







转载自:
DJJ补充:
数据缩放在机器学习中是一种常见的预处理步骤,其主要目的是确保特征具有相似的尺度,以避免某些特征对模型的训练产生过大的影响。这在使用基于距离的算法(例如支持向量机、k-最近邻等)或梯度下降优化的算法(例如线性回归、神经网络等)时尤为重要。
随机森林是一种基于树的集成算法,它通常不受特征尺度的影响,因为树的分割是基于特征的排序而不是具体的数值。因此,对于随机森林等基于树的算法,数据缩放通常不是必需的步骤。
最近在自学图灵教材《Python机器学习基础教程》,在csdn以博客的形式做些笔记。
在监督学习中,有神经网络和SVM等算法对数据缩放十分敏感。通常做法是对特征进行调节,使数据表示更适合于这些算法。通常来说,这是对数据的一种简单的按特征的缩放和移动。
---------------------------------------------------------------------------------------------------------------------------------
常用缩放方法
下图为数据缩放的几种方法: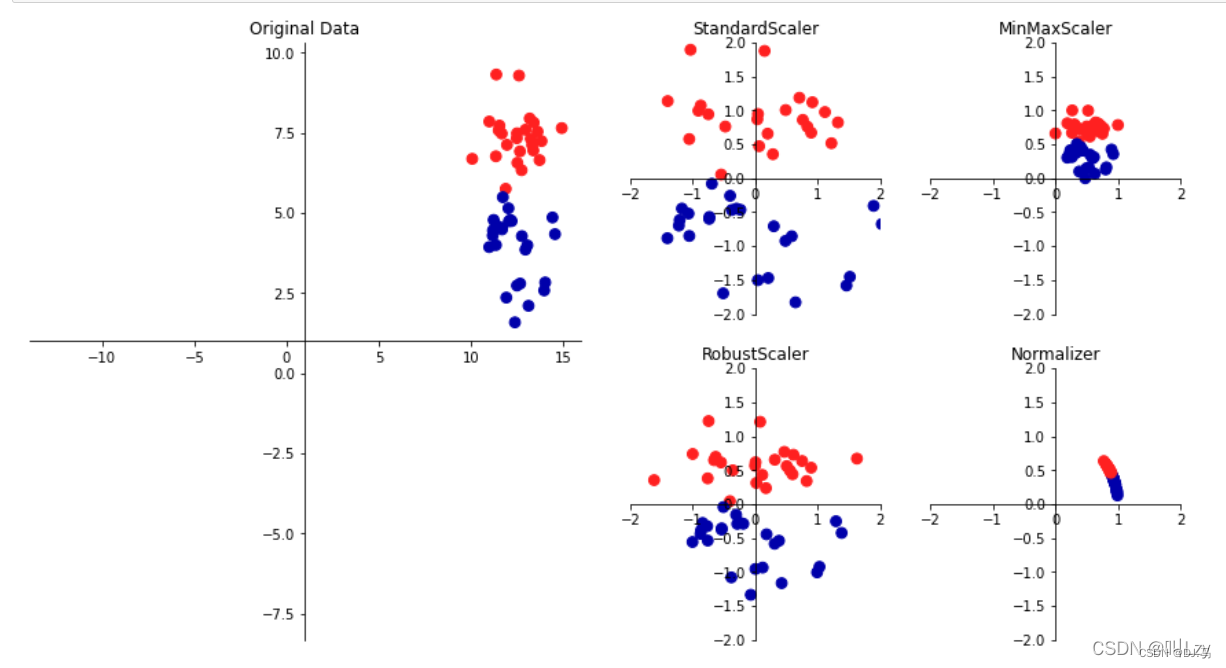
上图中,最左边的是有两个特征的二分类原始数据集。而又边的四幅图则为四种数据变换的方法。其中StandardScaler确保每个特征的平均值为0,方差为1,这使得所有特征值都属于同一个量级,但这种方法无法保证任何特定的最大值和最小值。
RobustScaler和StandardScaler相似,只不过它采用的是中位数和四分位数,因此RobustScaler会忽略与其他点有很大差别的数据点(异常值)。
MinMaxScaler 则移动数据,使得所有特征都刚好位于0和1之间。对于二维数据集来说,所有数据都会被包含在x轴0到1与y轴0到1的矩阵之中。
而Normalizer则用到一种完全不同的缩放方法,其对每个数据集进行缩放,使得特征向量的欧式长度等于1;也就是说它会将数据点投射到半径为1的圆上(更高维的则为球),因此每一个数据点的缩放比例都不相同,如果只有数据的方向(或角度)是重要的,而特征向量的长度无关紧要,则适宜采取这种归一化。
应用数据变换
我们在此对scikit-learn自带数据集cancer进行应用,假设我们想将核SVM应用在cancer数据集上,并使用MinMaxScaler来进行预处理。
首先对数据进行拆分
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=1)
print(X_train.shape)
print(X_test.shape)
##out:
##(426,30)
##(143,30)接下来导入实现预处理的类,然后将其实例化,再使用 fit 方法拟合缩放器(scaler),并将其应用于训练数据。对于 MinMaxScaler 来 说,fit 方法计算训练集中每个特征的最大值和最小值。
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(X_train)为了应用刚刚学习的变换(即对训练数据进行实际缩放),我们使用缩放器的 transform 方法。在 scikit-learn 中,每当模型返回数据的一种新表示时,都可以使用 transform 方法
X_train_scaled=scaler.transform(X_train)
print("transformed shape:{}".format(X_train_scaled.shape))
print("per-feature minimum before scaling:\n {}".format(X_train.min(axis=0)))
print("per-feature maximum before scaling:\n {}".format(X_train.max(axis=0)))
print("per-feature minimum after scaling:\n {}".format(X_train_scaled.min(axis=0)))
print("per-feature maximum after scaling:\n {}".format(X_train_scaled.max(axis=0)))
变换后的数据形状与原始数据相同,特征只是发生了移动和缩放。你可以看到,现在所有特征都位于0到1之间,这也符合我们的预期。为了将 SVM 应用到缩放后的数据上,还需要对测试集进行变换。这可以通过对 X_test 调 用 transform 方法来完成
对训练数据和测试数据进行相同的缩放
为了让监督模型能够在测试集上运行,对训练集和测试集应用完全相同的变换是很重要的。如果我们使用测试集的最小值和范围,看看接下来这样一个案例:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 构造数据
X, _ = make_blobs(n_samples=50, centers=5, random_state=4, cluster_std=2)
# 将其分为训练集和测试集
X_train, X_test = train_test_split(X, random_state=5, test_size=.1)
# 绘制训练集和测试集
fig, axes = plt.subplots(1, 3, figsize=(13, 4))
axes[0].scatter(X_train[:, 0], X_train[:, 1],c=mglearn.cm2(0), label="Training set", s=60)
axes[0].scatter(X_test[:, 0], X_test[:, 1], marker='^',c=mglearn.cm2(1), label="Test set", s=60)
axes[0].legend(loc='upper left')
axes[0].set_title("Original Data")
# 利用MinMaxScaler缩放数据
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 将正确缩放的数据可视化
axes[1].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1],c=mglearn.cm2(0), label="Training set", s=60)
axes[1].scatter(X_test_scaled[:, 0], X_test_scaled[:, 1], marker='^',c=mglearn.cm2(1), label="Test set", s=60)
axes[1].set_title("Scaled Data")
# 单独对测试集进行缩放
# 使得测试集的最小值为0,最大值为1
# 千万不要这么做!这里只是为了举例
test_scaler = MinMaxScaler()
test_scaler.fit(X_test)
X_test_scaled_badly = test_scaler.transform(X_test)
# 将错误缩放的数据可视化
axes[2].scatter(X_train_scaled[:, 0], X_train_scaled[:, 1],c=mglearn.cm2(0), label="training set", s=60)
axes[2].scatter(X_test_scaled_badly[:, 0], X_test_scaled_badly[:, 1],marker='^', c=mglearn.cm2(1), label="test set", s=60)
axes[2].set_title("Improperly Scaled Data")
for ax in axes:
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")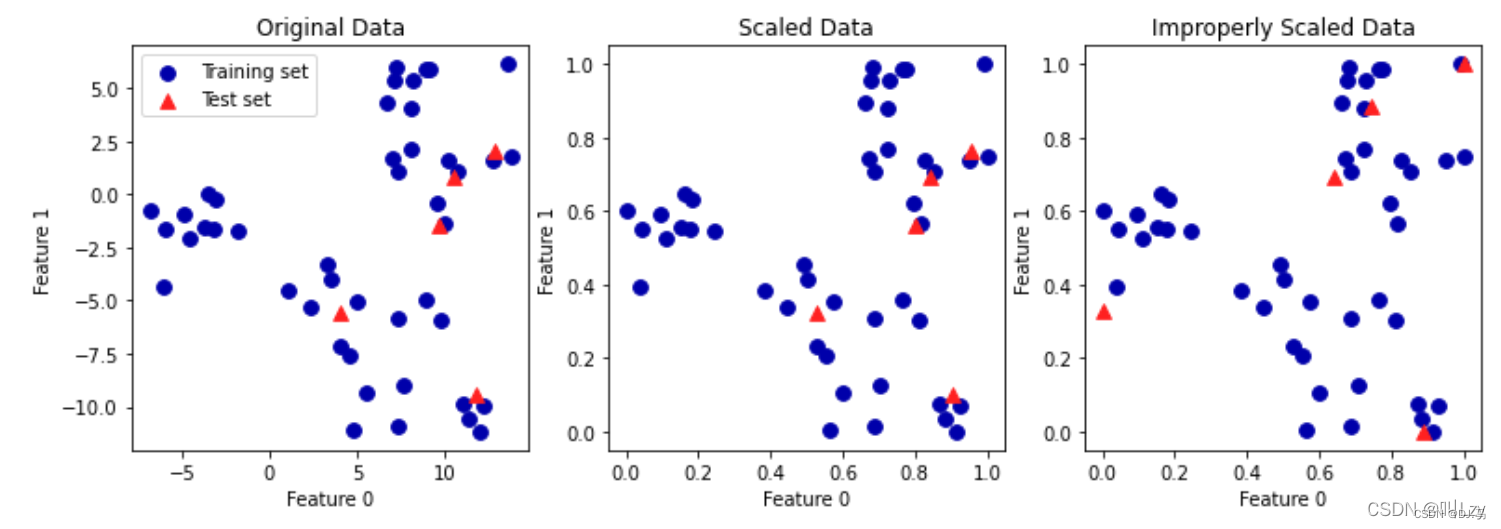
第一张图是未缩放的二维数据集,其中训练集用圆形表示,测试集用三角形表示。第二张 图中是同样的数据,但使用 MinMaxScaler 缩放。这里我们调用 fit 作用在训练集上,然后 调用 transform 作用在训练集和测试集上。你可以发现,第二张图中的数据集看起来与第 一张图中的完全相同,只是坐标轴刻度发生了变化。现在所有特征都位于 0 到 1 之间。你 还可以发现,测试数据(三角形)的特征最大值和最小值并不是 1 和 0。 第三张图展示了如果我们对训练集和测试集分别进行缩放会发生什么。在这种情况下,对 训练集和测试集而言,特征的最大值和最小值都是 1 和 0。但现在数据集看起来不一样。 测试集相对训练集的移动不一致,因为它们分别做了不同的缩放。我们随意改变了数据的排列。这显然不是我们想要做的事情。
预处理对监督学习的作用
回到 cancer 数据集,观察使用 MinMaxScaler 对学习 SVC 的作用
首先看svc对原始数据集的处理效果
from sklearn.svm import SVC
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
random_state=0)
svm = SVC(C=100)
svm.fit(X_train, y_train)
print("Test set accuracy: {:.2f}".format(svm.score(X_test, y_test)))![]()
准确率达到了百分之94,这已经非常高了,接下来我们可以看看svc对于进行了预处理的数据集的处理效果
# 使用0-1缩放进行预处理
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 在缩放后的训练数据上学习SVM
svm.fit(X_train_scaled, y_train)
# 在缩放后的测试集上计算分数
print("Scaled test set accuracy: {:.2f}".format(
svm.score(X_test_scaled, y_test)))![]()
我们发现准确率更高了,达到了97% 。
正如我们上面所见,数据缩放的作用非常好(在上面的例子由于原有数据的得分就非常高,所以提升不是很大)。虽然数据缩放不涉及任何复杂的数学,但 良好的做法仍然是使用 scikit-learn 提供的缩放机制,而不是自己重新实现它们,因为即使在这些简单的计算中也容易犯错。















 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









