







主要特点:
- 基于c/c++开发,主要目标是运行在计算能力比较弱的终端设备:比如说各类arm v7/v8/v9的开发板。甚至弱到主频100MHZ的芯片都可以运行。
- 可运行在windows/linux/macos/android/ios,甚至各类rtos平台上。
- 占用很低的内存(可低到100k以下)和很低的CPU资源。
- 95-98%的准确率。
- 模型可自动升级。
婴儿哭声识别的价值(场景、流程)
婴幼儿时期的哭声不仅是他们表达需求的主要方式,也是健康状况的直接反映。
主要的需求场景是实时哭声监测与报警/反馈机制,比如在婴儿哭闹时及时通知父母和实时安抚措施。
调研显示,对于夜间或短暂离开时的哭声监测需求尤为迫切。
主要产品比如说智能婴儿床,baby monitor等等。

哭声的特点
一段哭声的时域图:
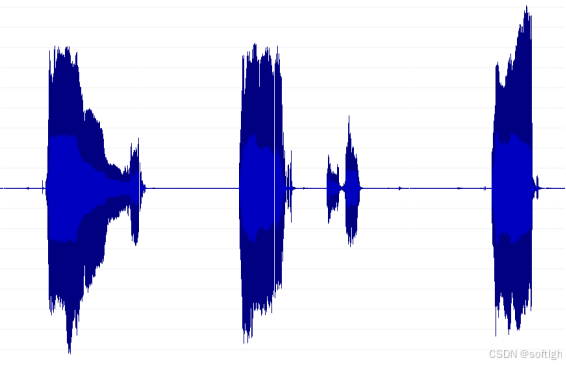
一段典型的哭声频谱如图:
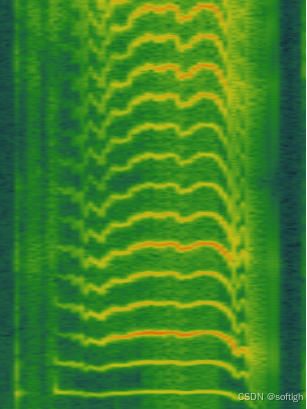
从频谱上看,哭声的特征比较明显,与正常的说话声区别比较大,表现为明显的基频-共振峰的特征,而且呈现一个起落的过程,基频大约在300Hz至500Hz之间,并持续相对比较长的一小段时间。
婴儿哭声的识别方法
婴儿哭声的识别过程主要包括:哭声音频信号进行预处理、特征提取和算法识别等步骤,构建高效、准确的哭声识别模型。模型特征主要包括时域、频域特征。
音频信号预处理
音频信号预处理主要包括噪声抑制、信号增强、端点检测等步骤。以噪声抑制为例,考虑到实际应用场景中可能存在的复杂环境噪声,如家庭环境中的电视声、谈话声,或是公共场所的嘈杂声,所以采用了基于自适应降噪的噪声抑制算法。该算法能有效抑制噪声,提高信噪比。实验数据显示,在典型家庭环境噪声下,该算法能将信噪比提升约5-10dB,显著改善了哭声识别的准确性。
另外数据预处理还包括使用数据增强技术,如音频变速、加噪等,增加模型的泛化能力。
特征提取
从上面哭声的时域来说,特征相对不明显。而我们主要从频域提取数据特征,频谱图反映了哭声在不同频率上的能量分布情况。对哭声进行傅里叶变换从时域转换到频域,进而提取出频谱特征。
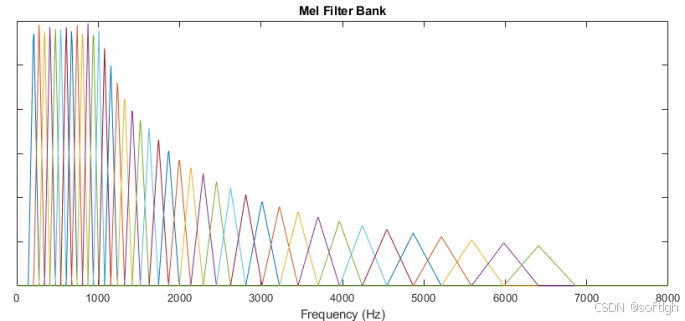
提取mel谱,这是因为人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。Mel频率分析就是基于人类听觉感知实验得出的:
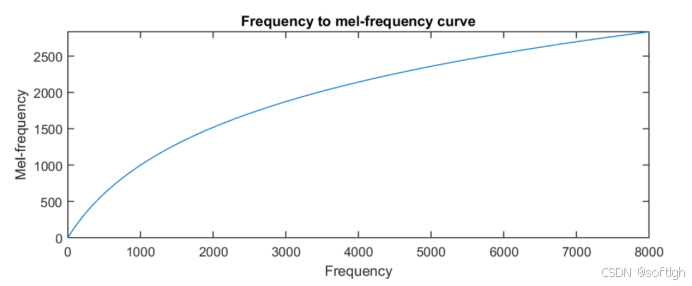
低频区域有很多的滤波器,他们分布比较密集,但在高频区域,滤波器的数目就变得比较少,分布很稀疏:
在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC。如果是CNN等深度模型则不需要做倒谱分析,使用FBank就能使得深度模型能充分学习到数据的细节;如果是传统机器学习模型则可以取倒谱系数MFCC。
其它特征还可以包括时频参数zcr, energy, energy_entropy, chroma1-12等等,以及这些特征的delta, delta-delta。
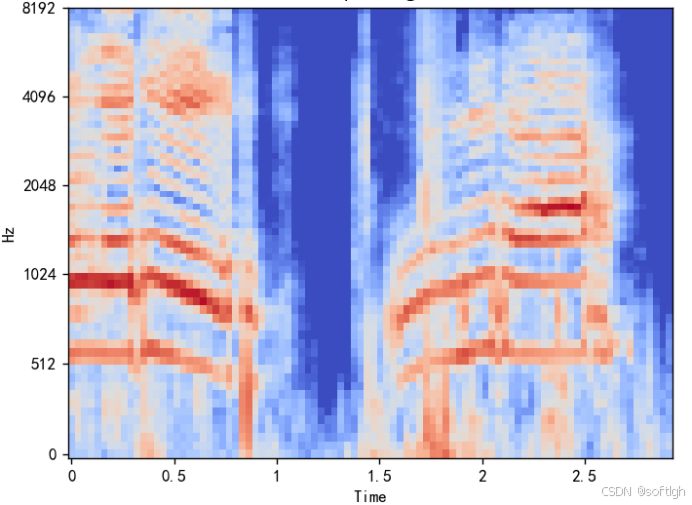
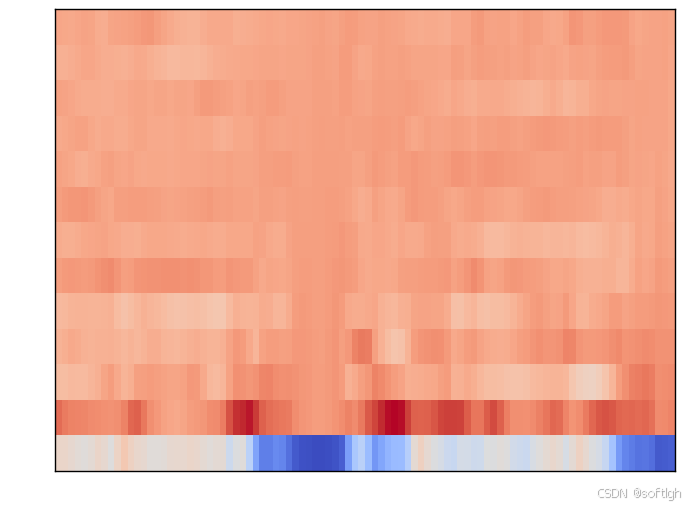
同一段语音的频谱图,mel频谱图和MFCC:
频谱图:
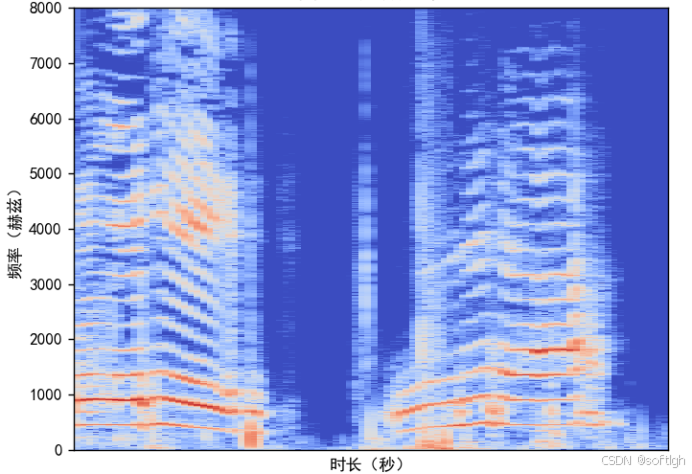
Mel频谱图:
MFCC:
算法
哭声识别的主要算法包括支持向量机(SVM)、随机森林(Random Forest)、DNN神经网络以及深度卷积神经网络(CNN),而时序模型RNN和LSTM也可以用于与CNN结合来提取哭声中的时序模式。
支持向量机(SVM)以其在小样本、高维数据及非线性分类中的良好表现著称,适用于哭声特征较为明确且数据集规模适中的情况。然而,SVM在处理大规模数据集时可能面临计算效率的挑战。相比之下,随机森林(Random Forest)通过构建多个决策树并集成其预测结果,展现出强大的抗过拟合能力和稳定性,尤其适合处理包含噪声和复杂交互作用的哭声数据。而卷积神经网络(CNN)擅长捕捉音频信号中的局部特征,如频率、振幅等,通过卷积层、池化层的堆叠,能够自动提取并学习哭声的高级特征表示。
通过各种模型的对比实验,我们发现结合CNN和LSTM的混合模型在保持高准确率的同时,也具备较好的实时性,能够满足系统需求。此外,还借鉴了行业内的最佳实践,如利用迁移学习技术,在预训练的模型基础上进行微调,以加速模型收敛并提升识别效果。
同时也使用了集成学习的方法,将多个机器学习算法(如支持向量机SVM、随机森林RF和深度学习模型CNN)进行融合,通过投票或加权平均的方式得出最终识别结果。这种策略不仅提高了识别准确率,还增强了模型的鲁棒性。
另外程序还引入了实时反馈机制,通过用户反馈不断优化模型参数和算法逻辑。
哭声识别的难点
哭声信号的复杂性和多样性是首要难题。婴儿哭声不仅不同的个体频率和模式不同,同一个体在不同年龄、健康状况、情绪状态等情况下也会有很大变化,这使得哭声特征参数的提取与识别变得尤为复杂。
复杂环境下的噪声干扰是制约识别准确率的关键因素之一。家庭环境中常见的背景噪声,如电视声、谈话声、厨房烹饪声等都对识别有很大的影响。在嘈杂环境中,哭声识别的误报率可高达30%以上,这直接影响了用户体验。为解决这一问题,我们引入了先进的自适应噪声消除技术,自适应噪声消除算法通过实时估计并消除背景噪声,提高信噪比,从而增强哭声信号的清晰度。通过大量样本训练,使系统能在不同噪声背景下准确识别哭声,有效降低了误报率至5%以下。
另外就是婴儿的哭声与笑声的相似性,与猫叫声的相似性也是识别难点之一。
准确性
测试结果显示,程序在识别准确率上达到了95%以上,且在不同场景下的表现均较为稳定。
运行平台
本程序可以运行在windows平台(所有windows系统), linux平台, mipsel平台, arm平台, iphone平台, android平台,全部都有SDK,后面的附件中有各个平台的库,你自己可以选择下载
性能及硬件要求
CPU要求:主频100MHZ以上。
内存要求:50k-100k。
代码及示例
定义:
#ifndef SPEECH_RECOGNIZER_H
#define SPEECH_RECOGNIZER_H
#ifdef __cplusplus
extern "C" {
#endif
typedef enum SR_RECOGNIZE_MODE_ {
SR_RECOGNIZE_VAD = 1, //速度快的vad
SR_RECOGNIZE_VAD2 = 2, //比较敏感的vad
SR_RECOGNIZE_WAKEUP = 4, //唤醒
SR_RECOGNIZE_KEYWORD = 8, //离线词识别
SR_RECOGNIZE_BREAK = 16, //打断
SR_RECOGNIZE_NS_MONO1 = 256, //降噪1
SR_RECOGNIZE_NS_MONO2 = 512, //降噪2
SR_RECOGNIZE_CRY_DETECT = 2048, //哭声检测
SR_RECOGNIZE_CRY_DETECT2 = 4096, //哭声检测
SR_RECOGNIZE_FINAL = 0x40000000
} SR_RECOGNIZE_MODE;
typedef enum sr_bool_ {sr_false = 0, sr_true = 1} sr_bool;
typedef enum SR_VAD_STATUS_ {SR_VAD_STATUS_SILENCE = 0, SR_VAD_STATUS_MAYBE = 1, SR_VAD_STATUS_ACTIVITY = 2} SR_VAD_STATUS;
//_voicePos是指送入数据(字节)的位置
typedef void (*sr_pVADListener)(void *_listener, SR_VAD_STATUS _vadStatus, long long _voicePos);
typedef void (*sr_pVAD2Listener)(void *_listener, long long _voicePos, char *_data, int _dataLen);
typedef void (*sr_pVAD3Start)(void *_listener, long long _pos);
typedef void (*sr_pVAD3Data)(void *_listener, long long _pos, char *_data, int _len);
typedef void (*sr_pVAD3End)(void *_listener, long long _pos);
typedef void (*sr_pWakeUpListener)(void *_listener, long long _voiceStartPos, long long _voiceEndPos, float _confidence);
typedef void (*sr_pKeywordListener)(void *_listener, int _keyword, const char *_keywordStr, long long _voiceStartPos, long long _voiceEndPos, float _confidence);
typedef void (*sr_pTimeOut)(void *_listener);
typedef void (*sr_pData)(void *_listener, char *_data, int _len);
typedef void (*sr_pCryDetectListener)(void *_listener, long long _voicePos, float _confidence);
//创建识别器
void *sr_createRecognizer(int _mode);
void *sr_createRecognizer2(int _sampleRate, int _mode);
void *sr_createRecognizer3(int _sampleRate, int _mode, int _channel);
//销毁识别器
void sr_destroy(void *_recognizer);
//设置VAD监听器
void sr_setVADListener(void *_recognizer, void *_listener, sr_pVADListener _flistener);
void sr_setVADListener2(void *_recognizer, void *_listener, sr_pVAD2Listener _flistener);
void sr_setVADListener3(void *_recognizer, void *_listener, sr_pVAD3Start _fonVADStart, sr_pVAD3Data _fonVADData, sr_pVAD3End _fonVADEnd);
void sr_setVADMaxGapsilence(void *_recognizer, int _microSeconds);
void sr_setVADMaxStartsilence(void *_recognizer, int _microSeconds);
void sr_setVADMinLen(void *_recognizer, int _microSeconds);
void sr_setVADLevel(void *_recognizer, int _level);
void sr_setKeywordListener(void *_recognizer, void *_listener, sr_pKeywordListener _flistener);
void sr_loadKeywordModel(void *_recognizer, const char *_modelDir, const char *_modelName);
void sr_setNSMonoListener(void *_recognizer, void *_listener, sr_pData _flistener);
void sr_setNSMonoLevel(void *_recognizer, int _level);
void sr_loadCryDetectModel(void *_recognizer, const char *_modelDir, const char *_modelName);
void sr_setCryDetectListener(void *_recognizer, void *_listener, sr_pCryDetectListener _flistener);
void sr_setCryThresh(void *_recognizer, float _cryTime);
void sr_setFinalDataListener(void *_recognizer, void *_listener, sr_pData _flistener);
void sr_setTimeOutListener(void *_recognizer, int _msTime, void *_listener, sr_pTimeOut _fonTimeOut);
//开始识别
//这里一般是线程,这个函数在停止识别之前不会返回
void sr_run(void *_recognizer);
//识别一小段时间,该函数处理片断时刻后返回
sr_bool sr_runOnce(void *_recognizer);
//暂停信号分析
void sr_pause(void *_recognizer, sr_bool _isPause);
//void sr_reset(void *_recognizer);
//停止识别,该函数调用后sr_run会返回
//该函数只是向识别线程发出退出信号,判断识别器是否真正已经退出要使用以下的sr_isStopped函数
void sr_stop(void *_recognizer);
//判断识别器线程是否已经退出
sr_bool sr_isStopped(void *_recognizer);
//要求输入数据单声道,16bits采样精度,小端编码的音频数据
int sr_writeData(void *_recognizer, char *_data, int _dataLen);
int sr_writePlayData(void *_recognizer, char *_data, int _dataLen);
int sr_getVer();
#ifdef __cplusplus
}
#endif
#endif使用:
#include <stdio.h>
#include <stdlib.h>
#include "speechRecog.h"
#ifdef WIN32
#include <Windows.h>
#include <process.h>
#else
#include<pthread.h>
#include <unistd.h>
#endif
#ifdef WIN32
#define mysleep Sleep
#else
#define mysleep(_ms) usleep(_ms * 1000)
#endif
void myCryDetected_Em(void *_listener, long long _voicePos, float _confidence)
{
printf("-----------------cry detected(%f)------------\n", _confidence);
};
int main(int argc, char* argv[])
{
void *recognizer = NULL;
char *buf[512];
recognizer = sr_createRecognizer2(SAMPLE_RATE,
SR_RECOGNIZE_CRY_DETECT2
//| SR_RECOGNIZE_VAD
);
//sr_loadCryDetectModel(recognizer, "./crydetect", "crydetect");
sr_setCryDetectListener(recognizer, NULL, myCryDetected_Em);
while(true)
{
//这里假定录音数据不断在写到buf中
//...
//把语音数据写到识别器
sr_writeData(recognizer, buf, sizeof(buf));
//执行一帧的识别
while (sr_runOnce(recognizer));
}
sr_stop(recognizer);
while (sr_runOnce(recognizer));
while (!sr_isStopped(recognizer))mysleep(1);//让异步线程执行完
sr_destroy(recognizer);
return 0;
}作者: 夜行侠 微信号:softlgh, QQ:3116009971, 邮件:3116009971@qq.com
婴儿哭声库及demo源码下载:babyCry.zip
其它声音处理方面程序:
声波通讯:
android/iphone/windows/linux/微信声波通讯库
Android/iphone/微信手机通过声波初始化智能设备的WIFI信息
鼾声识别:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









