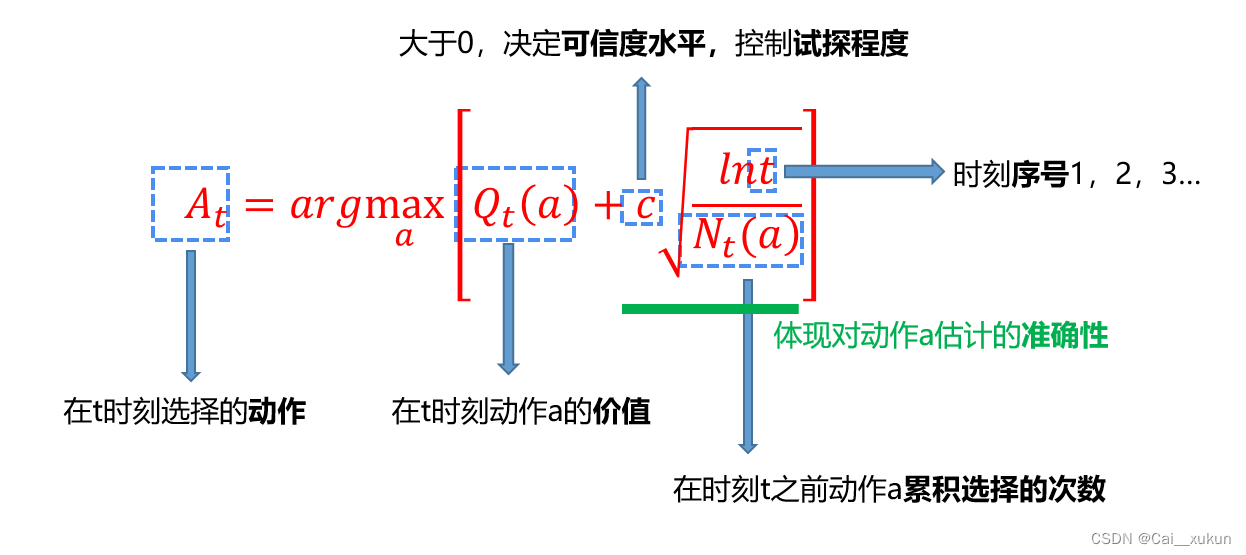
基于置信度上界的动作选择按照上述式子进行动作选择。Qt(a)表示在t时刻动作a的价值,而后面的大式子体现对动作a估计的准确性。由于存在分母Nt(a),表示时刻t之前动作a的累积次数,当其越小说明探索这个动作越少,则总的加和值就会越大,更加倾向于选择这个动作。
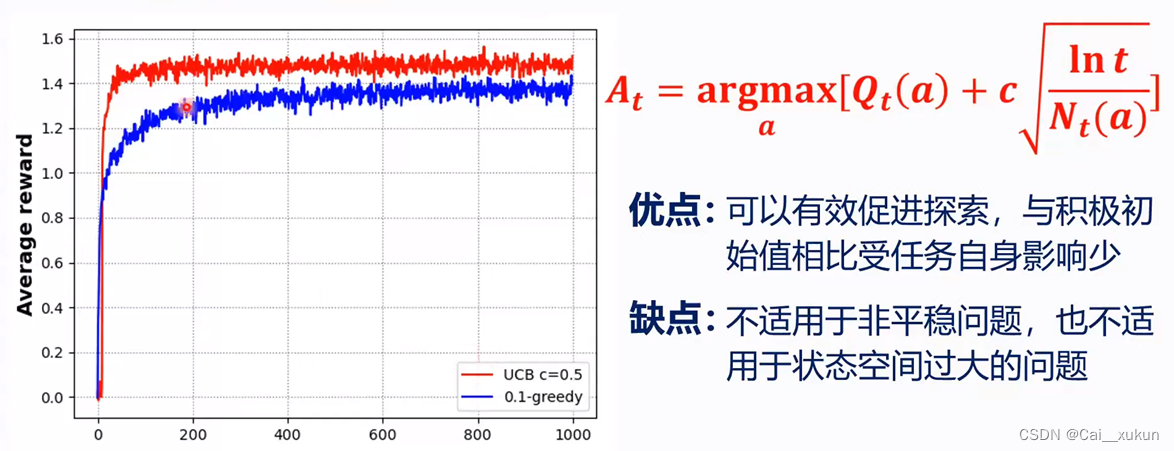
3.梯度赌博机算法
前面的方法都是用到的绝对值的数据,它们定义一个动作的优劣,都是取argmax,这显得有点偏激。而梯度赌博机算法利用相对趋势,显得更加平滑。

红色的式子看着很像softmax函数,实现多分类的选择,是sigmoid的扩展,其实就是softmax函数的效用模型,起到一个离散选择作用,也起到了一个效应放大器的作用,把效应好的选择的可能性进行放大。
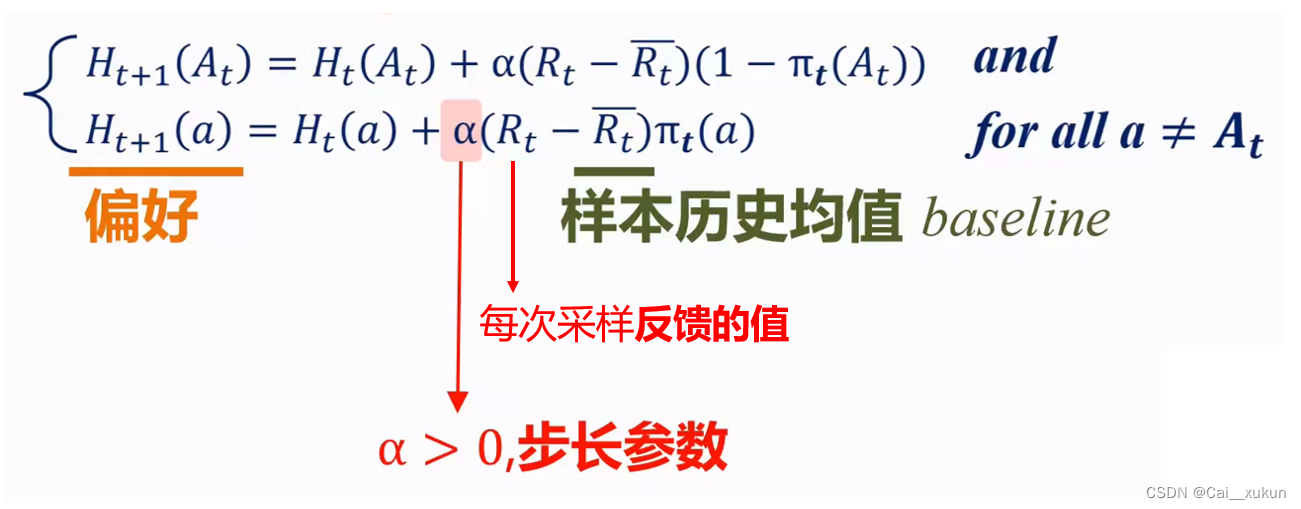
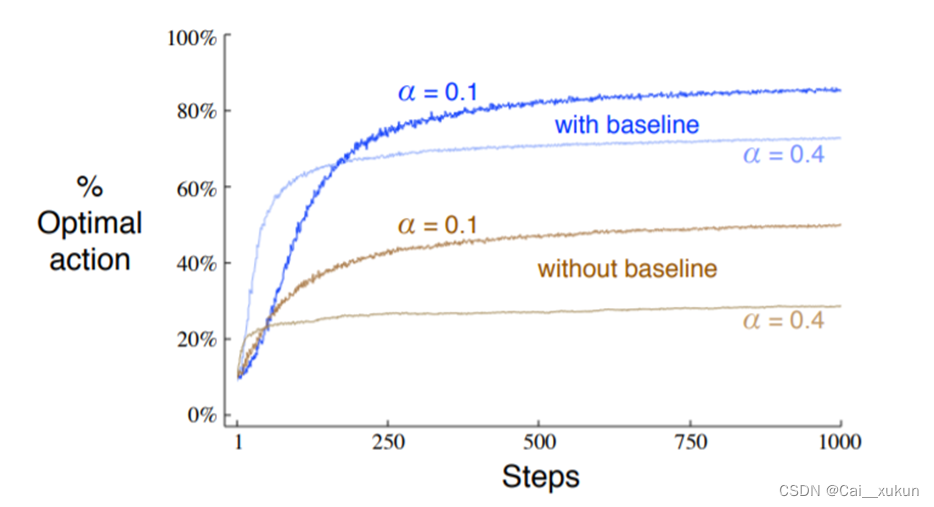
4.总结与分析
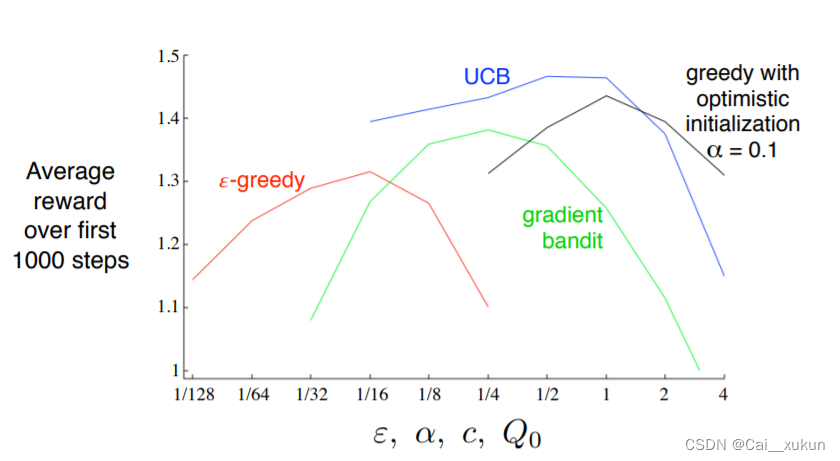

















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









