







近年来,多模态大模型(Multimodal Large Language Models, MLLMs)在人工智能领域取得了显著的进展,特别是在自然语言处理、计算机视觉和多模态理解方面。这些模型能够理解和生成多种类型的数据,如文本、图像、音频和视频,为多模态学习和应用提供了强大的工具。
今天给大家汇总了13个开源多模态大模型,这些模型在各自的领域中刷新了多个SOTA记录,每个模型都将附上相关的论文和代码,一起看看多模态大模型的最新研究成果吧!
论文PDF和开源代码都整理好了
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取🆓

架构和创新
1、NExT-GPT: Any-to-Any Multimodal LLM(ICLR 2024)
NExT-GPT:任意对任意多模态 LLM
简述:本文提出了通用任意对任意MM-LLM系统NExT-GPT,该系统将LLM与多模态适配器和不同解码器连接,使NExT-GPT能感知输入并以任意组合生成文本、图像、视频和音频输出。利用现有高性能编码器和解码器,NExT-GPT仅需少量参数(1%)进行调优,有利于低成本训练和扩展。此外,研究人员引入模态切换指令调优(MosIT),并整理高质量数据集,使NExT-GPT具备复杂跨模态语义理解和内容生成能力。

2、DreamLLM: Synergistic Multimodal Comprehension and Creation(ICLR 2024)
DreamLLM:协同多模态理解与创造
简述:本文提出了DreamLLM,这是一个学习框架,它首先实现了多功能多模态大型语言模型(MLLM),该模型强调了多模态理解和创作之间的协同作用。DreamLLM 通过直接在原始多模态空间中采样来生成语言和图像,避免了外部特征提取器的局限性。此外,它能够生成原始交错文档,包括文本、图像和非结构化布局。DreamLLM是首个能生成自由格式交错内容的MLLM,实验证明,它作为零样本多模态通才表现出色,从增强的学习协同作用中获益。
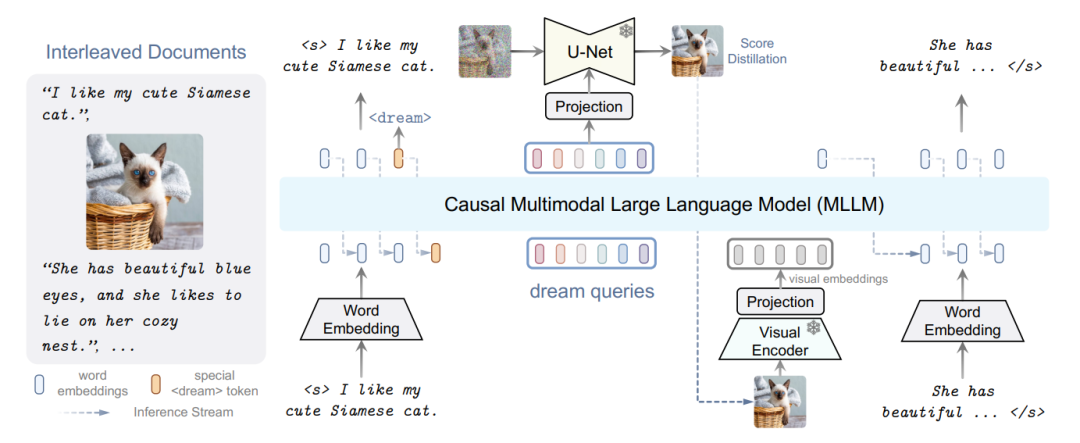
3、Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization(ICLR 2024)
具有动态离散视觉标记化的 LLM 统一语言视觉预训练
简述:本文提出了一种新的多模态大模型LaVIT,它通过将视觉内容转换为可被语言模型处理的离散标记,实现了视觉和语言数据的统一处理。这种方法打破了传统方法中将视觉输入仅作为提示的局限性,使LaVIT能够无差别地处理图像和文本,提高了模型在视觉语言任务中的性能。实验结果表明,LaVIT在处理大规模视觉语言任务方面优于现有模型。
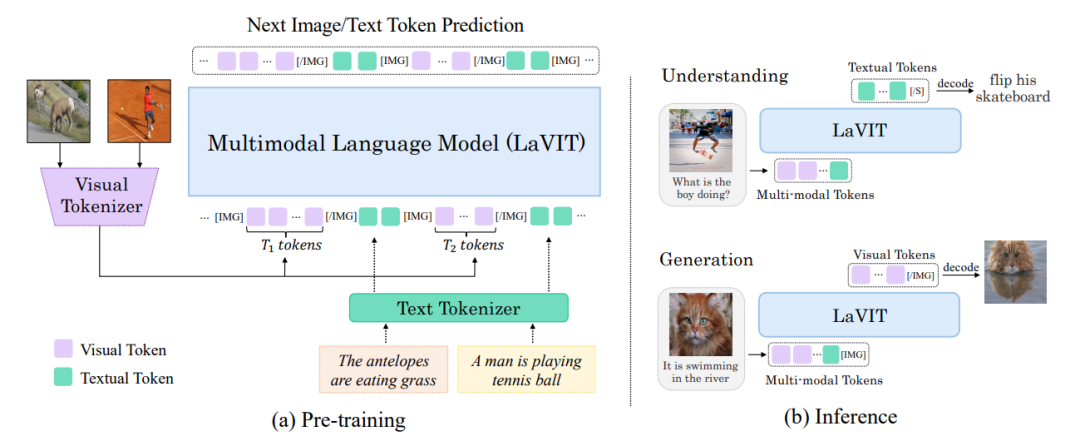
4、MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
MoE-LLaVA:大型视觉语言模型专家组合
简述:本文提出了一种名为MoE-tuning的新的大型视觉语言模型(LVLM)训练策略,该策略构建了一个参数数量多但计算成本恒定的稀疏模型,解决了多模态学习和模型稀疏性相关的性能下降问题。还提出了MoE-LLaVA框架,一种基于MoE的稀疏LVLM架构,它在部署期间只激活部分专家,从而减少了计算成本。实验表明,MoE-LLaVA在视觉理解方面表现出色,并减少了模型输出的幻觉。MoE-LLaVA使用30亿个稀疏激活的参数,在各种视觉理解数据集上性能与LLaVA-1.5-7B相当,甚至在某些基准测试中超过了LLaVA-1.5-13B。
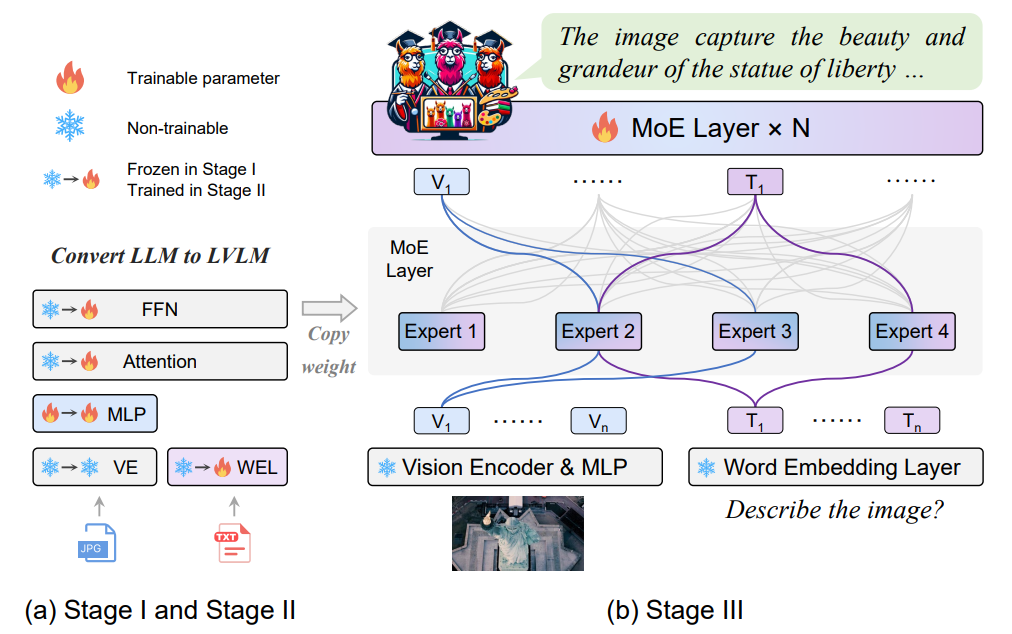
5、LEGO:Language Enhanced Multi-modal Grounding Model
语言增强型多模态接地模型
简述:现有的多模态模型重点捕捉每个模态内的全局信息,但忽视
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









