







后向传播算法应用中的问题
1. 回顾
在上两讲中,我们讲解了如何利用后向传播算法训练多层神经网络,我们总结出了后向传播算法的基本框架,包含以下步骤:
(1)对神经网络每一层的各个神经元,随机选取相应的 w , b w,b w,b 的值。
(2)前向计算,对于输入的训练数据,计算并保留每一层的输出值,直到计算出最后一层的输出 y y y 为止。
(3)设置目标函数 E E E,例如 : E = 1 2 ∣ ∣ y − Y ∣ ∣ 2 :E=\frac12||y-Y||^2 :E=21∣∣y−Y∣∣2,用后向传播算法对每一个 w w w和 b b b,计算 ∂ E ∂ w \frac{∂E}{∂w} ∂w∂E和 ∂ E ∂ b \frac{∂E}{∂b} ∂b∂E。
(4)利用如下迭代公式,更新 w w w和 b b b的值
w ( n + 1 ) = w ( n ) − α ∂ E ∂ w ∣ w ( n ) , b ( n ) w^{(n+1)}=w^{(n)}-α{\frac{∂E}{∂w}|}_{w^{(n)},b^{(n)}} w(n+1)=w(n)−α∂w∂E∣w(n),b(n)
b ( n + 1 ) = b ( n ) − α ∂ E ∂ b ∣ w ( n ) , b ( n ) b^{(n+1)}=b^{(n)}-α{\frac{∂E}{∂b}|}_{w^{(n)},b^{(n)}} b(n+1)=b(n)−α∂b∂E∣w(n),b(n)
其中 α α α是一个超参数,叫作学习率。
(5)回到(2)不断循环,直到所有 ∣ ∂ E ∂ w ∣ w ( n ) , b ( n ) |\frac{∂E}{∂w}|_{w^{(n)},b^{(n)}} ∣∂w∂E∣w(n),b(n), ∣ ∂ E ∂ b ∣ w ( n ) , b ( n ) |\frac{∂E}{∂b}|_{w^{(n)},b^{(n)}} ∣∂b∂E∣w(n),b(n)很小为止,退出循环。
但是,在实际的应用中,我们却需要对上述基本框架进行一系列的改进,才能保证神经网络训练过程的顺利完成,这一讲将重点讲解三个重要的改进。学习完本讲后,大家可以利用多层神经网络解决实际分类的问题。
2. 对非线性函数的改进
第一个改进是对非线性函数的改进,我们前面提到,如果层与层之间的非线性函数是阶跃函数,即如下所示
φ ( x ) = { 1 , x > 0 0 , x < 0 φ(x)=\begin{cases} 1, & x>0\\ 0, & x<0 \end{cases} φ(x)={
1,0,x>0x<0
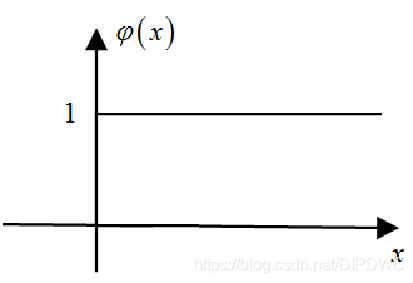
如果非线性函数是阶跃函数,那么三层神经网络可以模拟任意的决策函数。我们回顾一下上一讲后向传播算法的递推公式
δ i ( l ) = ∂ E ∂ z i ( l ) = ∂ E ∂ y i ∂ y i ∂ z i ( l ) = ( y i − Y i ) φ ′ ( z i ( l ) ) δ_i^{(l)}=\frac {∂E}{∂z_i^{(l)}}=\frac {∂E}{∂y_i}\frac {∂y_i}{∂z_i^{(l)}}=(y_i-Y_i)φ'(z_i^{(l)}) δi(l)=∂zi(l)∂E=∂yi∂E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1647
1647











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









