






CUDA学习(一):并行规约Reduce
该系列文章主要用于记录自己学习cuda并行优化的整个学习过程,方便本人回顾复习,如果能给有所帮助,不甚荣幸,诸君共勉,振兴中华!
文章目录
前言
规约(Reduce)可以认为是对所有数组添加一种规则或者说规范,这是一种非常典型的并行算法,给定N个输入数据,指定符合结合律的二元操作符最终得到规约结果,而这个二元操作符便包括求和,最大最小,点积等。本文主要介绍的是求和的并行规约算法。
一、主函数实现
主函数主要划分为以下四个部分:
1、初始化数据
设定输入数据的大小,以及每个规约数据块的大小,为输入数据在主机端和设备端分别申请空间,并且初始化空间
代码如下所示:
const int N = 32 * (1 << 20); //输入数据规模:32M
const int NUM_PER_THREAD = 8; //每个线程在加载全局内存时计算的数字个数
//主机端输入数据初始化
float *h_in = (float *)malloc(N * sizeof(float));
initialData(h_in , N);
//设备端输入数据初始化
float *d_in;
cudaMalloc((void **)&d_in , N * sizeof(float));
cudaMemcpy(d_in , h_in , N * sizeof(float) , cudaMemcpyHostToDevice);
这里的使用自定义的初始化主机空间函数initialData代码如下所示:
// 对数组进行初始化
void initialData(float * A, int width)
{
for (int i = 0; i < width; i++)
{
A[i] = 1.0;
}
}
2、主机串行规约并计时
初始化主机端输入数据后,使用串行的方式实现规约算法,串行规约算法即将原先输入数组按照规约数据块的大小进行划分,再分别计算对应数据块的规约结果存储到对应串行结果中,代码如下:
// (2)主机串行计算并计时
int block_num = (N / BLOCK_SIZE); // 线程块的个数
float * seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
// 划分为256个小块进行累加求和
for (int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for (int j = 0; j < BLOCK_SIZE; j++)
{
seq_result[i] += h_in[i * BLOCK_SIZE + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
这里使用到的CPU运行计时函数为自定义函数吗,具体函数代码如下所示:
// 获取当前CPU时间的函数
double cpuSecond()
{
struct timeval tp;
gettimeofday(&tp, NULL);
return ((double)tp.tv_sec + (double)tp.tv_usec * 1e-6);
}
3、GPU并行规约并计时
GPU并行规约实现同串行实现一样将全部数据按照数据块大小进行划分,但是会在GPU上由核函数实现,主函数部分主要通过cuda事件对GPU上核函数的运行时间进行计时。具体代码如下所示:
// (3) GPU计算并计时
float * d_out;
cudaMalloc(&d_out, block_num * sizeof(float));
float * h_out = (float *)malloc(sizeof(float) * block_num);
cudaEvent_t start, stop;
float gpu_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 核函数规约计算
reduce5<BLOCK_SIZE, NUM_PER_THREAD><<<block_num, BLOCK_SIZE>>>(d_in, d_out);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&gpu_time, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(h_out, d_out, sizeof(float) * block_num, cudaMemcpyDeviceToHost);
checkResult(seq_result, h_out, block_num);
这里最后会对串行和并行实现的结果进行比较,比较函数代码如下所示:
// 对CPU计算结果与GPU计算结果进行对比
void checkResult(float *hostResult, float *gpuResult, int width)
{
double epsilon = 1.0e-3; // 单精度浮点数相加会出现大数吃小数的现象,小数点后的精度不能卡的太低
for (int i = 0; i < width; i++)
{
if (abs(hostResult[i] - gpuResult[i]) > epsilon)
{
printf("第%d个计算结果不同:host %.8f, gpu %.8f, 相差 %.3f\n", i, hostResult[i], gpuResult[i], abs(hostResult[i] - gpuResult[i]));
exit(1);
}
}
}
4、输出结果
上述分别在主机端和设备端按照数据块将原始数据进行分块,并分别计算每个数据块的规约结果,最终得到block_num个数据块的计算结果,最终在主机端使用CPU计算最后的规约结果,之后分别输出主机端和设备端的结果,释放主机端和设备端申请的空间。
// (4)计算最终结果并输出
float seq_final_res = 0.0;
float gpu_final_res = 0.0;
for (int i = 0; i < block_num; i++)
{
seq_final_res += seq_result[i];
gpu_final_res += h_out[i];
}
printf("相邻配对规约串行实现的结果为 %.3f, 并行实现的结果为 %.3f\n", seq_final_res, gpu_final_res);
printf("计算%dM数据串行实现时间为 %fms, 并行实现时间为 %fms\n", N/ (1 << 20), cpu_time, gpu_time);
printf("并行计算加速比为: %.2f\n", cpu_time / gpu_time);
// 释放指针空间
free(h_in);
free(h_out);
free(seq_result);
cudaFree(d_in);
cudaFree(d_out);
return 0;
二、相邻配对实现
首先本文通过相邻配对的方法实现并行规约算法。

如上图所示,相邻配对的思路指的是相邻两数相加并将结果写回到前者,相邻元素之间的步长从1开始,每一轮翻倍,经过多轮迭代得到最终的规约结果。
在kernel函数中,考虑使用与数据块对应大小的线程块通过相邻配对的方式进行规约,并且考虑将数据放入共享内存中,在共享内存中对数据进行规约,最后再将结果写回到全局内存。代码如下所示:
// 规约核函数
__global__ void reduce0(float * g_in, float * g_out)
{
// 相邻配对的方法实现规约
// (1)首先从全局内存加载到共享内存中
__shared__ float s_data[BLOCK_SIZE];
int i = blockIdx.x * blockDim.x + threadIdx.x; // 在全局内存上的位置
int tid = threadIdx.x; // 在共享内存上的位置
s_data[tid] = g_in[i];
__syncthreads(); // 线程同步
// (2)相邻元素进行配对相加
for(int s = 1; s < BLOCK_SIZE; s = 2 * s)
{
// 针对对应位置的元素进行规约运算, 每个线程束都会出现线程束的分化,需要给对应的线程分配资源,修改线程索引,让线程束中空闲线程去执行操作
if (tid % (2 *s) == 0)
{
s_data[tid] = s_data[tid] + s_data[tid + s];
}
__syncthreads(); // 线程同步
}
if (tid == 0)
g_out[blockIdx.x] = s_data[0];
}
这里需要注意的是核函数中在将全局内存加载到共享内存后,和每一轮迭代计算后需要进行线程同步;以及加载全局内存时候需要将在全局内存中的位置以及在共享内存中的位置对应。
得到执行结果如下:
相邻配对规约串行实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 89.594126ms, 并行实现时间为 5.768512ms
并行计算加速比为: 15.53
三、消除线程束分化
在相邻配对的方式实现并行规约时,每个线程束warp中会出现线程束分化。
线程束是SM中基本的执行单位,线程块被分配到某一个SM上以后,将划分为多个线程束,每个线程束一般是32个线程,在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但处理的数据为私有的数据。
线程束分化指的是同一线程束中的线程,执行不同的指令,但是在刚刚介绍中,我们知道一个线程束中的所有线程是按照SIMT的方式执行,每一步执行相同的指令,那么发生分化后同一线程束中的线程为什么可以执行不同的指令呢,这里实际上每个线程都执行了if和else中的部分,那么线程束中一部分满足条件的线程去执行了if块内的代码,剩下一部分不满足条件的线程便等待这部分满足条件的线程执行完。
因此线程束分化会产生非常严重的性能下降。而在之前相邻配对方式实现规约时的判断便会发生线程束分化,例如线程束warp0中的0~31号线程在第一轮迭代会有一半线程需要等待另外一半满足if (tid % (2 *s) == 0)条件判断的线程执行完成后再执行。
可以参考下面这篇博客:线程束分化理解
为了解决线程束分化问题,只需要让一个线程束中所有的线程都能满足条件或者都不能满足条件即可,那么只需要将线程号与数据块中元素的对应进行修改即可。具体代码如下:
__global__ void reduce1(float *g_in,float *g_out)
{
//(1)每个线程从全局内存中加载一个对应位置元素到共享内存
__shared__ float s_data[BLOCK_SIZE];//共享内存大小等于线程块的大小
int tid = threadIdx.x; //共享内存中的索引,即在线程块中的编号
int i = blockIdx.x*blockDim.x + threadIdx.x;//全局内存中的索引
s_data[tid] = g_in[i];
__syncthreads(); //同步等待共享内存加载完毕
//(2)在共享内存做相邻配对归约,线程和数据序号间隔对应
for(int s = 1; s < blockDim.x; s *= 2)
{
int index = 2 * s * tid;
if (index < blockDim.x)
{
s_data[index] += s_data[index + s];
}
__syncthreads();
}
//(3)把结果写回全局内存
if (tid == 0) g_out[blockIdx.x] = s_data[0];
}
值得注意的是,我们将原本的线程号tid进行了映射,映射为index = 2 * s * tid,这样可以让一个线程束中所有的线程都能去执行相同的指令。
消除线程束分化后得到运行结果如下:
除线程束约束优化后串行实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 89.890003ms, 并行实现时间为 6.966688ms
并行计算加速比为: 12.90
这里问题就来啦!咱们明明是做了线程束分化消除优化的,为什么并行计算的时间反而相较于相邻配对的实现更多了呢?
这里就需要引入我们接下来的新的优化了。
四、消除Bank Conflict
消除线程束分化的同时,在共享内存中也发生了bank conflict,导致了消除线程束分化未能实现加速。那么为什么会发生bank conflict呢?
了解bank conflict,首先需要去了解共享内存中的地址映射方式,在共享内存中,连续的32bits字被分配到连续的32个bank中,其中每一列表示一个bank,至于为什么是32呢,其实也和warp是32个线程相对应的。
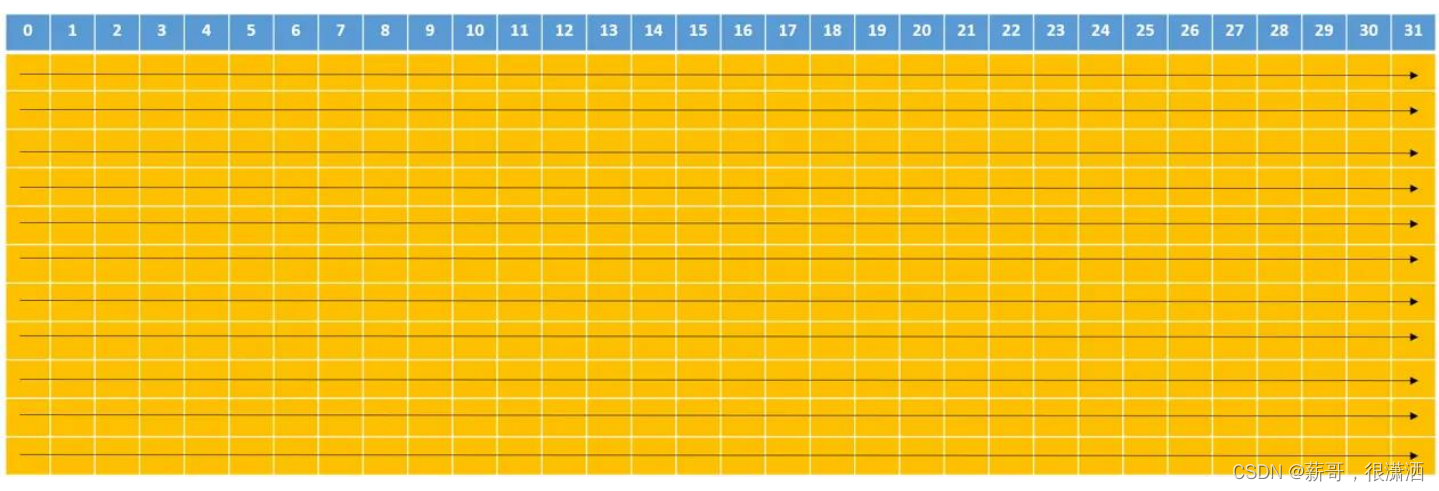
当同一线程束的不同线程对共享内存中的同一bank进行访存时便会出现bank conflict。
在消除线程束分化时,同一线程束中0号线程s_data[0]和s_data[1],16号线程访问s_data[32]和s_data[33],而在共享内存中s_data[0]和s_data[32]在同一bank中,便发生了同一线程束中的不同线程访问共享内存中同一bank的情况即发生了bank conflict。
可以采用交错配对规约的方式消除bank conflict,同时也可以消除线程束分化。
交错配对规约的形式如下图所示:
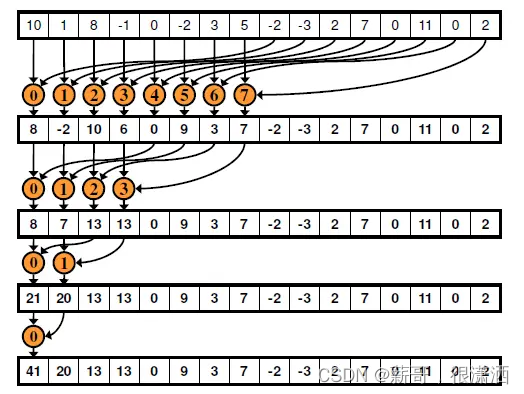
采取的步长从(blockDim.x / 2)开始缩减,规约操作的数位置分别为tid和tid+s,最终计算结果存入tid位置。
核函数代码如下所示:
__global__ void reduce2(float * g_in, float * g_out)
{
// (1) 线程将全局内存传入共享内存中
__shared__ float s_data[BLOCK_SIZE];
int tid = threadIdx.x;
int i = blockDim.x * blockIdx.x + threadIdx.x;
s_data[tid] = g_in[i];
__syncthreads();
// (2) 交错匹配进行并行规约运算
for(int s = (BLOCK_SIZE / 2); s > 0; s = s / 2)
{
if (tid < s)
{
s_data[tid] = s_data[tid] + s_data[tid + s];
}
__syncthreads();
}
if (0 == tid) g_out[blockIdx.x] = s_data[tid];
}
运行结果如下所示:
使用交错配对方式消除bank conflict优化后串行实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 86.750031ms, 并行实现时间为 4.734624ms
并行计算加速比为: 18.32
五、加载时计算
上述的优化方法均为单线程块处理一个大小相同的数据块,但是单线程块在将全局内存中的数据加载到共享内存同时仍然存在大量线程处于空闲状态,考虑将一个线程块展开两个数据块的处理,即每个线程从全局内存中取数的同时,从相邻数据块内取两个数做加法并将计算结果存入共享内存中。
加载时计算让线程数量减半,并且每个线程有更多的独立内存加载/存储操作,实现更好的延迟隐藏。
具体操作如下图所示
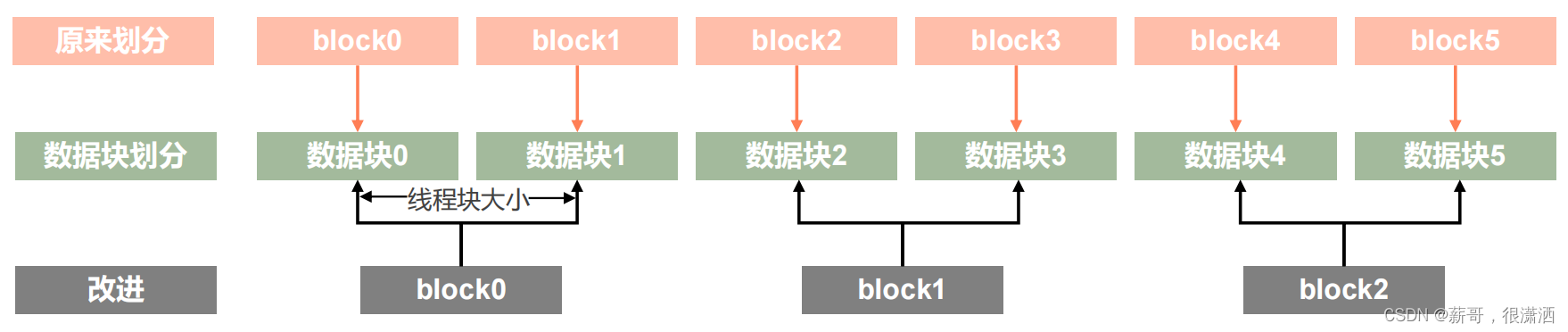
当然这里不仅仅是只能用单线程块处理两个数据块,也可以处理多个数据块。
这里给出单线程块同时处理两个数据块的具体核函数,代码如下所示:
__global__ void reduce3(float * g_in, float * g_out)
{
// (1) 从全局内存加载至共享内存,并且加载时计算,减半线程块达到延迟隐藏
__shared__ float s_data[BLOCK_SIZE];
int tid = threadIdx.x;
int i = blockDim.x * (2 * blockIdx.x) + threadIdx.x;
s_data[tid] = g_in[i] + g_in[i + blockDim.x];
__syncthreads(); // 线程同步
// (2)交错规约计算
for (int s = (blockDim.x / 2); s > 0; s = s / 2)
{
if (tid < s)
s_data[tid] += s_data[s + tid];
__syncthreads();
}
// 输出结果
if (0 == tid)
g_out[blockIdx.x] = s_data[tid];
}
这里需要注意的是此时单线程块处理的数据块数量不一致,因此在主函数实现时CPU计算的数据块大小也需要变化为单线程块处理的数据块大小,修改后CPU计算的代码如下所示:
// (2) CPU上规约计算并计时,使用加载时计算,因此线程块数量减半
int block_num = N / (BLOCK_SIZE *2);
float * seq_result = (float *)malloc(block_num * sizeof(float));
double cpu_start = cpuSecond();
for (int i = 0; i < block_num; i++)
{
seq_result[i] = 0.0;
for (int j = 0; j < BLOCK_SIZE * 2; j++)
{
seq_result[i] += h_in[i * BLOCK_SIZE * 2 + j];
}
}
double cpu_time = (cpuSecond() - cpu_start) * 1000.0;
得到最后的运行结果如下所示
优化三加载时计算实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 89.803934ms, 并行实现时间为 3.621984ms
并行计算加速比为: 24.79
六、循环展开
在使用高级语言编程时,我们已经不会刻意去进行循环展开了,因为这件事会由编译器帮助我们完成。但是在CUDA编程中,循环展开便具有很重要的意义,因为循环展开给线程束调度器提供更多可用的线程束,以帮助有效的隐藏延时。
在做交错规约计算时会发现在只有32及小于32个元素需要规约时,此时只需要32个或者更少的线程参与,而当每次迭代之后都需要进行线程束同步,可以考虑将最后六次的迭代展开,让warp0去执行分支里面的内容,核函数的代码如下所示:
__global__ void reduce4(float * g_in, float * g_out)
{
// (1)使用加载时计算的方法将全局内存加载至共享内存
__shared__ float s_data[BLOCK_SIZE];
int tid = threadIdx.x;
int i = blockDim.x * blockIdx.x * 2 + threadIdx.x;
volatile float * cache;
s_data[tid] = g_in[i] + g_in[i + blockDim.x];
__syncthreads();
// (2) 对wrap0线程束进行循环展开
for (int s = (BLOCK_SIZE / 2); s > 32; s = s / 2)
{
if (tid < s)
s_data[tid] += s_data[tid + s];
__syncthreads();
}
// 当只需要一个wrap中的线程时则不需要其他线程束进行同步等待
if (tid < 32)
{
cache = s_data;
cache[tid] += cache[tid + 32];
cache[tid] += cache[tid + 16];
cache[tid] += cache[tid + 8];
cache[tid] += cache[tid + 4];
cache[tid] += cache[tid + 2];
cache[tid] += cache[tid + 1];
}
if (0 == tid)
g_out[blockIdx.x] = cache[tid];
}
需要注意的是这里使用了volatile关键字,添加该关键字的作用在于告诉编译器不对该变量做优化,使用volatile声明变量,必须直接读写所在的内存,同时保证对特殊地址的稳定访问。
得到运行结果如下所示:
优化三加载时计算实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 89.094162ms, 并行实现时间为 1.898496ms
并行计算加速比为: 46.93
可以发现在使用循环展开的方法优化后,加速比得到了非常大的提升。
七、循环完全展开
目前核函数中只剩下一个循环了,由于已知最大迭代次数,也可以将该for循环进行展开。
代码如下所示:
template<int blockSize, int NUM_PER_THREAD>
__global__ void reduce5(float * g_in, float * g_out)
{
// (1)加载数据
__shared__ float s_data[blockSize];
int tid = threadIdx.x;
int idx = (blockSize * NUM_PER_THREAD * blockIdx.x) + threadIdx.x;
volatile float * cache;
s_data[tid] = 0.0; // 这里的s_data[tid]在下面并不是直接赋值可能会将原先的地址的值加载进去
// 使用pragma语句改变编译器,使编译器对循环进行展开
#pragma unroll
for (int i = 0; i < NUM_PER_THREAD; i++)
{
s_data[tid] += g_in[idx + blockSize * i];
}
__syncthreads();
// 输出s_data
printf("%f\n", s_data[tid]);
__syncthreads();
// (2) 交错配对并行规约计算
// 将循环完全展开
if (blockSize >= 1024)
if (tid < 512)
s_data[tid] += s_data[tid + 512];
__syncthreads();
if (blockSize >= 512)
if (tid < 256)
s_data[tid] += s_data[tid + 256];
__syncthreads();
if (blockSize >= 256)
if (tid < 128)
s_data[tid] += s_data[tid + 128];
__syncthreads();
if (blockSize >= 128)
if (tid < 64)
s_data[tid] += s_data[tid + 64];
__syncthreads();
// 针对单线程束的循环展开
if (tid < 32)
{
cache = s_data;
cache[tid] += cache[tid + 32];
cache[tid] += cache[tid + 16];
cache[tid] += cache[tid + 8];
cache[tid] += cache[tid + 4];
cache[tid] += cache[tid + 2];
cache[tid] += cache[tid + 1];
__syncthreads();
}
if (0 == tid)
g_out[blockIdx.x] = s_data[tid];
}
得到结果如下所示:
优化五:循环完全展开+单线程块执行多数据块实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 117.948055ms, 并行实现时间为 1.213600ms
并行计算加速比为: 97.19
可以看到这次的优化也得到了非常大的提升效果,该提升效果的作用可能还来源于单线程执行更多的数据块的原因。
八、shuffle指令优化
shuffle是一组针对warp的指令,使用该指令优化可以允许线程直接读其他线程的寄存器值
利用shuffle指令优化将每个线程块按照warp进行规约,并将规约结果存入共享内存中,在对每个warp进行规约时可以使用shuffle指令进行优化,代码如下所示:
template<int blockSize>
__device__ float warpReduce(float sum)
{
if (blockSize >= 32) sum += __shfl_down_sync(0xffffffff, sum, 16);
if (blockSize >= 16) sum += __shfl_down_sync(0xffffffff, sum, 8);
if (blockSize >= 8) sum += __shfl_down_sync(0xffffffff, sum, 4);
if (blockSize >= 4) sum += __shfl_down_sync(0xffffffff, sum, 2);
if (blockSize >= 2) sum += __shfl_down_sync(0xffffffff, sum, 1);
return sum;
}
template<int blockSize, int NUM_PER_THREAD>
__global__ void reduce6(float * g_in, float * g_out)
{
// (1) 使用单线程块处理多个数据块的数据
float sum = 0.0;
int tid = threadIdx.x;
int index = blockIdx.x * (blockSize * NUM_PER_THREAD) + tid;
for (int i = 0; i < NUM_PER_THREAD; i++)
{
sum += g_in[i * blockSize + index];
}
// 计算多个数据块上对应线程的之和交给该线程进行处理
// 对一个线程块中的数据分线程束规约至共享内存
__shared__ float warpSum[WARP_SIZE];
// 确定线程束的编号和线程束的内的编号,线程束中每个线程的编号称之为lane
int laneId = tid % WARP_SIZE;
int warpId = tid / WARP_SIZE;
// 线程束中所有元素归约到laneId为0的线程
sum = warpReduce<blockSize>(sum);
if (laneId == 0)
warpSum[warpId] = sum;
__syncthreads();
// 对共享内存中warpSum的元素进行规约计算
// 将结果收集到0号线程束的各线程
sum = (threadIdx.x < (blockSize / WARP_SIZE)) ? warpSum[laneId] : 0;
// 交由0号线程束做规约操作
if (warpId == 0) sum = warpReduce<blockSize/WARP_SIZE>(sum);
if (tid == 0) g_out[blockIdx.x] = sum;
}
得到优化结果如下所示
优化六:shuffle指令优化+单线程块执行多数据块实现的结果为 33554432.000, 并行实现的结果为 33554432.000
计算32M数据串行实现时间为 91.916084ms, 并行实现时间为 1.015264ms
并行计算加速比为: 90.53
可以发现在使用shuffle指令优化后效果确实可以达到比较好的优化效果,但是效果相较于完全展开的方式要差一些,其实这种shuffle指令的方式代码更为复杂,有时候咱们还是需要权衡一下代码实现时间和代码实现效果之间的关系。
总结
经过上述的一系列优化方法可以使得并行规约的运行时间得到大幅度的提升,可以看到循环展开的优化效果是非常明显的。作为入门级优化项目,完整的实现上述优化方法还是可以很好的帮助我们入门并行优化。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









