






一、Self-Attention 自注意力
先来看看最基本的 Self-Attention
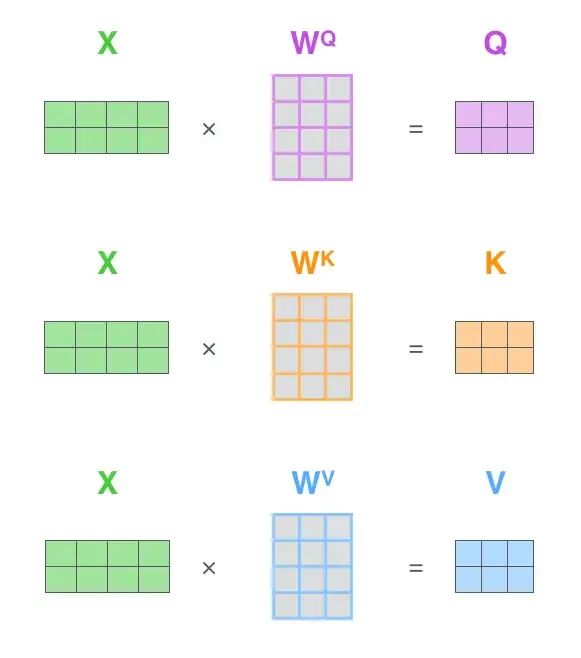
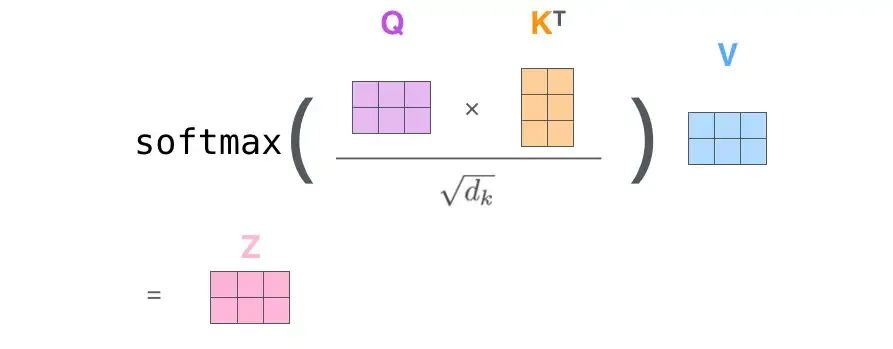
为了最终计算出z, 需要一步一步来, 这里面就产生了计算时中间结果占用内存. 我们知道计算机 (无论是 GPU 还是 CPU) 的内存都是分级的, 如果能够优化内存占用, 就可以尽可能减少内存的存取, 这个对于 latency 的降低帮助很大.
著名的 FlashAttention 就是利用中间结果可以分块计算这一特性, 来减少中间结果的内存占用, 进而达到降低 latency 的目的. 下面我们来分析一下 FlashAttention, 在这个过程中, 也可以更加清晰的分析有哪些中间结果.
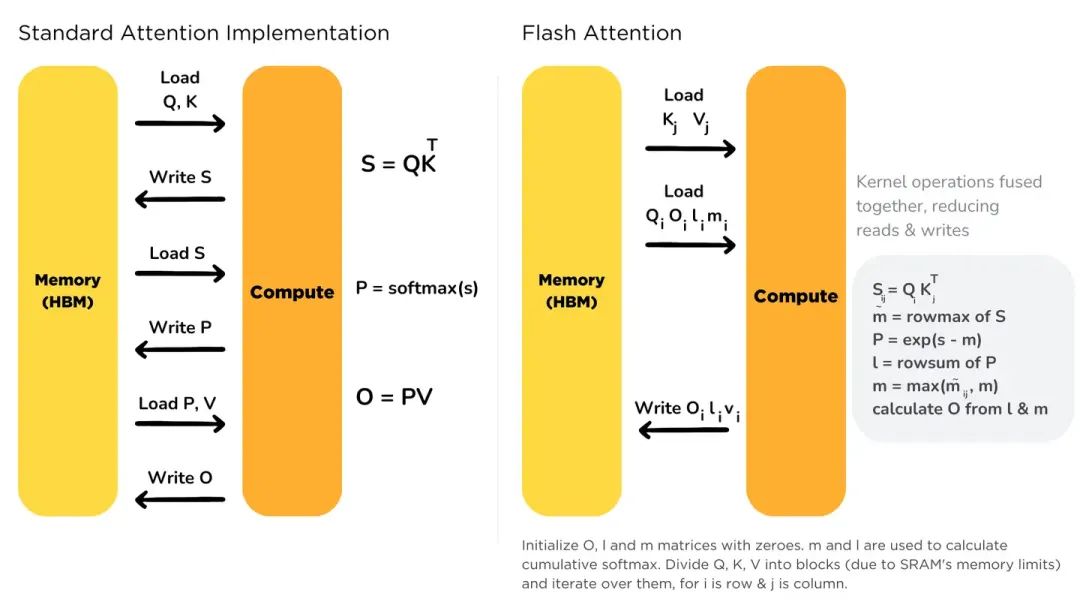
注意, 中间结果基本都涉及内存的写和读. 因为得到中间结构后要写, 然后再用中间结果算下一步的时候要读.
拆解一下上图 (以 LLaMA 70b 为例, 有 80 层. 为了简化计算, 我们假设 single head attention)
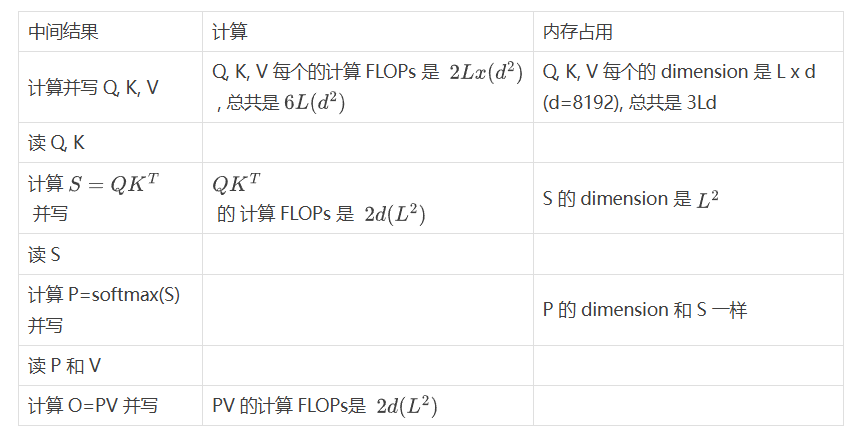
从这个表我们可以分析出很多东西. 其中一个就是 Attention Map 的大小是 , 其实这也是为什么 long sequence 对于 Transformer 一直都是一个问题. 二次方的代价实在是太高.
接下来, 我们接着讨论 Self Attention 在 training 和 inference 时候分别的问题和解决思路.
二、训练
现有的语言模型训练时大多采用 Causal language modeling.
先来讲一下 CLM.
首先要澄清两个非常容易混淆的概念, 就是 CLM 和 NWP (next world prediction) 其实不能混为一谈.
这两个概念有关系, 但绝非等价.
NWP 是从任务的角度来定义的, 我们训练 Transformer 时候做的是预测下一个词. 比如一句话 “I am doing ok”, 那么 NWP 做的是:
• I --> am
• I am --> doing
• I am doing --> ok
而 CLM 是讲我们在算 attention 的时候, 无论是 1 还是 2 还是 3, 每个词都只能 attention 到它之前的词. 举个例子, 1 的时候, 因为只有 “I” 这个词, 所以没办法, “I” 只能 attention “I” 自己. 到了 2 的时候, 这个时候即使 “I” 后面有个 “I” 这个词, 但是在 CLM 设定下, “I” 还是只能 attention “I” 自己, 而不能 attention 自己之后的词 “am”.
至于 CLM 为啥这么规定, 这里的原因不止一个,
有一些建模上的原因: 比如有人说是加了 CLM mask 的 attention 天然满秩, 为什么现在的LLM都是Decoder only的架构[1]?, 还有人说这样的 attention 隐式的编码了位置信息[2].
但是我们马上还会看到, 这样做还有一些计算上的原因.
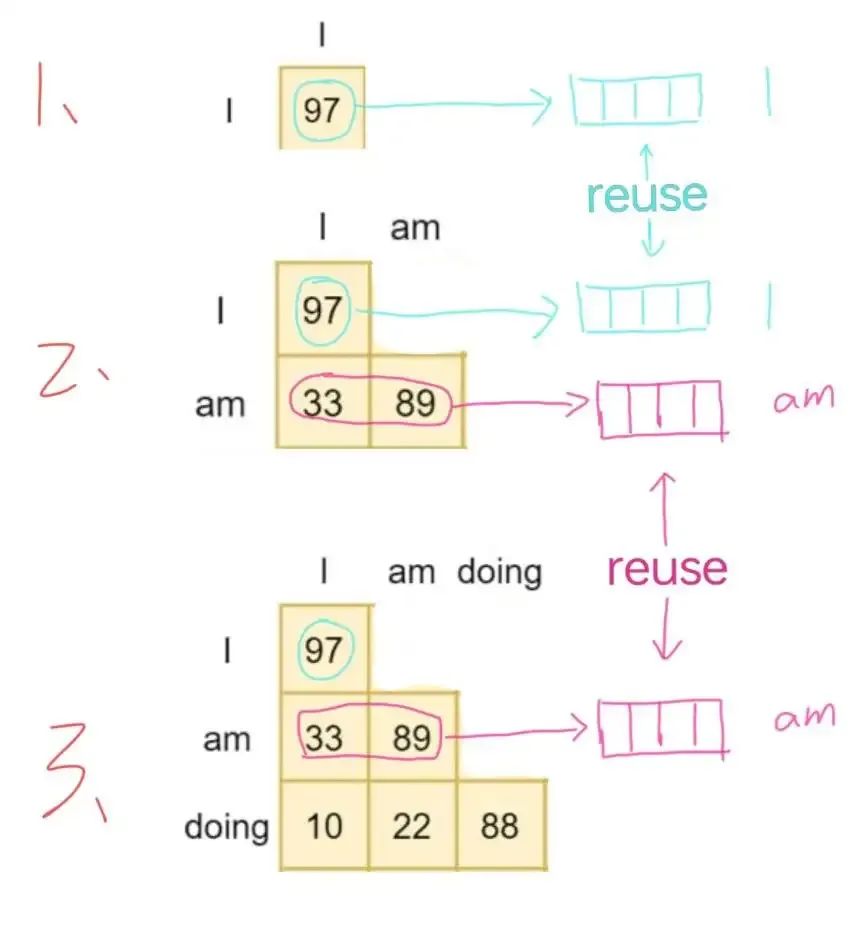
第一行 (1), 输入是 “I”, 所以计算 “I” 的 embedding 的时候, 只能用到 “I” 自己.
第二行 (2), 输入是 “I am”, 由于 Causal Language Modeling 的规定, “I” 还是只能 attention 自己, 所以第二行的 attention map, 要 “故意” 把右上角 mask out. 而这带来一个好处, 那就是, 不管是第一行还是第二行(甚至第三行) “I” 这个单词对应的 embedding 一定是一样的. 那么我们在算第二行的时候, 其实可以直接复用第一行 “I” 的 embedding.
第三行 (3), 以此类推, “am” 的 embedding 可以复用第二行的. 这种复用是非常强大的, 也就是说
一个四个单词的句子, 可以构建出三个预测任务 (1,2,3), 但是完成这三个任务可以复用一些结果, 导致每个任务平均下来只需要算一个新的 embedding 就可以. 而且, 其实在实现上这三个任务可以一次性算出来, 只需要对 attention map 加一个上三角的 mask 就可以.
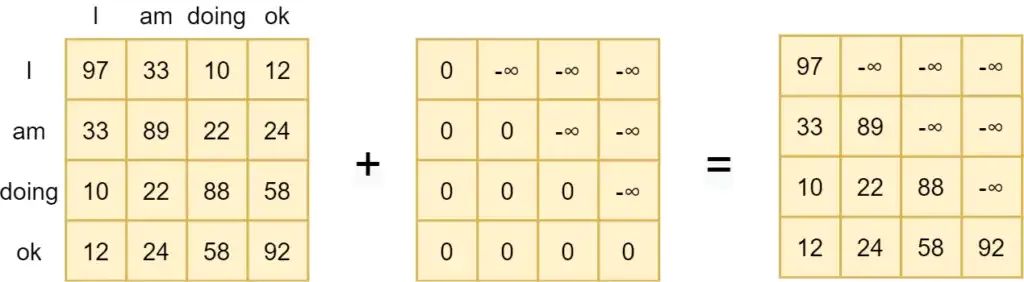
因为是负无穷, 经过 softmax 之后就会变成 0.
我们可以想象一下, 如果还是做 Next Word Prediction, 但是 是 Non-Causal Language Modeling, 情况会怎么样?
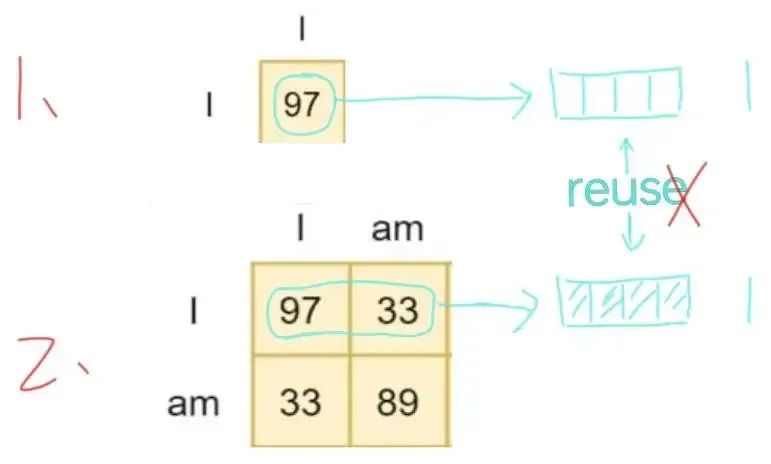
在第二行, “I” 如果可以 attention 到 “am”, 会导致 “I” 最终产生的 embedding 和第一行里面 “I” 的 embedding 不同, 自然就不能 reuse 了. 也就说, 这三个任务, 对于每个任务都需要重新算一遍 attention map. 这和 Casual Language Modeling 相比, 计算复杂度直接乘了 sequence length.
推理
既然训练的时候可以 reuse, 那么自然推理的时候也可以 reuse.
由于推理的时候, 每次生成一个词, 所以其实每次只需要算 attention map 最后一行对应的那个 token embedding 就行了, 其他的直接复用.
这个 attention map 最后一行涉及到: a. 最后一个 token 的输入 embedding, b. 之前所有 token 的 k, c. 之前所有 token 的 v.
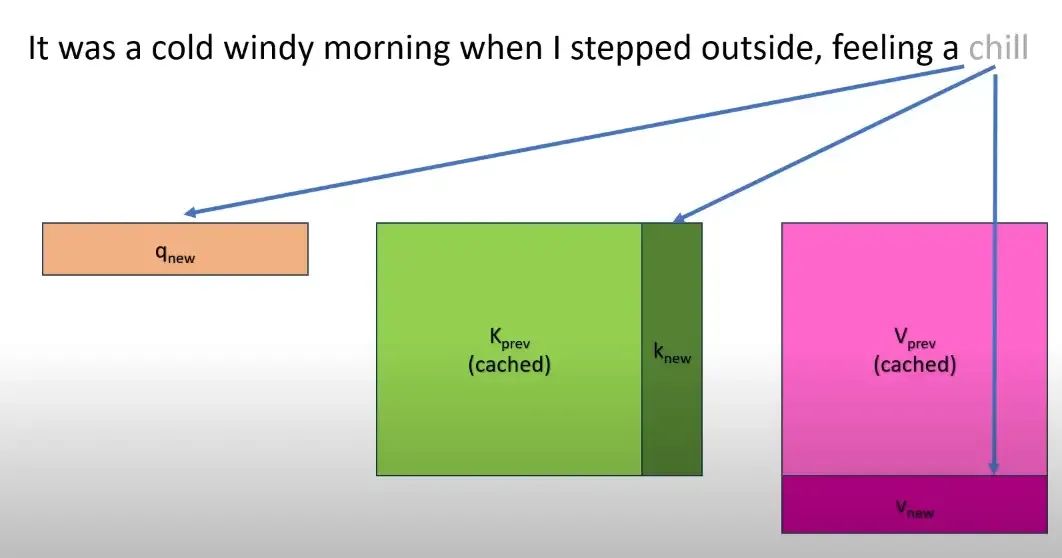
这个复用虽然省了计算, 但是费了存储, 这也是为什么大模型的 k v cache 是一个大问题.
并行 与 复用
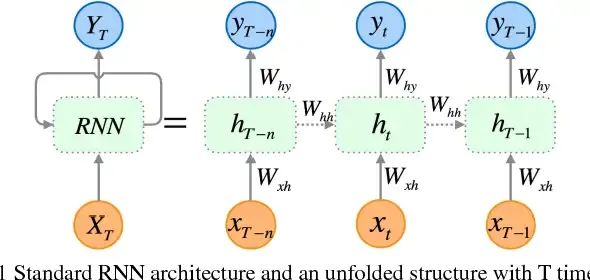
我们经常听到 RNN不方便并行, Transformer 并行化好.
首先, 我们要理解当我们说并行的时候, 我们到底在说什么. 先来看下 RNN 的结构
首先我们可以看到, RNN 中 中间结果 的复用性是非常强的. 所有之前的 token, 都被 “浓缩” 到了一个固定 hidden state 中, 所以 RNN 几乎不存在 cache 太大的问题. 这个是 RNN 的计算优点, 但也是她的建模缺点.
再来说一下, 为什么大家说 RNN 的并行度低呢, 因为 在当前层, 我们如果想要开始计算的 embedding, 必须要先完成的计算并拿到才能开始. 那这样,和 的计算自然就不能并行, 因为他们之间有先后关系.
而这个先后关系, 正是 RNN 中的强复用性导致的.
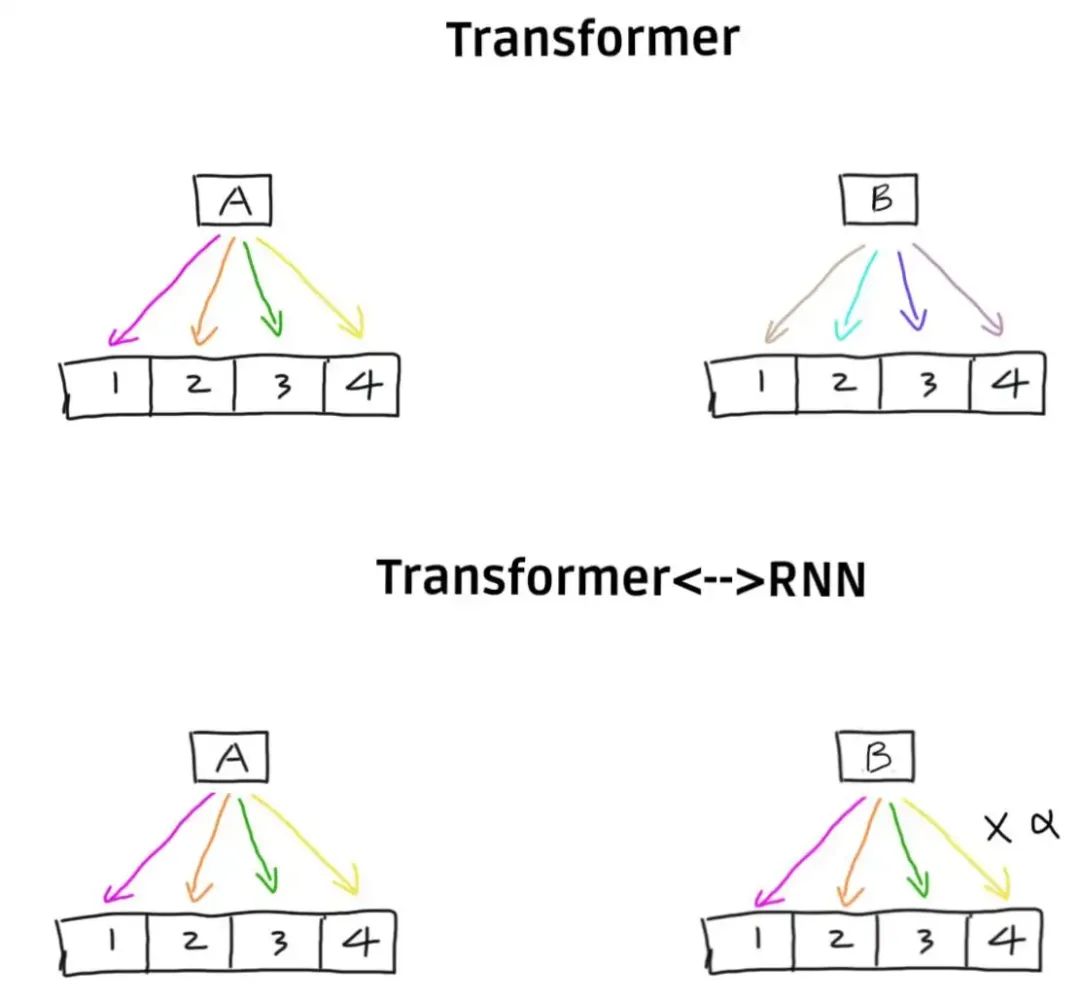
再来看下 Transformer. Transformer 中, 在当前层, 我们如果想要开始计算 x_t 的 embedding, 必须拿到上一层所有的 token 的 embedding, 跟本层的其他 token 的 embedding 无关, 因此可以并行.
但是我们前面讲过 Transformer 也有复用, 为什么 Transformer 的复用没有导致低并行度呢? 因为
Transformer 的复用不是发生在当前层, 也就是说 并不需要复用 的结果.
(Casual) Transformer 的复用是发生在不同的 runs 之间, 或者说 tasks 之间.
• I --> am
• I am --> doing
• I am doing --> ok
在这三个 run 中, “I” 这个 token 对应的 embedding 总是一样的. 所以, 2, 3 可以复用 1 已经算出来的 “I”.
三、Multi-Head Attention
其实 Multi-head Attention 很简单, 就是把每个 embedding 拆成 N 份, 然后每份独立做 Attention, 做完之后再把这 N 份的结果拼接起来, 最后再过一个全连接层混合一下. 这么做基本没有什么计算或者内存的变化 (加的那个全连接层除外).
四、Multi-Query Attention
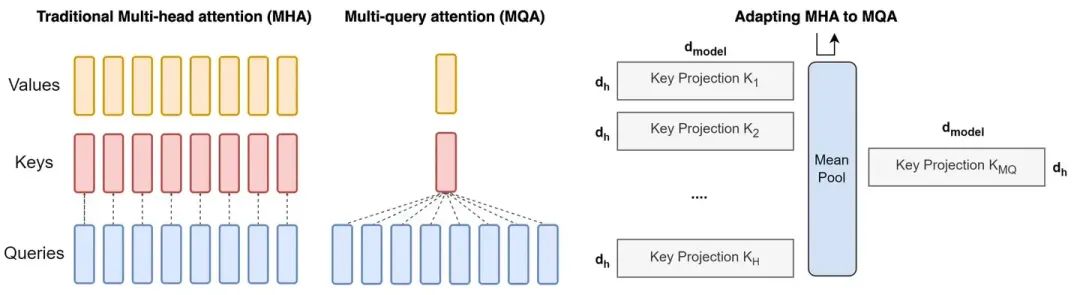
前面讲了, MHA 就是 N 个 Attention Head 独立操作, 最后拼接起来. 上图最左边就代表了一个有 N=8 个 Attention Head 的 MHA.
Multi-Query Attention 其实就是做了一些 weight sharing. 还是有 8 个 Attention Head, 这 8 个 head 各自有各自的 Query, 但是他们共享 Key 和 Value 的部分. 至于怎么共享, MQA 原文的做法是把原本独立的 8 个 Key (或者 Value) 求个平均, 然后复制 8 份来用.
可以看到, MQA 的优势自然是降低了中间结果的大小, 使得需要 cache 的内容变少了.
那么在 MHA 和 MQA 之间还衍生出了 Grouped Query Attention
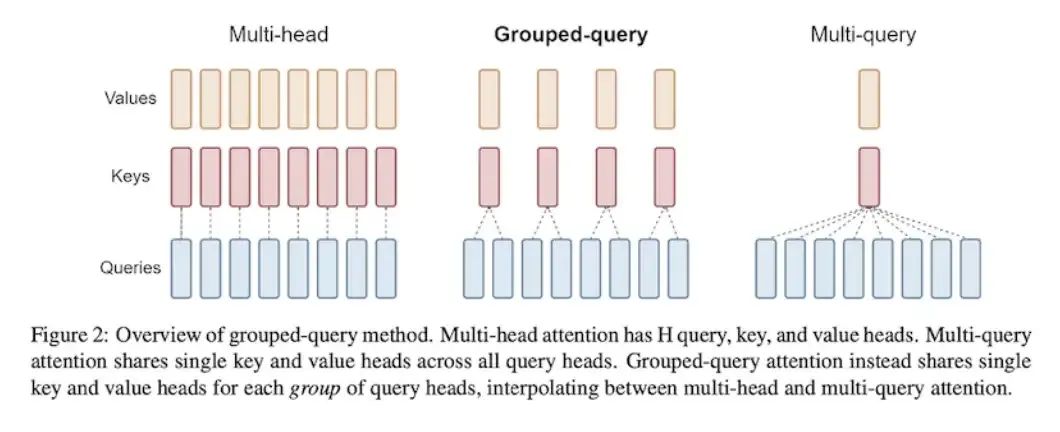
无非就是改了一下 weight sharing 的程度, 相当于在 MHA 和 MQA 之间找一个中庸位置. 这个 GQA 用的还是比较广泛的, LLaMA 2 和 Mistral7B 都用了 GQA.
五、Linear Attention 线性注意力
其实, 对于某个 token 来说, Attention 说白了就是 加权求和 (weighted sum). 我们算的 Attention map 就是这里的 权 (weight).
如上图所示, 计算一个 token 需要的 Attention map 要由, 当前 token 的 query 去和 之前所有 token 的 key 做 dot product, 然后经过 softmax. 这里的 dot product 其实不一定是 dot product, 任何可以表征两个向量 similarity 的都可以.
拿到 Attention map 之后, 还要再和 之前所有 token 的 value 做 dot product, 完成 weighted sum.
细心的你肯定观察到了, 这里面有两个 dot product, 而且没办法合并. 为什么呢? 主要是因为 softmax 是非线性的, 使得结合律不成立了.
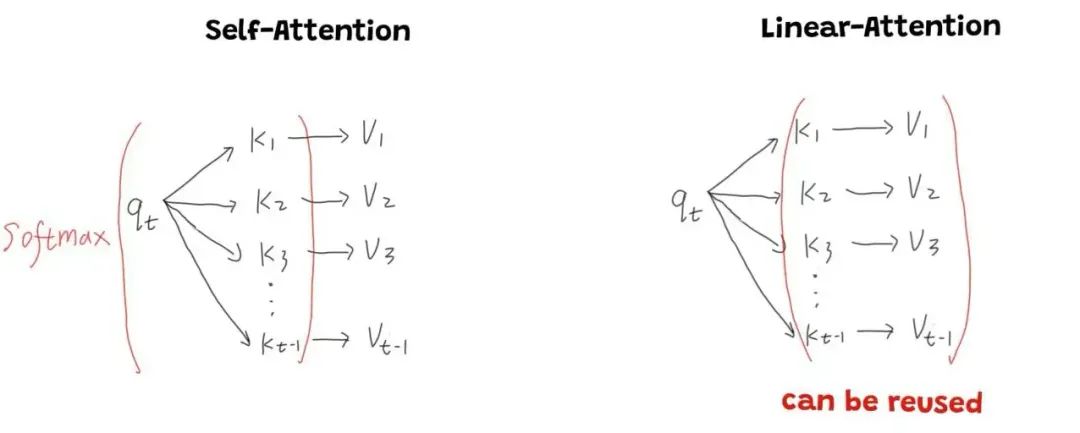
这两个 dot product 合并之后, 神奇的事情发生了, 右边括号里面的计算变得和 无关了, 这意味对于不同的 token, 我们可以 reused 这部分结果.


看到这里, 我们就明白作者给论文取名字的良苦用心了, “Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention”. 开始有 RNN 的 递归 那味了.
如果要把 Transformer 当成一种"特殊"的 RNN 来看, 那么:
-
传统 Transformer 中的 k, v cache 就相当于 hidden state, 一个超大的 hidden state. 而且使用这个 hidden state 需要的计算也不少 (前面讲过的 dot product + softmax + dot product). --> 这个点保证了 Transformer 抓取信息的能力.
更新这个 hidden state 则是直接往里面 append 新的东西, 换句话说这个 hidden state 的大小不断变大. --> 这个点保证了 Transformer 对于之前信息保留/记忆 的能力.

六、Attention Free Transformer
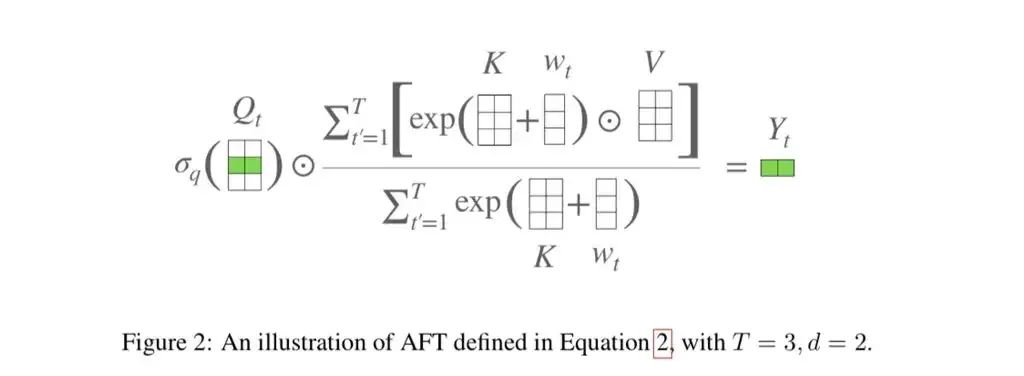
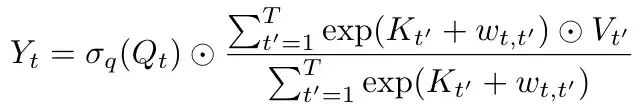
看到这里, 你大概就明白了, Attention-free 其实还是 Attention, 还是 weighted sum. 只不过这里面的 weight 不再是 query 和 key 之间做 dot product 算 similarity, 而是每个 key 和一个预定的偏置 , 这个偏置的作用类似于 positional embedding.
Attention-free 这个方法和前面的 Linear-Attention 相比, 是没办法写成递归形式的. 以第一个 token 为例,

从这个点看, Attention-free 的这个改动, 好像没有带来什么计算方面的优势.
所以 Attention-free 原文有提出了对 的一些不同改动, 其中一个改动就是把 通通置为 0. 这样一来, 上面说的不符合的两条又符合, 那么 Attention-free 其实又变回了 Linear-attention.
七、RWKV

八、对比
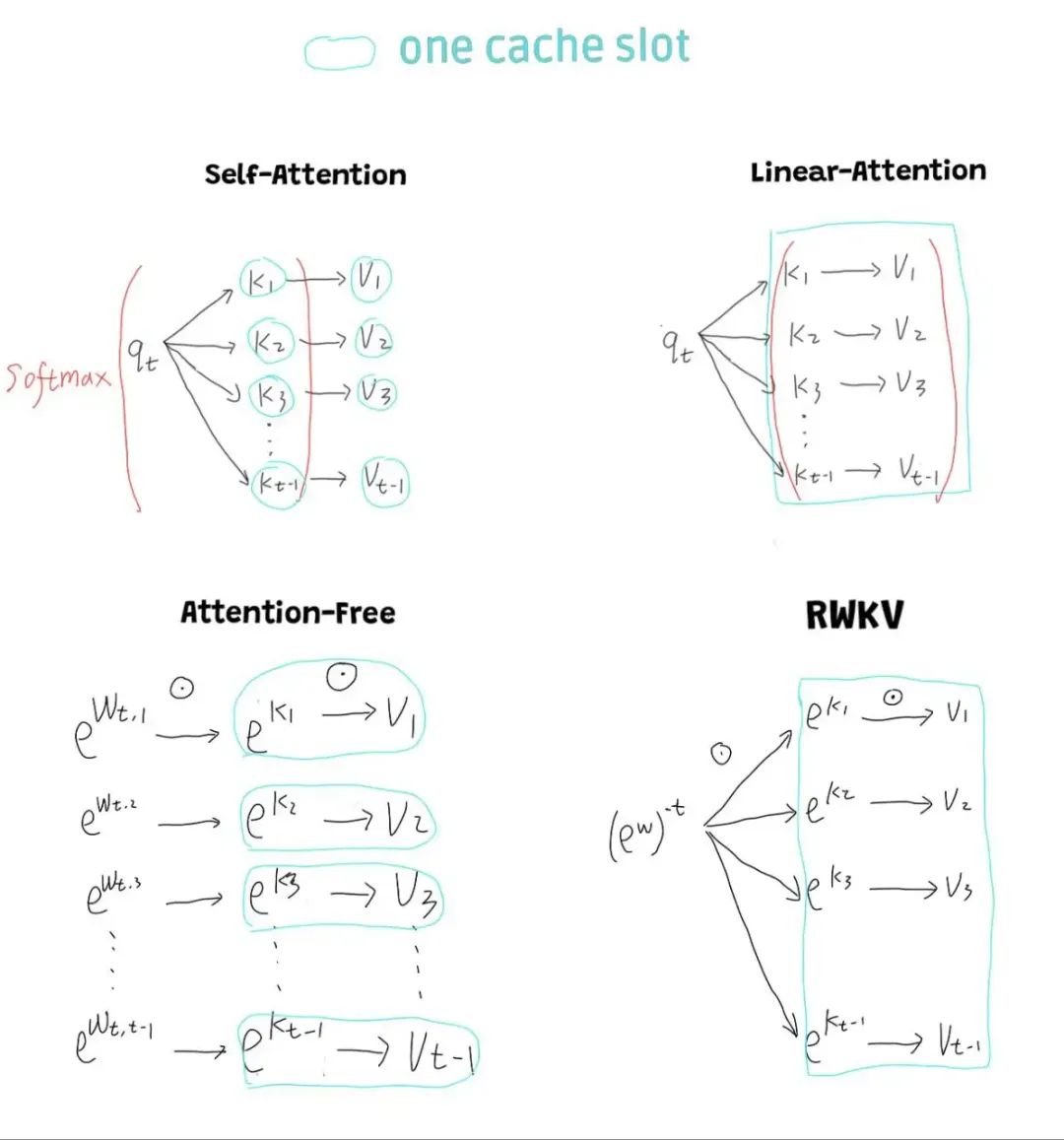
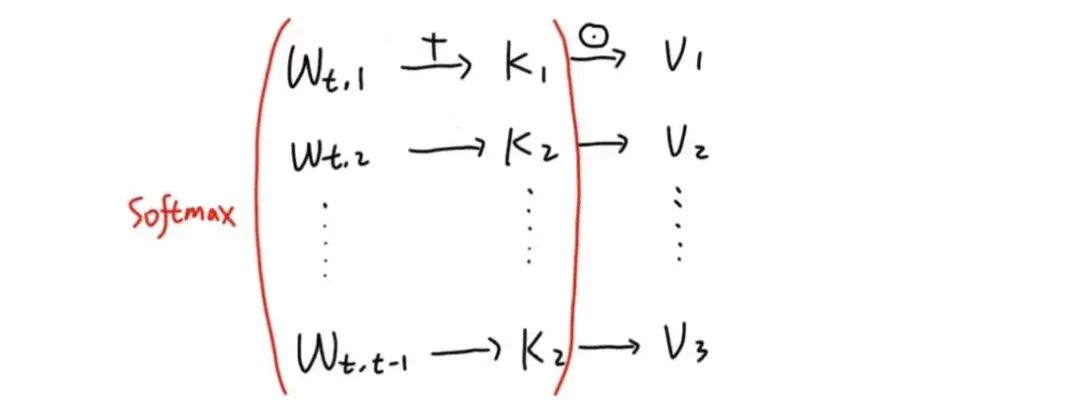
如果我们把 k v cache 当成 Transformer 的 hidden state, 可以看到 Transformer 的 hidden state 是随着 sequence 的长度增加而增加的.
那么所有致力于实现 Transformer <–> RNN (例如 Linear Attention 和 RWKV) 的工作都希望能够把 hidden state 变成固定大小. 他们实现的方式都是限制 token 之间 similarity 的可变性. 例如, 有两个 token A, B. 在 Transformer 里, 他们与第一个 token 之间的 similarity 可以是任意的. 而在其他工作中, 他们与第一个 token 之间的 similarity 必须一样.
引用链接
[1] 为什么现在的LLM都是Decoder only的架构: https://www.zhihu.com/question/588325646/answer/2940298964
[2] attention 隐式的编码了位置信息: https://arxiv.org/abs/2203.16634
九、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









