







前言
如今,DeepSeek的大语言模型凭借其出色的表现火爆全球。但是,在面对一些高隐私性数据的时候,我们不希望将这些内容用于训练。此时,在本地部署模型就成为了我们的首选方案,而且本地部署高度定制化的能力可以帮助我们适应更加个性化的场景。
我们本地部署的模型是官方模型的“蒸馏模型”,在这里就不多赘述相关的学术名词了,直接把模型性能的结果展示给大家。
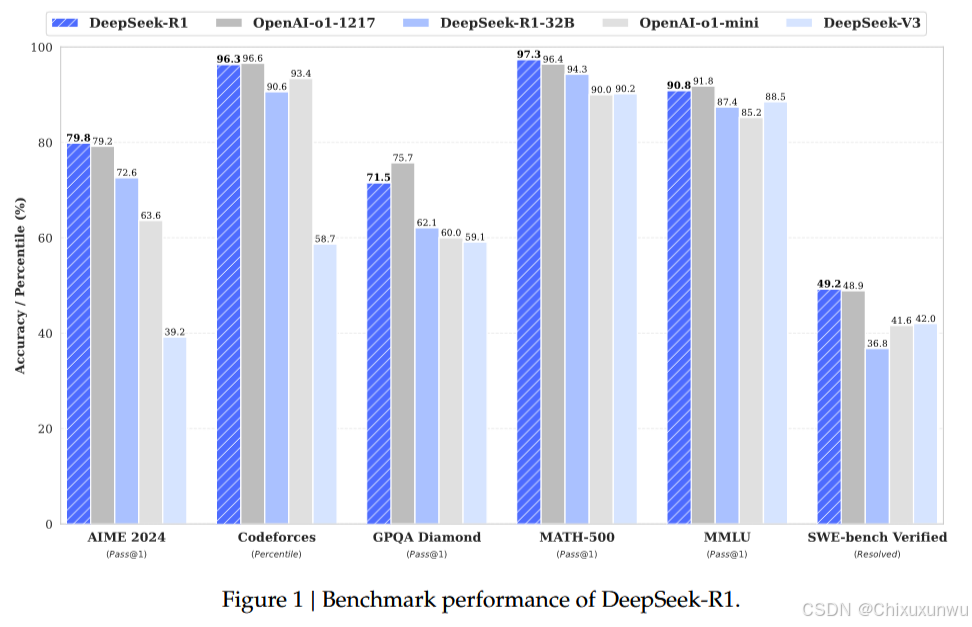
这张图片来源于官方发表的一篇学术论文,链接在此:https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
我们所选用本地部署的模型,就是诸如DeepSeek-R1-32B这样的模型,也就是蒸馏模型。从柱状图中显而易见,这个模型的性能已经非常媲美我们网页上所使用的DeepSeek-R1这个模型了。在电脑性能允许的前提下,通过合理的参数设置,可以实现本地不联网就能舒适流畅地使用。
值得注意的是,本教程只适用于NVIDIA显卡(N卡)的用户,AMD显卡(A卡)没有CUDA可能需要别的方式才能本地部署。
本文涉及的资料都将会在文章末尾的网盘链接中给出
一、安装LM Studio
这个软件的主要用途就是让我们在本地使用LLM(大语言模型),大家可以自行前往官网进行下载
官网链接:LM Studio - Discover, download, and run local LLMs
二、给LM Studio断网
在将该软件安装到你需要的地方后,和前言中讲的一样,为了不让我们的隐私被泄露,我们需要给LM Studio断网。
有的人可能会说:“那我在用这个软件的时候拔网线不就行了,要这么麻烦干嘛?”。结果是一样的,但是从防火墙层面给LM Studio断网是一个更为“一劳永逸”的方式。
1. 给第一个程序断网
首先,我们在windows的开始菜单中搜索防火墙,点击打开
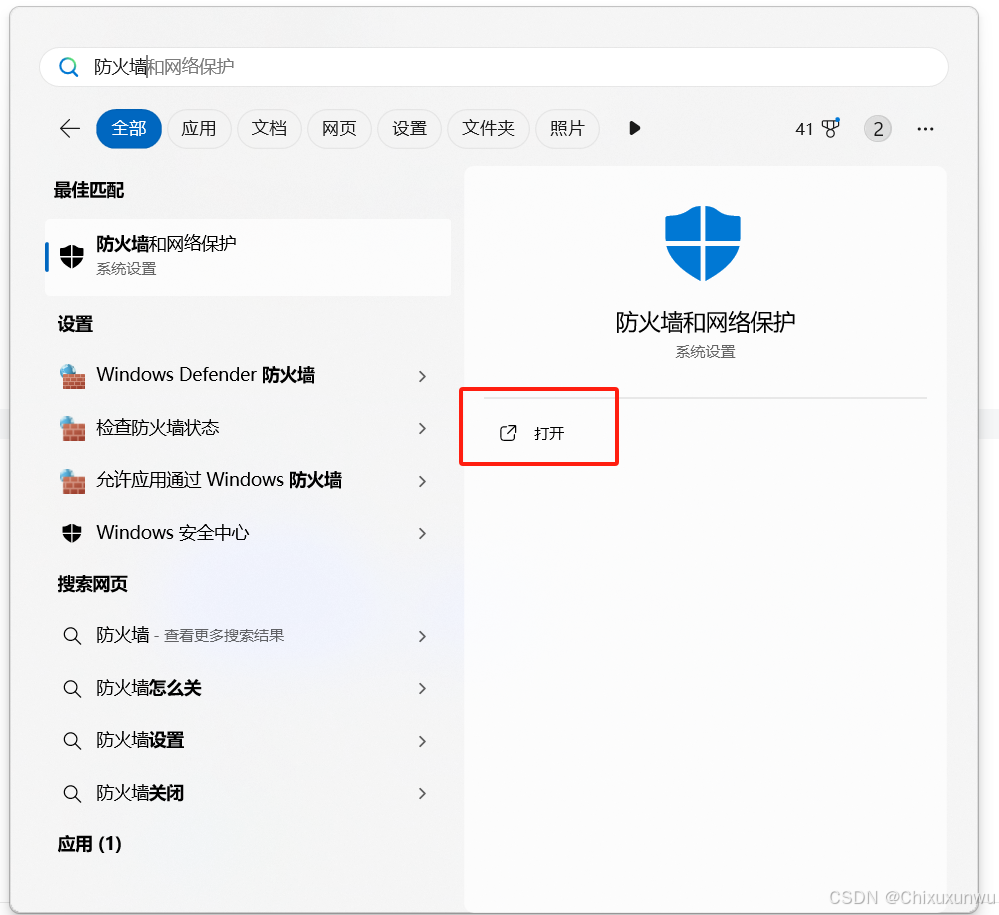
点击如图的高级设置

点击“入站规则”页面后,再点击右侧的“新建规则”
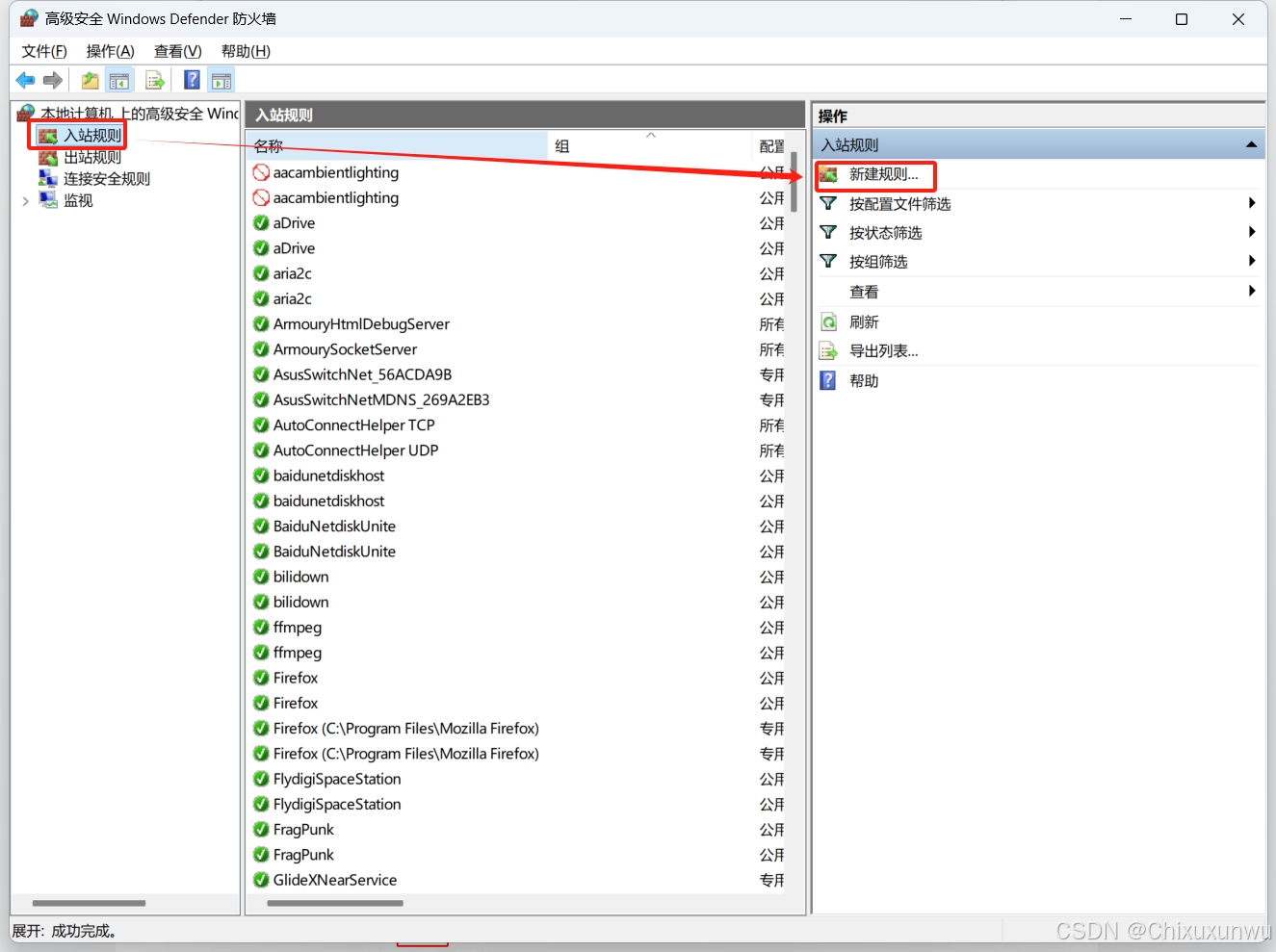
我们一共要禁用三个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 976
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









