






文章目录
前言
本人小白一个,叙述过程中有不对的地方请加以指正,前一段时间偶然配置在好IA-SSD运行环境。一来为了复盘,二为了以后自己有个参考,在此从头重新配置一次。
最终环境cuda11.1 pytorch 1.8.1 spconv2.x
一、电脑硬件以及环境配置
硬件:显卡RTX3070
软件环境:cuda11.1以及anconda
注:1 虽然在虚拟环境中安装pytorch的时候会安装cuda相关选项,不过据本人观察还是会依靠大环境的cuda的相关软件,建议提前安装上cuda 。
2 cmake版本不要太旧,记得提前升级好
二、大环境参考资料
为了避免本人重复造轮子,本人这里给出相关链接
1.cuda
注意:保持显卡算力,显卡驱动,cuda版本兼容
首先驱动上显示的cuda版本号是自己目前的驱动可以兼容的最高cuda,其次显卡限制了cuda最低版本(当然也限制最高版本),如果cuda版本太低,也是不行的。
总结:显卡驱动和显卡限制了cuda的最高版本,显卡限制了cuda的最低版本(显卡驱动应该也限制最低吧,没做实验,不敢瞎说)
比如:硬件RTX3070
安装好驱动,输入nvidia-smi 出现
NVDIA-SMI 530.41.03 Driver Version: 530.41.03 CUDA Version: 12.1
则我的cuda最高12.1 ,本人安装的是cuda11.1,也曾尝试安装cuda10.2,这是不兼容的
教程:请百度
2. anconda
安装conda
conda常用指令
本人是安照这个教程安装的
三、 配置IA-SSD开发环境
1.建立conda环境
conda create --name dxpIA-SSD python=3.8
conda activate dxpIA-SSD
2.配置 pytorch
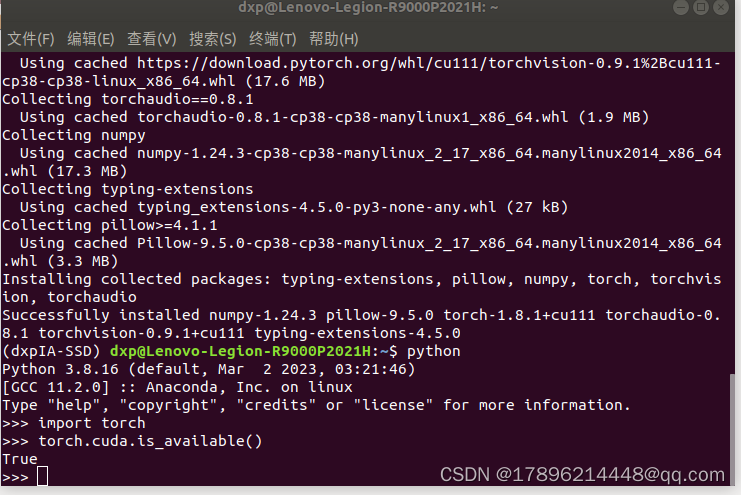
pip install torch==1.8.1+cu111 torchvision==0.9.1+cu111 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
安装完毕后,验证是否成功
python
import torch
torch.cuda.is_available()
返回true,说明安装成功
 按键ctrl+z 返回,继续安装spconv
按键ctrl+z 返回,继续安装spconv
3. 安装spconv
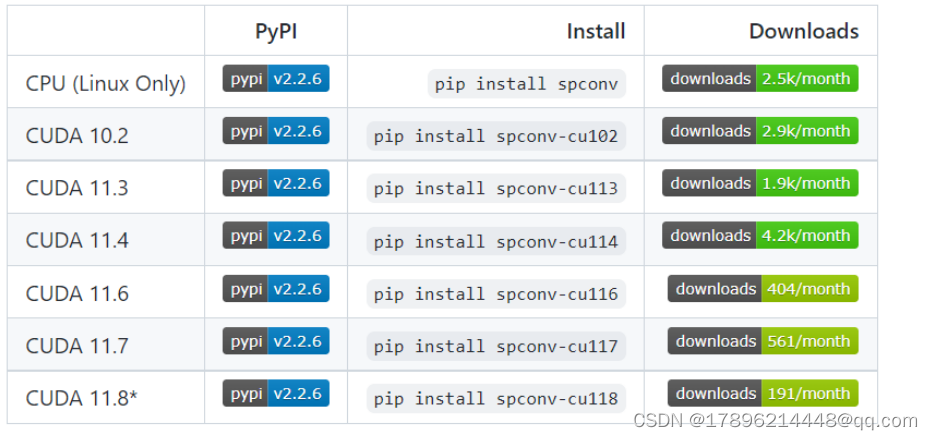
pip install spconv-cu111
验证
python
import spconv
没有输出则安装完毕
4 下载 IA-SSD 源码
git clone https://github.com/yifanzhang713/IA-SSD.git && cd IA-SSD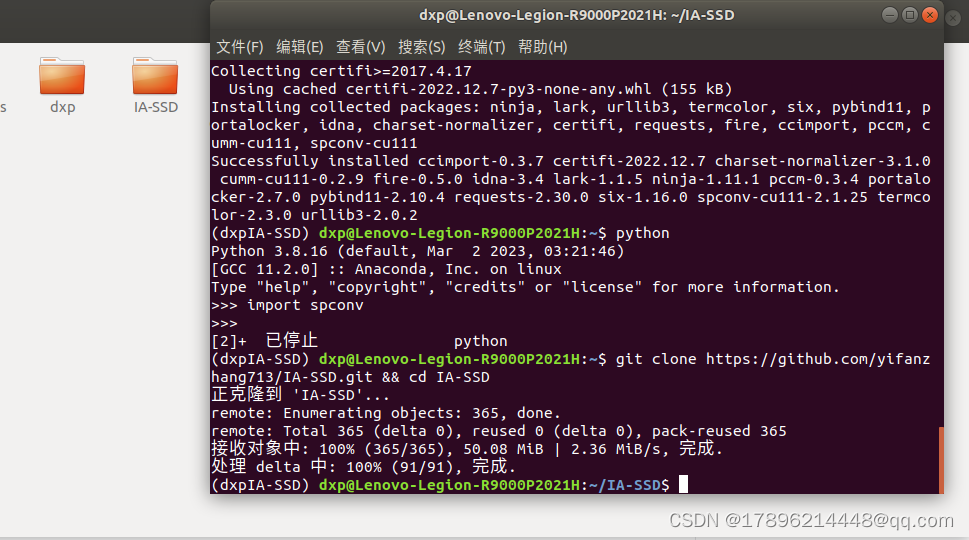
pip install -r requirements.txt
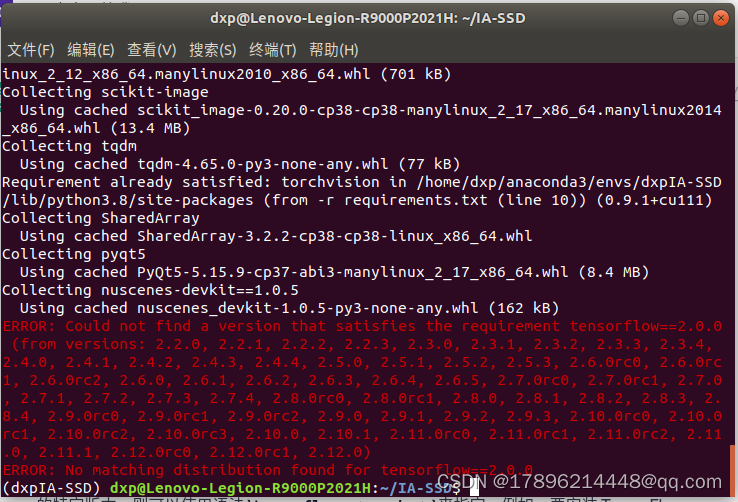
pip install tensorflow
安装完毕后,依旧报错 直接运行下句(这里是tensonrflow 直接跳过应该问题不大)
python setup.py develop
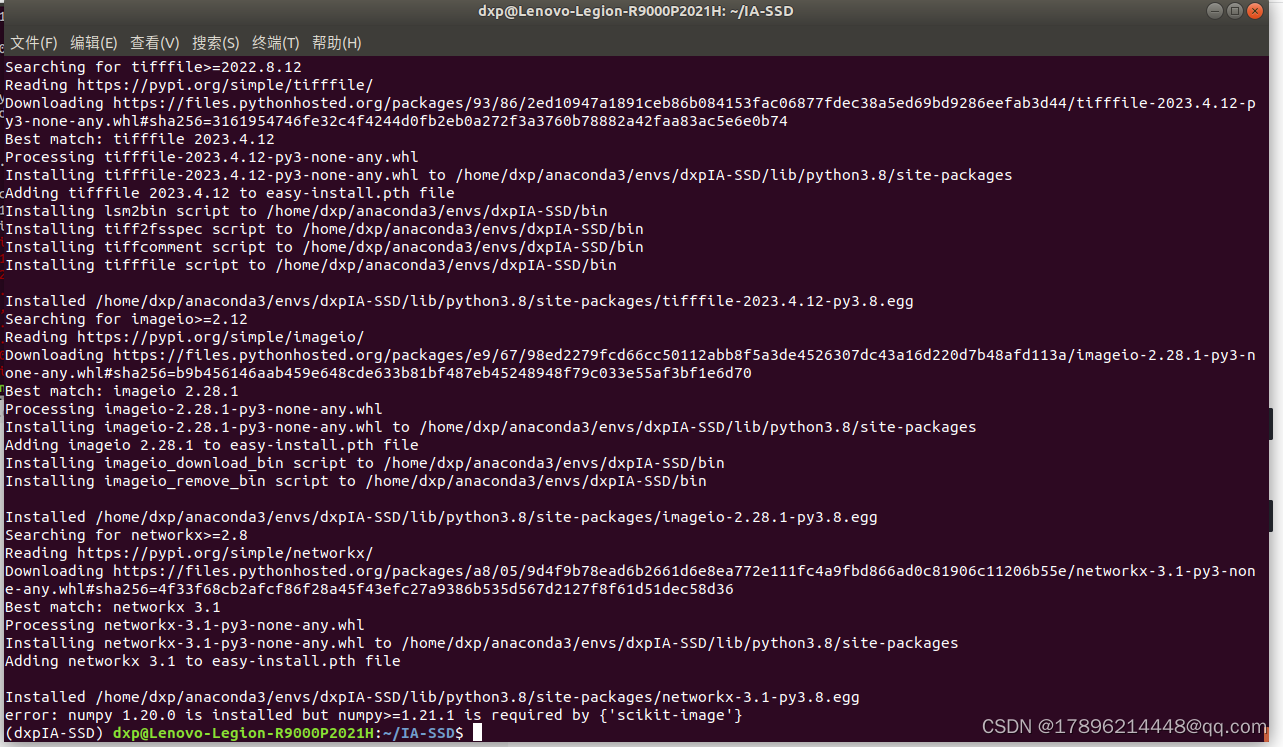
有点小错误,安装numpy 1.24.3
pip install numpy==1.24.3
安装open3d
pip install open3d
pip install mayavi
运行 demo.py
我的版本还要安装
pip install kornia==0.5.10
(本教程适用于OpenPCDet)
3D框的插件
sudo apt-get install ros-melodic-jsk-recognition-msgs
sudo apt-get install ros-melodic-jsk-rviz-plugins
import argparse
import glob
from pathlib import Path
try:
import open3d
from visual_utils import open3d_vis_utils as V
OPEN3D_FLAG = True
except:
import mayavi.mlab as mlab
from visual_utils import visualize_utils as V
OPEN3D_FLAG = False
import numpy as np
import torch
from pcdet.config import cfg, cfg_from_yaml_file
from pcdet.datasets import DatasetTemplate
from pcdet.models import build_network, load_data_to_gpu
from pcdet.utils import common_utils
class DemoDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None, ext='.bin'):
"""
Args:
root_path:
dataset_cfg:
class_names:
training:
logger:
"""
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger
)
self.root_path = root_path
self.ext = ext
data_file_list = glob.glob(str(root_path / f'*{self.ext}')) if self.root_path.is_dir() else [self.root_path]
data_file_list.sort()
self.sample_file_list = data_file_list
def __len__(self):
return len(self.sample_file_list)
def __getitem__(self, index):
if self.ext == '.bin':
points = np.fromfile('/home/dxp/dxp/IA-SSD/data/kitti/training/velodyne/007303.bin', dtype=np.float32).reshape(-1, 4)
elif self.ext == '.npy':
points = np.load(self.sample_file_list[index])
else:
raise NotImplementedError
input_dict = {
'points': points,
'frame_id': index,
}
data_dict = self.prepare_data(data_dict=input_dict)
return data_dict
def parse_config():
parser = argparse.ArgumentParser(description='arg parser')
parser.add_argument('--cfg_file', type=str, default='cfgs/kitti_models/second.yaml',
help='specify the config for demo')
parser.add_argument('--data_path', type=str, default='demo_data',
help='specify the point cloud data file or directory')
parser.add_argument('--ckpt', type=str, default=None, help='specify the pretrained model')
parser.add_argument('--ext', type=str, default='.bin', help='specify the extension of your point cloud data file')
args = parser.parse_args()
cfg_from_yaml_file(args.cfg_file, cfg)
return args, cfg
def main():
args, cfg = parse_config()
logger = common_utils.create_logger()
logger.info('-----------------Quick Demo of OpenPCDet-------------------------')
demo_dataset = DemoDataset(
dataset_cfg=cfg.DATA_CONFIG, class_names=cfg.CLASS_NAMES, training=False,
root_path=Path(args.data_path), ext=args.ext, logger=logger
)
logger.info(f'Total number of samples: \t{len(demo_dataset)}')
model = build_network(model_cfg=cfg.MODEL, num_class=len(cfg.CLASS_NAMES), dataset=demo_dataset)
model.load_params_from_file(filename='IA-SSD.pth', logger=logger, to_cpu=True)
model.cuda()
model.eval()
with torch.no_grad():
for idx, data_dict in enumerate(demo_dataset):
logger.info(f'Visualized sample index: \t{idx + 1}')
data_dict = demo_dataset.collate_batch([data_dict])
load_data_to_gpu(data_dict)
pred_dicts, _ = model.forward(data_dict)
V.draw_scenes(
points=data_dict['points'][:, 1:], ref_boxes=pred_dicts[0]['pred_boxes'],
ref_scores=pred_dicts[0]['pred_scores'], ref_labels=pred_dicts[0]['pred_labels']
)
if not OPEN3D_FLAG:
mlab.show(stop=True)
logger.info('Demo done.')
if __name__ == '__main__':
main()
经过自己修改完的以后直接输入
python demo.py
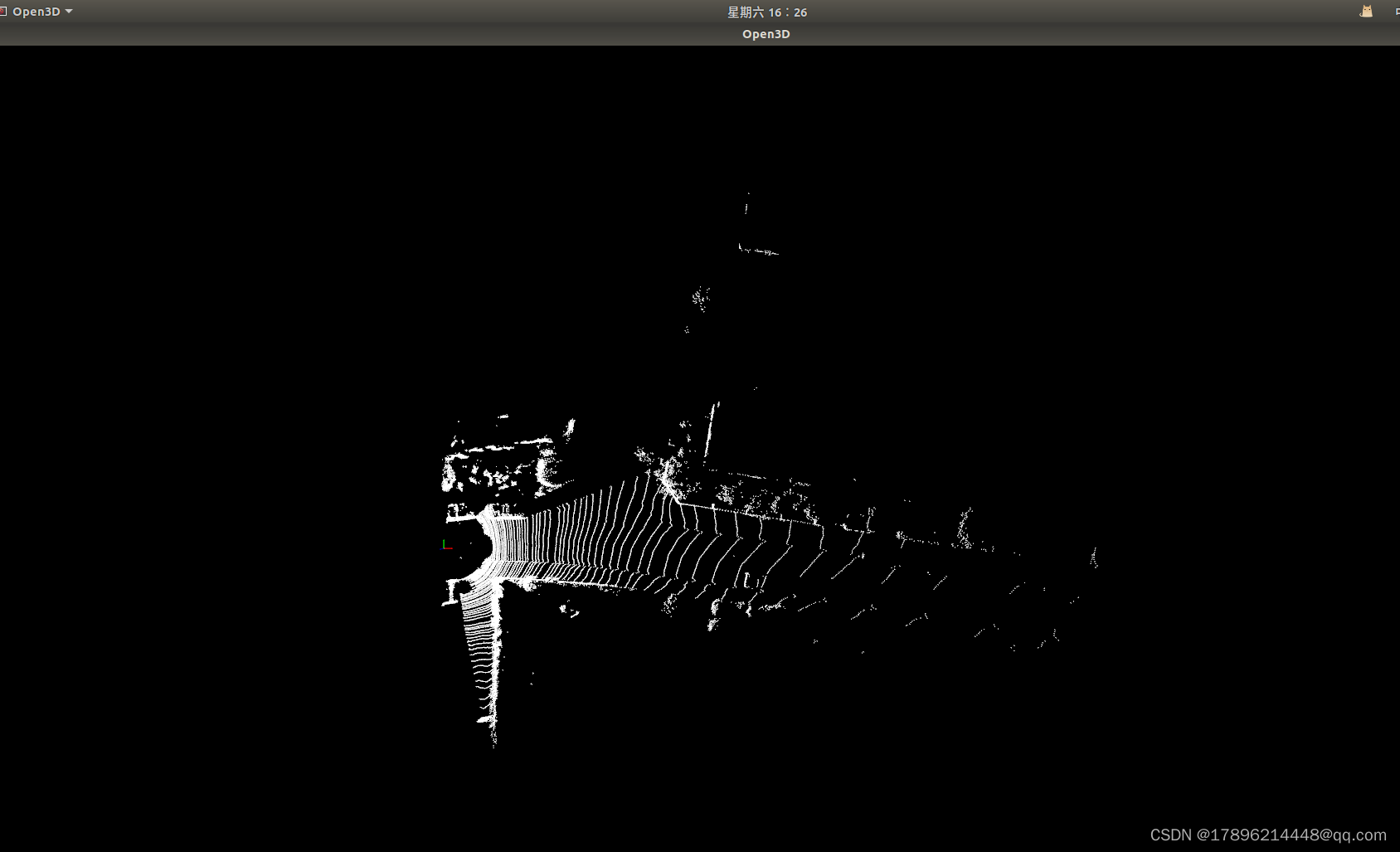
相比原来修改了这里
points = np.fromfile(‘/home/dxp/dxp/IA-SSD/data/kitti/training/velodyne/007303.bin’, dtype=np.float32).reshape(-1, 4)
这里加载数据
model.load_params_from_file(filename=‘IA-SSD.pth’, logger=logger, to_cpu=True)
//这里是模型















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









