









CUDA PCL 1.0是基于CUDA开发的点云处理库,目前为止提供了5个库:cluster、octree、ICP、segmentation和filter。本文只实验segmentation库在Robosense激光雷达下的地面分效果。关于雷达的基本信息如下图所示。

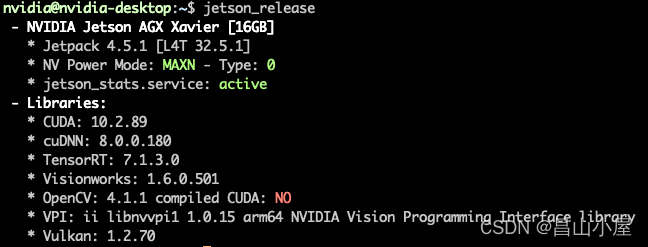
我所用的实验平台是Nvidia Jetson AGX Xavier。
PCL-CUDA 1.0中地面分割目前还只支持SAC_RANSAC + SACMODEL_PLANE方式,也就是RANSAC加地平面方程的形式。从实际应用的角度来说,这种方式剔除点面当然是远远不够的。所以重点只是体验一下PCL-CUDA带来的加速效果。为了方便演示,我将原有的cuda-pcl/cuda-segmentation/main.cpp代码改造成了ros节点,方便订阅点云,完成推理并发布分割后的点云。核心代码如下。
#include <stdlib.h>
#include <iostream>
#include <fstream>
#include <chrono>
#include <pcl/io/pcd_io.h>
#include "cuda_runtime.h"
#include "lib/cudaSegmentation.h"
#include <ros/ros.h>
#include <pcl/point_cloud.h>
#include <sensor_msgs/PointCloud2.h>
#include <pcl_conversions/pcl_conversions.h>
#include <pcl/point_types.h>
#include <boost/foreach.hpp>
#include <boost/filesystem.hpp>
typedef pcl::PointXYZ PointType;
class CudaPclSeg {
private:
ros::NodeHandle nh_;
int modelSize_ = 4;
ros::Publisher pub1_;
ros::Publisher pub2_;
ros::Subscriber sub_;
segParam_t seg_params_;
//cudaStream_t stream_ = nullptr;
//cudaSegmentation *cudaSeg_ = nullptr;
public:
CudaPclSeg():nh_("~") {
Init();
pub1_ = nh_.advertise<sensor_msgs::PointCloud2>("cuda_cloud_seg_ground",1);
pub2_ = nh_.advertise<sensor_msgs::PointCloud2>("cuda_cloud_seg",1);
sub_ = nh_.subscribe<sensor_msgs::PointCloud2>("/rslidar_points", 1, &CudaPclSeg::OnRecvPointCloud2, this);
}
~CudaPclSeg() {
//free(cudaSeg_);
}
void Init() {
seg_params_.distanceThreshold = 0.2;
seg_params_.maxIterations = 100;
seg_params_.probability = 0.99;
seg_params_.optimizeCoefficients = true;
//cudaStreamCreate(&stream_);
//cudaSeg_ = new cudaSegmentation(SACMODEL_PLANE, SAC_RANSAC, stream_);
//cudaSeg_->set(seg_params_);
GetInfo();
}
void ToPublish(const pcl::PointCloud<PointType>& cloud,const pcl::PointCloud<PointType>& cloud2) {
sensor_msgs::PointCloud2 msg_publish;
pcl::toROSMsg(cloud, msg_publish); //usr/include/pcl-1.8/pcl/ros/conversions.h
msg_publish.header.frame_id = "/rslidar";
pub1_.publish(msg_publish);
pcl::toROSMsg(cloud2, msg_publish); //usr/include/pcl-1.8/pcl/ros/conversions.h
msg_publish.header.frame_id = "/rslidar";
pub2_.publish(msg_publish);
}
void GetInfo(void) {
int count = 0;
cudaDeviceProp prop;
cudaGetDeviceCount(&count);
printf("\nGPU has cuda devices: %d\n", count);
for (int i = 0; i < count; ++i) {
cudaGetDeviceProperties(&prop, i);
printf("----device id: %d info----\n", i);
printf(" GPU : %s \n", prop.name);
printf(" Capbility: %d.%d\n", prop.major, prop.minor);
printf(" Global memory: %luMB\n", prop.totalGlobalMem >> 20); //全局内存
printf(" Const memory: %luKB\n", prop.totalConstMem >> 10); //常量内存
printf(" SM in a block: %luKB\n", prop.sharedMemPerBlock >> 10); //每个个线程块(Block)可使用最大共享内存
printf(" warp size: %d\n", prop.warpSize); //warp size in threads
printf(" threads in a block: %d\n", prop.maxThreadsPerBlock); //每个线程块可包含的最大线程数量
printf(" block dim: (%d,%d,%d)\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf(" grid dim: (%d,%d,%d)\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
}
printf("\n");
}
void Inference(pcl::PointCloud<PointType>::Ptr cloud) {
std::chrono::steady_clock::time_point t1 = std::chrono::steady_clock::now();
std::chrono::steady_clock::time_point t2 = std::chrono::steady_clock::now();
std::chrono::duration<double, std::ratio<1, 1000>> time_span =
std::chrono::duration_cast<std::chrono::duration<double, std::ratio<1, 1000>>>(t2 - t1);
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
int nCount = cloud->width * cloud->height;
float *inputData = (float *)cloud->points.data();
float *input = NULL;
//分配旨在供主机或设备代码使用的内存
cudaMallocManaged(&input, sizeof(float) * 4 * nCount, cudaMemAttachHost); //统一内存分配API
cudaStreamAttachMemAsync(stream, input); //将内存与流绑定
cudaStreamSynchronize(stream); //必须的
int *index = NULL;
// index should >= nCount of maximum inputdata,
// index can be used for multi-inputs, be allocated and freed just at beginning and end
cudaMallocManaged(&index, sizeof(int) * nCount, cudaMemAttachHost);
cudaStreamAttachMemAsync(stream, index);
cudaStreamSynchronize(stream);
// modelCoefficients can be used for multi-inputs, be allocated and freed just at beginning and end
float *modelCoefficients = NULL;
cudaMallocManaged(&modelCoefficients, sizeof(float) * modelSize_, cudaMemAttachHost);
cudaStreamAttachMemAsync(stream, modelCoefficients);
cudaStreamSynchronize(stream);
cudaSegmentation cudaSeg(SACMODEL_PLANE, SAC_RANSAC, stream);
std::vector<int> indexV;
t1 = std::chrono::steady_clock::now();
cudaSeg.set(seg_params_);
cudaMemcpyAsync(input, inputData, sizeof(float) * 4 * nCount, cudaMemcpyHostToDevice, stream);
cudaSeg.segment(input, nCount, index, modelCoefficients);
cudaStreamSynchronize(stream);
for(int i = 0; i < nCount; i++) {
if(index[i] == 1) {
indexV.push_back(i);
}
}
t2 = std::chrono::steady_clock::now();
time_span = std::chrono::duration_cast<std::chrono::duration<double, std::ratio<1, 1000>>>(t2 - t1);
std::cout << "-----------" << std::endl;
std::cout << "Input Point Size: " << nCount << std::endl;
std::cout << "CUDA segment by Time: " << time_span.count() << " ms."<< std::endl;
std::cout << "CUDA index Size : " <<indexV.size()<< std::endl;
std::cout << "CUDA modelCoefficients: " << modelCoefficients[0]
<<" "<< modelCoefficients[1]
<<" "<< modelCoefficients[2]
<<" "<< modelCoefficients[3]
<< std::endl;
pcl::PointCloud<PointType>::Ptr cloudDst(new pcl::PointCloud<PointType>);
cloudDst->width = nCount;
cloudDst->height = 1;
cloudDst->points.resize (cloudDst->width * cloudDst->height);
pcl::PointCloud<PointType>::Ptr cloudNew(new pcl::PointCloud<PointType>);
cloudNew->width = nCount;
cloudNew->height = 1;
cloudNew->points.resize (cloudDst->width * cloudDst->height);
int check = 0;
for (std::size_t i = 0; i < nCount; ++i) {
if (index[i] == 1) {
cloudDst->points[i].x = input[i*4+0];
cloudDst->points[i].y = input[i*4+1];
cloudDst->points[i].z = input[i*4+2];
check++;
} else if (index[i] != 1) {
cloudNew->points[i].x = input[i*4+0];
cloudNew->points[i].y = input[i*4+1];
cloudNew->points[i].z = input[i*4+2];
}
}
std::cout << "CUDA find points: " << check << std::endl;
ToPublish(*cloudDst, *cloudNew);
cudaFree(input);
cudaFree(index);
cudaFree(modelCoefficients);
}
void OnRecvPointCloud2(const sensor_msgs::PointCloud2::ConstPtr& cloud_msg) {
pcl::PointCloud<PointType>::Ptr raw_cloud(new pcl::PointCloud<PointType>);
pcl::fromROSMsg(*cloud_msg, *raw_cloud);
Inference(raw_cloud);
}
};
int main(int argc, char **argv) {
ros::init(argc, argv, "cuda_pcl_seg");
CudaPclSeg seg;
ros::spin();
return 0;
}这里并未附加其它绝逼,直接接收点云,使用RANSAC+PLANE完成地面分割,发布点云。在Robosense雷达上的效果如下。其中白色的点为地面点。在当前阈值下,地面并未被完全分割出来。
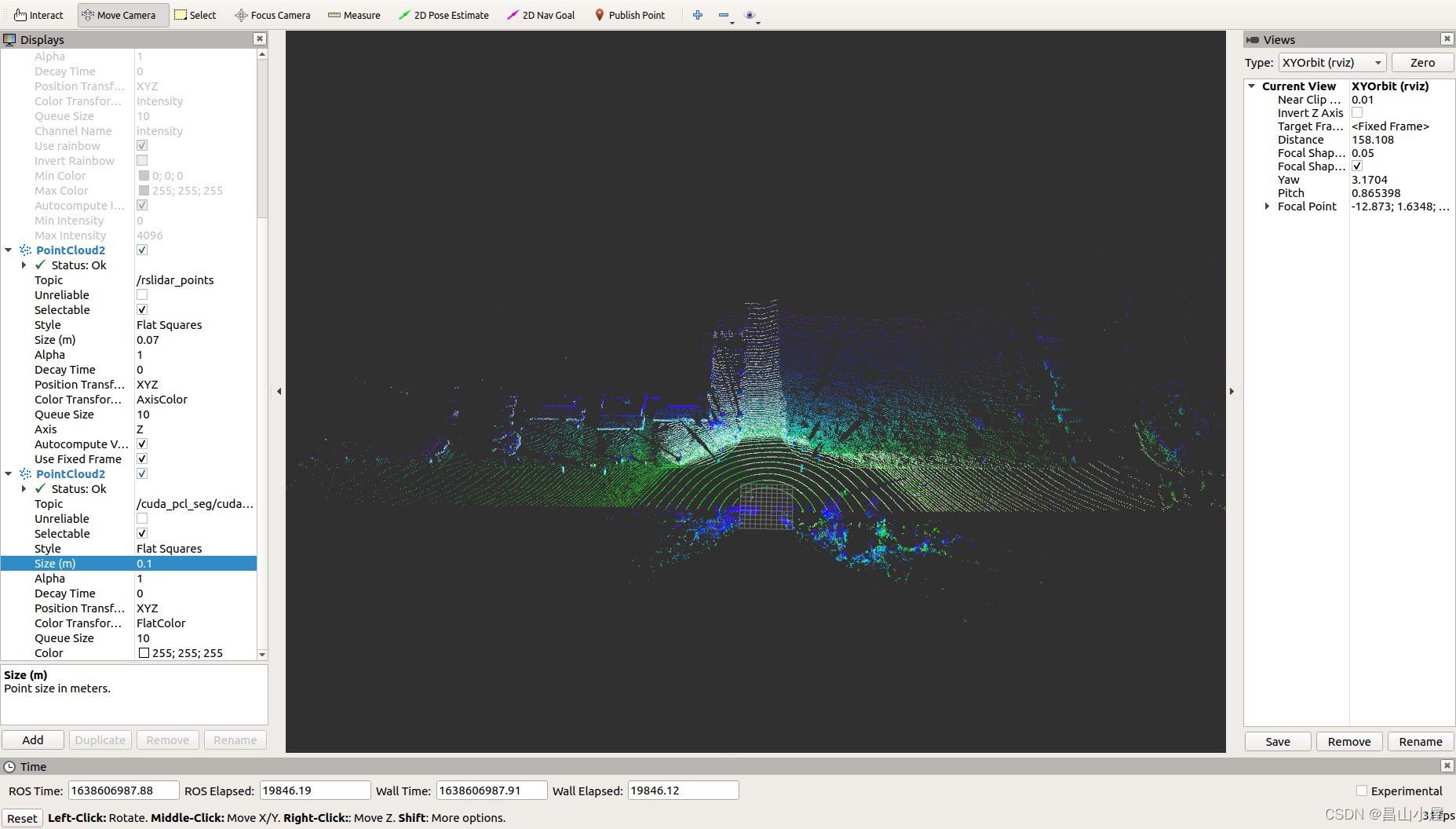
.......
-----------
Input Point Size: 144000
CUDA segment by Time: 37.8987 ms.
CUDA index Size : 15690
CUDA modelCoefficients: -0.0125325 -0.0128293 0.999839 2.19947
CUDA find points: 15690
-----------
Input Point Size: 144000
CUDA segment by Time: 35.1012 ms.
CUDA index Size : 9400
CUDA modelCoefficients: -0.0347887 -0.0161481 0.999264 0.313263
CUDA find points: 9400
-----------
Input Point Size: 131520
CUDA segment by Time: 32.413 ms.
CUDA index Size : 10265
CUDA modelCoefficients: -0.0946108 -0.00978332 0.995466 3.30611
CUDA find points: 10265
-----------
【参考文献】
 https://github.com/NVIDIA-AI-IOT/cuda-pcl.git
https://github.com/NVIDIA-AI-IOT/cuda-pcl.git

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









