







工作需要,要爬取新浪微博数据,之前一直用java, 但是遇到页面加密很伤,转到python。先拿糗事百科试试python里爬虫的写法。
工具
requests
BeautifulSoup
工具参考
Python爬虫利器一之Requests库的用法
Python爬虫利器二之Beautiful Soup的用法
还有一个据说比较好用的PyQuery, 试用了下,难用的要死!class 里有空格就懵逼了。之前在Java里一直用Jsoup解析,比较顺手,相应的感觉比较适应于BeautifulSoup,废话不多说,搞起!
页面结构
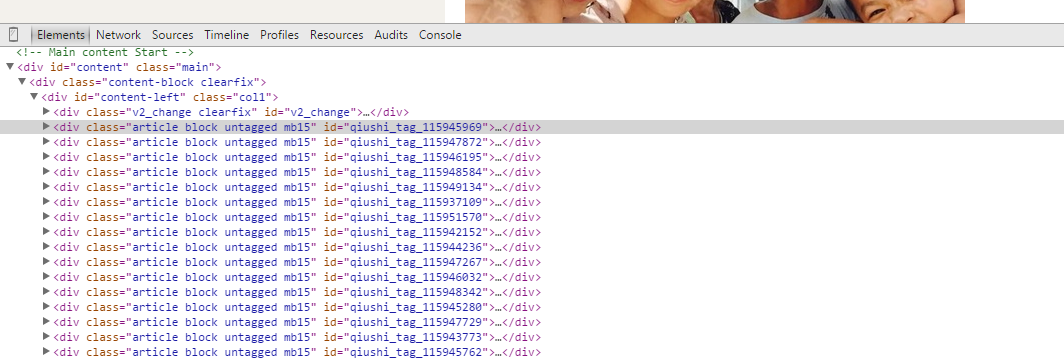
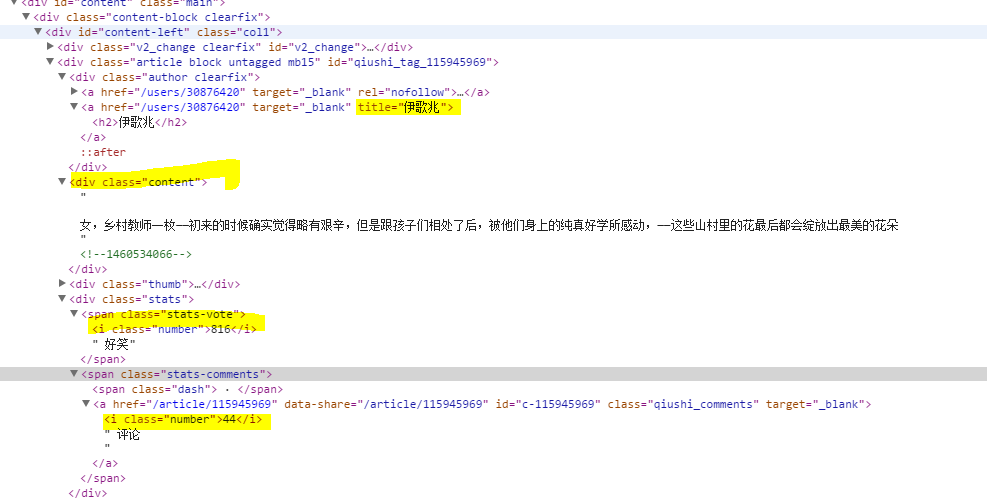
代码
import requests
from bs4  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









