







机器学习21_决策树(decision tree)逻辑回归树(regression tree)详解(2021.09.02)
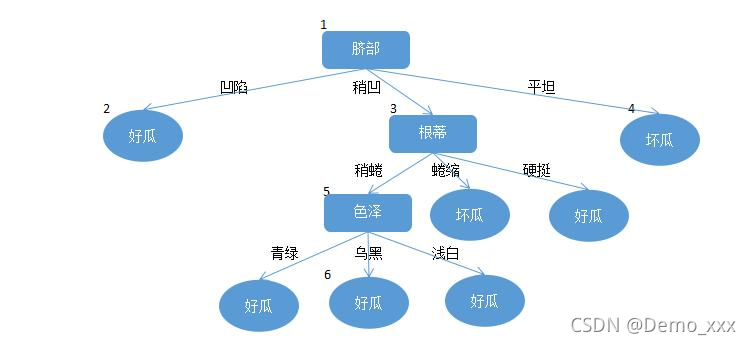
一. 究极总结
决策树:一个定义在特征空间与类空间上的条件概率分布。
逻辑回归树:解决逻辑回归问题的决策树。
二. 知识储备
- 什么是熵?
一种事物的不确定性就叫做熵。比如我想买一颗西瓜,该挑哪一颗我不知道,我很不确定,这种感觉就被称作为熵。用数学的角度来解释就是:熵是描述系统状态的函数,也就是用来计算系统的混乱程度。 - 什么是信息?
信息就是可以用来消除不确定的事物。其作用就是:调整概率、排除干扰、确定情况。比如当我买西瓜的时候,我看了看西瓜的颜色、敲了敲西瓜听声,就能够获取一些有关这颗西瓜的信息,从而便于让我判断这颗西瓜的好坏。 - 什么是噪音?
噪音就是指那些不能消除某人对某件事情不确定性的事物。比如我在买西瓜的时候,瓜农的名字叫王婆,她一直在吹嘘她的每一颗瓜都是又沙又甜,听了她的屁话,我在选择西瓜的时候就会受到一定的干扰。 - 熵如何去量化?
一般情况下,可以将一个事情分为两种情况:等概率均匀分布(比如你投一枚硬币),以及,概率不相等分布(判断一个生物的种类)。因此根据不同的概率分布情况,熵量化的方法也有所不同。
(1) 等概率均匀分布:以抛硬币实验为例,抛硬币的结果除了是正面就是反面,而且两个面出现的概率是相等的。当硬币为1枚的时候有:正、反两个结果;当硬币为2枚的时候有:正正、正反、反正、反反四种结果;当硬币有3枚就有八种结果;n枚就有2^n个结果。在这个游戏中会让你蒙的就是结果到底是啥?而会直接影响结果是啥的其实就是硬币的个数,因此在这个实验中熵的计算方法就是:
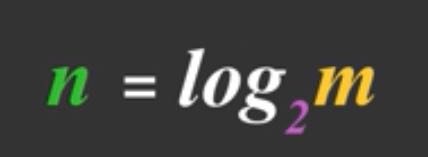
其中m就是该事件中可能结果的个数,而n就是该事件的熵。以抛三枚硬币的事件为例,量化后的熵的结果为:log2^8 = 3
(2) 概率分布不相等的情况:举一个例子,比如有一个不知道种类的生物,它被看作是狗的概率是1/2,看作猫的概率是1/3,看作羊的概率是1/6,在对熵进行量化时的计算方法就是:

- 信息如何量化?(信息增益的计算方法)
举一个例子,通过对信息的熵进行计算从而量化得到的信息:小明要做选择题,在没看提示之前,他不会做这道题。因此对于他来说,选择选项a、b、c、d的概率都是一样的。后来小明的老师给了小明一定的提示,让小明对选择有了改变:a:1/6, b:1/6,c:1/2,d:1/6 。通过计算熵来感受一下,信息不同所导致的结果吧:
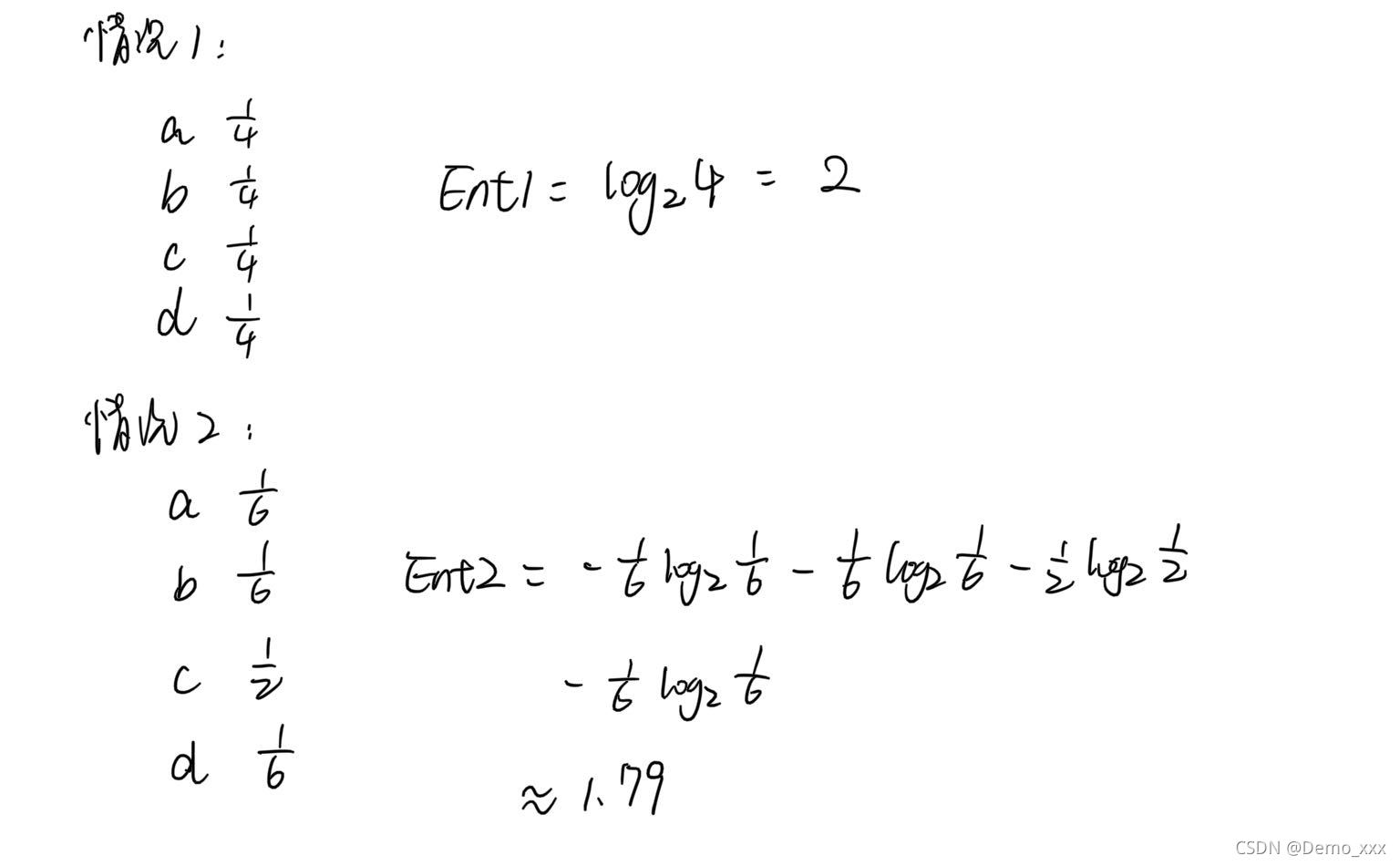
从而发现,在得到一定的有用的信息后,熵的值是变小了的,换句话说就是事件的复杂性变少了,也就是懵逼的程度减轻了。而具体老师给小明提供的信息量,其实就可以通过两次计算的熵值相减而得出(信息增益):Gain = Ent1 - Ent2 = 2 - 1.79 = 0.21 。通过这样的手段也就完成了对信息的量化。 - 如何计算信息增益率?
在获取了信息增益后,仍面临着一个问题,如果一个属性具有很多个或者很少个分支,比如在判断西瓜的好坏的时候,有一个属性是色泽,色泽这个属性就有:黑色、青色、黑青色、白色等好几种分支,相比于其他属性,分枝的数量是明显更多的,换句话说就是,色泽这个属性在一定程度上因为其本身的性质,有可能导致的信息增益会比实际预期稍微小一些。因此就有了信息增益率这么一个计算方法。

- 什么是基尼值?
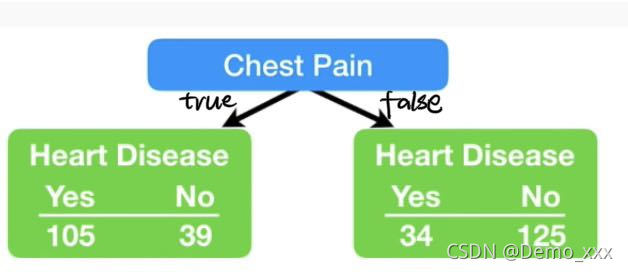
基尼值Gini(D)用于表示一组数据的纯度。表示在数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(D)越小,则数据集D的纯度就越高。举一个例子:有一组有关心脏病的决策树数据,其中有一条属性是胸闷,根据有没有胸闷的状况,再区分为有无心脏病的情况,具体决策树的表示如下图所示:

- 什么是基尼指数?
在计算完基尼值之后,就可以通过基尼值来计算出基尼指数了。
基尼指数(基尼不纯度)= 样本被分错的概率 * 样本被选中的概率

三. 逻辑回归树(Regression Tree)
- 为什么要有逻辑回归树?
一般情况下,决策树常常被用作处理分类任务,但实际生活中并不是所有的事情都只是非黑即白的,因此就有了为了处理回归型任务的回归树。但是在遇到的回归问题的时候,又可以将回归问题分类为:线性回归和非线性回归,对于线性回归问题,通常我们可以通过对数据的分析而拟合出一个回归方程(直线)从而完成对未知结果的数据进行回归预测;但是对于非线性的数据,就需要用到逻辑回归树(Regression Tree)了。
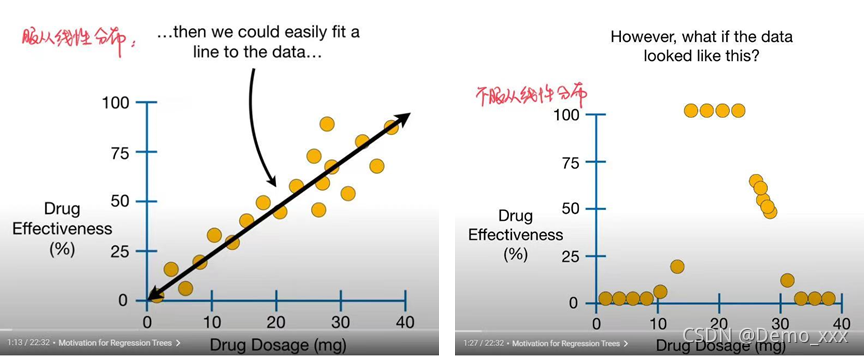
- 如何根据数据集生成逻辑回归树?
使用的数据集:根据疫苗注射量反应疫苗的生效程度

生成逻辑回归树的步骤如下所示:
(1)根据设置不同的阈值,计算得到最小的残差平方来找到根节点。
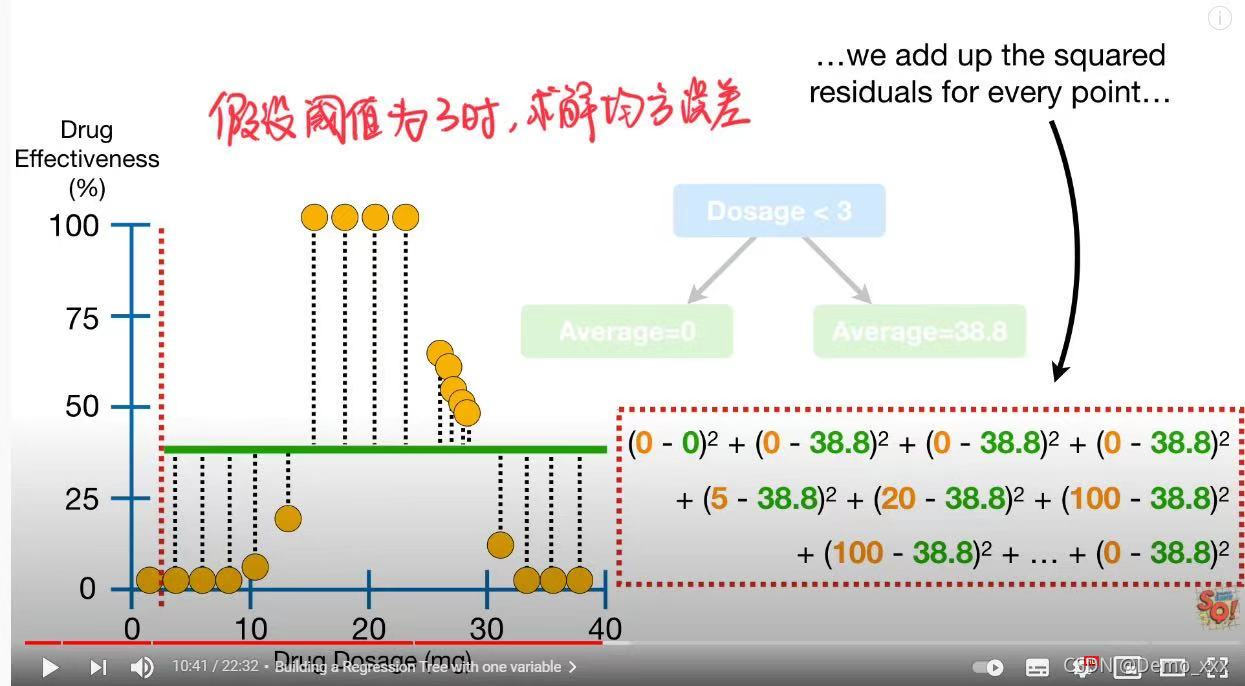
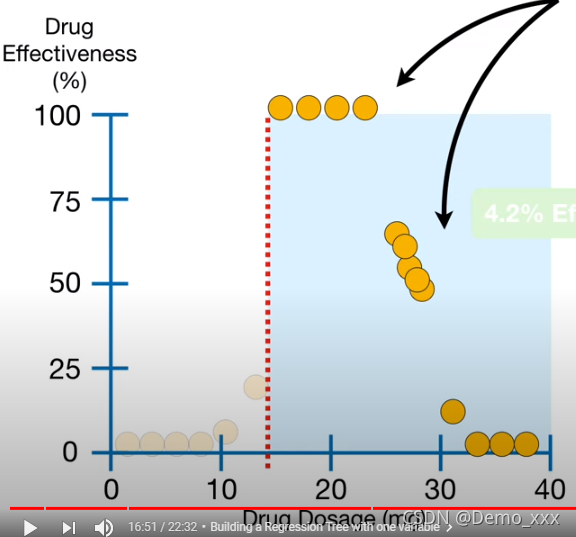
以此类推,分别设置不同的点作为阈值,最终得到一个残差平方的图像
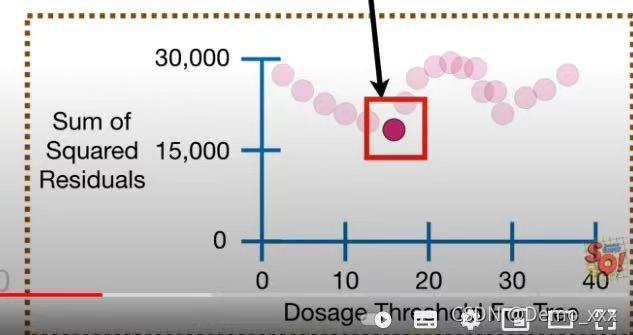
从而选择出了根节点的值为14.5.
(2)根据根节点将所有的数据集划分成两个小的集合,之后对小的集合进行同样的选择阈值,设置节点的操作。首先是注射量少于14.5的部分:
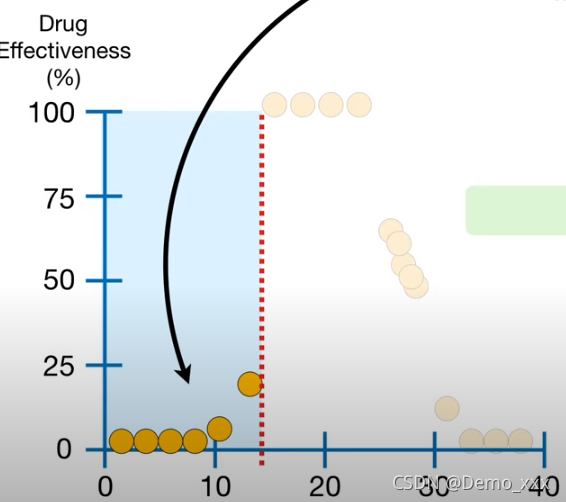
在进行了同样的选择阈值、设置节点的操作之后,生成了如下的树:
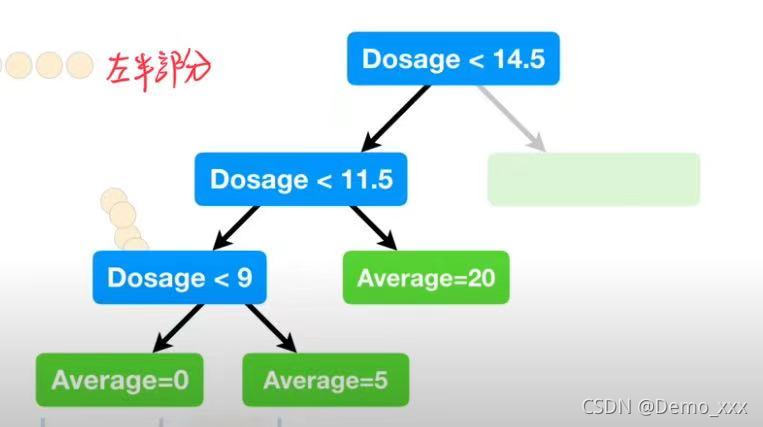
(3)可以看出这棵树可以说是完美的契合了数据集的结果,这不禁会让人想到是否是出现了过拟合的现象!因此,为了防止出现过拟合的状况,通常只有数据量大于20的情况下才进行阈值的划分操作,由于这里的数据量本身就很少,因此将20缩减为7,从而有了新的,算是进行了简化后的树(这一操作通常被称为剪枝操作):
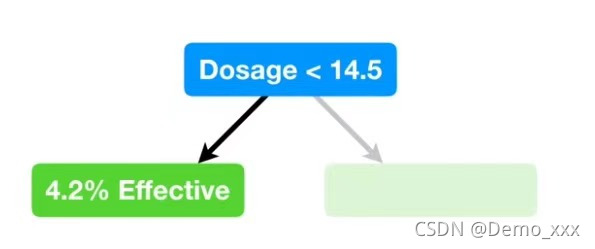
(4)之后就是注射量大于14.5的部分:
与注射量小于14.5的部分处理方法相同:选择阈值、设置节点、解决过拟合,从而得到了整体的逻辑回归树:
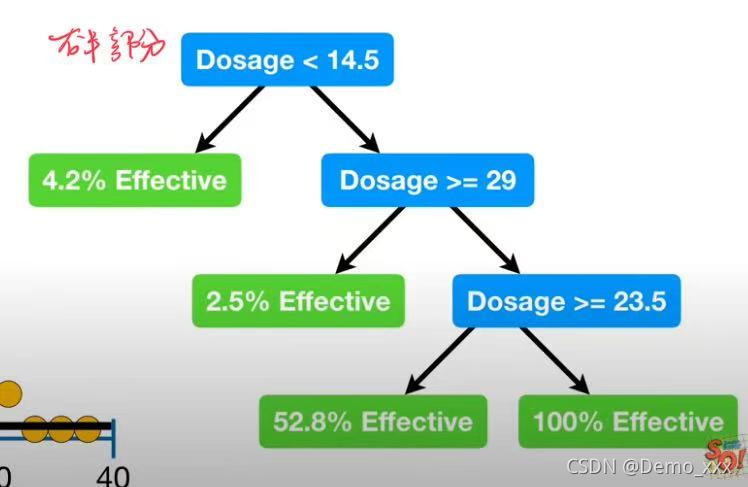
这样就完成了对只有单一属性的数据的逻辑回归任务。但在大多数情况下,数据集所附带的属性并非只有一种,如下就是包含多个属性的有关疫苗生效程度的数据集(注射量、注射者年龄、注射者性别)

针对这样的多属性数据集,想要生成有关它的逻辑回归树,步骤通常有以下几步:
(1)分别假设Dosage、Age、Sex为根节点,计算出每个属性所对应的残差平方有多大,从而选出最小的作为最终树的根节点。
Dosage:
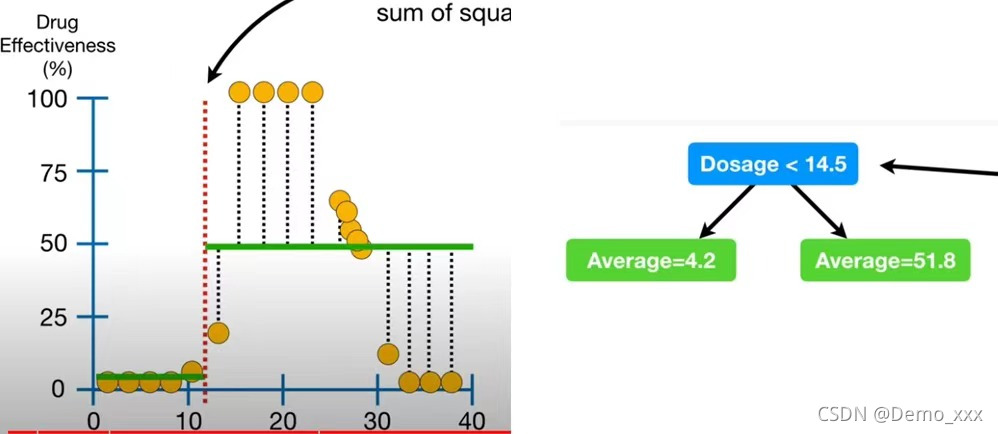
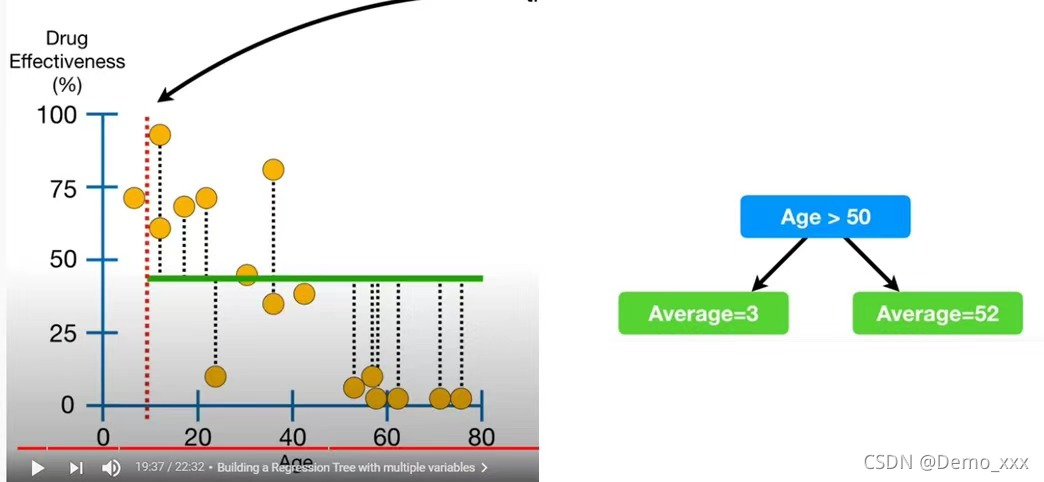
Age:
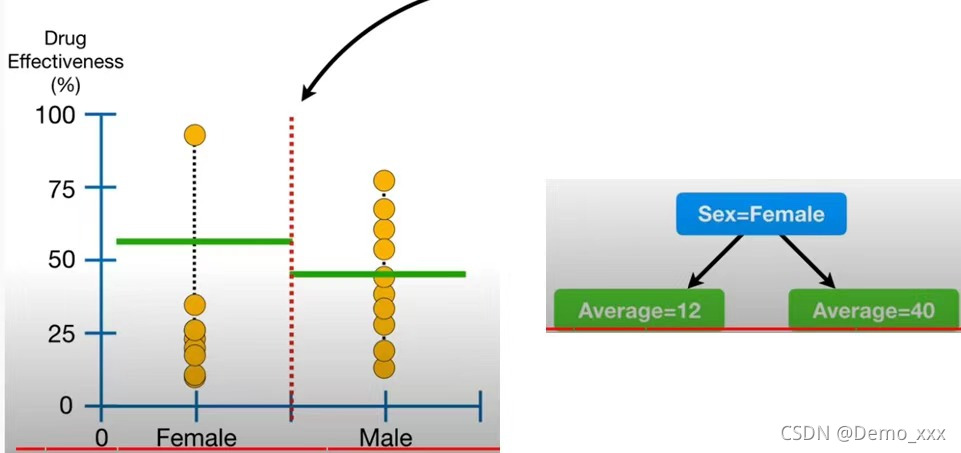
Sex:
残差平方:

从残差平方的大小可以看出,由于Age属性的残差平方最小,因此,可以选择它作为最终树的根节点。
(2)之后根据树的根节点,将数据划分成Age>50和Age<50的两组,之后对每一组再次进行依照Dosage、Age、Sex属性的残差平方计算,依次往复,最终形成最终的树。(注:为了防止过拟合,始终按照小于6个数据就不进行划分的规则)从而生成了最终的逻辑回归树:
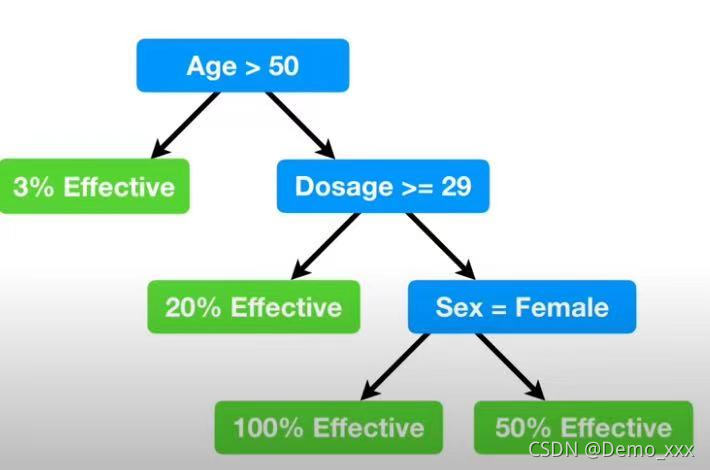
四. 感悟与分享
- 决策树优点:
算法简单,容易理解。
不用对数据进行归一化处理。
可用于小数据集。
时间复杂度较小。
可以处理多分类任务。
对缺失值不敏感。
是集成算法的基础。 - 决策树的缺点:
容易出现过拟合。
处理特征相关性较强的数据效果不是很好。
连续性字段难以预测。
类别太多时,错误可能增加得比较快。 - 有关逻辑回归树的教程:https://www.youtube.com/watch?v=g9c66TUylZ4&t=532s (内容为英文,且需要科学上网)
如有问题,敬请指正。欢迎转载,但请注明出处。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









