







我们又见面了,续着之前的Python高级,我们来说说今天的知识点,早就废话不多说,直接开始我们的战斗!谁都别拦我,这把我要拿五杀!!!
装饰器
第一个要说的知识点就是装饰器,我们照旧先来看它的概念。先了解一下OCP原则。
OCP原则(open close protocol):对已有运行(稳定的)代码,不应该修改它,如果你增加新的功能,添加新的功能代码即可
对修改关闭、对增加扩展开放。
那到底什么是装饰器?
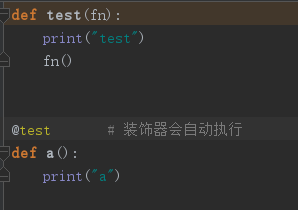
装饰器就是一个闭包函数,它能够@闭包名称
装饰一个原有的函数,
是的原有函数的功能更加的强大
那我们如何定义装饰器?
1、首先定义一个闭包,闭包有一个默认的参数,是一个引用,该引用就是需要装饰的函数
2、一个需要在里面函数里面调用引用(函数),在调用之前写的代码就会被装饰在原函数之前,再fn()调用之后的代码,会被装饰在原函数之后。

装饰器原理
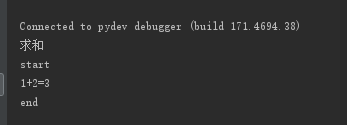
用了断点调试,追踪了下代码的运行流程,发现装饰器的运行原理
python动态语言允许动态添加或者删除属性和方法
class User(object):
def __init__(self):
self.name = "xixi"
self.age = 16
if __name__ == '__main__':
u1 = User()
print(u1.name)
print(u1.age)
# 动态语言的特性
u1.gender = "girl"
print(u1.gender)
del u1.name
print(u1.name)
python垃圾回收机制的原理:
以引用计数为主,以分代收集和标记清除为辅
正则表达式(Ragular Expression)
1、 什么是正则
正则表达式,正则匹配式、表示式,使用一些特殊符号来匹配、查找、替换字符串文本的一种技术。
2、re模板
>>> import re
>>> res=re.match("today","today is rainy")
>>> res.group()# 将匹配的结果显示
使用 res.group()提取匹配结果,
如果是,则返回匹配对象(Match Object),否则返 回 None
'today'
3、元字符
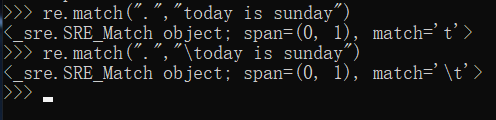
使用re.match来匹配开头(第一个符号,有则返回匹配的东西,没有则显示None,什么也不显示)
以下是常用的一些元字符
. # 匹配任意符号(除换行符外(\n))
\d # 匹配数字 digest
\w # 匹配所有的有效(大小写字母、数字、下划线_、各国语言符号)
\s # 匹配空白位 (如:空格、\t)
^ # 以xx开头
$ # 以xxx结尾
[] # 列举 # [0123456789] <==> \d 有效符号:[A-Za-z0-9_],大小写字母:[A-Za-z]
下面实际运用下,更加明了的理解下。

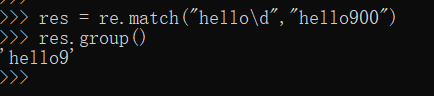


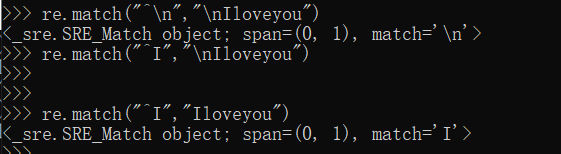
4、反义符
\D # 非数字
\W # 特殊符号
\S # 非空白位
[^] # 列举反义 注意[]和[]的区别
[^] # 列举反义 注意 举例:[^]和[^]
^[]匹配[ ]里开头的
[^]匹配不是[]里的字符
re.match("[^abcd]","a")
#表示除 a、b、c、d 外的任何字符都匹配
5、转义符
在python的字符串中\是具有特殊含义要正常表示一个\,需要两个\来表示在正则中,\是具有特殊含义的,要正常表示一个\,需要两个\来表示
建议大家以后在写正则的时候,一定要在正则表达式前面加上r
re.match("c:\\","c:\\a\\b")
# error 报错,因为\\转义后就变成了\了
re.match("c:\\\\","c:\\a\\b") #正确
re.match(r"c:\\","c:\\a\\b") # 正确,
表示匹配的字符不进行转义【推荐】,
以后匹配符不要再写出上面的的转义了。
比如你查找.,或者*,就出现了问题:你没法指定它们,因为它们会被解释成其它的意思。这时你就必须使用\来取消这些字符的特殊意义
6、位数
(1) * # 表示匹配任意位(可以是0位、可以是1位、可以有n位)
(2) + # 至少一位(至少是1位、可以有n位)
(3) ? # 0位或者1位
(4) {n} # 有n位
(5){n,} # 至少n
(6){n, m} # 表示n~m这个区间范围
7、分组(group)
在正则表达式中,使用圆括号()将正则中包裹起来,会形成正则匹配后的二次筛选分组最大的好处就是能够形成第二次筛选
r"</?.*?>" # 匹配HTML标签
|-- 贪婪模式和非贪婪(懒惰)模式
|-- Python,默认都是使用贪婪模式
将贪婪转换为非贪婪模式使用?
今天的整理先到这里,我还有有些地方还有些迷糊,所以待我温习一遍,再过来补上更新。
加油的一天,奥里给!















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









