






先看一个C递归函数:
uint32_t c_recursion(uint32_t t, uint32_t depth) {
uint32_t res = 0;
if (depth == 0) { //底层返回
res = t;
}else {
res += c_recursion(hash(t * 10086u), depth - 1); //向下传递本层处理过的参数
res += c_recursion(hash(t * 5201314u), depth - 1);
}
return hash(res * 0x47a92fu); //本层返回 合并的、经过本层处理的值
}给定一个初始值,从这个初始值递推分叉出去,最后逐层返回到最上层,在C递归中很简单的函数
在CUDA中实现的思路:
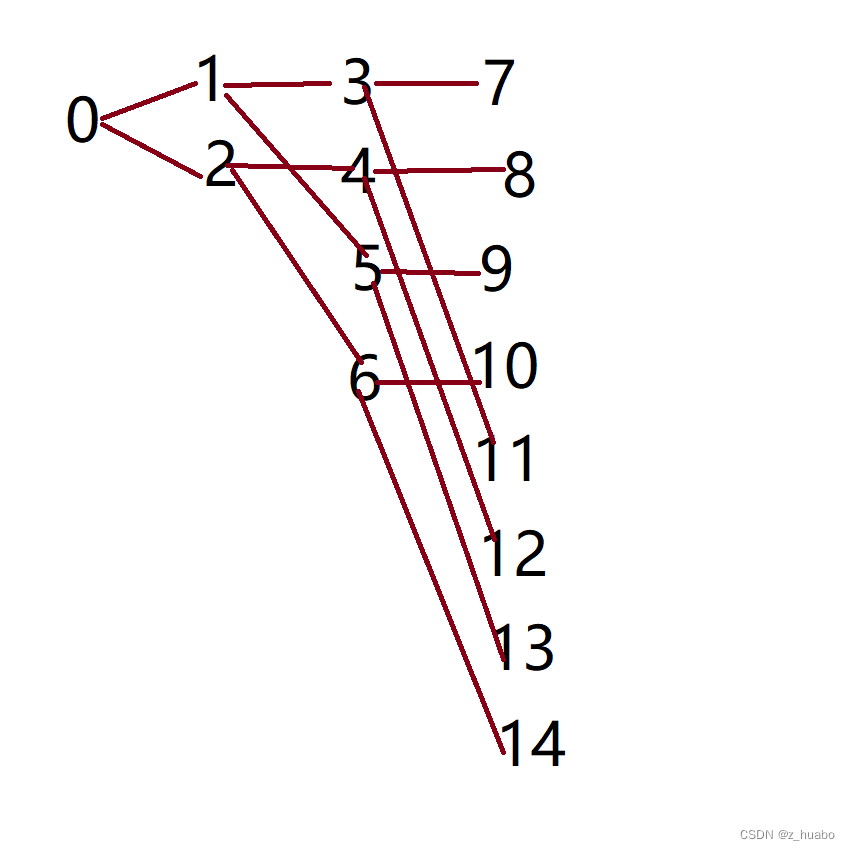
递推过程中,本层参数与下层第一分叉参数,共享同一个tid,第二分叉tid加本层线程总数
完整代码如下:
using namespace std;
//#include <windows.h>
struct Timer {
LARGE_INTEGER tc; //最低频率
LARGE_INTEGER start;//起始时间
LARGE_INTEGER t1;//上次时间
void init() {
QueryPerformanceFrequency(&tc);//系统精确计时的最小单位值
QueryPerformanceCounter(&start); //时间计数开始
t1 = start;
}
//与上次的计时
double TimingButton_ms() {
LARGE_INTEGER now;
QueryPerformanceCounter(&now);
double res = (double)((now.QuadPart - t1.QuadPart) * 1000.0 / tc.QuadPart);
t1 = now;
return res;
}
//与最初的计时
double TotalTime_ms() {
LARGE_INTEGER now;
QueryPerformanceCounter(&now);
return (double)((now.QuadPart - start.QuadPart) * 1000.0 / tc.QuadPart);
}
};
// hash作者:https://nullprogram.com/blog/2018/07/31/
//bias: 0.17353355999581582 ( very probably the best of its kind )
__device__ __host__
uint32_t lowbias32(uint32_t x) {
x ^= x >> 16;
x *= 0x7feb352dU;
x ^= x >> 15;
x *= 0x846ca68bU;
x ^= x >> 16;
return x;
}
#define hash(x) lowbias32((x))
uint32_t c_recursion(uint32_t t, uint32_t depth) {
uint32_t res = 0;
if (depth == 0) { //底层返回
res = t;
}else {
res += c_recursion(hash(t * 10086u), depth - 1); //向下传递本层处理过的参数
res += c_recursion(hash(t * 5201314u), depth - 1);
}
return hash(res * 0x47a92fu); //本层返回 合并的、经过本层处理的值
}
__global__
void first_push(uint32_t* now_params) {
const uint32_t tid = (blockIdx.y * gridDim.x * blockDim.x) + (blockIdx.x * blockDim.x) + threadIdx.x;
now_params[tid] = 5;
}
__global__
void push(uint32_t* now_params, uint32_t* next_params) {
const uint32_t tid = (blockIdx.y * gridDim.x * blockDim.x) + (blockIdx.x * blockDim.x) + threadIdx.x;
const uint32_t now_total = gridDim.y * gridDim.x * blockDim.x;
uint32_t t = now_params[tid];
next_params[tid] = hash(t * 10086u);
next_params[tid + now_total] = hash(t * 5201314u);
}
__global__
void first_back(uint32_t* now_retuenvalue, uint32_t* now_params) {
const uint32_t tid = (blockIdx.y * gridDim.x * blockDim.x) + (blockIdx.x * blockDim.x) + threadIdx.x;
now_retuenvalue[tid] = hash(now_params[tid]* 0x47a92fu);
}
__global__
void back(uint32_t* now_retuenvalue, uint32_t* now_params, uint32_t* last_retuenvalue) {
const uint32_t tid = (blockIdx.y * gridDim.x * blockDim.x) + (blockIdx.x * blockDim.x) + threadIdx.x;
const uint32_t now_total = gridDim.y * gridDim.x * blockDim.x;
uint32_t res = last_retuenvalue[tid]+ last_retuenvalue[tid + now_total];
now_retuenvalue[tid] = hash(res * 0x47a92fu);
}
std::map<std::string, void*> devMemory;
std::map<std::string, void*> hostMemory;
void cleanup() {
for (auto iter = devMemory.begin(); iter != devMemory.end(); ++iter) {
cudaFree(iter->second);
cout << "cleanup devMemory:" << iter->first << endl;
}
for (auto iter = hostMemory.begin(); iter != hostMemory.end(); ++iter) {
cudaFree(iter->second);
cout << "cleanup hostMemory:" << iter->first << endl;
}
}
#define ERRORINSP(status,str) if (status != cudaSuccess) {cout << str <<"\n" <<cudaGetErrorString(status) << endl; cleanup(); return 0;}
int main(void) {
const uint32_t max_depth = 20;//30层使用内存8GB 可能超过显存
const uint32_t value_count = (1u << max_depth) - 1;
Timer timer={};
timer.init();
uint32_t f = c_recursion(5, max_depth-1);
cout << "C递归计时:" << timer.TotalTime_ms() << "ms" << endl;
std::printf("C递归结果: 0x%X \n", f);
timer.init();
cudaError_t cudaStatus;
cudaStatus = cudaMalloc((void**)&devMemory["params"], value_count * sizeof(uint32_t));
ERRORINSP(cudaStatus, "cudaMalloc failed!");
cudaStatus = cudaMalloc((void**)&devMemory["retValues"], value_count * sizeof(uint32_t));
ERRORINSP(cudaStatus, "cudaMalloc failed!");
size_t memsize = value_count * sizeof(uint32_t) * 2;
cout << "已创建的设备内存大小:" << memsize/(1ULL<<20) <<"MB" << endl;
first_push << < 1, 1 >> > ((uint32_t*)devMemory["params"]); //初始值
cudaStatus = cudaDeviceSynchronize();
ERRORINSP(cudaStatus, "launching Kernel:")
cudaStatus = cudaGetLastError();
ERRORINSP(cudaStatus, "Kernel launch failed:")
uint32_t p_offset = 0;
for (int i = 0; i < max_depth - 1; i++) {
uint32_t n = 0x1U << i;
uint32_t* now_params = (uint32_t*)devMemory["params"] + p_offset;
uint32_t* next_params = (uint32_t*)devMemory["params"] + p_offset + n;
dim3 bolck = { 1,1,1 };
dim3 thread = { n,1,1 };
if (i > 10) {
thread.x = 1u << 10u;
bolck.x = 1u << (i-10);
}
push << < bolck, thread >> > (now_params, next_params); //参数递推
cudaStatus = cudaDeviceSynchronize();
ERRORINSP(cudaStatus,"launching Kernel:")
cudaStatus = cudaGetLastError();
ERRORINSP(cudaStatus, "Kernel launch failed:")
p_offset += n;
}
p_offset = value_count;
for (int i = max_depth-1; i >= 0; i--) {
uint32_t n = 0x1U << i;
p_offset -= n;
uint32_t* now_params = (uint32_t*)devMemory["params"] + p_offset;
uint32_t* now_retuenvalue = (uint32_t*)devMemory["retValues"] + p_offset;
dim3 bolck = { 1,1,1 };
dim3 thread = { n,1,1 };
if (i > 10) {
thread.x = 1u << 10u;
bolck.x = 1u << (i - 10);
}
if (i == max_depth - 1) {
first_back << <bolck, thread >> > (now_retuenvalue, now_params); //底层返回
}else{
uint32_t* last_retuenvalue = (uint32_t*)devMemory["retValues"] + p_offset+ n;
back << <bolck, thread >> > (now_retuenvalue, now_params, last_retuenvalue); //返回值
}
cudaStatus = cudaDeviceSynchronize();
ERRORINSP(cudaStatus, "launching Kernel:")
cudaStatus = cudaGetLastError();
ERRORINSP(cudaStatus, "Kernel launch failed:")
}
cout << "CUDA计时:" << timer.TotalTime_ms() << "ms" << endl;
uint32_t data = 0;
cudaStatus = cudaMemcpy(&data, devMemory["retValues"], 1 * sizeof(uint32_t), cudaMemcpyDeviceToHost);
std::printf("CUDA递归结果: 0x%X \n", data);
// system("pause");
cleanup();
return 0;
}运行结果如下
C递归计时:8.3675ms
C递归结果: 0x96AA2994
已创建的设备内存大小:7MB
CUDA计时:301.847ms
CUDA递归结果: 0x96AA2994
cleanup devMemory:params
cleanup devMemory:retValues结果是正确的,说明效果达到了。
如果提高一个维度,把初始的0看做一个像素
我使用它来改造用C语言画光(七):比尔-朗伯定律 - 知乎 (zhihu.com)


1024*1024像素,255次采样,4层追踪,:3分钟 ,5层:8分钟,6层:13分钟
场景更复杂的情况下比原版快十倍
cuda还可以用2048*2048模拟4次采样,这些是同时发生的















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









