





总结:
本文基于2020年cvpr 3d-ssd,是一个单阶段的检测算法。使用分类感知采样和质心感知采样代替随机或最远点采样,以保留小目标的前景点。
过程:
1、将点经送入pointnet++的SA层,提取局部几何特征。前两层使用D-FPS降采样,之后使用提出的实例感知降采样以保留前景点。
2、将上述得到的256个特征点输入到上下文质心预测模块,使用3个MLP层预测质心(Deep hough voting for 3D object detection in point clouds. In ICCV[30])。
3、附加层分类和回归层(三个MLP层)以输出语义标签和相应的边界框。
abstract
现有的基于点的管道通常采用与任务无关的随机采样或最远点采样来逐步下采样输入点云,但并非所有点对目标检测任务都同样重要。对于目标检测前景点远比后景点重要,因此我们提出了一个高效的、单阶段的3d检测器,IA-SSD。关键方法是利用两个可学习的、面向任务的、实例感知的降采样策略来选择属于感兴趣对象的前景点。此外我们还引入了上下文中心感知模块,进一步估计实例的中心,最后为了效率按照仅编码的结构来构建IA-SSD。
1. Introduction
早期工作将3d原始点云转化为中间通常表示,例如鸟瞰和正面2d图像,或者稠密3d体素,但这些方法在3d转2d投影或体素的过程中都有一定的量化误差。另外基于点的pipeline学习点的广泛特征,并通过特定的对称函数(例如max-pooling)进行聚合,但这些方法计算、存储成本较高,检测性能有限。
本篇文章发现大多数文章使用的启发式采样策略不令人满意,许多前景点在最后的边界回归步骤中已被删除。对于行人等小物体检测效果不佳。因此本文认为不是所有点对于检测任务都同等重要。特别是只有前景点我们才关心。
因此,我们提出一个 面向任务的、实例感知的下采样框架,以保留前景点,同时降低内存、计算空间。具体而言,提出了两种变体,本别是类别感知和质心感知的采样策略。此外,我们还提出了上下文实例的质心感知,以充分利用围绕边界框的有意义的上下文信息,例如中心回归。该方法可以通过多个对象类别进行训练,这不同于常见的训练不同类别需要不同模型的做法。
贡献:
1、我们在现有基于点的检测器中确定了采样问题,并通过引入两个基于学习的实例感知降采样策略来提出一个有效的基于点的3D检测器。
2、所提出高效的IA-SSD,能够单次检测LIDAR点云上的多级对象。我们还提供了详细的内存足迹与推理速度分析,以进一步验证提出的方法的优越性。
3、实验效果好
2. Related Work
2.1. Voxel-based Detectors
为了处理非结构化的3D点云,基于体素的检测器通常首先将不规则点云转换为常规素网格。这进一步允许利用成熟的卷积神经体系结构。早期作品(例如[46])密集地对输入点云进行了素化,然后利用卷积神经网络学习特定的几何模式。但是,效率是这些方法的主要局限性之一,因为计算和内存成本随输入分辨率的立方体增长。为此,Yan等人。 [49]提出了一个高效的体系结构,称为SECOND,通过利用3D sub流形稀疏卷积[9]。通过减少空素的计算,计算和记忆效率已得到显着提高。此外,提出了PointPillars[18],以进一步将体素简化为支柱(即仅在平面中的体素化)。
现有方法可以大致分为单阶段[7、11、54、55、57、58]和两个阶段探测器[4、36-39、53]。尽管简单有效,但由于缩小的空间分辨率和结构信息不足,它们通常无法实现令人满意的检测性能,尤其是对于稀疏点的小物体。为此, [11]介绍SA-SSD通过引入辅助网络来利用结构信息。 Ye等。[54]引入混合体素网络(HVNET),以专注于汇总和投影多尺度特征地图,以实现更好的性能。 Zheng等。 [58]介绍自信的Iou-Aware(CIA-SSD)网络,以提取空间语义特征以进行对象检测。相比之下,两阶段探测器可以实现更好的性能,但具有较高的计算/记忆成本。 Shi等[39]提出了一个两阶段检测器,即部分A2,该零件由零件感知和聚合模块组成,以利用对象内部的部分位置。邓等。 [5]通过引入一个完全卷积的网络来进一步利用体积表示,以同时利用体积表示,并同时扩展了PV-RCNN [36]。
总体而言,基于体素的方法可以通过有希望的效率实现良好的检测性能。然而,体脱化不可避免地引入了量化损失。为了补偿预处理阶段的结构失真,需要在[20、25、27、28、35]中引入复杂的模块设计,这又大大恶化了最终检测效率。此外,考虑到复杂的几何形状和各种不同对象,确定实践中最佳分辨率并不容易。
2.2. Point-based Detectors
与基于体素的方法不同,基于点的方法[30,38,52]直接从非结构化点云中学习几何形状,进一步生成了感兴趣的对象的特定建议。考虑到3D点云的无序性质,这些方法通常采用PointNet [31]及其变体[22,32,33,45,47],以使用对称函数来汇总独立的点特征。 Shi等。 [38]提出Pointrcnn,这是用于3D对象检测的两阶段3D区域建议框架。该方法首先从分段的前景点生成对象建议,然后通过利用语义功能和局部空间提示来回归高质量的3D边界框。 Qi等。 [30]介绍了基于深度霍夫投票以预测实例质心的基于单阶段的3D探测器的Votenet。 Yang等人受到2D图像中单阶段检测器的启发[21]。 [52]提出了3D单阶段检测(3DSSD)框架,而键是一种融合采样策略,其中包括特征和欧几里得空间上最远的点采样。 Pointgnn [40]是通过将图神经网络推广到3D对象检测的框架。
基于点的方法直接在原始点云上运行,而无需任何额外的预处理步骤,例如素化,因此通常直观而直接。但是,基于点的方法的主要瓶颈是学习能力不足和效率有限。
2.3. Point-Voxel Methods
为了克服两种基于点的方法的缺点(即,不规则和稀疏数据访问,内存差[23])和基于体素的方法(即量化损失),几种方法[3,16,36,37,53 ]已经开始使用基于point-voxel的方法从3D点云中学习。具体而言,PV-RCNN [36]及其后续工作[37]从体素抽象网络中提取点的特征,以完善从3D Voxel骨架产生的建议。此外,单阶段3D检测器HVPR [29]引入了一个有效的内存模块,以增强基于点的特征,从而在准确性和效率之间提供了更好的折衷。 Qian等。 [34]通过本地邻里图构造提出了一个轻巧的区域聚集网络(BANET),该网络构造产生了更准确的盒子边界预测。
总体而言,不同的检测管道具有自己的优点。在本文中,我们提出了基于单阶段的检测器IA-SSD,以同时提高检测准确性和运行时效率。特别是,我们的IA-SSD和现有基于点的技术之间的关键差异在于实例感知的采样策略和上下文实例质心感知模块,如以下各节所示。
3. The Proposed IA-SSD 3.1. Overview
3.1. Overview
现有的下采样如随机采样、最远点采样对于行人、车等小物体构成的前景点效果不佳,在采样过程中点数会减少。此外,由于不同物体的大小和几何形状差异很大,现有探测器通常会用各种精心调整的超参数训练单独的模型,用于不同类型的对象。因此,本文的目的是:我们可以训练一个基于点的模型,该模型有效并且能够在单次中检测多级对象?
如图2所示,为了效率,IA-SSD遵循3D-SSD[52]中使用的轻质编码结构。最初,输入激光雷达点云被馈入网络以提取点的特征,然后是提出的实例感知的下采样,学习的潜在特征是上下文质心感知模块的进一步输入,以生成实例建议并回归最终的边界框。
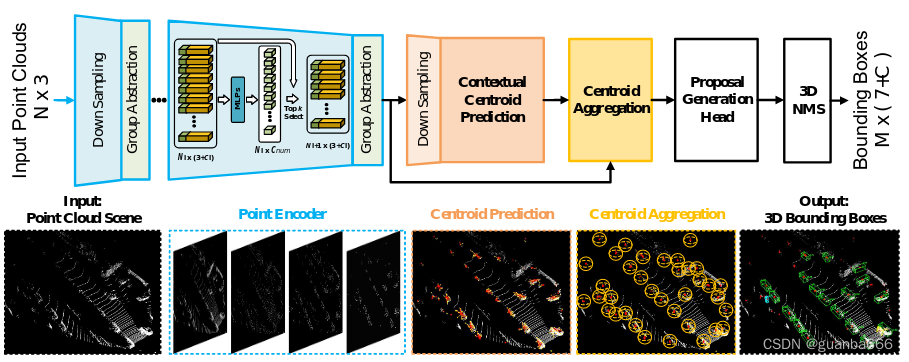
拟议的IA-SSD的例证。首先将输入点云送入几个集合(SA)层,然后进行实例感知的降采样,以逐步降低内存和计算成本。保留的代表点进一步送入了上下文中心的感知模块,例如中心预测和提议产生。最后,输出了3D边界框和关联的类标签。
3.2. Instance-aware Downsampling Strategy
对于有效的3D对象检测,必须通过渐进的下采样来降低记忆和计算成本,尤其是对于大规模3D点云。但是,积极的下采样可能会失去前景对象的大部分信息。总体而言,目前尚不清楚如何在计算效率和前景点保存之间实现理想的权衡。为此,我们首先进行了一项实证研究,以定量评估不同的抽样方法。特别是,我们遵循常用的编码体系结构(即带有4个编码层的PointNet ++ [32]),并在表1中的每个层上报告实例召回(即在采样后保留的实例比率)。特别是,报告了随机点采样 [14]、基于欧氏距离的 FPS (D-FPS) [32] 和特征距离 (Feat-FPS) [52]。
分析:
(1)几次随机下采样后,实例召回率显着下降,表明前景点已经被删除。(2)D-fps和Feat-fps在早期阶段达到了相对较好的实例召回率,但也无法在最后一个编码层保留足够的前景点。因此,精确检测感兴趣的对象,特别是对于行人和骑自行车者等小物体,只剩下极限前景点,仍然具有挑战性。
解决方法:
分类感知采样
这种采样策略旨在学习每个点的语义,从而实现选择性下采样。 为此,我们引入了额外的分支来利用潜在特征中丰富的语义。 特别是,两个 MLP 层被附加到编码层以进一步估计每个点的语义类别。 从原始边界框注释生成的逐点单热语义标签用于监督。 这里我们使用香草交叉熵损失:
中心点感知采样
越接近中心盒质心的点权重越高,在盒子表面的点分数为0。在训练期间,soft point mask将用于根据空间位置为边界框中的点分配不同的权重,因此将几何学先验隐含地纳入网络训练中。特别是,加权交叉透镜损失的计算如下:
3.3. Contextual Instance Centroid Perception
Contextual Centroid Prediction:使用Deep hough voting for 3D object detection in point clouds[30]这篇文章的投票法预测质心
Centroid-based Instance Aggregation:对于转移的代表(质心)点,我们进一步利用PointNet ++模块来学习每个实例的潜在表示。具体而言,我们将相邻点转换为局部规范坐标系,然后通过共享的MLP和对称函数汇总点特征。
Proposal Generation Head:然后将聚合的质心点特征输入到提案生成头中,以预测具有类别的边界框。
3.4. End-to-End Learning
总损失LTOTAL由下采样策略损失lsample,质心预测损失Lcent,分类损失Lcls和预测框损失Lbox组成:
4. Experiments
4.1. Implementation Details
我们基于单阶段的典型体系结构来构建IA-SSD,以提高效率。具体而言,许多SA层[32]用于提取点上的特征。使用半径增加组的多尺度组([0.2,0.8],[0.8,1.6],[1.6,4.8])稳定提取局部几何特征。考虑到早期层中有限的语义,我们在前两个编码层中采用了D-FPS,之后采用提出的实例感知下采样。接下来,将256个代表点特征送入上下文质心预测模块中,其次是三个MLP层(256→256→3),以预测实例质心。最后,将分类和回归层(三个MLP层)附加到输出语义标签和相应的边界框。附录中报告了更多实施细节。
4.2. Comparison with State-of-the-Art Methods















 4300
4300











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









