







参考文章:
https://blog.csdn.net/qq_38232598/article/details/88695454

YOLO核心思想
·端到端:采用直接回归的思路,将目标定位和目标类别预测整合于单个神经网络模型中
·直接在输出层回归bbox的位置和所属类别 – 快!!!
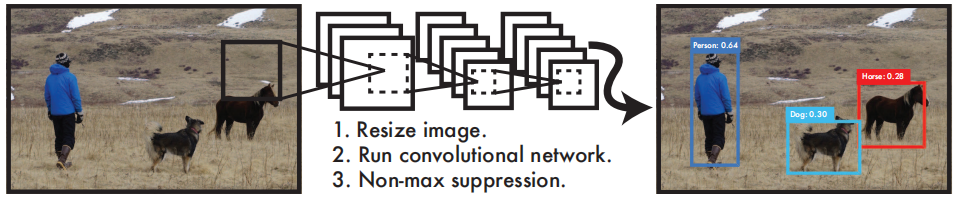
1.将一幅图像分为SXS个网格,如果某个object的中心落在网格中(通过ground-truth框确定),则对应网格就负责预测这个object
2.对于网络预测的Bounding box,除了回归自身位置外,还需要带一个confidence值,该值代表所预测的框中是否含有object和若含有object,该object预测的多准概率的乘积
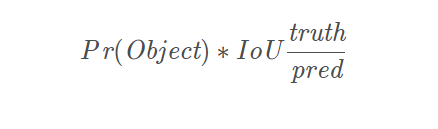
3、每个网格单元针对20种类别预测bboxes属于单个类别的条件概率P r ( Classi∣Object) ,属于同一个网格的B个bboxes共享一个条件概率。在测试时,将条件概率分别和单个的bbox的confidence预测相乘:
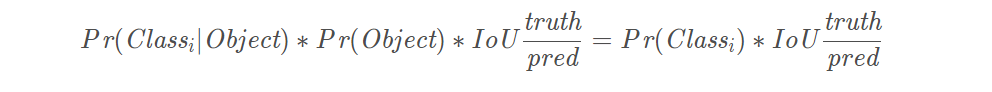
YOLO网络结构

YOLO使用了24个级联卷积层和最后2个全连接层,1x1的卷积层目的是降低前面层的特征空间。在ImageNet任务中,使用分辨率为224x224的输入图像对卷积层进行预训练,然后将分辨率加倍进行目标检测

bounding box预测的五个之分别是:框的坐标x,y值,框的宽度,长度,以及confidence值
因此输出的tensor张量计算公式为SxSx(5xB+C),(x,y)表示bounding box相对于网格单元的边界的offset,归一化到0-1的范围内,而w,h相对于整个图片的预测宽和高,前四个值都被归一化到0-1的范围内。c表示的则是object在bounding box的confidence值
归一化原理
假设图片划分为7x7个网格,宽为wi,高为hi
1.x,y–bbox的中心相对于单元格的offset
如下图所示,蓝色格的坐标为(Xcol = 1,Yrow = 4),假设预测输出时红色框bbox,设该框中心坐标为(xc,yc),则最终预测的(x,y)经归一化公式处理后,得到相对于单元格的offset
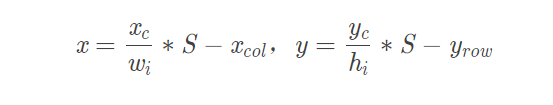

2. w,h – bbox相对于整张图片的比例
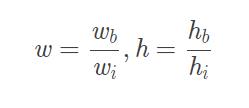
Inference
每个grid cell对应的两个bounding box的5个值在tensor中体现出来,组成前十维。每个单元格负责预测一个object,但是每个单元格预测出两个bounding box

tensor的前10维表示bounding box的信息,剩下20维则表示与类别相关的信息,其中对应维的值表示此object在此bbox中的时候,属于class_i的概率分数



每个单元格预测一个属于类别classi的条件概率Pr(Classi|Object).言注意的是,属于一个网格的两个bbox共享一套条件概率,预测出一个object类别的最终值
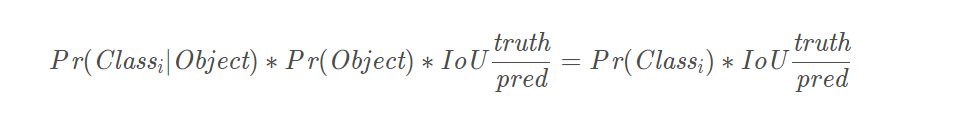
根据上式,可以计算每个bbox的class-specific confidence score分数,对每个格子的每一个bounding box进行该运算,最后得到7x7x2=98个score(每个格子两个盒子),设置一个阈值,过滤掉低分的盒子,对保留的bbox进行NMS(Non Maximum Suppression)处理,最后得到检测结果


预测框的定位
经过上一步计算,可以得到每个bbox的class-specific confidence score

· 首先通过设定阈值,过滤掉得分低的bboxs

· 将所得分数从大到小进行排序




· 排序后,将得分最高的盒子标为bbox_max

· 将bbox和其他分数较低但不为零的盒子(bbox_cur)做对比,主要是计算它们的重合度,具体做IOU计算,如果IOU(bbox_max,bbox_cur)> 0.5,则判定重合度过大,将bbox cur的分数设为0

· 接着遍历下一个score,如果它不是最大的,且不为0,则和最大的score bbox做IOU运算(同上),如果补充和,则score不变,继续处理下一个bbox_cur

· 计算完一轮后,得到新序列,找出score第二的bbox_cur,作为下一轮的bbox_max(如上图的0.2),循环计算后面的bbox_cur于新的bbox_max的IOU值(和之前步骤一致),一直循环直到最后一个score。上图最后得到的score排列为(0.5,0.2,0,…,0)

· 其他类别的预测也一样


再筛选bounding box
经过前面NMS算法的处理,会有很多score为0的情况
最后,针对每个bbox的20个类别score:
1.找出bbox中score最大的类别的索引号,记为class
2.找出该bbox的最大score,记为score
3.判断score是否大于0,如果是,则在图像中画出标有class的框。否则,丢弃该bbox


·最终结果:

损失函数

在损失函数中,只有某个网格中有object的中心落入时,才对classification loss做惩罚,只有某个网格i中的bbox对某个ground-truth box负责时,才对coordinate error进行惩罚。那个bbox对ground-truth box负责通过IOU最大设定
· LOSS参数解释
1.在实际预测中,localization error和classfication error的重要性是不一样的,为了加大localization error对结果的影响,增加了λcoord权重,在Pascal VOC训练中取5
2.对于不存在object的bbox,一般赋予更小的损失权重,记为λnoobj,在Pascal VOC中取0.5。若没有物体中心落在框中,则置为0。0.5的意义在于解决因为没有权重而造成不平衡的现象
3.对于存在object的bbox的confidence loss和类别的loss,权重取常数1。对于每个格子而言,作者设计只能包含同种物体。若格子中包含物体,我们希望希望预测正确的类别的概率越接近于1越好,而错误类别的概率越接近于0越好。loss第4部分中,若p i ^ ( c ) 为0中c为正确类别,则值为1,若非正确类别,则值为0
4.wi和hi的误差取平方根计算原因在于,小物体的预测框偏离影响要比大物体偏离大,因此取平方根会加大小物体偏差的惩罚
YOLO V1的不足和优点
优点
1.假阳性(FP)低–YOLO网络将整个图像的全部信息作为上下文,结合了全图信息,因此能更好地区分目标和背景区域
2. 端到端(end-to-end),速度快 (tiny可以达到155fps)
3. 通用性强
缺点
1.性能表现比最先进的目标检测算法低
2.定位精确性差,小目标和密集群体定位效果不好(每个格子只能有一个box)
3.大小物体偏差还是难以处理
4.检测尺寸固定,分辨率固定
5、采用了多个下采样层,网络学到的物体特征不够精细
代码解读
pascal_voc.py – 读入VOC数据集数据
import os
import xml.etree.ElementTree as ET
import numpy as np
import cv2
import pickle
import copy
import yolo.config as cfg
class pascal_voc(object):
def __init__(self, phase, rebuild=False):
#找VOC数据集数据
self.devkil_path = os.path.join(cfg.PASCAL_PATH, 'VOCdevkit')
self.data_path = os.path.join(self.devkil_path, 'VOC2007')
#yolo/config.py设定的参数读取
self.cache_path = cfg.CACHE_PATH #初始化参数
self.batch_size = cfg.BATCH_SIZE #每次训练45个
self.image_size = cfg.IMAGE_SIZE #图片大小-448
self.cell_size = cfg.CELL_SIZE #每张图片划分的网格数--7*7
self.classes = cfg.CLASSES #所有类别字典数据
self.class_to_ind = dict(zip(self.classes, range(len(self.classes))))
self.flipped = cfg.FLIPPED #是否图片翻转增强数据
self.phase = phase #数据文件选择标志
self.rebuild = rebuild #标签解析对象文件是否重建标志
self.cursor = 0
self.epoch = 1 #样本训练伦茨
self.gt_labels = None #标签列表字典对象
self.prepare() #获得准备好的数据
def get(self): #依次获取图像及其标签文件,生成器
images = np.zeros(
(self.batch_size, self.image_size, self.image_size, 3))
labels = np.zeros(
(self.batch_size, self.cell_size, self.cell_size, 25))
count = 0
while count < self.batch_size:
imname = self.gt_labels[self.cursor]['imname']
flipped = self.gt_labels[self.cursor]['flipped']
images[count, :, :, :] = self.image_read(imname, flipped)
labels[count, :, :, :] = self.gt_labels[self.cursor]['label']
count += 1
self.cursor += 1
if self.cursor >= len(self.gt_labels): #获取完一轮gt_labels所有数据后,打乱顺序,重新获取
np.random.shuffle(self.gt_labels)
self.cursor = 0
self.epoch += 1 #下一轮次
return images, labels
def image_read(self, imname, flipped=False): #读取图片
image = cv2.imread(imname)
image = cv2.resize(image, (self.image_size, self.image_size)) #重新设置图片大小
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32) #BGR转成三通道RGB格式
image = (image / 255.0) * 2.0 - 1.0 #像素归一化到(-1,1) 数据格式为浮点型
if flipped:
image = image[:, ::-1, :] #图片翻转增强
return image
def prepare(self): #完成标签数据准备的编码
gt_labels = self.load_labels() #将所有图像的信息提取出来
if self.flipped: #检测图像是否翻转,如果翻转要相应改变坐标位置
print('Appending horizontally-flipped training examples ...') #水平翻转
gt_labels_cp = copy.deepcopy(gt_labels)
for idx in range(len(gt_labels_cp)): #返回得到的可迭代数目
gt_labels_cp[idx]['flipped'] = True
gt_labels_cp[idx]['label'] =\
gt_labels_cp[idx]['label'][:, ::-1, :] #水平翻转标签,这里反转的是cell网格,xc(cell)
for i in range(self.cell_size):
for j in range(self.cell_size):
if gt_labels_cp[idx]['label'][i, j, 0] == 1: #有物体才进行操作
gt_labels_cp[idx]['label'][i, j, 1] = \
self.image_size - 1 -\
gt_labels_cp[idx]['label'][i, j, 1] #对标签的xc进行翻转,xc即图像的中心坐标(x.center)
gt_labels += gt_labels_cp
np.random.shuffle(gt_labels) #再第0个维度进行打乱
self.gt_labels = gt_labels
return gt_labels
def load_labels(self): #读取标签对象=》列表字典对象
cache_file = os.path.join(
self.cache_path, 'pascal_' + self.phase + '_gt_labels.pkl')
if os.path.isfile(cache_file) and not self.rebuild:
print('Loading gt_labels from: ' + cache_file)
with open(cache_file, 'rb') as f:
gt_labels = pickle.load(f) #将标签文件解析为对象
return gt_labels #不重建的化,直接return
print('Processing gt_labels from: ' + self.data_path)
if not os.path.exists(self.cache_path):
os.makedirs(self.cache_path)
if self.phase == 'train':
txtname = os.path.join(
self.data_path, 'ImageSets', 'Main', 'trainval.txt')
else:
txtname = os.path.join(
self.data_path, 'ImageSets', 'Main', 'test.txt')
with open(txtname, 'r') as f:
self.image_index = [x.strip() for x in f.readlines()] #读取图片编号 strip()删除开头或结尾的字
#将读取到的数据做成label,并存到gt_labels里
gt_labels = []
for index in self.image_index:
label, num = self.load_pascal_annotation(index)
if num == 0:
continue
imname = os.path.join(self.data_path, 'JPEGImages', index + '.jpg')
gt_labels.append({'imname': imname,
'label': label,
'flipped': False}) #组成列表
print('Saving gt_labels to: ' + cache_file)
with open(cache_file, 'wb') as f:
pickle.dump(gt_labels, f) #序列化列表字典文件为对象
return gt_labels
def load_pascal_annotation(self, index): #该方法的作用主要是从PASCAL VOC自带的xml中解析出bbox的坐标,并分配tensor参数
"""
Load image and bounding boxes info from XML file in the PASCAL VOC
format.
"""
imname = os.path.join(self.data_path, 'JPEGImages', index + '.jpg')
im = cv2.imread(imname)
h_ratio = 1.0 * self.image_size / im.shape[0] #因为重新设定了图像大小,因此实际坐标也要跟着改变
w_ratio = 1.0 * self.image_size / im.shape[1]
# im = cv2.resize(im, [self.image_size, self.image_size])
label = np.zeros((self.cell_size, self.cell_size, 25))
filename = os.path.join(self.data_path, 'Annotations', index + '.xml') #找出xml配置文件
tree = ET.parse(filename)
objs = tree.findall('object')
for obj in objs:
bbox = obj.find('bndbox')
# Make pixel indexes 0-based
'''
min() -- 让控制框不超过image_size,将超出边界的拉回来
max() -- 当框坐标小于0是,将其拉回到图像内
-1 == 让像素从0开始,索引也是从0开始
'''
x1 = max(min((float(bbox.find('xmin').text) - 1) * w_ratio, self.image_size - 1), 0)
y1 = max(min((float(bbox.find('ymin').text) - 1) * h_ratio, self.image_size - 1), 0)
x2 = max(min((float(bbox.find('xmax').text) - 1) * w_ratio, self.image_size - 1), 0)
y2 = max(min((float(bbox.find('ymax').text) - 1) * h_ratio, self.image_size - 1), 0)
cls_ind = self.class_to_ind[obj.find('name').text.lower().strip()] #让每一个类对应一个数字索引
boxes = [(x2 + x1) / 2.0, (y2 + y1) / 2.0, x2 - x1, y2 - y1] #(x.center,y.center,width,height)
x_ind = int(boxes[0] * self.cell_size / self.image_size) #分成7*7网格表示
y_ind = int(boxes[1] * self.cell_size / self.image_size)
#(confidence,x,y,width,height,class)
if label[y_ind, x_ind, 0] == 1: #同框多个obj时,一个cell只负责检测一个物体
continue
label[y_ind, x_ind, 0] = 1 #置信度
label[y_ind, x_ind, 1:5] = boxes
label[y_ind, x_ind, 5 + cls_ind] = 1
return label, len(objs)#返回标签和tensor的实际维数
yolo_net.py – yolo网络搭建 + loss function
import numpy as np
import tensorflow as tf
import yolo.config as cfg
slim = tf.contrib.slim
class YOLONet(object):
def __init__(self, is_training=True):
self.classes = cfg.CLASSES #分类字典
self.num_class = len(self.classes)
self.image_size = cfg.IMAGE_SIZE
self.cell_size = cfg.CELL_SIZE
self.boxes_per_cell = cfg.BOXES_PER_CELL
self.output_size = (self.cell_size * self.cell_size) *\
(self.num_class + self.boxes_per_cell * 5)
self.scale = 1.0 * self.image_size / self.cell_size
self.boundary1 = self.cell_size * self.cell_size * self.num_class
self.boundary2 = self.boundary1 +\
self.cell_size * self.cell_size * self.boxes_per_cell
self.object_scale = cfg.OBJECT_SCALE
self.noobject_scale = cfg.NOOBJECT_SCALE
self.class_scale = cfg.CLASS_SCALE
self.coord_scale = cfg.COORD_SCALE
self.learning_rate = cfg.LEARNING_RATE
self.batch_size = cfg.BATCH_SIZE
self.alpha = cfg.ALPHA
self.offset = np.transpose(np.reshape(np.array(
[np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell),
(self.boxes_per_cell, self.cell_size, self.cell_size)), (1, 2, 0)) #offset--单元划分后和图片的比值
self.images = tf.placeholder(
tf.float32, [None, self.image_size, self.image_size, 3],
name='images')
self.logits = self.build_network(
self.images, num_outputs=self.output_size, alpha=self.alpha,
is_training=is_training)
if is_training:
self.labels = tf.placeholder(
tf.float32,
[None, self.cell_size, self.cell_size, 5 + self.num_class])
self.loss_layer(self.logits, self.labels)
self.total_loss = tf.losses.get_total_loss()
tf.summary.scalar('total_loss', self.total_loss)
#定义yolo网络结构
def build_network(self,
images,
num_outputs,
alpha,
keep_prob=0.5,
is_training=True,
scope='yolo'):
with tf.variable_scope(scope):
with slim.arg_scope(
#定义要用的层
[slim.conv2d, slim.fully_connected],
activation_fn=leaky_relu(alpha),
weights_regularizer=slim.l2_regularizer(0.0005),
weights_initializer=tf.truncated_normal_initializer(0.0, 0.01)
):
net = tf.pad( #填充补数,作用是保证最后输出特征图大小是7*7
images, np.array([[0, 0], [3, 3], [3, 3], [0, 0]]),
name='pad_1')
net = slim.conv2d(
net, 64, 7, 2, padding='VALID', scope='conv_2') #7*7*64-s-2
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_3')
net = slim.conv2d(net, 192, 3, scope='conv_4') #3*3*192
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_5')
net = slim.conv2d(net, 128, 1, scope='conv_6')
net = slim.conv2d(net, 256, 3, scope='conv_7')
net = slim.conv2d(net, 256, 1, scope='conv_8')
net = slim.conv2d(net, 512, 3, scope='conv_9')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_10')
net = slim.conv2d(net, 256, 1, scope='conv_11')
net = slim.conv2d(net, 512, 3, scope='conv_12')
net = slim.conv2d(net, 256, 1, scope='conv_13')
net = slim.conv2d(net, 512, 3, scope='conv_14')
net = slim.conv2d(net, 256, 1, scope='conv_15')
net = slim.conv2d(net, 512, 3, scope='conv_16')
net = slim.conv2d(net, 256, 1, scope='conv_17')
net = slim.conv2d(net, 512, 3, scope='conv_18')
net = slim.conv2d(net, 512, 1, scope='conv_19')
net = slim.conv2d(net, 1024, 3, scope='conv_20')
net = slim.max_pool2d(net, 2, padding='SAME', scope='pool_21')
net = slim.conv2d(net, 512, 1, scope='conv_22')
net = slim.conv2d(net, 1024, 3, scope='conv_23')
net = slim.conv2d(net, 512, 1, scope='conv_24')
net = slim.conv2d(net, 1024, 3, scope='conv_25')
net = slim.conv2d(net, 1024, 3, scope='conv_26')
net = tf.pad(
net, np.array([[0, 0], [1, 1], [1, 1], [0, 0]]),
name='pad_27')
net = slim.conv2d(
net, 1024, 3, 2, padding='VALID', scope='conv_28')
net = slim.conv2d(net, 1024, 3, scope='conv_29')
net = slim.conv2d(net, 1024, 3, scope='conv_30')
net = tf.transpose(net, [0, 3, 1, 2], name='trans_31') #转置为[0,3,1,2]的排列
net = slim.flatten(net, scope='flat_32') #输入扁平化,但保留batch_size,假设第一维是batch
net = slim.fully_connected(net, 512, scope='fc_33')
net = slim.fully_connected(net, 4096, scope='fc_34')
net = slim.dropout(
net, keep_prob=keep_prob, is_training=is_training,
scope='dropout_35')
net = slim.fully_connected(
net, num_outputs, activation_fn=None, scope='fc_36') #最后一层用线性激活函数
return net #最后输出的学习特征为7x7x30 = 1490,同时也能体现cellxcell*25等标签空间特征
def calc_iou(self, boxes1, boxes2, scope='iou'): #计算IOU
#将原始的中心点坐标和长宽,转换成矩形框左上角和右下角两个点坐标
"""calculate ious
Args:
boxes1: 5-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ====> (x_center, y_center, w, h)
boxes2: 5-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL, 4] ===> (x_center, y_center, w, h)
Return:
iou: 4-D tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
"""
with tf.variable_scope(scope):
# transform (x_center, y_center, w, h) to (x1, y1, x2, y2) 1 -- 左上角 2--右下角
boxes1_t = tf.stack([boxes1[..., 0] - boxes1[..., 2] / 2.0,
boxes1[..., 1] - boxes1[..., 3] / 2.0,
boxes1[..., 0] + boxes1[..., 2] / 2.0,
boxes1[..., 1] + boxes1[..., 3] / 2.0],
axis=-1)
boxes2_t = tf.stack([boxes2[..., 0] - boxes2[..., 2] / 2.0,
boxes2[..., 1] - boxes2[..., 3] / 2.0,
boxes2[..., 0] + boxes2[..., 2] / 2.0,
boxes2[..., 1] + boxes2[..., 3] / 2.0],
axis=-1)
# calculate the left up point & right down point -- 划定IOU区域(相交矩形区域)
lu = tf.maximum(boxes1_t[..., :2], boxes2_t[..., :2]) #选坐标较大的左上角
rd = tf.minimum(boxes1_t[..., 2:], boxes2_t[..., 2:]) #选坐标较小的右下角
# intersection -- 计算相交区域大小
intersection = tf.maximum(0.0, rd - lu) #IOU的长和宽
inter_square = intersection[..., 0] * intersection[..., 1] #IOU区域面积,交集的大小
# calculate the boxs1 square and boxs2 square
square1 = boxes1[..., 2] * boxes1[..., 3]
square2 = boxes2[..., 2] * boxes2[..., 3]
union_square = tf.maximum(square1 + square2 - inter_square, 1e-10) #两个框的真实面积(减去一次重叠部分),也就是并集的大小
return tf.clip_by_value(inter_square / union_square, 0.0, 1.0) #计算出两个框的交并比,并规定在0-1之间
def loss_layer(self, predicts, labels, scope='loss_layer'):
with tf.variable_scope(scope):
predict_classes = tf.reshape(
predicts[:, :self.boundary1],
[self.batch_size, self.cell_size, self.cell_size, self.num_class]) #预测类别
predict_scales = tf.reshape(
predicts[:, self.boundary1:self.boundary2],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell]) #预测置信度
predict_boxes = tf.reshape(
predicts[:, self.boundary2:],
[self.batch_size, self.cell_size, self.cell_size, self.boxes_per_cell, 4]) #预测框的信息,一个cell两个盒子,所以占8维
#拿ground-truth的值,准备计算损失函数
response = tf.reshape( #responce--提取label中的置信度,表示该地方是否有狂
labels[..., 0],
[self.batch_size, self.cell_size, self.cell_size, 1])
boxes = tf.reshape(
labels[..., 1:5],
[self.batch_size, self.cell_size, self.cell_size, 1, 4]) #升维度,提取label的框信息 盒子在前5维
# tf.tile 对boxes张量进行赋值,扩张规则为第二个参数(对轴3赋值两次,因为一个cell两个框)
boxes = tf.tile(
boxes, [1, 1, 1, self.boxes_per_cell, 1]) / self.image_size #进行Xc/image_size的归一化操作,
# 为了匹配predict_scales/self.image_size,处理wi,hi
classes = labels[..., 5:] #5维后为分类类别,提取label的类
offset = tf.reshape( #offsetz作用是将每个cell的坐标对齐
tf.constant(self.offset, dtype=tf.float32),
[1, self.cell_size, self.cell_size, self.boxes_per_cell]) #offset = none,cell,cell,per_Cell(四维).Cell能取0-6
offset = tf.tile(offset, [self.batch_size, 1, 1, 1]) #扩张为batch_size的大小,表示一批
offset_tran = tf.transpose(offset, (0, 2, 1, 3)) #转置,将每个cell的坐标对齐,同时赋一个偏置初值(0-1)之间
predict_boxes_tran = tf.stack( #矩阵拼接
[(predict_boxes[..., 0] + offset) / self.cell_size,
(predict_boxes[..., 1] + offset_tran) / self.cell_size,
tf.square(predict_boxes[..., 2]), #xc = (x(相对)+xcol)*wi/S
tf.square(predict_boxes[..., 3])], axis=-1) #初始化 predict_boxes_tram[...,:]
iou_predict_truth = self.calc_iou(predict_boxes_tran, boxes) #iou_predict_truth [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL]
# calculate I tensor [BATCH_SIZE, CELL_SIZE, CELL_SIZE, BOXES_PER_CELL],计算有obj的区域,就是猜中了的地方
object_mask = tf.reduce_max(iou_predict_truth, 3, keep_dims=True) #得到交并比较大的框
object_mask = tf.cast( #tf.cast--点乘 高维矩阵没有叉乘
(iou_predict_truth >= object_mask), tf.float32) * response
# calculate no_I tensor [CELL_SIZE, CELL_SIZE, BOXES_PER_CELL],计算noobj区域
noobject_mask = tf.ones_like(
object_mask, dtype=tf.float32) - object_mask #ones_like将值全为1,再减有目标的,等于没目标的
boxes_tran = tf.stack( #计算bbox的相对位置信息
[boxes[..., 0] * self.cell_size - offset, # (Xc*S-Xcol)/wi =x =>相对值 wi在 185行处理的
boxes[..., 1] * self.cell_size - offset_tran, #y一样,wi,hi前面已经处理过
tf.sqrt(boxes[..., 2]),
tf.sqrt(boxes[..., 3])], axis=-1) #对于损失函数,w,h要开方
#开始计算损失
# class_loss
class_delta = response * (predict_classes - classes) #置信度*类别差
class_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(class_delta), axis=[1, 2, 3]),
name='class_loss') * self.class_scale
# object_loss
object_delta = object_mask * (predict_scales - iou_predict_truth)
object_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(object_delta), axis=[1, 2, 3]),
name='object_loss') * self.object_scale
# noobject_loss
noobject_delta = noobject_mask * predict_scales
noobject_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(noobject_delta), axis=[1, 2, 3]),
name='noobject_loss') * self.noobject_scale
# coord_loss
coord_mask = tf.expand_dims(object_mask, 4)
boxes_delta = coord_mask * (predict_boxes - boxes_tran)
coord_loss = tf.reduce_mean(
tf.reduce_sum(tf.square(boxes_delta), axis=[1, 2, 3, 4]),
name='coord_loss') * self.coord_scale
tf.losses.add_loss(class_loss)
tf.losses.add_loss(object_loss)
tf.losses.add_loss(noobject_loss)
tf.losses.add_loss(coord_loss)
tf.summary.scalar('class_loss', class_loss)
tf.summary.scalar('object_loss', object_loss)
tf.summary.scalar('noobject_loss', noobject_loss)
tf.summary.scalar('coord_loss', coord_loss)
tf.summary.histogram('boxes_delta_x', boxes_delta[..., 0])
tf.summary.histogram('boxes_delta_y', boxes_delta[..., 1])
tf.summary.histogram('boxes_delta_w', boxes_delta[..., 2])
tf.summary.histogram('boxes_delta_h', boxes_delta[..., 3])
tf.summary.histogram('iou', iou_predict_truth)
def leaky_relu(alpha):
def op(inputs):
return tf.nn.leaky_relu(inputs, alpha=alpha, name='leaky_relu')
return op
train.py – 训练设置
import os
import argparse
import datetime
import tensorflow as tf
import yolo.config as cfg
from yolo.yolo_net import YOLONet
from utils.timer import Timer
from utils.pascal_voc import pascal_voc
slim = tf.contrib.slim
class Solver(object):
def __init__(self, net, data):
self.net = net
self.data = data
self.weights_file = cfg.WEIGHTS_FILE
self.max_iter = cfg.MAX_ITER
self.initial_learning_rate = cfg.LEARNING_RATE
self.decay_steps = cfg.DECAY_STEPS
self.decay_rate = cfg.DECAY_RATE
self.staircase = cfg.STAIRCASE
self.summary_iter = cfg.SUMMARY_ITER
self.save_iter = cfg.SAVE_ITER
self.output_dir = os.path.join(
cfg.OUTPUT_DIR, datetime.datetime.now().strftime('%Y_%m_%d_%H_%M'))
if not os.path.exists(self.output_dir):
os.makedirs(self.output_dir)
self.save_cfg()
#将流程图画到tensorboard上
self.variable_to_restore = tf.global_variables() #返回所用变量的list
self.saver = tf.train.Saver(self.variable_to_restore, max_to_keep=None) #保存list下的所有变量
self.ckpt_file = os.path.join(self.output_dir, 'yolo') #日志文件保存路径
self.summary_op = tf.summary.merge_all() #打包所有summary文件用于tensorboard显示
self.writer = tf.summary.FileWriter(self.output_dir, flush_secs=60) #保存
self.global_step = tf.train.create_global_step() #用于训练过程的global_step(学习率变化周期),每执行一次加1
self.learning_rate = tf.train.exponential_decay(
self.initial_learning_rate, self.global_step, self.decay_steps,
self.decay_rate, self.staircase, name='learning_rate') #学习率衰减,根据训练次数和衰减周次,按衰减率变化
self.optimizer = tf.train.GradientDescentOptimizer(
learning_rate=self.learning_rate)
self.train_op = slim.learning.create_train_op(
self.net.total_loss, self.optimizer, global_step=self.global_step)#根据损失定义优化操作
gpu_options = tf.GPUOptions() #用于限制GPU资源
config = tf.ConfigProto(gpu_options=gpu_options) #初始化GPU资源分配
self.sess = tf.Session(config=config) #配置生效
self.sess.run(tf.global_variables_initializer()) #全局初始化
#保存权重参数
if self.weights_file is not None:
print('Restoring weights from: ' + self.weights_file)
self.saver.restore(self.sess, self.weights_file)
self.writer.add_graph(self.sess.graph) #添加计算图文件,用于保存
def train(self):
train_timer = Timer()
load_timer = Timer()
for step in range(1, self.max_iter + 1):
#计时工具,用于分析模型运行速度
load_timer.tic()#开始计时
images, labels = self.data.get()
load_timer.toc()#结束计时
feed_dict = {self.net.images: images,
self.net.labels: labels} #一步一个批次,一个批次45张 1epoch=sum(img)/batch_size = 17125/45 = 381批次
if step % self.summary_iter == 0: #每10步记录summary
if step % (self.summary_iter * 10) == 0: #每100步打印日志
train_timer.tic()
summary_str, loss, _ = self.sess.run(
[self.summary_op, self.net.total_loss, self.train_op],
feed_dict=feed_dict)
train_timer.toc()
log_str = '''{} Epoch: {}, Step: {}, Learning rate: {},'''
''' Loss: {:5.3f}\nSpeed: {:.3f}s/iter,'''
'''' Load: {:.3f}s/iter, Remain: {}'''.format(
datetime.datetime.now().strftime('%m-%d %H:%M:%S'),
self.data.epoch,
int(step),
round(self.learning_rate.eval(session=self.sess), 6),
loss,
train_timer.average_time,
load_timer.average_time,
train_timer.remain(step, self.max_iter))
print(log_str)
else:
train_timer.tic()
summary_str, _ = self.sess.run(
[self.summary_op, self.train_op],
feed_dict=feed_dict)
train_timer.toc()
self.writer.add_summary(summary_str, step)
else:
train_timer.tic()
self.sess.run(self.train_op, feed_dict=feed_dict)
train_timer.toc()
if step % self.save_iter == 0: #每1000次保存检查点文件
print('{} Saving checkpoint file to: {}'.format(
datetime.datetime.now().strftime('%m-%d %H:%M:%S'),
self.output_dir))
self.saver.save(
self.sess, self.ckpt_file, global_step=self.global_step)
def save_cfg(self):
with open(os.path.join(self.output_dir, 'config.txt'), 'w') as f:
cfg_dict = cfg.__dict__
for key in sorted(cfg_dict.keys()):
if key[0].isupper():
cfg_str = '{}: {}\n'.format(key, cfg_dict[key])
f.write(cfg_str)
def update_config_paths(data_dir, weights_file):
cfg.DATA_PATH = data_dir
cfg.PASCAL_PATH = os.path.join(data_dir, 'pascal_voc')
cfg.CACHE_PATH = os.path.join(cfg.PASCAL_PATH, 'cache')
cfg.OUTPUT_DIR = os.path.join(cfg.PASCAL_PATH, 'output')
cfg.WEIGHTS_DIR = os.path.join(cfg.PASCAL_PATH, 'weights')
cfg.WEIGHTS_FILE = os.path.join(cfg.WEIGHTS_DIR, weights_file)
def main():
parser = argparse.ArgumentParser() #编写命令行接口
parser.add_argument('--weights', default="YOLO_small.ckpt", type=str)
parser.add_argument('--data_dir', default="data", type=str)
parser.add_argument('--threshold', default=0.2, type=float)
parser.add_argument('--iou_threshold', default=0.5, type=float)
parser.add_argument('--gpu', default='', type=str)
args = parser.parse_args()
if args.gpu is not None:
cfg.GPU = args.gpu
if args.data_dir != cfg.DATA_PATH:
update_config_paths(args.data_dir, args.weights)
os.environ['CUDA_VISIBLE_DEVICES'] = cfg.GPU
yolo = YOLONet()
pascal = pascal_voc('train')
solver = Solver(yolo, pascal)
print('Start training ...')
solver.train()
print('Done training.')
if __name__ == '__main__':
# python train.py --weights YOLO_small.ckpt --gpu 0
main()
test.py – 测试设置,画出框及判断类别
import os
import cv2
import argparse
import numpy as np
import tensorflow as tf
import yolo.config as cfg
from yolo.yolo_net import YOLONet
from utils.timer import Timer
class Detector(object):
def __init__(self, net, weight_file):
self.net = net
self.weights_file = weight_file
self.classes = cfg.CLASSES
self.num_class = len(self.classes)
self.image_size = cfg.IMAGE_SIZE
self.cell_size = cfg.CELL_SIZE
self.boxes_per_cell = cfg.BOXES_PER_CELL
self.threshold = cfg.THRESHOLD
self.iou_threshold = cfg.IOU_THRESHOLD
self.boundary1 = self.cell_size * self.cell_size * self.num_class
self.boundary2 = self.boundary1 +\
self.cell_size * self.cell_size * self.boxes_per_cell
self.sess = tf.Session()
self.sess.run(tf.global_variables_initializer())
print('Restoring weights from: ' + self.weights_file)
self.saver = tf.train.Saver()
self.saver.restore(self.sess, self.weights_file)
def draw_result(self, img, result): #画出bbox
for i in range(len(result)):
x = int(result[i][1])
y = int(result[i][2])
w = int(result[i][3] / 2)
h = int(result[i][4] / 2)
cv2.rectangle(img, (x - w, y - h), (x + w, y + h), (0, 255, 0), 2)
cv2.rectangle(img, (x - w, y - h - 20),
(x + w, y - h), (125, 125, 125), -1)
lineType = cv2.LINE_AA if cv2.__version__ > '3' else cv2.CV_AA
cv2.putText(
img, result[i][0] + ' : %.2f' % result[i][5],
(x - w + 5, y - h - 7), cv2.FONT_HERSHEY_SIMPLEX, 0.5,
(0, 0, 0), 1, lineType) #在框上写出类别名称
def detect(self, img): #将预测集上预测的转换回原图像中
#图片数据预处理
img_h, img_w, _ = img.shape
inputs = cv2.resize(img, (self.image_size, self.image_size))
inputs = cv2.cvtColor(inputs, cv2.COLOR_BGR2RGB).astype(np.float32)
inputs = (inputs / 255.0) * 2.0 - 1.0 #(-1-1)
inputs = np.reshape(inputs, (1, self.image_size, self.image_size, 3))#变成四维
result = self.detect_from_cvmat(inputs)[0] #只有一张图片
for i in range(len(result)): #同时存放多个类型的物体
result[i][1] *= (1.0 * img_w / self.image_size) #位置缩放 坐标的尺寸 原图于标准化的缩放变化
result[i][2] *= (1.0 * img_h / self.image_size)
result[i][3] *= (1.0 * img_w / self.image_size)
result[i][4] *= (1.0 * img_h / self.image_size)
return result
def detect_from_cvmat(self, inputs): #预测测试集的结果
net_output = self.sess.run(self.net.logits,
feed_dict={self.net.images: inputs})
results = []
for i in range(net_output.shape[0]): #批次处理图片数量 net_output = None*1470
results.append(self.interpret_output(net_output[i])) #一次处理一个卷积结果
return results #(sum(batch)xnum)x(class,xc,yc,w,h,score)
def interpret_output(self, output): #将预测结果转换,变成对应图像上的实际长宽,以及总共预测有多少个类别,返回预测结果
#将各维信息提取出来
probs = np.zeros((self.cell_size, self.cell_size,
self.boxes_per_cell, self.num_class))
class_probs = np.reshape(
output[0:self.boundary1],
(self.cell_size, self.cell_size, self.num_class))
scales = np.reshape(
output[self.boundary1:self.boundary2],
(self.cell_size, self.cell_size, self.boxes_per_cell))
boxes = np.reshape(
output[self.boundary2:],
(self.cell_size, self.cell_size, self.boxes_per_cell, 4))
offset = np.array(
[np.arange(self.cell_size)] * self.cell_size * self.boxes_per_cell)
offset = np.transpose(
np.reshape(
offset,
[self.boxes_per_cell, self.cell_size, self.cell_size]),
(1, 2, 0))
boxes[:, :, :, 0] += offset #加上x方向的Xcell偏置,就是还原回原图大小的位置
boxes[:, :, :, 1] += np.transpose(offset, (1, 0, 2)) #y也一样
boxes[:, :, :, :2] = 1.0 * boxes[:, :, :, 0:2] / self.cell_size #得到真实的(xc,yc)=>最后一维为真正计算的量,其他维数为位置上的对应关系
boxes[:, :, :, 2:] = np.square(boxes[:, :, :, 2:]) #之前开方的,平方回来
boxes *= self.image_size
for i in range(self.boxes_per_cell):
for j in range(self.num_class):
probs[:, :, i, j] = np.multiply(
class_probs[:, :, j], scales[:, :, i]) #计算框的类概率 P(c) * P(o|c) = P(o)
#分割阈值,概率大于等于1的保留
filter_mat_probs = np.array(probs >= self.threshold, dtype='bool')#高于阈值的才要,不是0就是1
filter_mat_boxes = np.nonzero(filter_mat_probs) #不为0的记录
boxes_filtered = boxes[filter_mat_boxes[0],
filter_mat_boxes[1], filter_mat_boxes[2]] #前三行要筛选,筛选所有非零元素值,返回二维数组
probs_filtered = probs[filter_mat_probs] #筛选出所有非0元素值 一维list
classes_num_filtered = np.argmax( #返回轴3上值为1的三位索引,构成数组的位置
filter_mat_probs, axis=3)[
filter_mat_boxes[0], filter_mat_boxes[1], filter_mat_boxes[2]]
argsort = np.array(np.argsort(probs_filtered))[::-1] #按照概率从大到小排列
boxes_filtered = boxes_filtered[argsort]
probs_filtered = probs_filtered[argsort]
classes_num_filtered = classes_num_filtered[argsort]
for i in range(len(boxes_filtered)): #nms非极大值抑制
if probs_filtered[i] == 0:
continue
for j in range(i + 1, len(boxes_filtered)):
if self.iou(boxes_filtered[i], boxes_filtered[j]) > self.iou_threshold: #计算两个框的重合度,如果重合度超过阈值就舍弃
probs_filtered[j] = 0.0 #避免重复操作,从第一个开始递归
filter_iou = np.array(probs_filtered > 0.0, dtype='bool') #最后筛选出来的结果,有几个非零值,就有几个目标物体
boxes_filtered = boxes_filtered[filter_iou] #得到目标的box
probs_filtered = probs_filtered[filter_iou] #得到目标的得分
classes_num_filtered = classes_num_filtered[filter_iou] #得到目标的class
'''
上述将高维矩阵中非零元素转化为低维数组的方法实例如下
import numpy as np
a = np.array([[0,0,3],[0,0,0],[0,0,9]])
b = np.nonzero(a) #output:(array([0,2],dtype=int64),array([2,2]),dtype=int64),将三维数组的非0元素转成了一维数组输出了
b[0] #output:(array[0,2],dtype=int64)
c = a>0 #output:array([false,false,true],
# [false,false,false],
# [false,false,true])
a[c] #转成了低维输出 array([3,9])
a[b] #和a[c]结果一样 array([3,9])
'''
result = []
for i in range(len(boxes_filtered)):
result.append(
[self.classes[classes_num_filtered[i]],
boxes_filtered[i][0],
boxes_filtered[i][1],
boxes_filtered[i][2],
boxes_filtered[i][3],
probs_filtered[i]])
return result #返回num X (class,xc,yc,w,h,score)
def iou(self, box1, box2): #计算重合区域
tb = min(box1[0] + 0.5 * box1[2], box2[0] + 0.5 * box2[2]) - \
max(box1[0] - 0.5 * box1[2], box2[0] - 0.5 * box2[2])
lr = min(box1[1] + 0.5 * box1[3], box2[1] + 0.5 * box2[3]) - \
max(box1[1] - 0.5 * box1[3], box2[1] - 0.5 * box2[3])
inter = 0 if tb < 0 or lr < 0 else tb * lr
return inter / (box1[2] * box1[3] + box2[2] * box2[3] - inter)
def camera_detector(self, cap, wait=10): #计算检测时间,拍照功能
detect_timer = Timer()
ret, _ = cap.read()
while ret:
ret, frame = cap.read()
detect_timer.tic()
result = self.detect(frame)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(
detect_timer.average_time))
self.draw_result(frame, result)
cv2.imshow('Camera', frame)
cv2.waitKey(wait)
ret, frame = cap.read()
def image_detector(self, imname, wait=0): #检测直接用图片的检测时间
detect_timer = Timer()
image = cv2.imread(imname)
detect_timer.tic()
result = self.detect(image)
detect_timer.toc()
print('Average detecting time: {:.3f}s'.format(
detect_timer.average_time))
self.draw_result(image, result)
cv2.imshow('Image', image)
cv2.waitKey(wait)
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', default="YOLO_small.ckpt", type=str)
parser.add_argument('--weight_dir', default='weights', type=str)
parser.add_argument('--data_dir', default="data", type=str)
parser.add_argument('--gpu', default='', type=str)
args = parser.parse_args()
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu
yolo = YOLONet(False) #False--测试,True--训练
weight_file = os.path.join(args.data_dir, args.weight_dir, args.weights) #拿出训练好的权重文件
detector = Detector(yolo, weight_file)
# detect from camera #实时拍照检测时用
# cap = cv2.VideoCapture(-1)
# detector.camera_detector(cap)
# detect from image file #拿图片来测试
imname = 'test/person.jpg'
detector.image_detector(imname)
if __name__ == '__main__':
main()















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









