









论文笔记 之 Every Frame Counts: Joint Learning of Video Segmentation and Optical Flow)
1,本文解决的问题
问题1:
已有方法主要有两类:
1,重用之前帧的特征,提高速度
2,通过光流或序列模型来建模多帧,提高精度
这两种方法均牺牲了速度和精度中的一者,换取另一者。
通过光流研究语义特征空间的时间一致性。
将语义分割与光流估计联合起来。语义信息帮助提高遮挡区域的光流估计,非遮挡区域的光流为语义分割提供像素级别的时间关联,从而提高语义分割的光流一致性。这其实是利用了语义的空间一致性和光流的时间一致性来互相提高对方。
问题2:
已有的模型往往利用连续两帧的特征实现更好的语义分割,但现有的数据集往往只标注视频中一部分帧,所以这些方法只能利用数据集中很小的一部分。而且它们往往还需要额外的数据来预训练光流。
模型能够通过同时训练光流和语义分割,充分利用视频中标注和未标注的数据,这降低了对数据集的要求。这应该是第一个能够同时端到端的训练光流和视频语义的框架。
2,本文采用的策略:
其实本文还是属于利用帧间信息提高分割精度的一类。
本文通过精心设计的网络结构和误差方程,实现了同时训练光流和语义分割,并能够使两者相互促进。从而提高精度。另外本文的光流采用自监督训练(两帧图像互相warp,然后比较),所以能够利用没有标记的数据,降低了对数据集的要求。
3,本文模型的结构:
模型主要包含三部分网络:Shared encoder、Flow Branch(Flow decoder)、 Segmentation Branch(semantic decoder),如图FIgure2所示。

输入是两帧图像Ii和Ii+t,通过同一个卷积网络shared encoder提取特征,然后将特征分别输入到Flow Branch和Segmentation Branch。
本文模型在多个尺度上进行了相同的操作,图Figure2显示了三个尺度,下面只对其中一个尺度解析。
Flow Branch在每个尺度上输出的是该尺度的光流图:Fi->i+t、Fi+t->i和遮挡Mask:Oi、Oi+t(在公式中的标记是Oest),表征相应光流图中相应位置是遮挡造成的错误(值越接近1说明错误概率越大)
Segmentation Branch在每个尺度上输出的特征图是Si和Si+t,分别对应Ii和Ii+t。
同时Segmentation Branch也输出该尺度上的语义分割图Mi和Mi+t。可能Si和Si+t就是Mi和Mi+t?
本文是通过误差方程来沟通光流和语义,实现相互促进的,在每个尺度上有以下5个误差:
1,Emporal Consistency Loss(时间一致性误差):Lcons
Lcons,表征光流估计(相对于中间层特征)的误差,是光流自监督的核心。其计算公式如(1)(2),注意是双向的i到i+t,i+t到i。
这里要说明一点,光流估计的误差有两个来源:
1,是由于遮挡(物体运动、相机视角变化)造成图片不匹配,引起的误差;
2,是纯粹的光流误差。
本文在计算Lcons时,由于采用了遮挡Mask:Oest,所以Lcons中只包含光流估计的纯粹的光流误差,不包含由遮挡引起的光流估计误差。
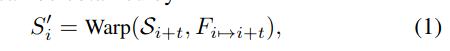
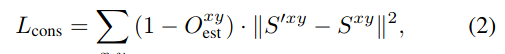
Occlusion Loss(遮挡误差):Locc
Locc,表征模型对遮挡的预测的误差。
其采用交叉熵函数,计算公式如公式(4):
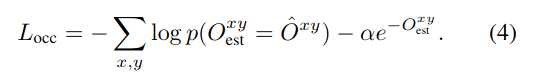
其中Oest如前所述,是网络预测的,而O^ 作为Oest的真实值,是由Fi->i+t、Fi+t->i计算来的:光流图中保存的是特征图相应坐标的偏移量,如果某个位置的坐标加上其偏移量后获得的新坐标不在[0,w)和[0,h)范围内(即超出特征图范围),则O^相应位置为1。
由此可见Locc和Lcons是耦合的,会使得网络有将所有位置的光流判定为误差过大(即,防止Oest每个元素都接近1)的倾向。于是在Locc增加了惩罚项(-后面的部分)
注意,Locc也是双向的。
photometric(光度):Lpm
这部分没有很看懂。。。
Lcons,表征光流估计(相对于原图Ii和Ii+t)的误差。
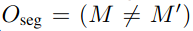
Oseg:是直接用M和经过光流Warp的M’,计算的,因而其表征了前面提到的两部分光流误差

Oerror,表征光流估计的纯粹的光流误差
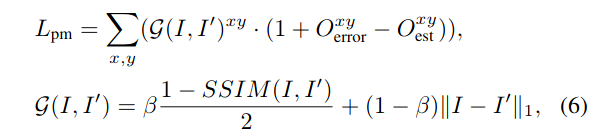

Smoothness Loss(平滑误差):Lsm
没看懂。。。

Semantic Segmentation Loss:Lseg
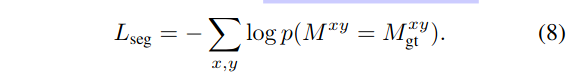














 351
351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









