







Hive数据模型
Hive的数据模型主要由表构成,包括内部表,外部表,分区表和桶表。我也将从这四个方面介绍。
在这之前先介绍另外一个概念:DDL,Data Definition Language数据定义语言,是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言。核心语法由CREATE, ALTER, DROP三个组成。DDL并不涉及表内部数据的操作, 也就是不涉及DELETE之类的。
- 内部表Table
表的创建过程和数据加载过程可以在同一个语句中完成,当删除表时,表中的数据和元数据将一同被删除。
//创建表
create table stu(
id int,
name string,
age int,
gender string
)
row format delimited fields terminated by "," //以’,'结尾的行格式分隔字段
location "hdfs://datalocation";
- 外部表External Table
外部表是一个过程,表的创建和加载是同时完成的,但是外表中真正的数据不是放在自己表所属的目录中,而是存储在指定的HDFS路径中。因此删除外部表,并不删除实际的数据,只是删除相应的元数据。
//创建表
create external table stu(
id int,
name string,
age int,
gender string
)
row format delimited fields terminated by ","
location "hdfs://datalocation";
- 分区表Partition Table
分区表是指在创建表时指定的Partition的分区空间。Hive引入分区表的目的是可以让查询发生在小范围的数据上,避免扫描整个表内容,从而提高了数据查询效率。
create table if not exists stu(
id int,
name string,
age int,
gender string
)
row format delimited fields terminated by ","
location ""
partition by id int;
一个表可以有一个或多个分区;分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段。
- 桶表Bucket Table
桶是更为细粒度的数据范围划分。桶是对数据文件本身来拆分数据,而表和分区则是基于目录级别的拆分数据。使用桶的表回将元数据文件按一定规律拆分成多个文件。Hive引入桶表的目的是为了获得更高的查询处理效率,它能使一些特定的查询效率更高,如对于具有相同的桶划分并且Join的列刚好就是在桶里的连接查询等。
create table stu(
id int,
name string
)
row format delimited fields terminated by ","
clustered by(id) into 4 buckets;
桶的数量是用户自定义的,Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
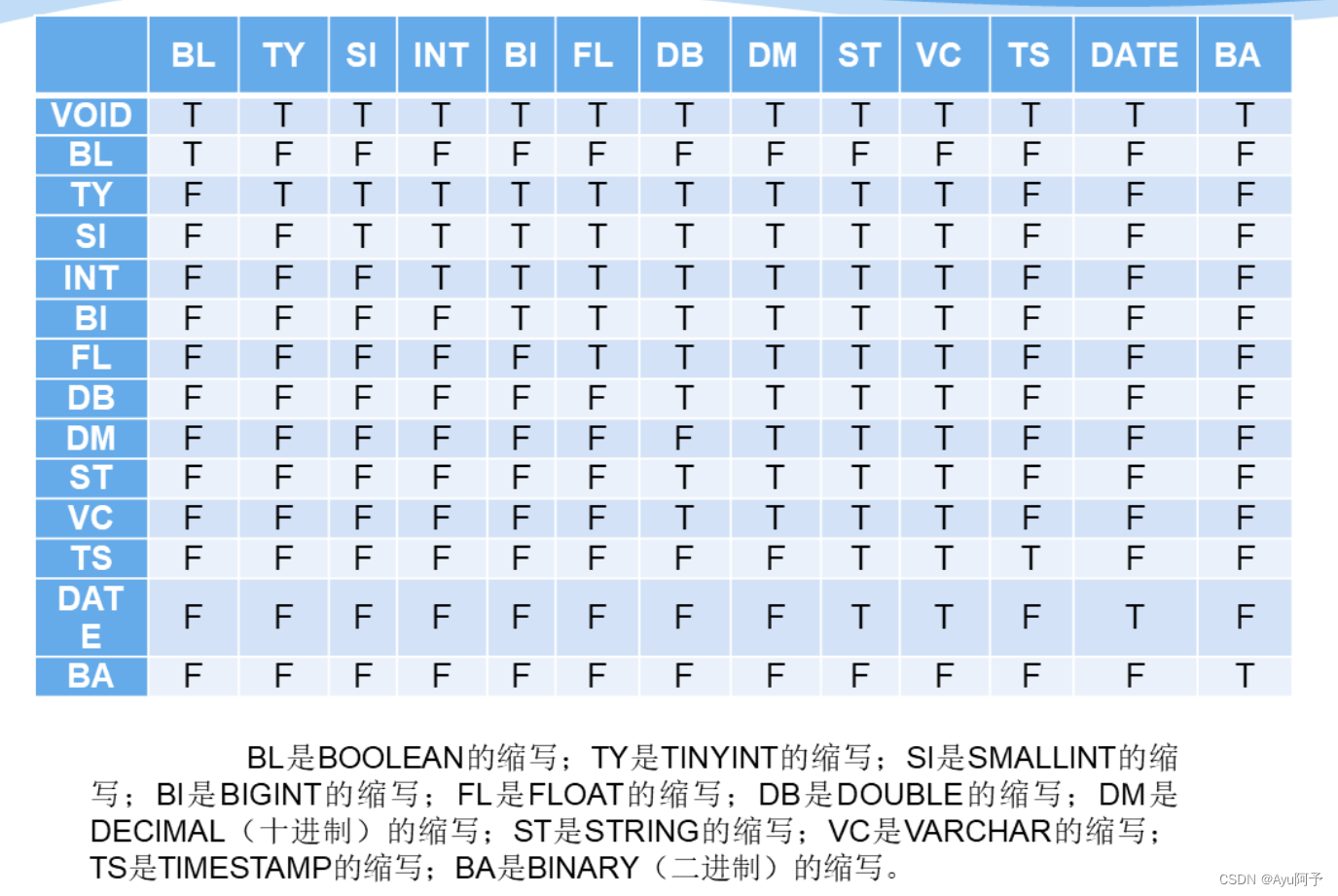
数据类型
除了关系型数据库支持的基本数据类型外,Hive还支持关系型数据库很少出现的四种复杂数据类型:数组,映射,结构体,联合体。
数据类型转换
















 2795
2795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











