







在深入了解XGBoost算法之前,大家可以先了解一下:GBDT回归、GBDT分类、正则化。
1、简介
XGBoost:又叫 eXtreme Gradient Boosting、gradient boosting、multiple additive regression trees、stochastic gradient boosting or gradient boosting machines。
XGBoost 是一种高效、灵活、便携的优化的分布式梯度提升系统。在梯度提升框架下实现了机器学习算法,是一种基于速度和性能的梯度提升决策树的实现。
XGBoost 提供了一种并行树提升(也称为GBDT、GBM),可以快速、准确地解决许多数据科学问题。
它旨在提供一个可扩展、可移植和分布式梯度提升(GBM、GBRT、GBDT)库。它运行在单台机器上,以及分布式处理框架Apache Hadoop、Apache Spark 和 Apache Flink 上。
算法支持的梯度提升形式:梯度提升算法、随机梯度提升(允许行列子采样)、正则化梯度提升(L1、L2正则)
算法特点:算法的实现是为了提高时间和内存资源的效率。设计目标是充分利用可用的资源来训练模型。主要特点有:
- 具有自动处理丢失数据值的稀疏感知实现。
- 块结构支持树结构的并行化
- 继续训练,这样就可以在新的数据上进一步完善一个已经安装好的模型。
算法优点:
- 执行速度:XGBoost 比其他梯度提升方法都快
- 模型的性能:在分类和回归预测建模问题上,XGBoost优于结构化或表格式数据集。证据是,它是众多机器学习竞赛优胜团队的首选算法。
What is the difference between the R gbm (gradient boosting machine) and xgboost (extreme gradient boosting)?
The name xgboost, though, actually refers to the engineering goal to push the limit of computations resources for boosted tree algorithms. Which is the reason why many people use xgboost.(Tianqi Chen,on Quora)
XGBoost成功背后最重要的因素是它在所有场景中的可伸缩性 (scalability in all scenarios)。XGBoost的可伸缩性得益于几个重要的系统和算法优化。这些创新包括:
- 一种新的树学习算法用于处理稀疏数据(sparse data)
- 一个理论上合理的加权分位数草图程序可以在近似树学习中处理实例权值
- 并行计算和分布式计算使学习速度更快,从而能够更快地进行模型探索
- 利用非核心计算(out-of-core computation),使数据科学家能够在桌面上处理数亿个示例
- 将这些技术组合在一起,形成一个端到端系统(end-to-end),可以使用最少的集群资源扩展到更大的数据。
下面通过例子了解该算法。
2、案例讲解
2.1 回归案例
如下图(左)所示,X 轴是药用量,Y轴是药效(7,8,-10,-7),总共有4个训练数据(橙黄色圆圈)。用红圈圈起来的两个观测值药效相对大的正值,说明该药是有帮助的。用黑圈圈起来的两个观测值药效是相对较大的负值,说明该药的危害大于益处。
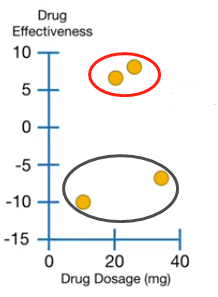

左 右
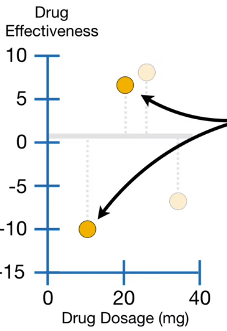
1)用 XGBoost 拟合训练数据确定初始预测
XGBoost 用于回归和分类时,这个初始预测值可以是任何值,默认是 0.5,即 。
第一次迭代:建立第一棵树
2)计算残差
初始预测值如上图(右)所示,粗黑色的水平线。观测值与预测值见得残差 ,上图(右)的黑色虚线说明了药效初始预测值的效果。
像其他 unextreme Gradient Boost,XGBoost 对 进行回归树拟合。但是,不同于 unextreme Gradient Boost 用常规的回归树结构, XGBoost 用一种独特的回归树(unique regressiontree)叫 XGBoost Tree。
3)计算残差的质量分(quality score)或相似分(similarity score)
是正则化参数(Regularization Parameters),用于降低预测对个别观测的敏感性。令
。
构建 XGBoost 回归的方式有多种,这里的是最常见的一种。
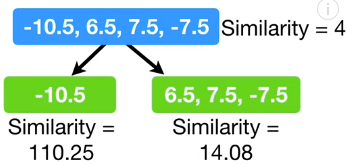
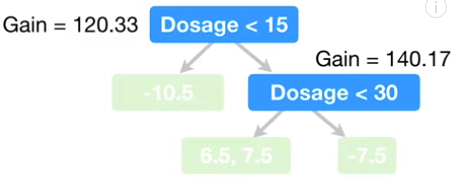
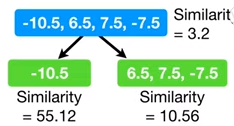
每个树从一个叶节点开始,所有的残差都在该结点。四个观测样本的残差为 -10.5,6.5,7.5,-7.5。
该叶结点的相似得分为:
4) 建树
第一次迭代(建第一分支):
i)选取最佳阈值(第一分支)
a) 选取前两个观测值的药量的均值为阈值
提问:将残差分成两组,对相似的残差进行聚类是否会更好?
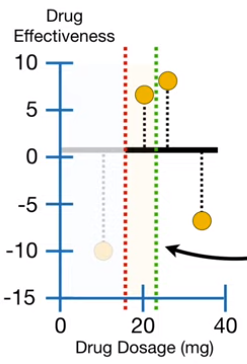
为回答这个问题,首先看低药剂量的两个观测值,如下图所示(左)。这两个观测值得药量平均值为15,即红色的虚线(下图中)。所以将观测值分为两组, 左边只有一个点,其他的点在叶的右边,如下图(右)所示。
左边的相似得分:
右边的相似得分:
由上可以看出,结点的相似得分非常不一样,当残差之间可以互消(两个观测值的残差相加为 )时,相似得分会相对小。当残差相似或只有一个时,残差之间无法互消,相似得分会相对大。
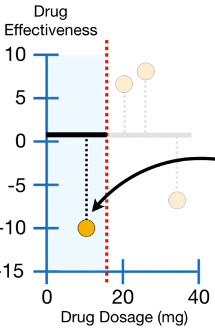
左 中 右
现在需要度量叶结点聚类相似残差比根结点好多少。通过计算两个组残差的增益来比较。
上式是阈值 的增益,可以计算其他阈值的增益进行比较。
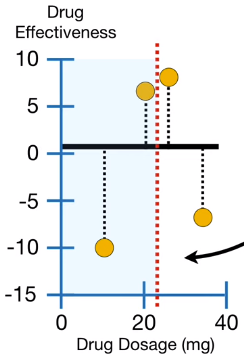
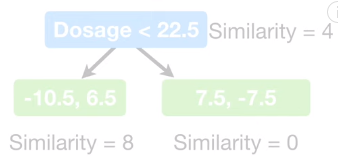
b) 选取中间两个观测值的药量的均值为阈值
将阈值向右移动计算中间两个观测值的药量均值(下图左),均值为 22.5,所以用 建立新的树(下图右)。
因为 (gain=4)的增益小于
(gain=120.33),所以
更适合将残差的相似值聚类。
左 右
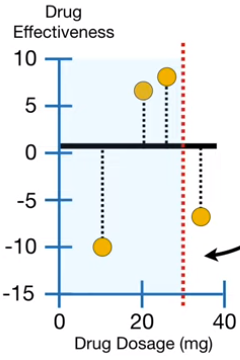
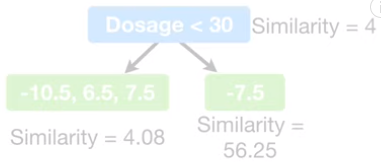
c) 选取后两个观测值的药量的均值为阈值
移动阈值,计算最后两个观测值的药量均值(下图左),均值为 30,所以用 建立新的树(下图右)。
因为 (gain=56.33)的增益小于
(gain=120.33),所以
更适合将残差的相似值聚类。
因为阈值再往右移动已经没有观测值,所以不同阈值的比较结束。
左 右
最终选取 作为第一分支。
第二次迭代(建第二分支):
ii)选取最佳阈值(第二分支)
第一分支如下图(左1)所示,左叶结点只有一个残差,无法进行分割,右结点有3个残差,可以进行分割,因此对右结点进行分割。
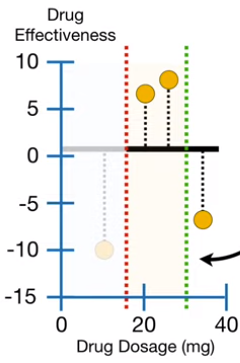
a) 选取右结点前两个观测值的药量的均值为阈值
对右结点的三个观测值进行阈值选取,先选取前两个观测值药量的均值(22.5)作为阈值,如下图(中1)绿色的线所示,红色的线是第一分支的阈值。类似上面的步骤计算不同阈值的叶结点相似度和增益。用 建立新的树(下图右1)

左1 中1 右1

中2 右2
b) 选取右结点后两个观测值的药量的均值为阈值
选取右结点后两个观测值药量的均值(30)作为阈值,如上图(中2)绿色的线所示,红色的线是第一分支的阈值。类似上面的步骤计算不同阈值的叶结点相似度和增益。用 建立新的树(上图右2)
因为 (gain=140.17)的增益大于
(gain=28.17),所以
更适合将残差的相似值聚类。
最终选取 作为第二分支。
本例中限制树的深度为2,因此该树不需要继续向下分割。但是,默认允许树的深度为6。
5)剪枝
XGBoost Tree 的剪枝是基于增益的值。
首先随机选取一个数值,如130。在XGBoost中叫做 。首先从最底的分支计算:
如果 ,则将该分支移除(remove);如果
,则将该分支保留。
对于第二分支 :
,所以保留该分支。
对于第一分支(根结点):
,虽然是负值,但是不会移除。因为最底层的分支没有被移除,所以不会移除根结点。
若 ,则第二分支
是负数,即应该移除该分支;第一分支
是负数,即应该移除根结点。现在只剩下药效初始预测值
,这是相当极端的修剪 。
若 ,
时的相似得分如下图(左)所示,通过与
的相似得分比较会发现,当
时,相似得分会变小,减少的数量与节点中残差的数量成反比。
当 ,
时构建的树的信息增益都大于130,所以不用剪枝。
当 ,
时构建的树的信息增益(第一分支:
,Gain=62.49;第二分支:
,Gain=82.9)都小于130,因此该树全被剪除。
所以当 时,叶结点容易被剪除,因为Gain会变小。
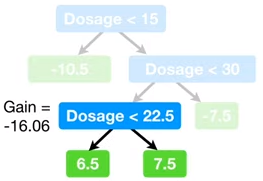
左 右
对于 的最后一个特征,假设
,则得到上图(右)所示结果,即第三分支
的增益为-16.06。当
,
仍为负数,即被移除。因此
阻止了训练数据的过拟合。
6)计算树的输出值
输出值得方程与相似得分的方程类似,但是分子不是残差和的平方。
以下面这棵树(左)为例:

左 右
对于第一个叶结点:
当,即没有正则化:
当:
因此当 时,会减少单个观测值对整体预测的影响,即正则化因子
会减少预测值对单个观测值的敏感性。
对于第二个叶结点:
当:
当:
对于第三个叶结点:
当:
当:
到此为止,第一棵树已经建好(上图右所示)。
7)计算预测值
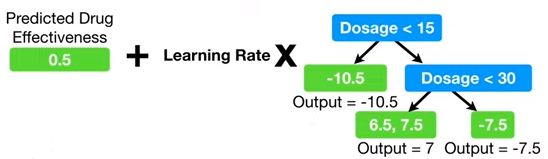
不像 unextreme Gradient Boost, XGBoost的预测从药效初始预测值开始,加上树的输出,按学习率缩放,如下图(左)所示。
左 右
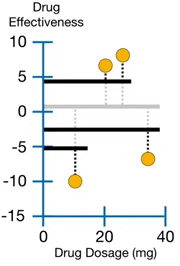
在XGBoost中,学习率(learning rate)叫 ,默认大小为 0.3。四个观测值得药效预测值如上图(右)黑色粗直线所示,新的残差如黑色虚线所示,相比之前的残差(黑色虚线浅色),可以看出新的残差要明显小的多。
第二次迭代:基于新的残差建立第二棵树
22)计算残差......
8)当残差很小或迭代达到最大值时,停止迭代。
2.2 分类案例
由于内容比较多,后面会单独写一帖。
参考:
1、XGBoost: A Scalable Tree Boosting System,Tianqi Chen。
2、StatQuest with Josh Starmer















 3683
3683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









