







随着AI技术的发展,人工智能已在各行业中不断被应用。
正常新生儿一天至少哭3小时,但不同的哭声代表不同涵义,一般家长可能听不出来。
对婴儿来说,哭声是一种通讯的方式,一个非常有限的,但类似成年人进行交流的方式。它也是一种生物报警器,向外界传达着婴儿生理和心理的需求。基于啼哭声声波携带的信息,婴儿的身体状况才能被确定,疾病才能被检测出来。因此,有效辨识啼哭声,成功地将婴儿啼哭声“翻译”成“成人语言”,让我们能够读懂啼哭声的含义,有重大的实际意义。
数据集一共6类
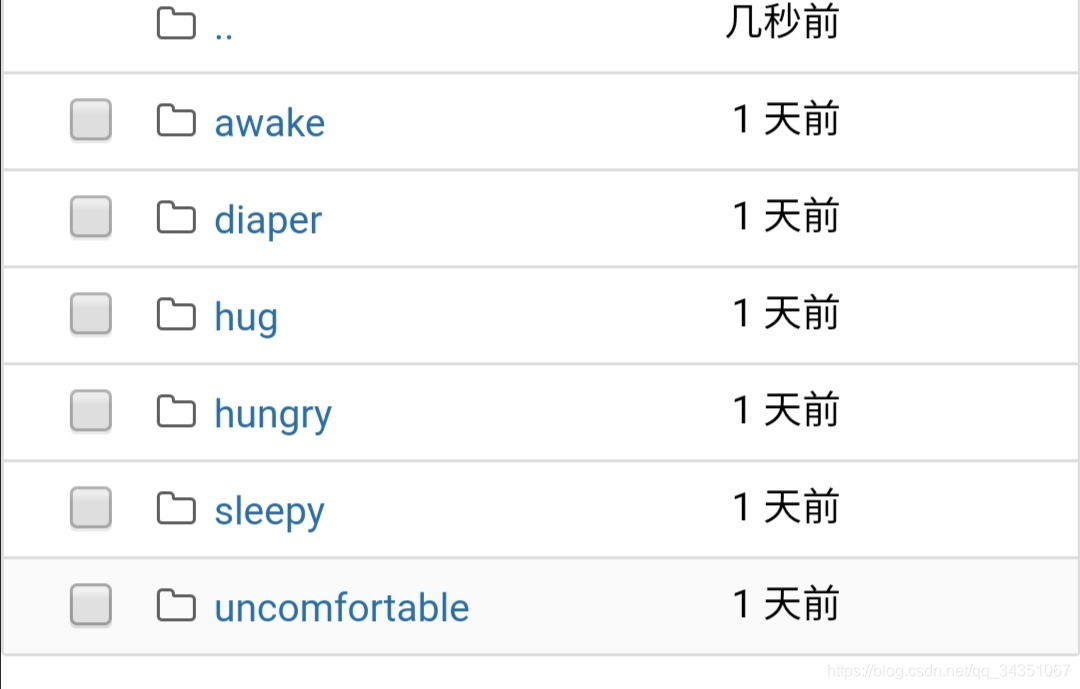
每类随机抽取13个样本做为测试集总共73。
安装环境
!pip install matplotlib
!pip install soundfile
!pip install librosa
!pip install torchlibrosa
!conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
!apt-get update
!apt-get install libsndfile1
环境可以直接使用配置好的免费云gpu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











