







概述
由于大规模模型的端到端训练,视觉和语言预训练的成本越来越高,BLIP-2是一种通用且高效的预训练策略,可以从现成的冻结的预训练图像编码器和冻结的大型语言模型引导视觉语言预训练。
模型主体框架
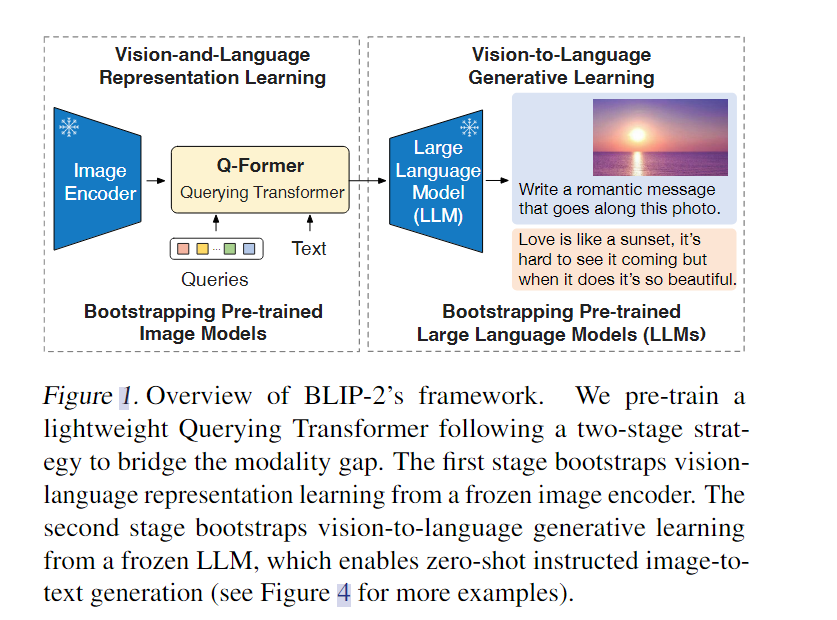
BLIP-2采用了一个轻量级的查询转换器Q-Former弥补了模态上的差距。该转换器分两个阶段进行预训练:第一个阶段从冻结的图像编码器中引导视觉语言表示学习;第二个阶段从一个冻结的语言模型中引导视觉到语言的生成学习,这可以帮助BLIP-2形成零样本指示的图像-文本生成。
基于冻结图像编码器的视觉语言表征学习阶段
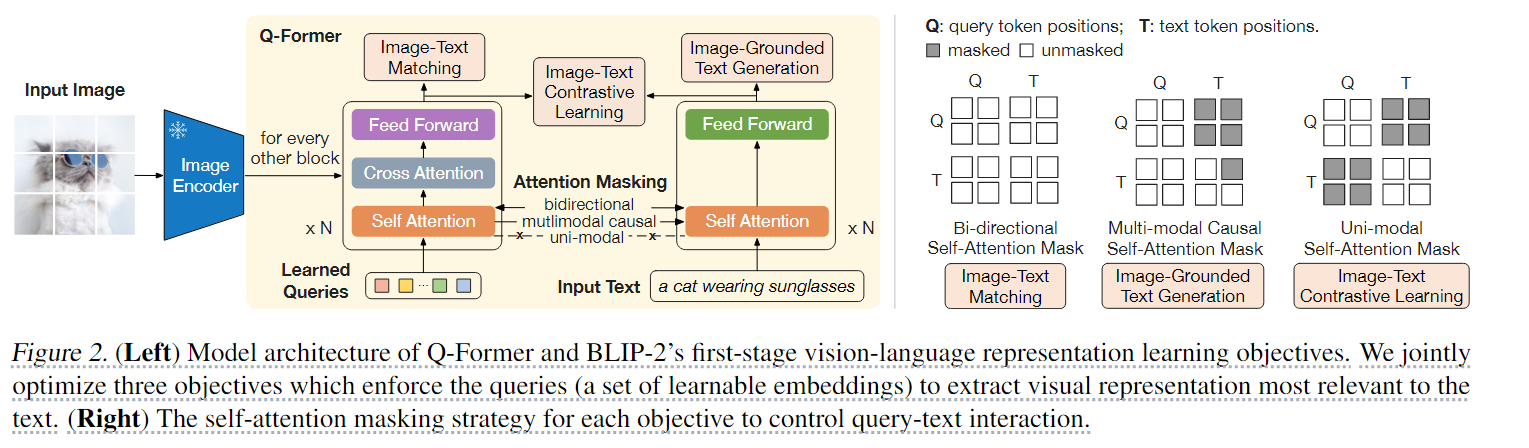
BLIP-2提出Q-Former作为可训练模块,以弥补冻结图像编码器和冻结LLM之间的差距。它从图像编码器中提取固定数量的输出特征。Q-Former由两个共享相同自注意力层的transformer子模块组成:一个图像transformer架构和冻结的图像编码器进行交互提取视觉特征;一个文本transfomer,既作为文本编码器又作为文本解码器。
- BLIP-2创建了一组可学习查询嵌入作为图像transformer的输入。查询通过自注意力层相互交互,并通过交叉注意力层(每隔一个transformer块嵌入)与冻结的图像特征进行交互。
- 查询还可以通过相同的自注意力层与文本交互。根据预训练任务的不同,BLIP-2应用不同的注意力掩码来控制查询-文本交互。
在BLIP-2的实验中,使用了32个查询,每个查询的维度为768(与Q-Former的隐藏层维度相同)。输出查询表示的大小Z(32 X 768)比冻结的图像特征大小(257 X 1024 ViT-L/14)要小的多,这种瓶颈结构与预训练目标一起工作,使查询提取与文本最相关的视觉信息。
损失函数
不同的掩码机制
图像文本对比学习(ITC)
图像文本对比学习学习对齐图像表示和文本表示,使它们的相互信息最大化。它通过对比正对和负对的图像-文本相似性来实现这一点。我们将来自图像transformer的输出查询表示Z与来自文本transformer的文本表示t对齐。其中t是[cls]令牌的输出嵌入。由于Z包含了多个输出嵌入(每个查询具有一个嵌入),我们首先计算每个查询输出与t之间的成对相似度,然后选择最高的一个作为图像-文本相似度。为了避免信息泄露,BLIP-2使用了单模态自注意力掩码,其中查询和文本不允许相互看到。
基于图像的文本生成(ITG)
基于图像的文本生成(ITG)损失训练Q-Former在给定输入图像的条件下生成文本。由于Q-Former的体系结构不允许冻结图像编码器和文本标记之间的直接交互,因此生成文本所需的信息必须首先由查询提取,然后通过自注意力层传递给文本标记。因此,查询被迫提取视觉特征来捕获关于文本的所有信息。BLIP-2使用了一个多模态因果自注意掩码来控制查询-文本交互,查询可以相互关注,但不能关注文本标记。每个文本标记都可以关注所有查询以及其之前的文本标记。BLIP-2还将[cls]令牌替换为一个新的[dec]令牌作为第一个文本令牌来知识解码任务。
、
图像文本匹配(ITM)
*图像文本匹配旨在学习图像和文本表示之间的细粒度对齐,这是一个二元分类任务,要求模型预测图像-文本对是匹配的还是不匹配的。BLIP-2使用双向自注意力掩码,其中所有查询和文本都可以相互关注。输出查询嵌入Z从而捕获多模态信息。BLIP-2将每个输出查询嵌入输入到一个两类线性分类器中,得到一个logits,并将所有查询中的logit平均为输出匹配分数。
从冻结的LLM中引导视觉到语言的生成学习
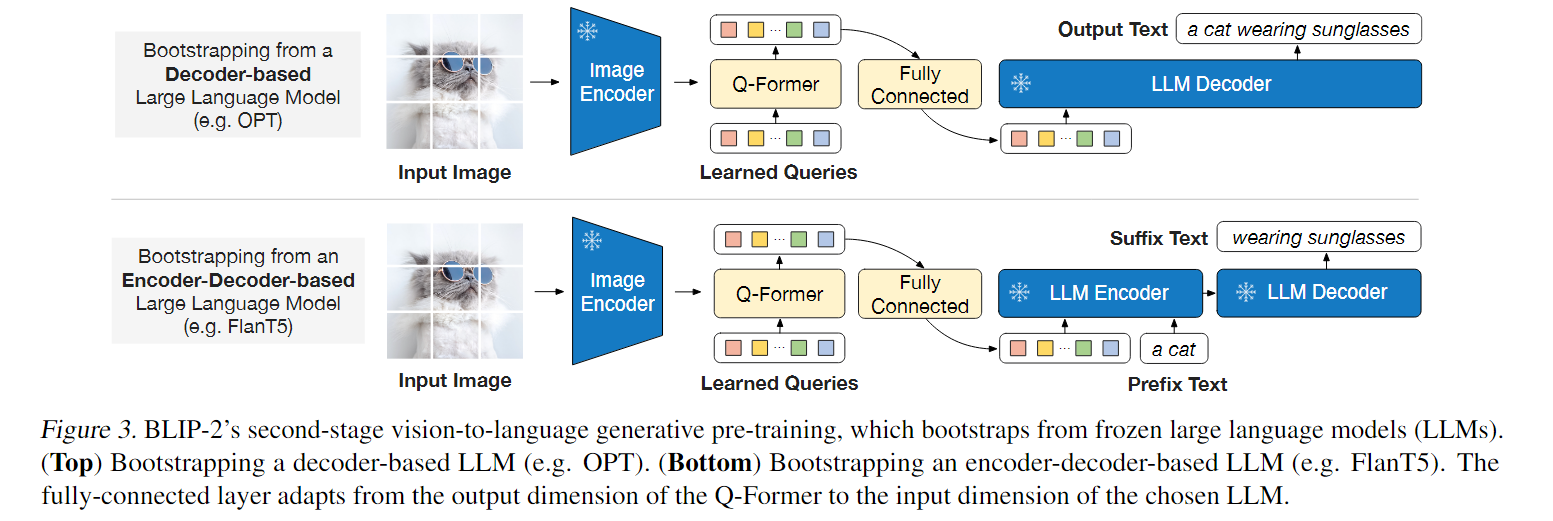
在生成预训练阶段,BLIP-2将Q-Former(附带冻结图像编码器)连接到冻结的LLM,以获取LLM的生成语言能力。BLIP-2使用全连接(FC)层将输出查询嵌入Z线性投影到与LLM的文本嵌入相同的维度。然后将投影的查询嵌入预处理为输入文本嵌入。它们起到了软视觉提示的作用,将LLM限制在Q-Former提取的视觉表示上。由于Q-Former经过预训练可以提取语言信息性的视觉表示,它有效的充当了一个信息瓶颈,将最有用的信息提供给LLM,同时去除不相关的视觉信息。这减轻了LLM学习视觉语言对齐的负担,从而减轻了灾难性的遗忘问题。
BLIP-2实验了两种类型的LLMs:基于解码器的LLMs和基于编码器-解码器的LLMs。
- 对于基于解码器的LLM,BLIP-2使用语言建模损失进行预训练,其中冻结的LLM的任务是根据Q-Former的视觉表示生成文本。
- 对于基于编码器-解码器的LLMs,BLIP-2使用前缀语言建模损失进行预训练,BLIP-2将文本分成两部。前缀文本与可视化表示相连接,作为LLM编码器的输入;后缀文本用作LLM解码器的生成目标。















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









