






自2021年ChatGPT发布以来,几个科技公司似乎都参与了AI的浪潮中,但是如今(2024)世界市值排名第2的Apple却一直“隐身”,直到WWDC24开完,世人才发现原来Apple也一直在AI领域发力。最近,Apple又研发出了一个解决模型更新后结果不一致情况的解决方案,名为MUSCLE。
目前模型的问题
在2023到2024年AI大模型大爆发以来,模型一直在不断的更新当中,但每次更新后可能因为一些原因,导致更新后的模型输出的结果跟以前的模型不一样的情况,被迫使用户为了得到相同的答案而适应新的模型版本,苹果的MUSCLE就是为了解决这个问题而产生的。
该策略的核心是通过训练一个兼容性适配器,使模型在更新后能够尽量保持与旧版本模型的兼容性,从而减少预测结果的不一致性,特别是减少所谓的“负翻转”现象。
什么是“负翻转”
论文(PDF):2407.09435 (arxiv.org)
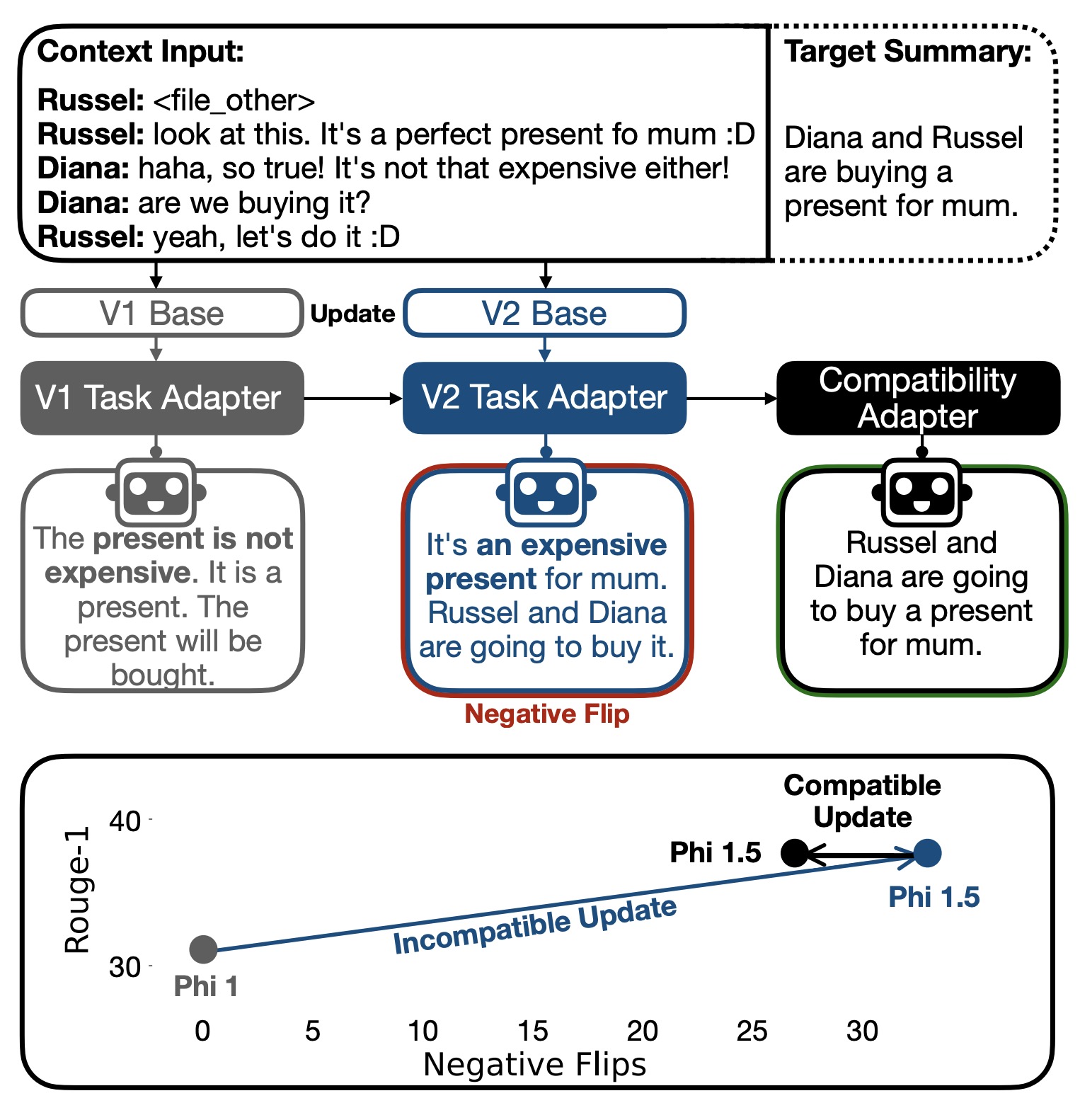
根据提供的PDF文档内容,"负翻转"(Negative Flips)是指在更新大型语言模型(LLMs)时出现的一种现象,即原本由旧模型正确预测或生成的实例,在新模型上变成了错误的预测或生成。这种现象对于用户来说可能会导致困惑和不满意,因为他们需要不断地适应新的模型行为。
负翻转的具体含义
-
定义:负翻转是指之前正确预测或生成的实例,在模型更新后变成了错误的预测或生成。
-
影响:这可能导致用户对模型的信任度下降,尤其是当用户已经对旧模型的行为有了心理预期时。
-
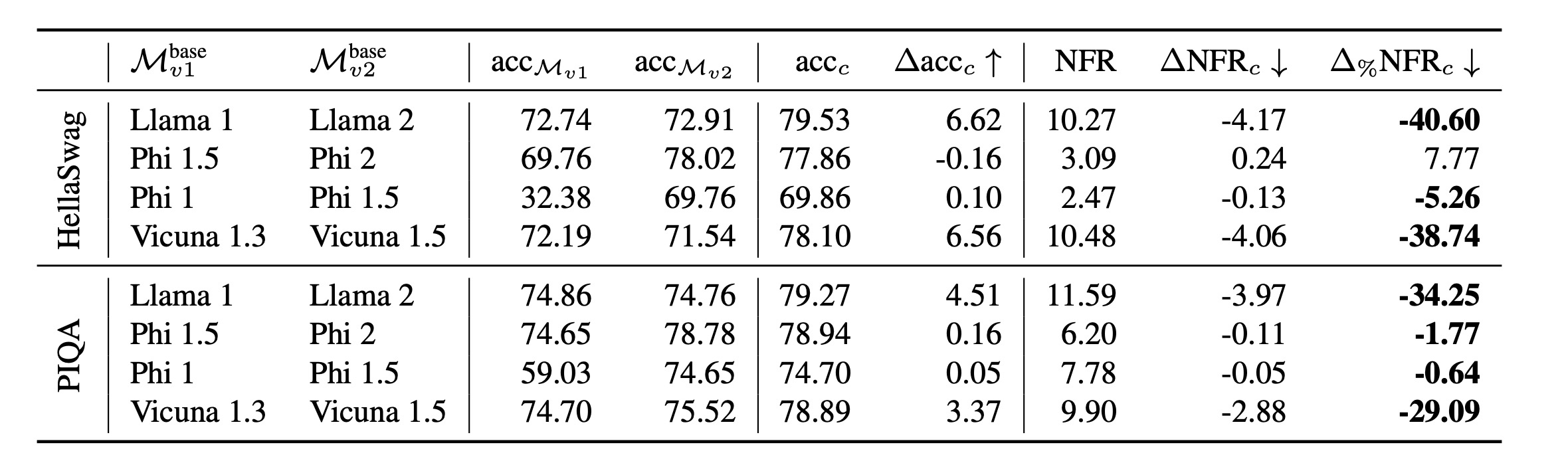
观察:研究发现,当旧模型和新模型之间的性能差距较小时,负翻转会更加明显。例如,在对话总结等生成任务中,连续评估指标(如ROUGE分数)对小的变化更加敏感,因此更容易观察到大量的负翻转。
相关实验结果
文档中提供了几个表格来展示不同模型更新前后负翻转的数量变化:
-
表3展示了使用MUSCLE方法训练的兼容任务适配器能够显著减少负翻转的数量。例如,在Llama 1到Llama 2的更新中,负翻转率从8.49%减少到了7.58%,减少了大约10.72%;在Vicuna 1.3到Vicuna 1.5的更新中,负翻转率从11.60%减少到了10.61%,减少了约8.53%。
-
表4显示了在数学问题评估中,MUSCLE方法同样减少了负翻转的数量,并且在大多数情况下保持了性能的提升。
-
表5进一步表明,在SAMsum总结任务中,MUSCLE方法能够降低ROUGE-1分数的回归率高达27%。
MUSCLE是如何解决的?
知识蒸馏
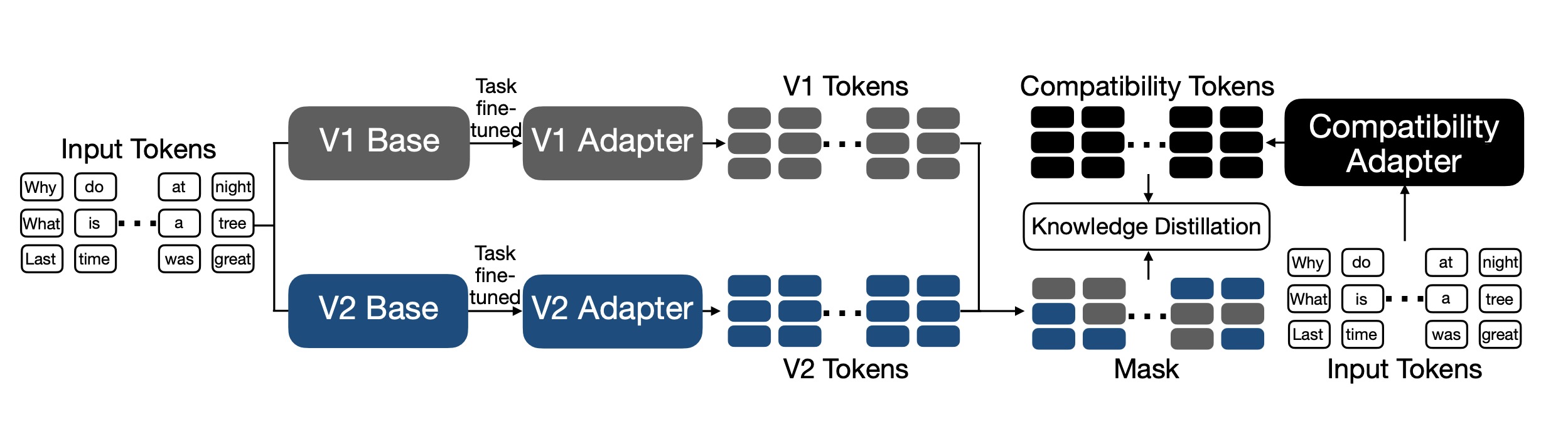
首先,我们采用知识蒸馏的方法,该方法通常用于将大型预训练模型的知识转移到较小的学生模型中。在这个场景下,学生模型(更新后的模型)和教师模型(旧版模型)都已经是经过预训练的模型。蒸馏的目标是在保持学生模型性能提升的同时,尽量减少负翻转。
MUSCLE旨在训练一个任务特化的微调模型,该模型既具有新版本模型的优点,又尽可能保持与旧版本模型的兼容性。具体步骤如下:
-
初始化兼容性适配器:首先,使用旧版模型的微调任务适配器来初始化兼容性适配器。
-
进一步微调:然后,利用任务训练数据集进一步微调兼容性适配器。微调的目标是使兼容性适配器在预测下一个词时与旧版模型或新版模型保持一致,具体取决于当前预测是否正确。
-
定义掩码:对于训练序列中的每个词,定义一个简单的掩码规则。如果兼容性适配器(正在训练的模型)的预测正确,则与新版模型对齐;如果预测不正确,则与旧版模型对齐。
-
定义微调损失:微调损失函数
Lmcomp是基于掩码规则定义的。如果兼容性适配器预测正确,则计算其与新版模型之间的Kullback-Leibler (KL) 散度;如果预测不正确,则计算其与旧版模型之间的KL散度。
掩码策略的实验分析
在实验部分,研究人员对比了几种不同的掩码策略,以评估设计选择的效果。以PIQA数据集和从Llama 1到Llama 2的模型更新为例,进行了以下分析:
-
基于似然的掩码策略:这种策略考虑了当前模型和旧模型预测下一个词的似然性。只有当当前模型预测的正确词的似然性低于旧模型时,才与旧模型对齐,否则与新模型对齐。这种方法在以log-likelihood评估的任务(例如PIQA)中可能特别有用。
-
基于序列的掩码策略:另一种方法是检查整个序列的似然性,而不是单个词。在这种情况下,如果整个序列的似然性较低,则所有词都会被掩码,以与旧模型对齐。
-
只在旧模型正确时对齐:还有一种策略仅在旧模型正确预测时与之对齐。
-
无掩码的对齐:另一种极端情况是完全与旧模型对齐,不使用任何掩码。
评价指标
MUSCLE 定义了负翻转率(Negative Flip Rate, NFR)
-
定义:对于一个实例 𝑥𝑖x**i,如果新版本模型 𝑀𝑣2M**v2 的预测 𝑀𝑣2(𝑥𝑖)M**v2(x**i) 与地面真实标签 𝑦𝑖y**i 不一致,并且新旧版本模型 𝑀𝑣1M**v1 和 𝑀𝑣2M**v2 的预测不同,那么就发生了一个负翻转。
-
公式:𝑁𝐹𝑚𝑐(𝑥𝑖)≜[𝑀𝑣2(𝑥𝑖)≠𝑦𝑖]∧[𝑀𝑣1(𝑥𝑖)≠𝑀𝑣2(𝑥𝑖)]NFm**c(x**i)≜[M**v2(x**i)\=y**i]∧[M**v1(x**i)\=M**v2(x**i)]
-
总体负翻转率:𝑁𝐹𝑅𝑚𝑐=1𝑁∑𝑖=1𝑁1[𝑁𝐹𝑚𝑐(𝑥𝑖)]NFRm**c=N1∑i=1N1[NFm**c(x**i)]
扩展评价指标
MUSCLE 提出了一系列扩展评价指标来评估模型更新,特别是在生成任务中。
模型更新时样本的四种可能性
在模型更新时,每个样本可能出现以下四种情况。这些情况被分为四个象限(Quadrants),分别表示正翻转、负翻转以及其他情况。
象限 1(Quadrant 1)
情况:新旧模型都正确。
意义:这表示模型更新没有影响到该样本的正确预测,保持了一致性。
象限 2(Quadrant 2)
情况:旧模型错误,新模型正确。
意义:这是正翻转,表示模型更新带来了性能提升。此类情况越多,说明模型更新越成功。
象限 3(Quadrant 3)
情况:新旧模型都错误。
意义:虽然模型在这个样本上的表现都不正确,但如果新旧模型在错误上保持一致(即犯相同的错误),这有助于用户更容易适应模型更新。这是因为用户可能已经开发了应对模型错误的方法,一致性的错误可以减少用户的不适感。
象限 4(Quadrant 4)
情况:旧模型正确,新模型错误。
意义:这是负翻转,表示模型更新导致了性能下降。这种情况会降低用户满意度,应尽量减少。

1. 多选项任务中的负翻转扩展
对于多选项任务,MUSCLE 扩展了负翻转的概念来捕获实例中两个模型都不正确,但行为发生了变化的情况。这可以通过扩展负翻转率公式来实现。
-
扩展负翻转率:𝑁𝐹𝑚𝑐(𝑥𝑖)≜[𝑀𝑣2(𝑥𝑖)≠𝑦𝑖]∧[𝑀𝑣1(𝑥𝑖)≠𝑀𝑣2(𝑥𝑖)]NFm**c(x**i)≜[M**v2(x**i)\=y**i]∧[M**v1(x**i)\=M**v2(x**i)]
-
多选项负翻转率:𝑁𝐹𝑅𝑚𝑐=1𝑁∑𝑖=1𝑁1[𝑁𝐹𝑚𝑐(𝑥𝑖)]NFRm**c=N1∑i=1N1[NFm**c(x**i)]
2. 连续评价指标
对于生成任务(如摘要生成),由于没有多个选择项可供比较,需要采用连续评价指标来评估模型更新的影响。
-
连续负翻转:对于生成任务,需要考虑实例的性能增益或退化,而不仅仅是是否发生了翻转。
-
评价方法:MUSCLE 使用诸如 ROUGE 或 BERTScore 这样的连续评价指标来衡量生成文本的质量,以此来评估兼容性。
-
目标:在更新模型时,不仅要避免性能的下降,还要尽量保持与用户的预期一致。
















 5512
5512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











