







项目介绍
在房地产大热的时代,很多人倾尽一生的财富来获取一套房子,很多时候客户会根据地理位置去选取某一小区来购置房产,那么在特定的地理位置上,什么样的房型是最热门的,什么样的房子才是具有性价比的,开发商该怎么去设计户型以及改变户型比例才能获取最好的销量以及最丰厚的利润,本次项目通过爬取知名网站房天下的数据,涵盖房子的单价、朝向、面积、户型等信息。然后使用各种回归算法(随机森林、线性回归、lasso回归、岭回归、梯度提升树)来建立房价预测模型。
一、数据获取
数据的获取方式主要是使用python里的request库进行网页的爬取,然后使用beautifulsoup对内容进行解析,使用的目标网站是房天下广州市海珠区的部分(https://gz.esf.fang.com/house-a074/),该网站的房子信息包涵户型、建筑面积、单价、朝向、楼层情况和装修情况。注意房天下网站有反爬措施,可以通过设置休眠时间来避开,以及使用库去获取网页会重定向到另一个网页,通过解析网页才可以获得正确的目标地址。
import pandas as pd
import time
import requests as req
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
def get_true_url(old_url):
'''获得正确的url'''
# print(old_url)
r = req.get(url=old_url, headers=headers)
if r'<title>跳转...</title>' in r.text:
soup = BeautifulSoup(r.text, 'lxml')
new_url = soup.find(name='a', attrs={
'class': 'btn-redir'}).attrs['href']
return new_url
return old_url
def getHouseInfo1(url):
info = {
}
soup = BeautifulSoup(req.get(get_true_url(url)).text,"html.parser")
res = soup.select(".tab-cont-right .trl-item1")
#获取户型,建筑面积,单价,朝向,楼层,装修情况
for re in res:
tmp = re.text.strip().split('\n')
name = tmp[-1].strip()
if("朝向" in name):
name = name.strip("进门")
if("楼层" in name):
name = name[0:2]
if("地上层数" in name):
name = "楼层"
if("装修程度" in name):
name = "装修"
info[name] = tmp[0].strip()
#获取小区名称,及总价
xiaoqu = soup.select(".rcont .blue")[0].text
info["小区名字"] = xiaoqu
zongjia = soup.select(".tab-cont-right .trl-item")
info["总价"] = zongjia[0].text
return info
#将爬取一页数据的代码放到方法中
domain = "https://gz.esf.fang.com"
city = "/house-a074/"
def pageFun1(i):
page_url = domain + city +"i3"+ i
print(page_url)
res = req.get(get_true_url(page_url))
soup = BeautifulSoup(res.text,"html.parser")
houses = soup.select(".shop_list dl")
page_info_list = []
#遍历返回的房屋信息
for house in houses:
#加try except异常处理
try:
info = getHouseInfo1(get_true_url(domain+house.select(".clearfix a")[0]['href']))
page_info_list.append(info)
#睡眠0.5秒钟
time.sleep(1)
except Exception as e:
print("---------->",e)
df = pd.DataFrame(page_info_list)
return df
查看数据
df.head()#数据前五行
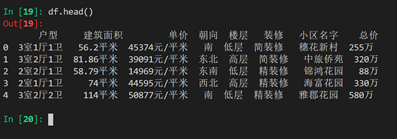
df.shape#获得数据形状

df.to_csv('house_data.csv',encoding='ANSI')#将数据导出成csv文件

二、数据预处理
数据预处理主要市观察是否有缺失值与异常值,对乱序的索引进行整理,以及对数据进行清理,包括转换类型,分解变量,从而能进入模型。
1、缺失值异常值处理
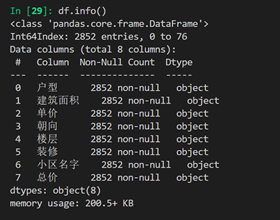
df.info()#首先查看数据大致信息
df.isnull().sum()#观察缺失值

可以了解到数据是没有缺失值的
df.index=range(len(df))#整理索引
df['户型'].value_counts()#查看户型信息

df=df[df['户型']!='暂无']#将户型暂无的样本删除,达到处理缺失值的效果

small_list=[]#定义一个空列表来存放数量较少的户型
features_counts=df['户型'].value_counts()#各户型类别数量
l = len(features_counts.values)
for i in range(l):#循环获取数量较少的户型
if features_counts[i]<10:
small_list.append(features_counts.index[i])
for i in small_list:#循环删除
df=df[df['户型']!=i]

df['户型'].value_counts()

df['朝向'].value_counts()#查看朝向信息
df['装修'].value_counts()#查看装修信息
df['楼层'].value_counts()#查看楼层信息

2、清洗变量
df['建筑面积']=df['建筑面积'].map(lambda x: x.replace('平米','')).astype(float)
df['建筑面积']
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









