






目录
前言
使用的编译环境和工具:Anaconda、Jupyter Notebook
需要安装的库:librosa(用于音频处理)、sklearn(用于机器学习模型的训练和预测)
安装方法:
1.打开Anaconda Prompt终端
2.运行以下命令来更新conda:conda update conda
3.安装librosa:conda install -c conda-forge librosa
4.安装scikit-learn:conda install scikit-learn
数据集准备
我的数据集来自百度AI开放数据集:
婴儿啼哭声识别 - 飞桨AI Studio (baidu.com) https://aistudio.baidu.com/aistudio/datasetdetail/41960文件结构:
https://aistudio.baidu.com/aistudio/datasetdetail/41960文件结构:
| babycry(总文件夹) | |||||||
| data(数据集) | Voice_baby_cry.ipynb(代码文件) | ||||||
| test(测试集) | train(训练集) | ||||||
| .wav | awake | diaper | hug | hungry | sleepy | uncomfortable | |
| .wav | .wav | .wav | .wav | .wav | .wav | ||
代码文件
import os
import librosa
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# 定义特征提取函数
def extract_features(file_path):
# 读取音频文件
y, sr = librosa.load(file_path, sr=None)
# 提取mfcc特征
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
# 计算mfcc的平均值和标准差
mfccs_mean = np.mean(mfccs, axis=1)
mfccs_std = np.std(mfccs, axis=1)
# 将平均值和标准差合并为一个向量
feature_vector = np.concatenate((mfccs_mean, mfccs_std))
return feature_vector
# 定义训练函数
def train(train_dir):
# 读取训练集中的音频文件并进行特征提取
features = []
labels = []
for root, dirs, files in os.walk(train_dir):
for file_name in files:
if file_name.endswith(".wav"):
file_path = os.path.join(root, file_name)
label = os.path.basename(os.path.dirname(file_path))
feature_vector = extract_features(file_path)
features.append(feature_vector)
labels.append(label)
# 使用随机森林模型进行训练
clf = RandomForestClassifier(n_estimators=100)
clf.fit(features, labels)
return clf
# 定义预测函数
def predict(test_dir, clf):
# 读取待测音频文件并进行特征提取
features = []
for file_name in os.listdir(test_dir):
file_path = os.path.join(test_dir, file_name)
feature_vector = extract_features(file_path)
features.append(feature_vector)
# 使用训练好的模型进行分类
predicted_labels = clf.predict(features)
# 使用训练好的模型计算分类置信度
confidence = clf.predict_proba(features)
return predicted_labels, confidence
# 训练模型
train_dir = './data/train'
clf = train(train_dir)
# 预测待测音频文件的标签和置信度
test_dir = './data/test'
predicted_labels, confidence = predict(test_dir, clf)
# 输出预测结果和置信度
for i, label in enumerate(predicted_labels):
print('文件名:', os.listdir(test_dir)[i])
print('标签:', label)
print('置信度:', confidence[i])这段代码实现了一个基于MFCC特征和随机森林模型的音频分类器,可以对指定测试集中的音频文件进行分类,并输出预测结果和分类置信度。
实现过程分析
一、导入需要用到的库:
os:用于文件操作;
librosa:用于音频处理;
numpy:用于数学计算;
sklearn:用于机器学习模型的训练和预测。
二、定义特征提取函数 extract_features(file_path),读取指定路径的音频文件,使用librosa库提取MFCC特征,计算平均值和标准差,并将平均值和标准差合并为一个向量,作为该音频文件的特征向量。
三、定义训练函数 train(train_dir),遍历指定路径下的训练集音频文件,调用 extract_features() 提取特征,并将特征向量添加到特征集 features 中,将标签添加到标签集 labels 中,最后使用随机森林模型进行训练,返回训练好的模型 clf。
四、定义预测函数 predict(test_dir, clf),遍历指定路径下的测试集音频文件,调用 extract_features() 提取特征,并将特征向量添加到特征集 features 中,使用训练好的随机森林模型 clf 进行分类预测,并计算分类置信度。
五、训练模型,调用 train(train_dir) 函数,读取训练集中的音频文件,提取特征并训练随机森林模型 clf。
六、预测待测音频文件的标签和置信度,调用 predict(test_dir, clf) 函数,读取测试集中的音频文件,提取特征并进行分类预测和计算置信度,返回预测结果和置信度。
七、输出预测结果和置信度,遍历预测结果,输出每个待测音频文件的文件名、预测标签和分类置信度。
MFCC特征
MFCC是Mel Frequency Cepstral Coefficients的缩写,是一种广泛应用于语音和音频信号处理的特征提取方法。它可以提取音频信号中的语音信息,从而用于音频分类、语音识别等任务。
MFCC将音频信号的频率域信息转化为一组在倒谱域中均匀分布的特征,这些特征被称为MFCC系数。MFCC系数的提取过程包括以下几个步骤:
1. 预处理:对音频信号进行预加重和分帧处理,将信号分成短时间段,每个时间段称为帧。
2. 傅里叶变换:对每个帧进行离散傅里叶变换(DFT),将信号从时域转化到频域。
3. 梅尔滤波器组:对DFT的结果进行梅尔滤波器组处理,将DFT频谱映射到梅尔刻度上。
4. 对数运算:对每个梅尔滤波器输出的幅度值取对数,将幅度谱转化为分贝(dB)单位。
5.倒谱变换:对取对数后的幅度谱进行离散余弦变换(DCT),得到倒谱系数。
最终,MFCC特征向量由一组倒谱系数构成,一般选择前20个系数作为特征。这些系数对音频信号的语音内容具有很强的代表性,可以用于音频分类和语音识别等任务。
随机森林模型
随机森林(Random Forest)是一种集成学习算法,它是由多个决策树组成的分类器。随机森林可以用于分类和回归问题,是一种非常强大的机器学习算法。
在随机森林中,每个决策树都是由随机选取的一部分数据和随机选取的一部分特征组成的。通过随机选择数据和特征,可以减少决策树之间的相关性,从而提高随机森林的泛化能力和减少过拟合的风险。
随机森林模型的训练过程包括以下几个步骤:
1. 从训练数据中随机选择一部分数据和一部分特征。
2. 使用选择的数据和特征训练一个决策树模型。
3. 重复步骤1和步骤2多次,训练多个不同的决策树模型。
4. 对于分类问题,将多个决策树的分类结果进行投票,选择票数最多的类别作为最终的分类结果。对于回归问题,将多个决策树的预测结果进行平均或加权平均,作为最终的回归结果。
随机森林具有良好的鲁棒性、准确性和可解释性,广泛应用于各种机器学习任务中。
分段释义
def extract_features(file_path):
# 读取音频文件
y, sr = librosa.load(file_path, sr=None)
# 提取mfcc特征
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20)
# 计算mfcc的平均值和标准差
mfccs_mean = np.mean(mfccs, axis=1)
mfccs_std = np.std(mfccs, axis=1)
# 将平均值和标准差合并为一个向量
feature_vector = np.concatenate((mfccs_mean, mfccs_std))
return feature_vector这段代码实现了对音频文件进行MFCC特征提取的过程。具体解释如下:
1. librosa.load(file_path, sr=None):使用Librosa库的load函数读取音频文件。file_path参数指定音频文件的路径,sr=None参数指定采样率为原始采样率。
2. librosa.feature.mfcc(y=y, sr=sr, n_mfcc=20):使用Librosa库的mfcc函数对音频数据进行MFCC特征提取。y参数为音频数据,sr参数为采样率,n_mfcc参数为提取的MFCC系数的数量,这里取20。
3. np.mean(mfccs, axis=1):使用NumPy库的mean函数计算每个MFCC系数在时间维度上的平均值。axis=1参数表示对时间维度(即每一列)进行计算。
4. np.std(mfccs, axis=1):使用NumPy库的std函数计算每个MFCC系数在时间维度上的标准差。
5. np.concatenate((mfccs_mean, mfccs_std)):使用NumPy库的concatenate函数将MFCC系数的平均值和标准差合并为一个特征向量。
6. return feature_vector:返回特征向量作为函数的输出。
def train(train_dir):
# 读取训练集中的音频文件并进行特征提取
features = []
labels = []
for root, dirs, files in os.walk(train_dir):
for file_name in files:
if file_name.endswith(".wav"):
file_path = os.path.join(root, file_name)
label = os.path.basename(os.path.dirname(file_path))
feature_vector = extract_features(file_path)
features.append(feature_vector)
labels.append(label)
# 使用随机森林模型进行训练
clf = RandomForestClassifier(n_estimators=100)
clf.fit(features, labels)
return clf这段代码定义了一个训练函数 train(),它接受一个参数 train_dir,代表训练集数据所在的文件夹路径。该函数的作用是将训练集数据读取并进行特征提取,然后使用随机森林模型进行训练。
具体来说,这段代码做了以下工作:
1. 创建两个空列表 features 和 labels,用于存储特征向量和对应的标签。
2. 使用 os.walk() 函数遍历 train_dir 文件夹及其子文件夹中的所有文件和目录,并获取每个 .wav 格式的音频文件的路径。
3. 对于每个音频文件,调用 extract_features() 函数提取 MFCC 特征,并将得到的特征向量添加到 features 列表中。
4. 从音频文件路径中获取标签信息,并将标签添加到 labels 列表中。
5. 使用 RandomForestClassifier 函数创建一个随机森林分类器,其中 n_estimators=100 表示使用 100 棵决策树构建随机森林。
6. 使用 clf.fit(features, labels) 函数训练随机森林分类器,其中 features 是特征向量的列表,labels 是对应的标签列表。
7. 返回训练好的随机森林分类器 clf。
# 定义预测函数
def predict(test_dir, clf):
# 读取待测音频文件并进行特征提取
features = []
for file_name in os.listdir(test_dir):
file_path = os.path.join(test_dir, file_name)
feature_vector = extract_features(file_path)
features.append(feature_vector)
# 使用训练好的模型进行分类
predicted_labels = clf.predict(features)
# 使用训练好的模型计算分类置信度
confidence = clf.predict_proba(features)
return predicted_labels, confidence这段代码是用训练好的随机森林模型对测试数据进行预测,并返回预测结果和置信度。
具体来说,这个函数接受两个参数:测试数据的目录路径和训练好的随机森林模型clf。
首先,它遍历测试数据目录下的每个文件,调用 extract_features 函数提取特征,并将特征向量添加到 features 列表中。
然后,使用 clf 对 features 列表中的特征向量进行预测,返回预测的标签列表 predicted_labels。
同时,使用 clf.predict_proba() 函数计算每个样本被预测为每个类别的概率,并返回一个二维数组 confidence,其中每一行表示一个样本,每一列表示一个类别。
最后,函数返回 predicted_labels 和 confidence。
# 训练模型
train_dir = './data/train'
clf = train(train_dir)
# 预测待测音频文件的标签和置信度
test_dir = './data/test'
predicted_labels, confidence = predict(test_dir, clf)
# 输出预测结果和置信度
for i, label in enumerate(predicted_labels):
print('文件名:', os.listdir(test_dir)[i])
print('标签:', label)
print('置信度:', confidence[i])这段代码实现了一个音频分类器的测试部分。
首先指定训练集和测试集所在的文件夹。
然后使用之前训练好的模型对测试集中的音频文件进行分类。分类结果和对应的分类置信度被存储在predicted_labels和confidence变量中。
接下来,使用一个循环遍历每个测试文件并输出对应的文件名、分类标签和分类置信度。enumerate函数用于获取每个文件的索引值,从而可以通过索引值来访问predicted_labels和confidence中的对应值。
最后的输出是一个包含文件名、标签和置信度的信息列表。
效果展示
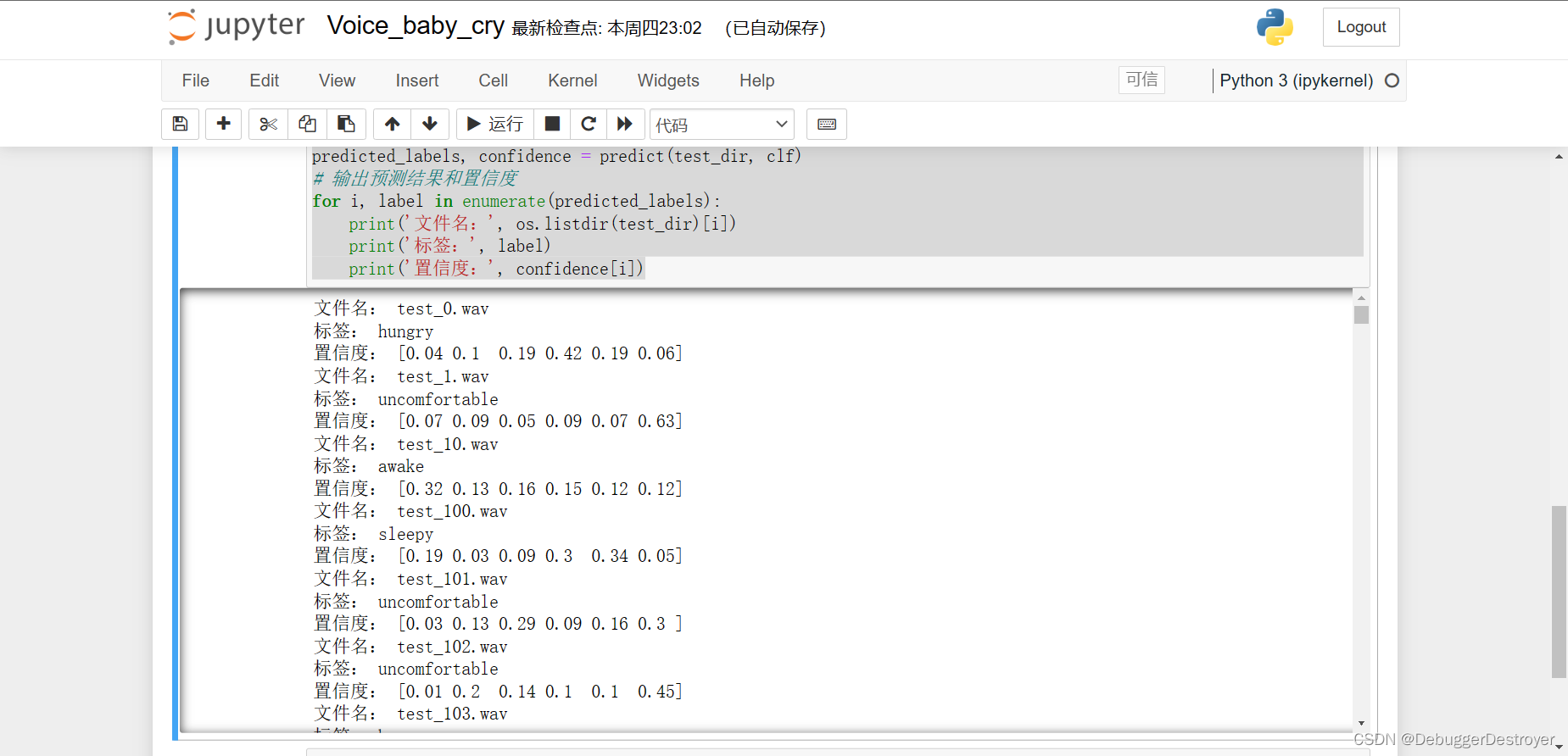
总结
最终的预测结果有些给出了很高的置信度,但大部分预测结果中各类标签的置信度是比较接近的。
我个人观点认为,这是因为数据并没有经过预处理,各种参数也没有经过很精确的调整。另一方面婴儿的哭声也确实有点难分辨。
但总的来说也确实是有了输出,在此基础上可以从数据预处理的方向入手提高精确度。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









