







 本文深入探讨了SwinTransformer,一种克服ViT计算复杂度和尺度问题的Transformer模型。SwinTransformer引入了层次化结构和局部窗口注意力,通过PatchEmbedding、PatchMerging和ShiftedWindowAttention降低计算复杂度,实现线性复杂度。模型在保持局部性和全局信息的同时,提高了效率,适用于图像分类、目标检测和语义分割等任务。
本文深入探讨了SwinTransformer,一种克服ViT计算复杂度和尺度问题的Transformer模型。SwinTransformer引入了层次化结构和局部窗口注意力,通过PatchEmbedding、PatchMerging和ShiftedWindowAttention降低计算复杂度,实现线性复杂度。模型在保持局部性和全局信息的同时,提高了效率,适用于图像分类、目标检测和语义分割等任务。
这里写目录标题
论文详情
名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
地址:原论文
代码:代码地址
视频讲解:
1李沐
2胡瀚研究员:Swin Transformer和拥抱Transformer的五个理由
3霹雳吧啦Wz-Swin-Transformer网络结构详解
笔记参考:
1李沐b站视频讲解笔记
2笔记解释
3霹雳吧啦Wz
4胡瀚研究员:Swin Transformer和拥抱Transformer的五个理由
专访 Swin Transformer 作者胡瀚:面向计算机视觉中的「开放问题
6.2021-Swin Transformer Attention机制的详细推导
7.详解Swin Transformer核心实现,经典模型也能快速调优
8.很好:理论+代码【机器学习】详解 Swin Transformer (SwinT)
swin-T模块
1.SwinT-让Swin-Transformer的使用变得和CNN一样方便快捷
VIT缺点
应用:
ViT主要针对图像分类问题设计,不适合作为通用 模型的backbone,也不适合更细粒度的识别问题(如目标检测、分割等)
vit实现过程:
ViT通过将图像均分成不相交的patch,通过编码每个patch然后计算两两patch之间的self-attention,来实现聚合信息,即聚合全局信息。
简述:直接将图片切割成相同大小的块,做全局Transformer
缺点:应对更高清的图片时,划分的patch数会受计算资源掣肘。
你可以这么想,4x4=16个patch,两两计算自注意力,和100x100=10000个patch,两两计算自注意力,计算复杂度完全不一样(前者的计算16x16次,后者计算 10000x10000 次,即计算复杂度跟 (HxW)平方呈线性关系)
改进点
目前Transformer应用到图像领域主要有两大挑战:
1一个就是尺度上的问题。
图片的scale变化非常大,非标准固定的
因为比如说现在有一张街景的图片,里面有很多车和行人,里面的物体都大大小小,那这时候代表同样一个语义的词,比如说行人或者汽车就有非常不同的尺寸,这种现象在 NLP 中就没有
2.计算复杂度高:
图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
CV中使用Transformer的计算复杂度是图像尺度的平方(Self-Attention 需要对输入的所有N个 token 计算 [公式] 大小的相互关系矩阵,考虑到视觉信息本来就就是二维(图像)甚至三维(视频),分辨率稍微高一点这计算量就很难低得下来。),这会导致计算量过于庞大。
为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:
- 引入CNN中常用的层次化构建方式构建层次化Transformer
- 引入locality思想,对无重合的window区域内进行self-attention计算。
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。
移动窗口的优点:
不仅带来了更大的效率,因为跟之前的工作一样,现在自注意力是在窗口内算的,所以这个序列的长度大大的降低了;
同时通过 shifting 移动的这个操作,能够让相邻的两个窗口之间有了交互,所以上下层之间就可以有 cross-window connection,从而变相的达到了一种全局建模的能力
这种层级式的结构不仅非常灵活,可以提供各个尺度的特征信息,同时因为自注意力是在小窗口之内算的,所以说它的计算复杂度是随着图像大小而线性增长,而不是平方级增长,
将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
概述
1.SwinTransformer想设计一个可以作为密集预测任务的Transformer Backbone,其采用PatchMerging的策略,构建了层次化的特征,使得其可以作为密集预测任务的Backbone。
2.同时考虑到密集预测任务中,tokens数目太多导致计算量过大的问题,其采用一种在local window内部计算Self-Attention的机制去降低计算复杂度,使得整体计算复杂度由O(N^2)降低至O(N)水平。
3.为了弥补Local Self-Attention带来了远程依赖关系缺失的问题,其创新性地采用了Shift Window操作,引入了不同window之间的关系,并且在精度以及速度上都超越了简单的Sliding Window的方法。
是Transformer在Local Attention策略上的一次不错的尝试。
核心思想
Swin Transformer就是想让 Vision Transformer像卷积神经网络一样,也能够分成几个 block,也能做层级式的特征提取,从而导致提出来的特征有多尺度的概念
原生 Transformer 对 N 个 token 做 Self-Attention ,复杂度为 NxN,
Swin Transformer 将 N 个 token 拆为 N/n 组, 每组 n (n设为常数)个token 进行计算,复杂度降为 [N*nxn] ,考虑到 n 是常数,那么复杂度其实为N。
分组计算的方式虽然大大降低了 Self-Attention 的复杂度,但与此同时,有两个问题需要解决,
其一是分组后 Transformer 的视野局限于 n 个token,看不到全局信息,
其二是组与组之间的信息缺乏交互。
对于问题一,Swin Transformer 的解决方案即 Hierarchical,每个 stage 后对 2x2 组的特征向量进行融合和压缩(空间尺寸HxW变成0.5Hx0.5W,特征维度C->4C->2C ),这样视野就和 CNN-based 的结构一样,随着 stage 逐渐变大。
对于问题二,Swin Transformer 的解决方法是 Shifted Windows,
整个SwinTRM 其实最重要的就两个点:
一个点是相对位置信息,
一个是移动窗口注意力机制;把握住这两个点,对SwinTRM的理解就到位;
其中相对位置信息的核心点在于可以把每种相对位置信息和att对应的一行信息对应上;
移动窗口注意力机制核心点在于mask,mask矩阵的生成是通过窗口索引tensor相减得到的;
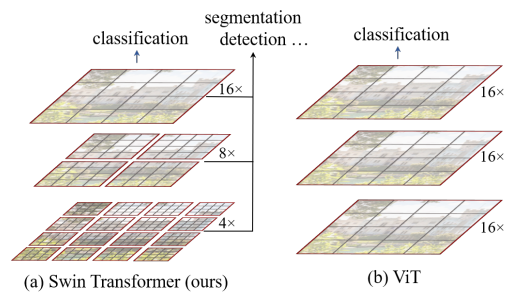
优点:
3. 相比于ViT,Swin Transfomer 计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。
4. Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
整体结构
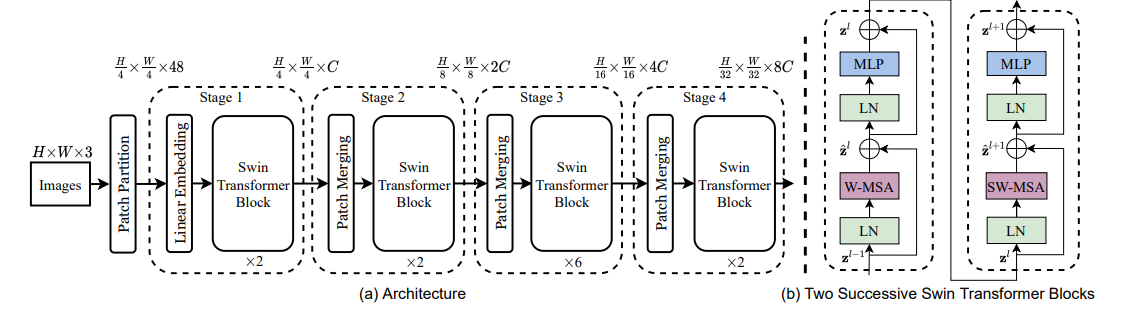
整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
- 在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。
- 在每个Stage里,由Patch Merging和多个Block组成
- Patch Merging模块主要在每个Stage一开始降低图片分辨率
- Block具体结构如右图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成
名称解释 Window、Patch、Token
假设输入图片的尺寸为224X224,先划分成多个大小为4x4像素的小片,每个小片之间没有交集。
- 224/4=56,那么一共可以划分56x56个小片。每一个小片就叫一个patch,
- 每一个patch将会被对待成一个token。所以patch=token。
- 而一张图被划分为7x7个window,每个window之间也没有交集。那么每个window就会包含8x8个patch。
与vit区别
1 与ViT一样对于输入的图像信息先做一个PatchEmbed操作将图像进行切分后打成多个pa
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









