







1. Swin Transformer的动机:
1.追求AI(NLP 和 CV)的统一性:
过去一个世纪,物理学界一直在追求四种相互作用力的统一,另外,下图右图是2000年Science的一篇文章,用小白鼠做的一个实验,验证说大脑的神经皮层其实是通用的,本来用于处理听觉信号的神经元,同时可以被训练来用于视觉信号。

这就激励作者思考如何在AI领域去进行统一的建模,作者认为Transformer是非常具有潜力的,第一是因为它是基于图的建模,图是很通用的结构,几乎可以表达任何概念(抽象的或具体的)以及它们之间的关系;第二是因为它是基于验证性的哲学来构建概念间的关系,不管输入是什么(文本、图像),都可以投影到一个子空间中进行比较,这样就都可以进行建模了。

2020年有个工作是ViT,虽然动机也是迈向NLP和CV领域的统一建模,但是其做法比较暴力直接,直接将图像划分Patch输入到Transformer中,最后得到输出。

虽然ViT取得了很好的指标,证明了Transformer可以作为统一NLP和CV领域比较general的框架,但是即使Transformer可以充当一种general的框架应用于CV领域中,也应该做一些 “适配” 来适应于视觉信号。也就是说ViT工作忽略了视觉信号与文本信号之间的差异。
2. 文本信号与视觉信号的差异:
- 文本数据中没有不同尺度的信息,不需要处理不同尺度的问题
- 文本数据中不具备视觉数据中的平移不变性。

也正是由于ViT没有考虑视觉信号与文本信号的差异,它只适合做图像分类问题,如果拿去做更细粒度的问题时效果就不好,比如说目标检测、语义分割等。

因此SwinTransformer想做的是:让Transformer与视觉信号的特点做结合,更好的建模视觉信号。(把视觉信号的先验引入到Transformer中)
- Shifted windows的由来
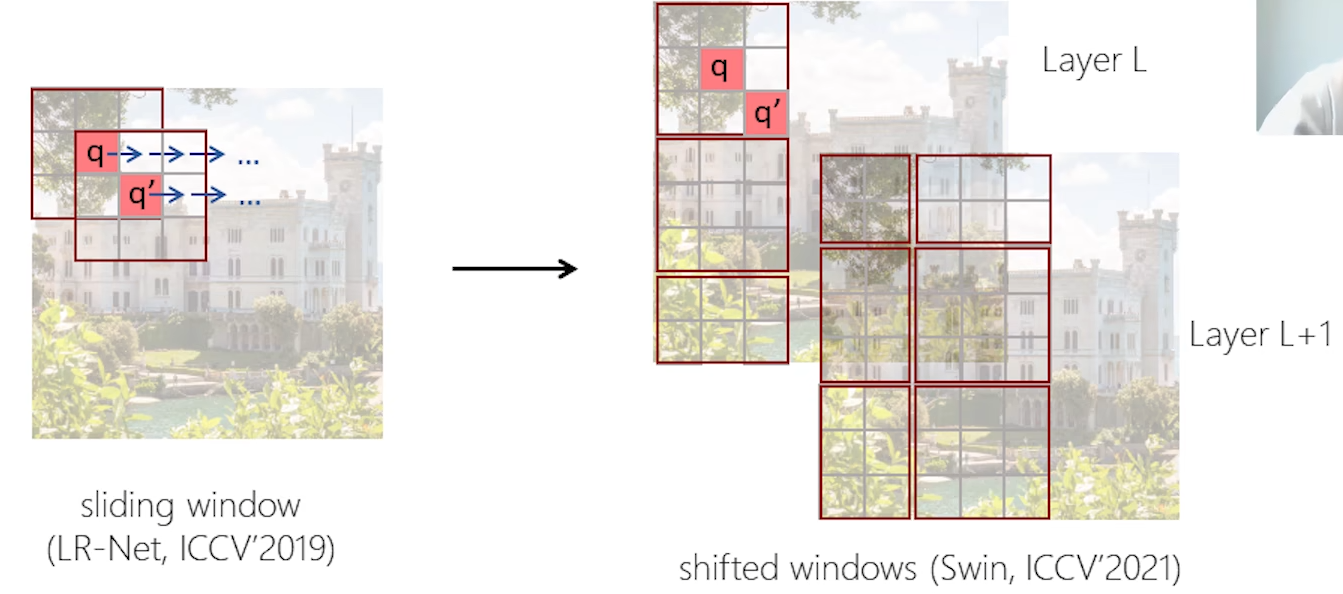
其实在ViT之前,作者在早些年就尝试了将Transformer用于视觉的backbone建模,论文在此, 在之前的这个工作中作者将卷积里的Sliding window引入进来,但是发现Sliding window对计算不是很友好。
因此作者在看ViT文章的时候,发现了ViT在和ResNet具有相同理论计算量的情况下,要比ResNet快50%了,这与之前作者之前的工作对计算不是很友好,于是作者就去分析原因,发现核心原因就是(重点来了):不同的query其实在共享key的集合。ViT中并没有专门的考虑这个问题,但是因为正好做了一个global的计算,所以就有了这个特性。于是作者就思考如何将这么一个比较好的特性与视觉里面的几个先验结合起来,于是就有了SwinT中的不重叠窗口设计以及shifted window设计。
2. Swin Transformer的做法:
相对于ViT,SwinT引入了视觉信号中几种性质:层次性(hierarchy)、局部性(locality)、平移不变性(translation invariance)
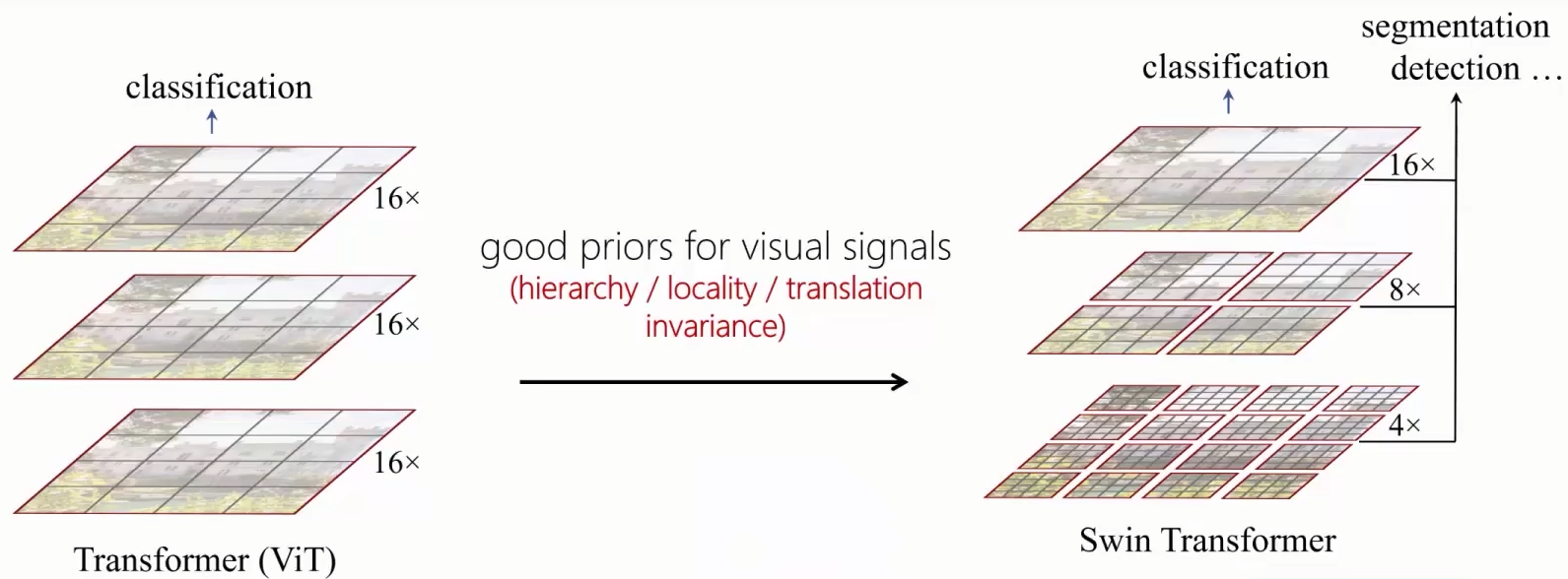
一开始的时候划分很多小的patch,这样的目的是可以构造高分辨率的输出,随着网络变深,会做一些patch之间的融合,这样就可以生成一些低分辨率的图片,也就是说可以生成不同层次的语义图片。
在计算时,会将计算限制在局部的框内,这样就可以构造局部的约束,相当于引入视觉信号的局部性。除此之外,想要实现这种将视觉信号的局部性先验引入到Transformer中,一个比较直接的计算方法就是像CNN那样做sliding window。但是sliding window对CNN的计算很友好,但是对于Transformer的计算不是很友好,就是不同的query采用的key不同,但是其实在计算时很多的元素是重复的,这样计算量就比较大。SwinT的做法是(以下图为例):首先,做窗口划分时,做成不重叠的窗口,对不同的query做计算时(q和q’),他们会共享相同的key(同一个红色的框内),这样就会使得计算比较友好。但是,这样做的话不同的窗口之间并没有信息交互,因此SwinT就设计了一个其核心的思想----shifted windows: L+1层对比于L层,会对窗口的划分进行平移,平移之后就可以使得这一层里面,实现上一层窗口间信息的交换成为可能。
最后:
本文章是个人在看B站【沈向洋带你读论文】对Swin Transformer解读这期视频时的笔记,链接在此。
个人认为视频中老师讲解的SwinT的动机和思考是更具有价值的,另外两位老师也分享了一些科研感悟,觉得也很有道理:
做学问不太可能是横空出世的,其实在ViT出现之前两年,SwinT的作者胡瀚老师就在思考AI模型关于NLP、CV领域的大一统。一篇好的工作果然需要不断地积累和思考,要坚持。
Aim high,做科研要aim high,写一篇烂的文章要花时间,写一篇好的文章也要花时间,那为什么不花时间写一篇好的文章。















 1289
1289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









