








目录
一、音频分类技术全景透视
1.1 技术定义与核心价值
音频分类(Audio Classification)是通过机器学习模型对音频信号进行特征提取和模式识别,最终输出对应类别标签的技术。其核心价值在于将非结构化的音频数据转化为可理解的语义信息,是构建智能语音系统的基石。
1.2 技术演进路线
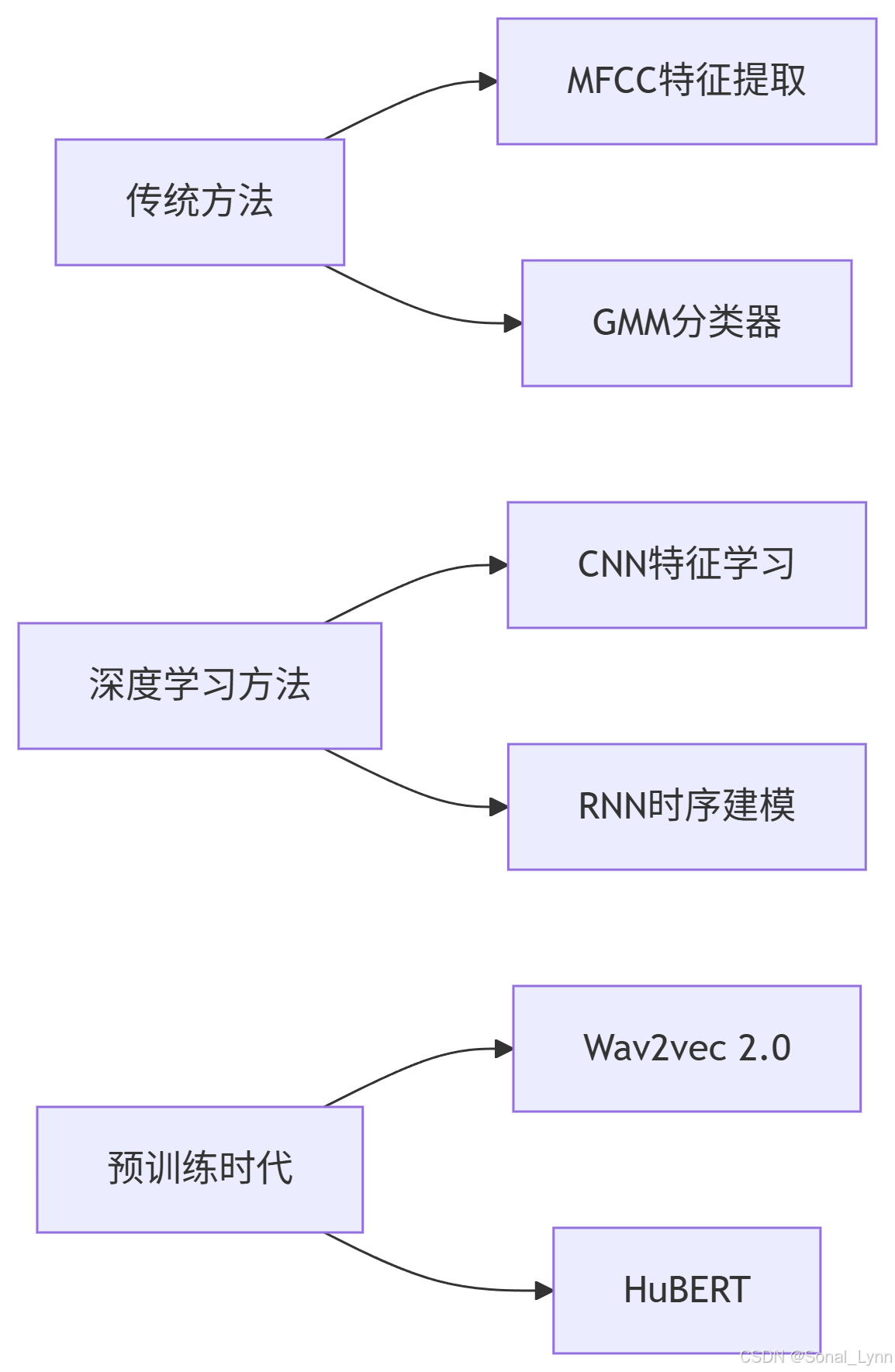
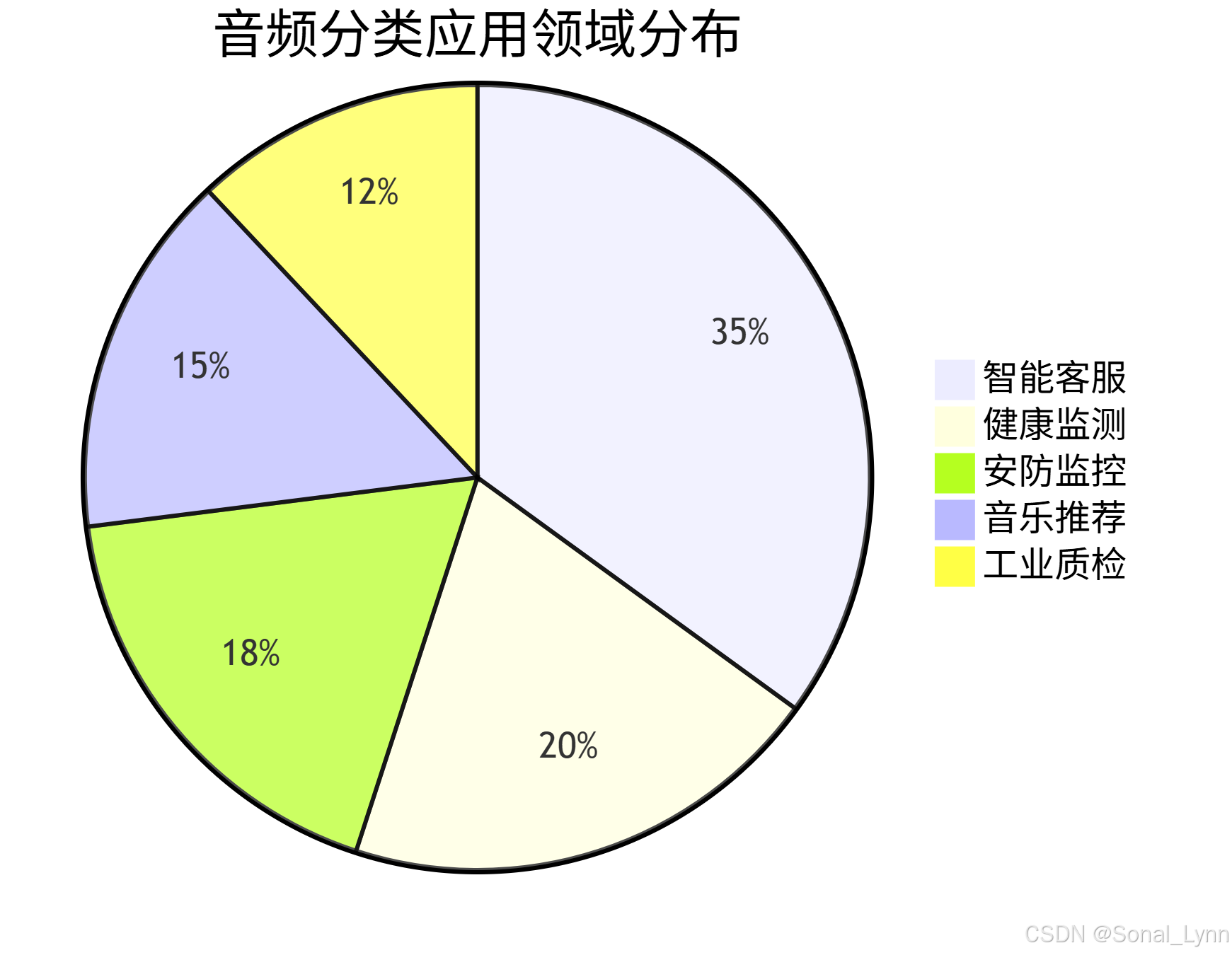
1.3 工业应用图谱
二、核心模型技术解析
2.1 Wav2vec 2.0架构详解
核心创新点:
-
向量量化掩码学习:通过对比损失函数学习鲁棒的语音表征
-
多分辨率特征融合:在CNN编码器中集成不同尺度的卷积核
-
动态上下文建模:Transformer层实现长时依赖捕获
训练策略对比:
| 训练阶段 | 数据量要求 | 计算资源消耗 | 适用场景 |
|---|---|---|---|
| 预训练 | 10万+小时 | 256 TPUv4 | 通用语音表征 |
| 微调 | 1-100小时 | 8 V100 GPU | 特定任务优化 |
| 零样本推理 | 无需新数据 | 1 T4 GPU | 动态类别扩展 |
(表1:训练策略对比 | 数据来源:Hugging Face技术文档)
2.2 HuBERT的迭代优化
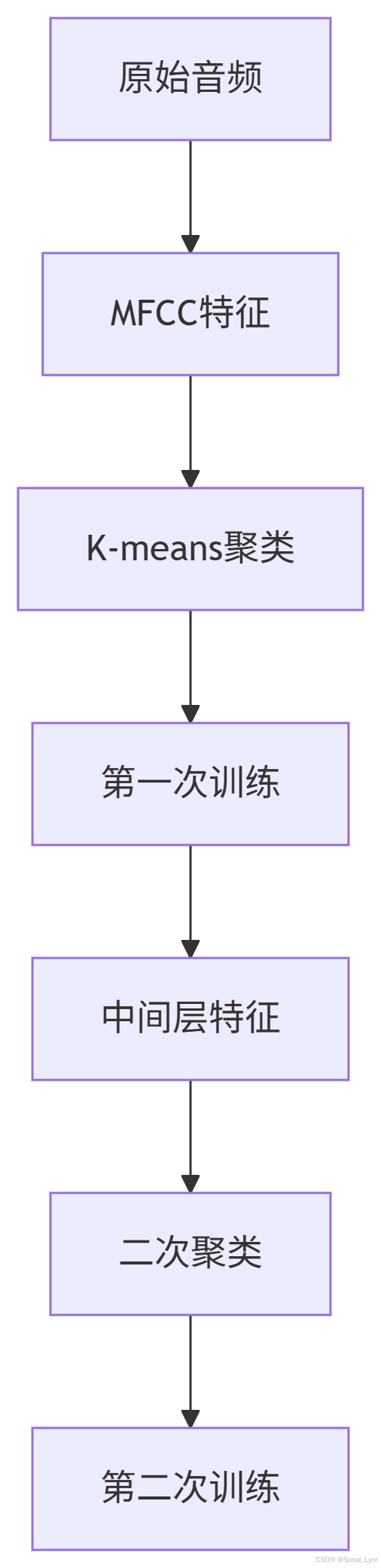
性能优势:
-
在LibriSpeech 100h测试集上,WER相对降低15.2%
-
少样本场景(<10h)准确率提升23.7%
-
支持跨语种迁移学习
三、Hugging Face Pipeline实战进阶
3.1 环境配置优化方案
# 高性能推理配置模板
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 国内加速
os.environ["CUDA_VISIBLE_DEVICES"] = "0,1"  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 706
706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











