







Swin Trasnformer
Swin Transformer是由微软亚洲研究院在2021年提出的一种新型的Transformer架构,专为计算机视觉任务设计。它在多个基准数据集上取得了出色的表现,尤其是在图像分类、目标检测和图像分割等领域。
Swin Transformer的主要创新点在于解决了传统Transformer从自然语言处理迁移到计算机视觉任务时面临的两大问题:
特征尺度变化范围大:在自然语言处理中,token通常是标准固定的大小,而在计算机视觉中,特征尺度变化范围非常大。Swin Transformer通过引入CNN中常用的层次化构建方式,构建了层次化的Transformer,使其能够处理不同尺度的输入。
计算复杂度高:在计算机视觉中,使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了降低计算复杂度,Swin Transformer引入了locality思想,对无重合的窗口区域内进行self-attention计算,这种被称为shifted window attention的机制大大降低了计算复杂度。
Swin Transformer的优点包括:
高效性能:由于采用了分层结构和局部注意力机制,Swin Transformer在保持高精度的同时,具有更高的计算效率。
良好的可扩展性:Swin Transformer支持在更大的尺度上进行训练,并在处理更复杂的场景时获得更好的性能。同时,它还支持可变形卷积和自适应卷积等技术,这些技术在复杂视觉任务中具有很好的应用价值。
良好的图像识别能力:Swin Transformer在图像分类和物体检测任务中表现出了优秀的性能,不仅在多个公开数据集中达到了最优水平,还可以处理一些具有挑战性的场景,如低分辨率图像或长尾分布的数据集。
Swin Transformer可以作为图像分类、目标检测和语义分割等任务的通用骨干网络,为这些任务提供了强有力的支持。其出色的性能和广泛的应用前景,使得Swin Transformer有可能成为CNN的完美替代方案。
1. 模型介绍
Swin Transformer是由微软亚洲研究院在今年公布的一篇利用transformer架构处理计算机视觉任务的论文。Swin Transformer 在图像分类,图像分割,目标检测等各个领域已经屠榜,在论文中,作者分析表明,Transformer从NLP迁移到CV上没有大放异彩主要有两点原因:1. 两个领域涉及的scale不同,NLP的token是标准固定的大小,而CV的特征尺度变化范围非常大。2. CV比起NLP需要更大的分辨率,而且CV中使用Transformer的计算复杂度是图像尺度的平方,这会导致计算量过于庞大。为了解决这两个问题,Swin Transformer相比之前的ViT做了两个改进:1.引入CNN中常用的层次化构建方式构建层次化Transformer 2.引入locality思想,对无重合的window区域内进行self-attention计算。另外,Swin Transformer可以作为图像分类、目标检测和语义分割等任务的通用骨干网络,可以说,Swin Transformer可能是CNN的完美替代方案。
2. 模型结构
下图为Swin Transformer与ViT在处理图片方式上的对比,可以看出,Swin Transformer有着ResNet一样的残差结构和CNN具有的多尺度图片结构。
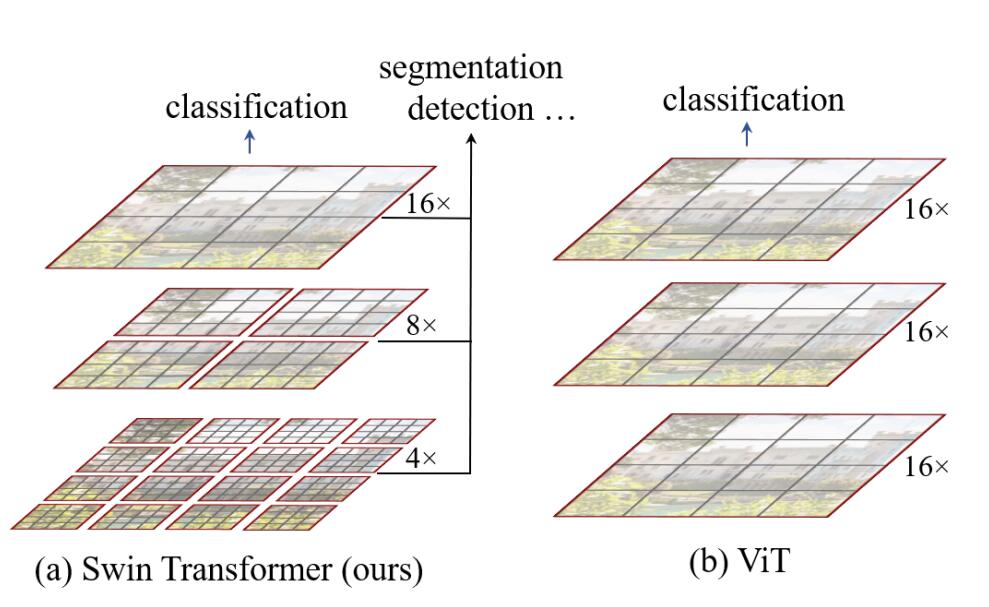
整体概括:
下图为Swin Transformer的网络结构,输入的图像先经过一层卷积进行patch映射,将图像先分割成4 × 4的小块,图片是224×224输入,那么就是56个path块,如果是384×384的尺寸,则是96个path块。这里以224 × 224的输入为例,输入图像经过这一步操作,每个patch的特征维度为4x4x3=48的特征图。因此,输入的图像变成了H/4×W/4×48的特征图。然后,特征图开始输入到stage1,stage1中linear embedding将path特征维度变成C,因此变成了H/4×W/4×C。然后送入Swin Transformer Block,在进入stage2前,接下来先通过Patch Merging操作,Patch Merging和CNN中stride=2的1×1卷积十分相似,Patch Merging在每个Stage开始前做降采样,用于缩小分辨率,调整通道数,当H/4×W/4×C的特征图输送到Patch Merging,将输入按照2x2的相邻patches合并,这样子patch块的数量就变成了H/8 x W/8,特征维度就变成了4C,之后经过一个MLP,将特征维度降为2C。因此变为H/8×W/8×2C。接下来的stage就是重复上面的过程。
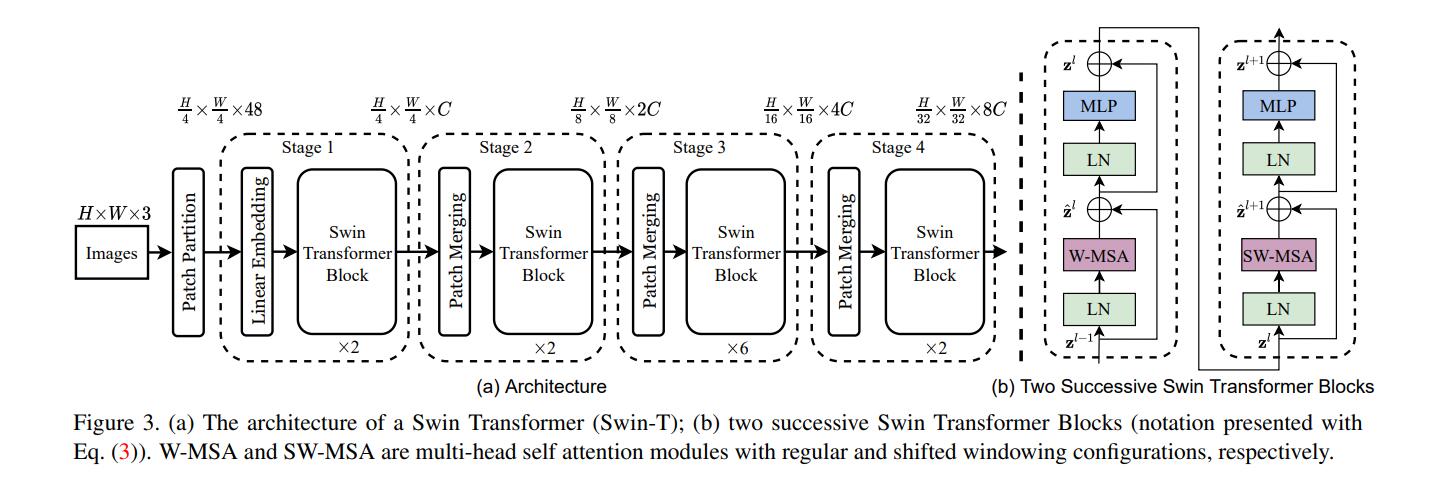
每步细说:
Linear embedding
下面用Paddle代码逐步讲解Swin Transformer的架构。 以下代码为Linear embedding的操作,整个操作可以看作一个patch大小的卷积核和patch大小的步长的卷积对输入的B,C,H,W的图片进行卷积,得到的自然就是大小为 B,C,H/patch,W/patch的特征图,如果放在第一个Linear embedding中,得到的特征图就为 B,96,56,56的大小。Paddle核心代码如下。
class PatchEmbed(nn.Layer):
""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Layer, optional): Normalization layer. Default: None
"""
def __init__(self,
img_size=224,
patch_size=4,
in_chans=3,
embed_dim=96,
norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [
img_size[0] // patch_size[0], img_size[1] // patch_size[1]
]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1] #patch个数
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2D(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) #将stride和kernel_size设置为patch_size大小
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x) # B, 96, H/4, W4
x = x.flatten(2).transpose([0, 2, 1]) # B Ph*Pw 96
if self.norm is not None:
x = self.norm(x)
return x
Patch Merging
以下为PatchMerging的操作。该操作以2为步长,对输入的图片进行采样,总共得到4张下采样的特征图,H和W降低2倍,因此,通道级拼接后得到的是B,4C,H/2,W/2的特征图。然而这样的拼接不能够提取有用的特征信息,于是,一个线性层将4C的通道筛选为2C, 特征图变为了B,2C, H/2, W/2。细细体会可以发现,该操作像极了
卷积常用的Pooling操作和步长为2的卷积操作。Pol
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5849
5849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











