






最近读了一篇文献,仍是关于STAR-RIS的参数优化问题设计,文章题目为《Energy-Efficient Design for a NOMA assisted STAR-RIS Network with
Deep Reinforcement Learning》,即基于深度强化学习的NOMA辅助STAR-RIS网络节能设计。
一.概述
这篇文献采用同时发射和反射的可重构智能表明(STAR-RIS)作为通信模型中的辅助设备,以提高无线网络的性能,同时改善RIS的信号覆盖问题。并且这篇文章是基于非正交多址(NOMA)辅助的STAR-RIS下行网络能效优化问题。由于采用传统的凸优化方法不能很好地解决优化问题,此文献采用深度强化学习算法来进行优化,采用DDPG这种深度强化学习算法来联合优化基站处的发射波束赋形矢量和STAR-RIS处的系数矩阵来实现EE(Energy-Efficient)最大化。
1.STAR-RIS简介
STAR-RIS与RIS不同,RIS只能反射信号,而STAR-RIS可以通过同时反射和传输入射信号来服务位于表明前后两侧的用户,实现360°的覆盖,具有很大的优势。
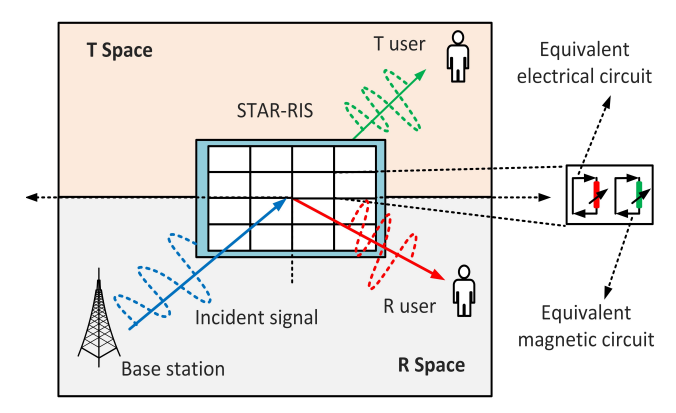
2. NOMA简介
参考BLOG: link
NOMA技术是5G当中的一个重要技术,面向5G频谱效率提升5~15倍的需求,业内提出采用新型多址接入复用方式,即非正交多址接入(NOMA)。NOMA不同于传统的正交传输,在发送端采用非正交发送,主动引入干扰信息,在接收端通过串行干扰删除技术实现正确解调。与正交传输相比,接收机复杂度有所提升,但可以获得更高的频谱效率。非正交传输的基本思想是利用复杂的接收机设计来换取更高的频谱效率,随着芯片处理能力的增强,将使非正交传输技术在实际系统中的应用成为可能。
在NOMA中采用的关键技术:
1、串行干扰删除(SIC)
在发送端,类似于CDMA系统,引入干扰信息可以获得更高的频谱效率,但是同样也会遇到多址干扰(MAI)的问题。关于消除多址干扰的问题,在研究第三代移动通信系统的过程中已经取得很多成果,串行干扰删除(SIC)也是其中之一。NOMA在接收端采用SIC接收机来实现多用户检测。串行干扰消除技术的基本思想是采用逐级消除干扰策略,在接收信号中对用户逐个进行判决,进行幅度恢复后,将该用户信号产生的多址干扰从接收信号中减去,并对剩下的用户再次进行判决,如此循环操作,直至消除所有的多址干扰。
2、功率复用
SIC在接收端消除多址干扰(MAI),需要在接收信号中对用户进行判决来排出消除干扰的用户的先后顺序,而判决的依据就是用户信号功率大小。基站在发送端会对不同的用户分配不同的信号功率,来获取系统最大的性能增益,同时达到区分用户的目的,这就是功率复用技术。功率复用技术在其他几种传统的多址方案没有被充分利用,其不同于简单的功率控制,而是由基站遵循相关的算法来进行功率分配。
二.系统模型与问题建模
1.系统模型
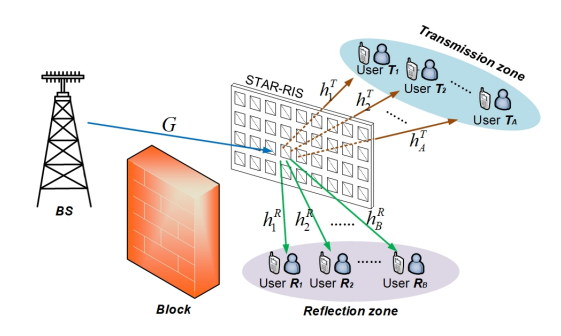
如图所示,考虑一个NOMA-MISO辅助STAR-RIS的下行网络,基站BS带有M个天线,STAR-RIS带有N个反射单元,基站通过具有N个单元的STAR-RIS将信号传输给多个单天线用户,其中分为反射区域和传输区域,假设BS到用户之间的直接链路被墙壁阻挡,采用NOMA下行传输服务。STAR-RIS遵循能量守恒定理,这在上一篇已经介绍,STAR-RIS的系数矩阵公式也已经介绍,具体详见链接: link。
本文中,从BS到用户的叠加信号用公式表示为:
y
ϵ
=
h
ϵ
H
Φ
k
(
ϵ
)
G
∑
v
∈
Ω
ω
v
s
v
+
z
_{y_{\epsilon}=\boldsymbol{h}_{\epsilon}^{H}\Phi ^{k\left( \epsilon \right)}\boldsymbol{G}\sum_{v\in \Omega}{\boldsymbol{\omega }}_vs_v+z}
yϵ=hϵHΦk(ϵ)G∑v∈Ωωvsv+z
其中 表示STAR-RIS与用户之间透射或者反射信道的共轭转置,
表示STAR-RIS与用户之间透射或者反射信道的共轭转置, 表示BS到STAR-RIS的信道,
表示BS到STAR-RIS的信道,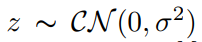 表示加性高斯白噪声,
表示加性高斯白噪声,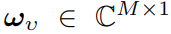 表示波束赋形向量,
表示波束赋形向量,![]() 表示用户v的信号
表示用户v的信号
关于NOMA传输方案,我们已经了解到要对用户即接收端采用串行干扰技术SIC。这篇文章当中首先假设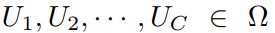 ,C表示反射用户总数量B和传输用户总数量A的和,即C=A+B,假设所有用户解码顺序为
,C表示反射用户总数量B和传输用户总数量A的和,即C=A+B,假设所有用户解码顺序为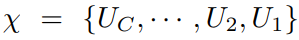 。则用户
。则用户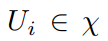 可实现数据速率为
可实现数据速率为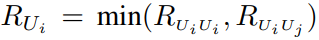 ,其中
{
R
U
i
U
i
=
log
2
(
1
+
∣
h
U
i
H
Φ
k
(
U
i
)
G
ω
U
i
∣
2
∑
U
z
∈
χ
′
∣
h
U
i
H
Φ
k
(
U
i
)
G
ω
U
z
∣
2
+
σ
2
)
.
R
U
i
U
j
=
log
2
(
1
+
∣
h
U
j
H
Φ
k
(
U
j
)
G
ω
U
i
∣
2
∑
U
z
∈
χ
′
∣
h
U
j
H
Φ
k
(
U
j
)
G
ω
U
z
∣
2
+
σ
2
)
\left\{ \begin{array}{l} R_{U_iU_i}=\log _2\left( 1+\frac{|h_{U_i}^{H}\Phi ^{k\left( U_i \right)}G\omega _{U_i}|^2}{\sum_{U_z\in \chi '}{|}h_{U_i}^{H}\Phi ^{k\left( U_i \right)}G\omega _{U_z}|^2+\sigma ^2} \right) .\\ \\ R_{U_iU_j}=\log _2\left( 1+\frac{|h_{U_j}^{H}\Phi ^{k\left( U_j \right)}G\omega _{U_i}|^2}{\sum_{U_z\in \chi '}{|}h_{U_j}^{H}\Phi ^{k\left( U_j \right)}G\omega _{U_z}|^2+\sigma ^2} \right)\\ \end{array} \right.
⎩
⎨
⎧RUiUi=log2(1+∑Uz∈χ′∣hUiHΦk(Ui)GωUz∣2+σ2∣hUiHΦk(Ui)GωUi∣2).RUiUj=log2(1+∑Uz∈χ′∣hUjHΦk(Uj)GωUz∣2+σ2∣hUjHΦk(Uj)GωUi∣2)
,其中
{
R
U
i
U
i
=
log
2
(
1
+
∣
h
U
i
H
Φ
k
(
U
i
)
G
ω
U
i
∣
2
∑
U
z
∈
χ
′
∣
h
U
i
H
Φ
k
(
U
i
)
G
ω
U
z
∣
2
+
σ
2
)
.
R
U
i
U
j
=
log
2
(
1
+
∣
h
U
j
H
Φ
k
(
U
j
)
G
ω
U
i
∣
2
∑
U
z
∈
χ
′
∣
h
U
j
H
Φ
k
(
U
j
)
G
ω
U
z
∣
2
+
σ
2
)
\left\{ \begin{array}{l} R_{U_iU_i}=\log _2\left( 1+\frac{|h_{U_i}^{H}\Phi ^{k\left( U_i \right)}G\omega _{U_i}|^2}{\sum_{U_z\in \chi '}{|}h_{U_i}^{H}\Phi ^{k\left( U_i \right)}G\omega _{U_z}|^2+\sigma ^2} \right) .\\ \\ R_{U_iU_j}=\log _2\left( 1+\frac{|h_{U_j}^{H}\Phi ^{k\left( U_j \right)}G\omega _{U_i}|^2}{\sum_{U_z\in \chi '}{|}h_{U_j}^{H}\Phi ^{k\left( U_j \right)}G\omega _{U_z}|^2+\sigma ^2} \right)\\ \end{array} \right.
⎩
⎨
⎧RUiUi=log2(1+∑Uz∈χ′∣hUiHΦk(Ui)GωUz∣2+σ2∣hUiHΦk(Ui)GωUi∣2).RUiUj=log2(1+∑Uz∈χ′∣hUjHΦk(Uj)GωUz∣2+σ2∣hUjHΦk(Uj)GωUi∣2)
其中![]() 表示用户Ui解码自身信号时的解码数据率,
表示用户Ui解码自身信号时的解码数据率,![]() 表示用户Uj对用户Ui进行解码时,用户Uj的解码数据速率。
表示用户Uj对用户Ui进行解码时,用户Uj的解码数据速率。
2.问题建模
在这篇文献中,待解决的问题是能量效率EE最大化,EE可以表示为
η
E
E
=
B
w
∑
ϵ
∈
Ω
R
ϵ
1
γ
P
T
+
P
C
\eta _{EE}=\frac{B_w\sum_{\epsilon \in \Omega}{R}_{\epsilon}}{\frac{1}{\gamma}P_T+P_C}
ηEE=γ1PT+PCBw∑ϵ∈ΩRϵ
这是一个标准的能量效率公式,PT是基站BS的发射功率(理想条件下可表示为所有用户总功率),PC是总的功耗,γ∈(0,1)表示功率放大器在BS的效率。这里简单介绍一下能量效率是什么。能量效率(Energy Efficiency,EE),简称能效。通信中能效的定义为有效信息传输速率R(bps)与信号发射功率(w)的比值,即比特每焦耳(J=w*s)。EE描述了系统消耗单位能量时可以获得的信息传输比特数,代表了系统对能量资源的利用效率。在无线通信中,将能量效率定义为单位带宽下每比特消耗的能量,即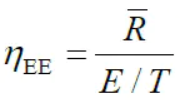 。故这篇文章建立的能效优化问题如下所示:
。故这篇文章建立的能效优化问题如下所示:

约束(4b)表示基站最大传输功率限制,约束(4c)和(4d)是STAR-RIS的幅度和相移系数的相关约束,约束(4e)表示用户的服务质量QoS(quality of service)要求。这个优化问题很难通过传统优化算法解决,所有这篇文章采取基于DRL深度强化学习的算法,共同优化波束赋形矢量和系数矩阵,这篇文献采用的是DDPG算法,解决连续优化问题。
三.采用DDPG算法联合优化
1.DDPG简介
DDPG基于actor-critic结构,包含四个神经网络,分别是行动者网络,行动者目标网络,评论家网络,评论家目标网络。具体可以参考以下链接,这里不再赘述。
深度强化学习-DDPG算法原理与代码
初探强化学习(5)DDPG算法。包含逐行分析Pytorch代码和算法分析
2.DDPG算法在该文献中的应用
一般来说,将强化学习应用于优化问题,需要考虑动作空间,状态空间,奖励函数,神经网络,以及约束的处理方法。这篇文献动作向量、状态向量和奖励函数的设计如下所示:
(1)动作向量
这篇文献采用波束赋形向量![]() 和系数矩阵
和系数矩阵![]() 作为动作向量,由于神经网络输入是实数,所以要将波束赋形向量和系数矩阵这复数分解为实部和虚部,则第t步训练的动作向量表示为:
作为动作向量,由于神经网络输入是实数,所以要将波束赋形向量和系数矩阵这复数分解为实部和虚部,则第t步训练的动作向量表示为:
a
(
t
)
=
{
Re{
ω
ϵ
(
t
)
}
,
Im{
ω
ϵ
(
t
)
}
,
Re{
Φ
n
τ
,
(
t
)
}
,
Im{
Φ
n
τ
,
(
t
)
}
}
a^{\left( t \right)}=\{\text{Re\{}\omega _{\epsilon}^{\left( t \right)}\},\text{Im\{}\omega _{\epsilon}^{\left( t \right)}\},\text{Re\{}\Phi _{n}^{\tau ,\left( t \right)}\},\text{Im\{}\Phi _{n}^{\tau ,\left( t \right)}\}\}
a(t)={Re{ωϵ(t)},Im{ωϵ(t)},Re{Φnτ,(t)},Im{Φnτ,(t)}}
(2)状态向量
状态向量充分呈现通信系统的状态并且优化问题,在t步将状态向量设计为:
s
(
t
)
=
{
R
ϵ
(
t
)
,
∣
∣
ω
ϵ
(
t
)
∣
∣
2
,
∣
h
ϵ
H
,
(
q
)
Φ
k
(
ϵ
)
,
(
t
)
G
(
q
)
∣
2
}
s^{\left( t \right)}=\{R_{\epsilon}^{\left( t \right)},||\omega _{\epsilon}^{\left( t \right)}||^2,|h_{\epsilon}^{H,\left( q \right)}\Phi ^{k\left( \epsilon \right) ,\left( t \right)}G^{\left( q \right)}|^2\}
s(t)={Rϵ(t),∣∣ωϵ(t)∣∣2,∣hϵH,(q)Φk(ϵ),(t)G(q)∣2}
(3)奖励函数
奖励函数是强化学习中特别重要的一部分,好的奖励函数能让训练更加顺利。此文优化问题是最大化EE,故t训练步骤的奖励采用EE,即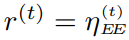 。DDPG的神经网络,两个actor网络的结构都是一个输入层,一个隐藏层,一个归一化层,一个隐藏层和一个输入层。在归一化层采用RELU激活函数,在第二层隐藏层采用Tanh激活函数。而两个critic网络,状态向量和动作向量分别送入两个单独的隐藏层,然后连接到两个归一化层,然后将两个归一化层连接起来,然后连接到一个隐藏层。采用Adam优化器优化神经网络参数,演员和评论家学习率分别为0.001和0.002。
。DDPG的神经网络,两个actor网络的结构都是一个输入层,一个隐藏层,一个归一化层,一个隐藏层和一个输入层。在归一化层采用RELU激活函数,在第二层隐藏层采用Tanh激活函数。而两个critic网络,状态向量和动作向量分别送入两个单独的隐藏层,然后连接到两个归一化层,然后将两个归一化层连接起来,然后连接到一个隐藏层。采用Adam优化器优化神经网络参数,演员和评论家学习率分别为0.001和0.002。
波束赋形向量![]() 是动作向量的一部分,而动作向量是actor网络的输出,且动作训练每个元素被Tanh激活函数限制在(-1,1)的范围,由于这个范围,故波束赋形向量不能直接用于计算EE,所以要对波束赋形向量进行转换。转换为新的波束赋形向量为
ω
^
ϵ
(
t
)
=
λ
ϵ
(
t
)
ω
ϵ
(
t
)
\boldsymbol{\hat{\omega}}_{\epsilon}^{\left( t \right)}=\sqrt{\lambda _{\epsilon}^{\left( t \right)}}\boldsymbol{\omega }_{\epsilon}^{\left( t \right)}
ω^ϵ(t)=λϵ(t)ωϵ(t)
是动作向量的一部分,而动作向量是actor网络的输出,且动作训练每个元素被Tanh激活函数限制在(-1,1)的范围,由于这个范围,故波束赋形向量不能直接用于计算EE,所以要对波束赋形向量进行转换。转换为新的波束赋形向量为
ω
^
ϵ
(
t
)
=
λ
ϵ
(
t
)
ω
ϵ
(
t
)
\boldsymbol{\hat{\omega}}_{\epsilon}^{\left( t \right)}=\sqrt{\lambda _{\epsilon}^{\left( t \right)}}\boldsymbol{\omega }_{\epsilon}^{\left( t \right)}
ω^ϵ(t)=λϵ(t)ωϵ(t)
其中这个新的构造的波束赋形向量![]() 同样应该满足BS的功率要求,即满足功率限制,并且其与原波束赋形向量要是同一个方向。该转换参数满足以下公式:
同样应该满足BS的功率要求,即满足功率限制,并且其与原波束赋形向量要是同一个方向。该转换参数满足以下公式:
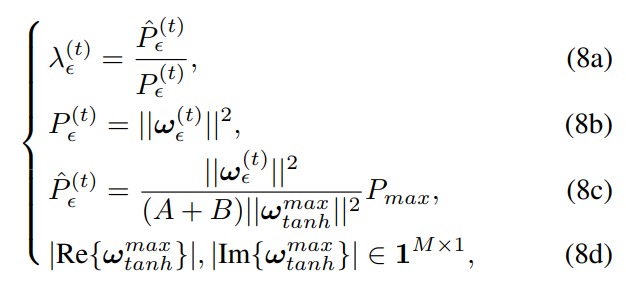
其中![]() 表示原来波束赋形的传输功率,
表示原来波束赋形的传输功率,![]() 表示转换后的传输功率,
表示转换后的传输功率,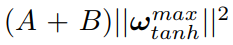 给出Tanh函数范围内所有用户可实现的最大值。
给出Tanh函数范围内所有用户可实现的最大值。![]() 是功率比率,可以创造一个新的归一化波束赋形向量。
是功率比率,可以创造一个新的归一化波束赋形向量。
类似地,需要自定义归一化系数矩阵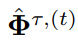 ,即
,即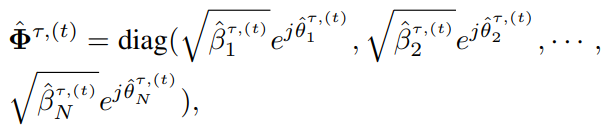
,其中
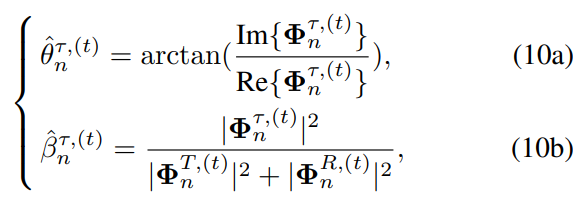 ,其中(10a)保证
,其中(10a)保证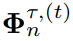 极坐标形式与其矩阵形式保持相同幅度,(10b)保证满足约束(4c)。
极坐标形式与其矩阵形式保持相同幅度,(10b)保证满足约束(4c)。
而针对奖励函数,针对训练第t步的奖励,可以构造出新的奖励函数如下所示:
r
^
(
t
)
=
ζ
r
(
t
)
\hat{r}^{\left( t \right)}=\zeta r^{\left( t \right)}
r^(t)=ζr(t)
其中ζ是奖励函数的惩罚因子,可以如下表示:
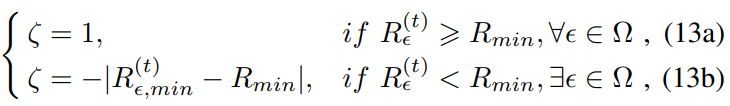
这一举措主要是能够满足约束条件(4e),采用惩罚项来实现,当不满足约束条件,即给一个负奖励,(13a)表示如果所有用户数据速率满足要求,则奖励保持不变,若不满足,则给一个负数惩罚项。
4.仿真结果
算法伪代码如下所示

信道增益![]() 和
和![]() 满足莱斯衰落模型
满足莱斯衰落模型
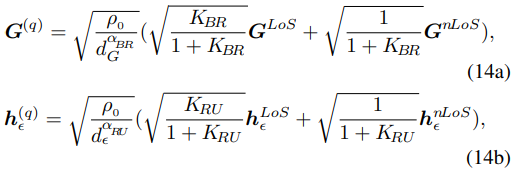
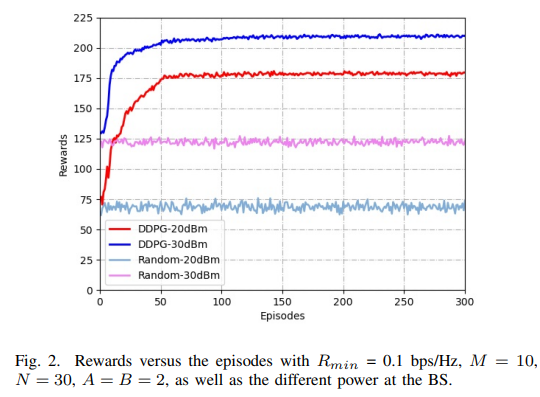
仿真结果图2如上所示,分别考虑BS功率最大值为20dBm和30dBm,STAR-RIS每侧有两个用户,从中可以看出STAR-RIS随机系数方案表现不佳,但是DDPG算法能够有性能显著提高。
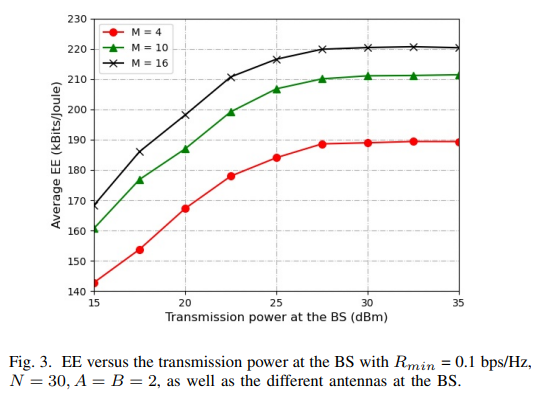
上图展示了不同的天线数量变化情况,EE与发射功率的关系,STAR-RIS元件数量N为30,可以看到,随着传输功率增加,EE会增加到一个峰值并且保持不变,表明在BS处EE不能随着功率增强而持续增加,性能提升幅度不断变小。
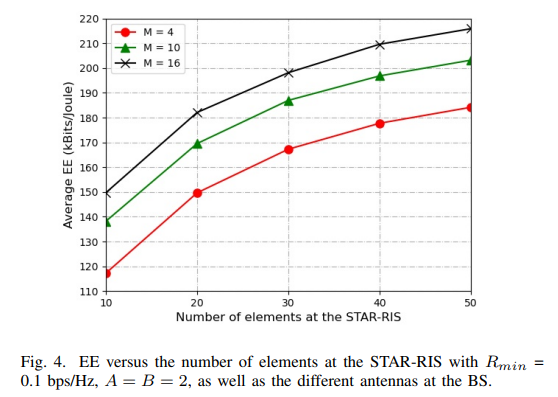
如上图所示,横坐标为STAR-RIS的反射元件数量,纵坐标为平均能量效率,随着STAR-RIS元件数量增加,EE增加。

















 650
650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









