







论文链接:https://arxiv.org/pdf/2111.06377.pdf
视频链接:MAE 论文逐段精读【论文精读】_哔哩哔哩_bilibili
Masked Autoencoders Are Scalable Vision Learners
Autoencoder :训练中的y,x都来自于一个数据
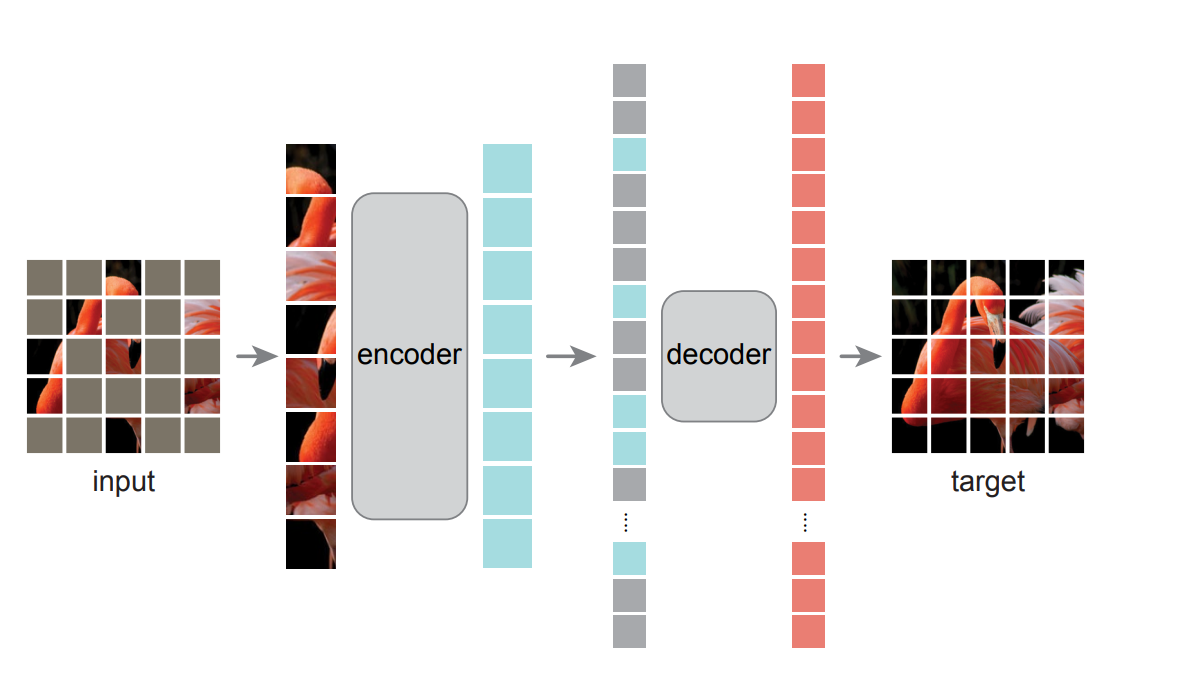
网络框架:
采用一个不对称的编码器-解码器框架。将一张图片分成不同的patch,并对patch进行随机的遮掩(实验数据表明当遮掩度为75%的时候效果较好),对于encoder 我们只对那些没有被遮掩住的patch进行训练,形成潜在表示,解码器是一个轻量级解码器,他从潜在表示和被遮住的token中还原原始图像。且解码器只有在预训练任务中采用来重构图片信息。
语言和视觉不同的原因:
- 模型不同:在上世纪,一直是卷积神经网络占有主导地位,直到最近的VIT模型成功跨界。
- 语言和视觉的信息密度不同:语言具有高度的场景和信息密度,图像具有严重的空间冗余性。
- 解码器在将潜在变量转为输入时扮演着不同的角色:在视觉领域中,解码器重建像素界别的信息,因此它的输出比普通的识别任务具有更低层次的语义信息,在语言任务中解码器富有语言信息。解码器在决定将潜在变量输出为何种层次的信息中扮演者重要的角色。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









