







PyG代码实战
Github地址:PyG-pytoch_geometric
官方文档地址:PyG开发文档
手动防爬虫,作者CSDN:总是重复名字我很烦啊,联系邮箱daledeng123@163.com
PyG安装
1、PyG is available for Python 3.7 to Python 3.11.(安装3.7以上的python版本,推荐2017年10月3.7版本,兼容性最好)
2、You can now install PyG via Anaconda for all major OS/PyTorch/CUDA combinations 🤗 If you have not yet installed PyTorch, install it via conda as described in the official PyTorch documentation. (安装pytorch,相关教程可以直接在torch官网看,也可以去其他博主看,有cuda版本和cpu版本,我的版本如下)
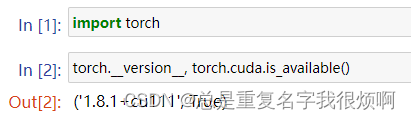
3、From PyG 2.3 onwards, you can install and use PyG without any external library required except for PyTorch. (除torch外,不需要额外安装其他依赖,直接pip安装)
!pip install torch_geometric -i https://pypi.tuna.tsinghua.edu.cn/simple
在本文代码运行过程中,如果出现其他库没有的,请自行安装。
注意:
2.3版本以上的PyG由于取消了依赖,因此有些经典代码的运行会出问题。如果安装低于2.3版本的PyG则需要手动安装依赖,具体操作可以参考知乎文章:PyG手动安装依赖步骤
图神经网络的通用代码框架撰写指南
GCN代码框架
PyG依然使用的Torch框架,因此需要对torch有一定的使用经验。在理论部分首先介绍的是GCN(图卷积模型),这个模型本质上就是嵌入向量和邻接混淆矩阵的不断左乘,因此在框架中的写法非常简单:
在框架搭建部分:
self.conv1 = GCNConv(输入节点嵌入维度, hidden_channel1)
self.conv2 = GCNConv(hidden_channel1, hidden_channel2)
...
self.convn = GCNConv(hidden_channen, 最终分类数量)
在前向传播部分:
x = self.conv1(x, 节点与节点之间的连接关系)
这里节点与节点的连接关系输入格式如下:
tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33],
[ 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 17, 19, 21, 31, 0, 2,
18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]])
GraphSAGE代码框架
class Net(torch.nn.Module): #针对图进行分类任务
def __init__(self):
super(Net, self).__init__()
self.conv1 = SAGEConv(embed_dim, 128)
self.pool1 = TopKPooling(128, ratio=0.8)
self.conv2 = SAGEConv(128, 128)
self.pool2 = TopKPooling(128, ratio=0.8)
self.conv3 = SAGEConv(128, 128)
self.pool3 = TopKPooling(128, ratio=0.8)
...
self.lin = torch.nn.Linear(128, output_dim)
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch
...
空手道俱乐部(karate club dataset)GCN代码实战
准备工作
%matplotlib inline
import matplotlib.pyplot as plt
import networkx as nx
import torch
from torch_geometric.datasets import KarateClub
from torch_geometric.utils import to_networkx
# 两个画图函数
def visualize_graph(G, color):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels = False, node_color=color, cmap='Set2')
plt.show()
def visualize_embedding(h, color, epoch=None, loss=None):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
h = h.detach().cpu().numpy()
plt.scatter(h[:,0], h[:,1], s=140, c=color, cmap='Set2')
if epoch is not None and loss is not None:
plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)
plt.show()
读取数据
dataset = KarateClub()
print(dataset)
print(len(dataset))
print(dataset.num_features)
print(dataset.num_classes)
>>KarateClub()
1
34
4
data = dataset[0]
data
>>Data(x=[34, 34], edge_index=[2, 156], y=[34], train_mask=[34])
这个表示34个样本量,每个样本34个特征,一共有156对关系,标签是34,预测的train_mask是34。
edge_index = data.edge_index
edge_index
>>tensor([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 3,
3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 6, 6, 6, 6, 7, 7,
7, 7, 8, 8, 8, 8, 8, 9, 9, 10, 10, 10, 11, 12, 12, 13, 13, 13,
13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 20, 20, 21,
21, 22, 22, 23, 23, 23, 23, 23, 24, 24, 24, 25, 25, 25, 26, 26, 27, 27,
27, 27, 28, 28, 28, 29, 29, 29, 29, 30, 30, 30, 30, 31, 31, 31, 31, 31,
31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 33, 33, 33, 33, 33,
33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33, 33],
[ 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 17, 19, 21, 31, 0, 2,
3, 7, 13, 17, 19, 21, 30, 0, 1, 3, 7, 8, 9, 13, 27, 28, 32, 0,
1, 2, 7, 12, 13, 0, 6, 10, 0, 6, 10, 16, 0, 4, 5, 16, 0, 1,
2, 3, 0, 2, 30, 32, 33, 2, 33, 0, 4, 5, 0, 0, 3, 0, 1, 2,
3, 33, 32, 33, 32, 33, 5, 6, 0, 1, 32, 33, 0, 1, 33, 32, 33, 0,
1, 32, 33, 25, 27, 29, 32, 33, 25, 27, 31, 23, 24, 31, 29, 33, 2, 23,
24, 33, 2, 31, 33, 23, 26, 32, 33, 1, 8, 32, 33, 0, 24, 25, 28, 32,
33, 2, 8, 14, 15, 18, 20, 22, 23, 29, 30, 31, 33, 8, 9, 13, 14, 15,
18, 19, 20, 22, 23, 26, 27, 28, 29, 30, 31, 32]])
这个就是156对对应关系。
可视化
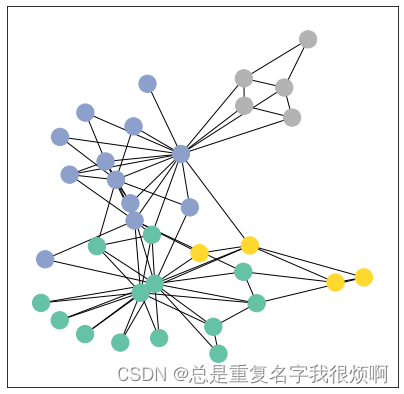
G = to_networkx(dataset[0], to_undirected=True)
visualize_graph(G, color = data.y)
GCN训练
import torch
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(1234)
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, 4)
self.conv3 = GCNConv(4, 2)
self.classifier = Linear(2, dataset.num_classes)
def forward(self, x, edge_index):
h = self.conv1(x, edge_index)
h = h.tanh()
h = self.conv2(h, edge_index)
h = h.tanh()
h = self.conv3(h, edge_index)
h = h.tanh()
out = self.classifier(h)
return out, h
model = GCN()
这里就非常简单,输入的是一个34维向量,然后经过三个GCN降到2维,然后接一个MLP把结果输出到我们需要的4分类上。
import time
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
def train(data):
optimizer.zero_grad()
out, h = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss, h
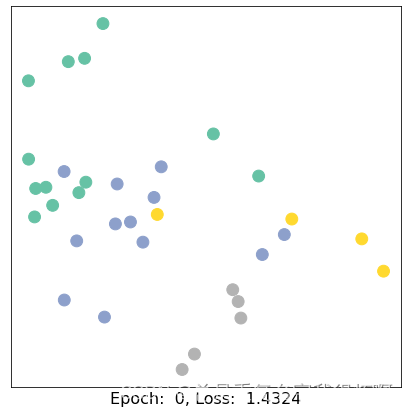
for epoch in range(401):
loss, h = train(data)
if epoch % 50 == 0:
visualize_embedding(h, color=data.y, epoch=epoch, loss=loss)
time.sleep(0.3)

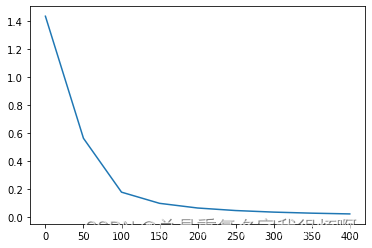
损失下降曲线
论文引用数据集(cora dataset)GCN代码实战
准备工作
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
dataset = Planetoid(root='data./Planetoid', name='Cora', transform=NormalizeFeatures())
print(dataset)
print(len(dataset))
print(dataset.num_features)
print(dataset.num_classes)
>>Cora()
1
1433
7
读取数据
data = dataset[0]
data
>>Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
2708个点,每一个点1433维,10556对连接,2708个标签
可视化
由于输出的维度是一个7维,因此需要用降维工具降到2维,这里选用sklearn的老朋友TSNE。
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
def visualize(h, color):
z = TSNE(n_components=2).fit_transform(h.detach().cpu().numpy())
plt.figure(figsize=(10,10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap='Set2')
plt.show()
MLP和GCN代码对比
import torch
import torch.nn as nn
from torch.nn import Linear
import torch.nn.functional as F
# MLP试验
class MLP(nn.Module):
def __init__(self, hidden_channels):
super().__init__()
torch.manual_seed(12345)
self.lin1 = Linear(dataset.num_features, hidden_channels)
self.lin2 = Linear(hidden_channels, dataset.num_classes)
def forward(self, x):
x = self.lin1(x)
x = x.relu()
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin2(x)
return x
mlp_model = MLP(hidden_channels=128)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
def train():
mlp_model.train()
optimizer.zero_grad()
out = mlp_model(data.x)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
mlp_model.eval()
out = mlp_model(data.x)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
mlp_acc = []
for epoch in range(1, 201):
loss = train()
if epoch % 40 == 0:
print(f'Epoch:{epoch}, Loss:{loss:4f}')
test_acc = test()
mlp_acc.append(test_acc)
# GCN
from torch_geometric.nn import GCNConv
class GCN(nn.Module):
def __init__(self, hidden_channel):
super().__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_features, hidden_channel)
self.conv2 = GCNConv(hidden_channel, dataset.num_classes)
def forward(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
x= F.dropout(x, p=0.5, training=self.training)
x = self.conv2(x, edge_index)
return x
gcn_model = GCN(hidden_channel=128)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
def train():
gcn_model.train()
optimizer.zero_grad()
out = gcn_model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
gcn_model.eval()
out = gcn_model(data.x, data.edge_index)
pred = out.argmax(dim=1)
test_correct = pred[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
gcn_acc = []
for epoch in range(1, 201):
loss = train()
if epoch % 40 == 0:
print(f'Epoch:{epoch}, Loss:{loss:4f}')
test_acc = test()
gcn_acc.append(test_acc)
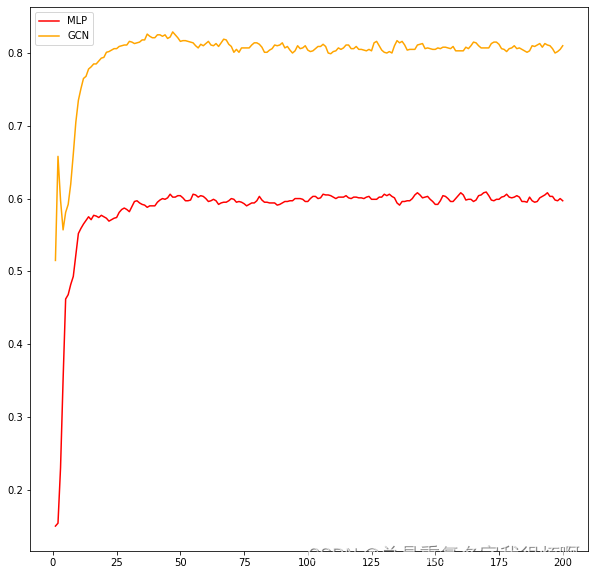
MLP和GCN准确度对比和GCN结果可视化
x = [i for i in range(1,201)]
plt.figure(figsize=(10,10))
plt.plot(x, mlp_acc, color='red', label='MLP')
plt.plot(x, gcn_acc, color='orange', label='GCN')
plt.legend()
out = model(data.x ,data.edge_index)
visualize(out, color=data.y)

构建PyG数据格式
单图和多图情景下的代码框架
PyG格式的写入主要是通过torch_geometric.data模块或torch_geometric.InMemoryDataset实现。这里InMemoryDataset是PyG推荐的一种写入数据方式,类似torch中DataLoader类。对于简单的数据,直接使用data即可,如果有很多图需要集成数据,则需要首先使用data封装单个图数据,再用InMemoryDataset封装多个data数据。
首先介绍最简单的Data。
假设这里有一个邻接矩阵为matrix([[0, 1, 0, 1],[1, 0, 1, 0],[0, 1, 0, 1],[1, 0, 1, 0]])的图,假设每个节点嵌入维度是2维,则:
import torch
# 嵌入向量x
x = torch.tensor([[2,1],[5,6],[3,7],[12,0]], dtype=torch.float)
# 节点类别y
y = torch.tensor([0,1,0,1], dtype=torch.float)
# 连接信息,edge_index[0]表示起始点,edge_index[1]表示连接终点,顺序无所谓
edge_index = torch.tensor([[0,1,2,0,3],
[1,0,1,3,2]], dtype=torch.long)
from torch_geometric.data import Data
data = Data(x=x, y=y, edge_index=edge_index)
data
>>Data(x=[4, 2], edge_index=[2, 5], y=[4])
4个节点,每个节点嵌入2维向量,一共有5对连接关系,一共有4个标签。
关于InMemoryDataset,直接复制官方代码进行改写。注意,这里所有的函数名都不可改,通常来说,只需要改写process部分。操作完全类似于Torch DataLoader。ClassName类名称可以自己取。
from torch_geometric.data import InMemoryDataset
class ClassName(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(YooChooseBinaryDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self): #检查self.raw_dir目录下是否存在raw_file_names()属性方法返回的每个文件,有文件不存在,则调用download()方法执行原始文件下载
return []
@property
def processed_file_names(self): #检查self.processed_dir目录下是否存在self.processed_file_names属性方法返回的所有文件,没有就会走process
return ['想要保存在本地的名字,用来服务最后一行torch.save']
def download(self):
pass
def process(self):
data_list = []
开始循环处理数据
for i in data_iteration:
这里放你的数据处理过程,找到Data需要的x、y和edge_index
data = Data(x=x, edge_index=edge_index, y=y)
data_list.append(data)
data_list储存了所有的图信息,然后封装保存到本地。
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
# 然后调用这个类就可以把数据保存在本地
dataset = ClassName(root='data/')
雅虎电商数据集(多图)用迭代器加载成PyG格式
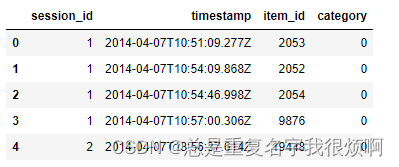
yoochoose-clicks储存用户浏览行为,session_id表示登录一次浏览了什么,item_id就是浏览的商品,yoochoose-buy描述是否购买,这里的数据如下:
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv('yoochoose-clicks.dat', header = None)
df.columns = ['session_id', 'timestamp','item_id','category']
buy_df = pd.read_csv('yoochoose-buys.dat', header = None)
buy_df.columns = ['session_id', 'timestamp','item_id','price', 'quantity']
item_encoder = LabelEncoder()
df['item_id'] = item_encoder.fit_transform(df.item_id)
df.head()
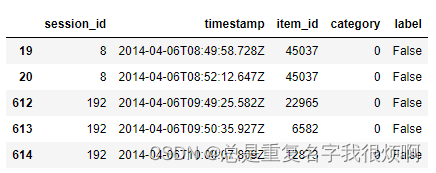
结合两张表,给是否购买添加label:
df['label'] = df.session_id.isin(buy_df.session_id)
df.head()
这里由于有很多用户,每个用户都会产生点击、购买行为,把每一个session_id都当作一个图,每一个图具有多个点和一个标签,因此属于多张图。所以需要InMemoryDataset迭代器。此外,对每一组session_id中的所有item_id进行编码(例如15453,3651,15452)就按照数值大小编码成(2,0,1),因为edge_index要0123这种格式。
明晰这些之后,直接改写上面的类:
from torch_geometric.data import InMemoryDataset
from tqdm import tqdm
df_test = df[:100]
grouped = df_test.groupby('session_id')
class YooChooseBinaryDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(YooChooseBinaryDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return []
@property
def processed_file_names(self):
return ['yoochoose_click_binary_1M_sess.dataset']
def download(self):
pass
def process(self):
data_list = []
# process by session_id
grouped = df.groupby('session_id')
for session_id, group in tqdm(grouped):
sess_item_id = LabelEncoder().fit_transform(group.item_id)
group = group.reset_index(drop=True)
group['sess_item_id'] = sess_item_id
node_features = group.loc[group.session_id==session_id,['sess_item_id','item_id']].sort_values('sess_item_id').item_id.drop_duplicates().values
node_features = torch.LongTensor(node_features).unsqueeze(1)
target_nodes = group.sess_item_id.values[1:]
source_nodes = group.sess_item_id.values[:-1]
edge_index = torch.tensor([source_nodes, target_nodes], dtype=torch.long)
x = node_features
y = torch.FloatTensor([group.label.values[0]])
data = Data(x=x, edge_index=edge_index, y=y)
data_list.append(data)
data, slices = self.collate(data_list)
dataset = YooChooseBinaryDataset(root='data/')
这样数据以PyG要求的格式保存在本地了。接下来就是训练部分。
雅虎电商数据(YooChooseBinaryDataset)GraphSAGE代码实战
为了加速这里把数据都放到GPU上。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
d = []
for data in dataset:
d.append(data.to(device))
模型搭建
embed_dim = 128
from torch_geometric.nn import TopKPooling,SAGEConv
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
import torch.nn.functional as F
class Net(torch.nn.Module): #针对图进行分类任务
def __init__(self):
super(Net, self).__init__()
self.conv1 = SAGEConv(embed_dim, 128)
self.pool1 = TopKPooling(128, ratio=0.8)
self.conv2 = SAGEConv(128, 128)
self.pool2 = TopKPooling(128, ratio=0.8)
self.conv3 = SAGEConv(128, 128)
self.pool3 = TopKPooling(128, ratio=0.8)
self.item_embedding = torch.nn.Embedding(num_embeddings=df.item_id.max() +10, embedding_dim=embed_dim)
self.lin1 = torch.nn.Linear(128, 128)
self.lin2 = torch.nn.Linear(128, 64)
self.lin3 = torch.nn.Linear(64, 1)
self.act1 = torch.nn.ReLU()
self.act2 = torch.nn.ReLU()
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch
x = self.item_embedding(x) # n*1*128 特征编码后的结果
x = x.squeeze(1) # n*128
x = F.relu(self.conv1(x, edge_index))# n*128
x, edge_index, _, batch, _, _ = self.pool1(x, edge_index, None, batch)# pool之后得到 n*0.8个点
x1 = gap(x, batch)
x = F.relu(self.conv2(x, edge_index))
x, edge_index, _, batch, _, _ = self.pool2(x, edge_index, None, batch)
x2 = gap(x, batch)
x = F.relu(self.conv3(x, edge_index))
x, edge_index, _, batch, _, _ = self.pool3(x, edge_index, None, batch)
x3 = gap(x, batch)
x = x1 + x2 + x3 # 获取不同尺度的全局特征
x = self.lin1(x)
x = self.act1(x)
x = self.lin2(x)
x = self.act2(x)
x = F.dropout(x, p=0.5, training=self.training)
x = torch.sigmoid(self.lin3(x)).squeeze(1)# batch个结果
return x
训练
from torch_geometric.loader import DataLoader
def train():
model.train()
loss_all = 0
for data in tqdm(train_loader):
data = data.to(device)
optimizer.zero_grad()
output = model(data)
label = data.y
loss = crit(output, label)
loss.backward()
loss_all += data.num_graphs * loss.item()
optimizer.step()
return loss_all / len(dataset)
model = Net().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
crit = torch.nn.BCELoss()
train_loader = DataLoader(dataset, batch_size=256)
for epoch in range(10):
print('epoch:',epoch)
loss = train()
print(loss)
















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











