







以下是设立随机数和随机噪声的code:
设定随机数的方法有很多,下面代码是通过numpy的API设定随机数,除了numpy,实际上scikit,tf,pytorch都有设定随机数的API的
# Set a random seed for reproducibility(01modifiy)加入随机数的代码最好是在第一行
np.random.seed(200)
# 数据集拆分
X, y = np.array(dataset['Smiles']), np.array(dataset['pIC50'])
# Add random noise to the target variable y(01modify)
noise_factor = 0.1 # You can adjust this value based on the amount of noise you want
y_with_noise = y + np.random.normal(0, noise_factor, size=len(y))
# Split the dataset with noisy target variable(01modify)
X_train, X_test, y_train, y_test = train_test_split(X, y_with_noise, test_size=0.3)以下是未加入随机噪声的code:
# 数据集拆分
X, y = np.array(dataset['Smiles']), np.array(dataset['pIC50'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)以01modifySVM.py为例:
加入随机噪声后结果
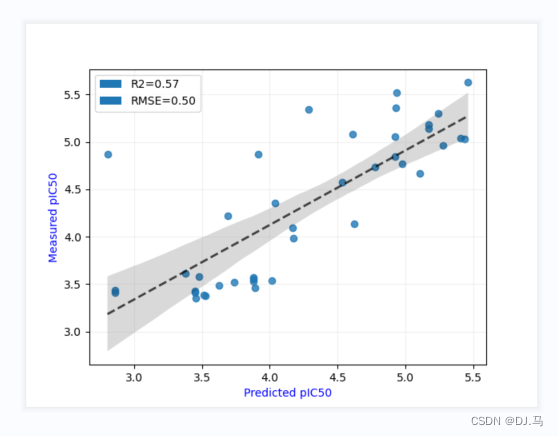
未加入随机噪声的结果:
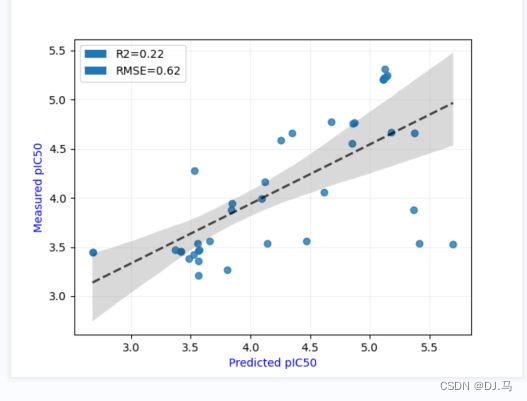
我们发现加入随机噪声后,效果更好。
我们知道,加入随机数的目的,是让结果可重复性,可控。加入随机噪声的原因是提高鲁棒性,因为现实情况实际上是有噪声的(如实验测活的误差)。
关于随机数的选取:
#这是某篇文章的插入随机的方案,就按梯度设置一系列随机数
for randx in [8,12,42,50,65,78,105]:
spliter = randomSpliter(test_size=0.25,random_state=randx)
spliter.ExtractTotalData(file,label_name='label')
spliter.SplitData()
tr_x = spliter.tr_x
tr_y = spliter.tr_y
te_y = spliter.te_y这里我们知道一点,如果只是发文章的话,可以挑取效果好的随机数,但是实际上我们要知道一点,如果模型受到随机数的影响较大,那只能说明模型不咋地。
















 1596
1596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











