









概述
除了图像分类,对比语言-文本预训练(CLIP)在广泛的视觉任务中取得了显著的成功,包括对象级和3D空间理解。然而,将从CLIP学习到的语义知识转移到更复杂的量化目标任务中仍然具有挑战性,例如几何信息深度估计。在本文中,我们建议将CLIP应用于零样本单目深度估计,称为DepthCLIP。DepthCLIP发现输入图像的补丁,可以响应某个语义距离标记,然后投影到量化的深度箱中进行粗估计。在没有任何训练的情况下,我们的DepthCLIP超越了现有的无监督方法,甚至接近早期的有监督网络。DepthFormer是第一个从语义语言知识中进行零样本适应以量化下游任务并执行零样本单目深度估计的方法。
方法
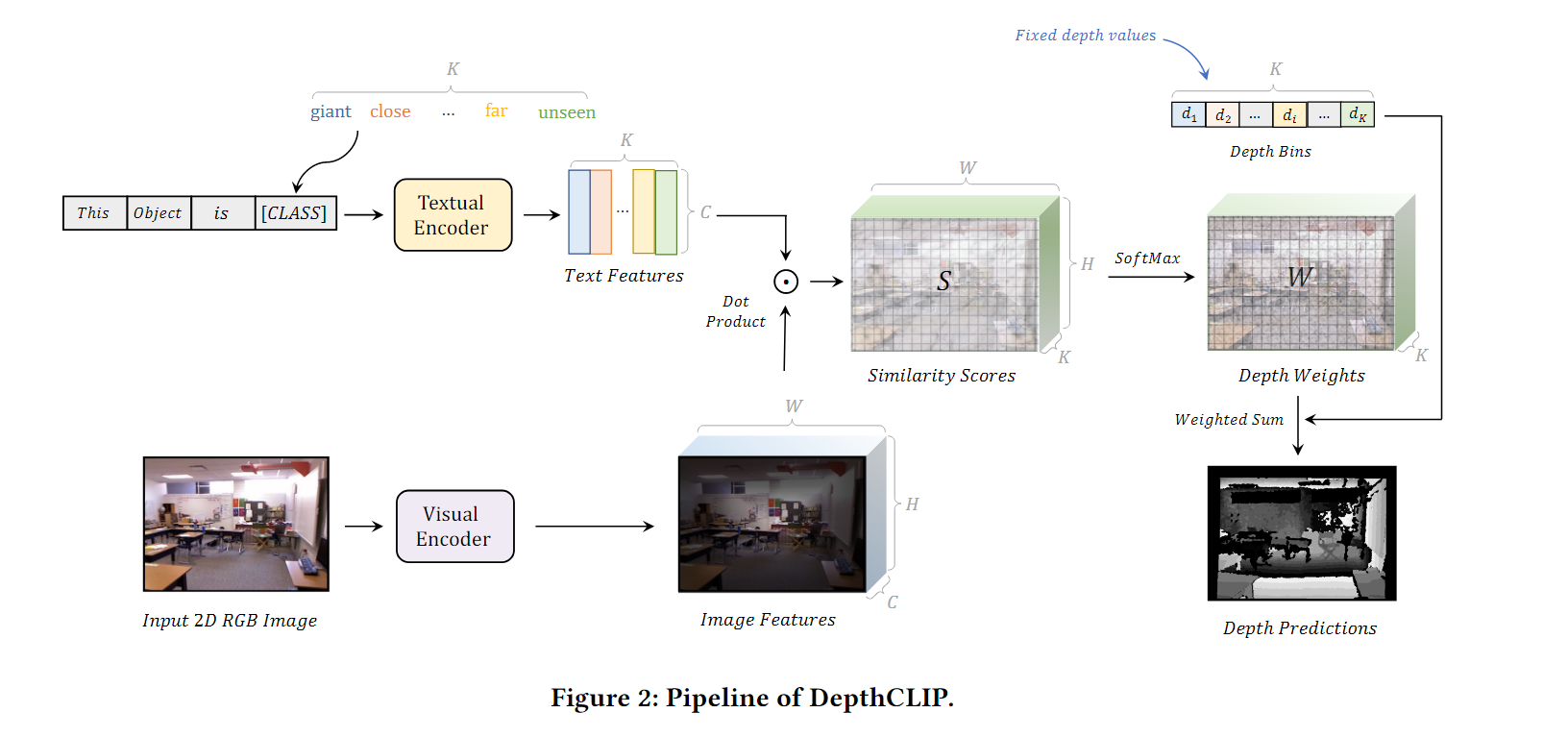
DepthCLIP模型利用了CLIP模型的预训练知识:2D图像通过CLIP模型的视觉编码器形成图像特征
R
H
W
×
C
R^{HW\times C}
RHW×C,通过物体的类别和响应的距离进行拼接,形成带有物体类别和响应距离的文本标记,送入CLIP模型的文本编码器中形成文本特征
R
K
×
C
R^{K\times C}
RK×C,通过点乘计算两者之间的相似度分数
S
K
×
H
×
W
S^{K\times H\times W}
SK×H×W。之后通过softmax函数获得深度权重,和相应的深度值进行点乘求和操作可以得到最终的深度信息。此时得到的深度图信息是经过CLIP视觉编码器下采样的大小,如果需要恢复原图的大小需要通过线性插值算法。下面依次介绍每个模块。
图像编码器
给定一个单目RGB图像
I
I
I,我们将其输入到视觉编码器中,而无需最终的池化层,然后我们获取它的最后一层特征图
F
i
m
g
F_{img}
Fimg,
F
i
m
g
=
V
i
s
u
a
l
E
n
c
o
d
e
r
(
I
)
∈
R
H
W
×
C
\mathrm{F}_{img}=\mathrm{VisualEncoder}(I) \in\mathbb{R}^{HW\times C}
Fimg=VisualEncoder(I)∈RHW×C
F
i
m
g
F_{img}
Fimg的每个点,将根据其对语义语言标记的响应给出对应的深度预测。由于CLIP预训练的编码器结构是通过塑造分类代理任务来获得的,在池化之前,特征图的每个位置都会掌握区域语义信息,池化层会将局部知识集合起来,形成给定图像的全局解释。因此,特征图的每个位置将保留其周围的语义细节,并通过文本标记响应以获得其深度近似值。
文本编码器
由于CLIP的对比代理任务,CLIP文本编码器会向图像特征的邻域投射相似的语义标记,在DepthCLIP中,我们利用”This object is distance class“这样的提示,并应用代替distance类的close,far,remote语义令牌来形成K语义令牌。这些令牌T将通过CLIP的文本编码器传入潜在空间。
F
t
e
x
t
=
TextualEncoder(T)
∈
R
K
×
C
\mathrm{F}_{text}=\text{TextualEncoder(T)}\in\mathbb{R}^{K\times C}
Ftext=TextualEncoder(T)∈RK×C
其中C的维度和
F
i
m
g
F_{img}
Fimg一致,然后我们,通过
S
=
F
t
e
x
t
⋅
F
i
m
g
⊤
∥
F
t
e
x
t
∥
∥
F
i
m
g
∥
∈
R
K
×
H
W
\mathrm{S}=\frac{\mathrm{F}_{text}\cdot\mathrm{F}_{img}^\top}{\|\mathrm{F}_{text}\|\|\mathrm{F}_{img}\|}\in\mathbb{R}^{K\times HW}
S=∥Ftext∥∥Fimg∥Ftext⋅Fimg⊤∈RK×HW计算语义令牌特征
F
t
e
x
t
F_{text}
Ftext与图像特征
F
i
m
g
F_{img}
Fimg之间的余弦相似度
Prompt的替换如下所示
templates = 'This {} is {}'
depth_classes = ['giant', 'extremely close', 'close', 'not in distance', 'a little remote', 'far', 'unseen']
object_classes =['object']
for depth in depth_classes:
for obj in obj_classes:
texts = [template.format(obj,depth) for template in templates]
深度投影和组合
在获得相似分数S(
d
i
m
=
H
×
W
×
K
dim=H\times W\times K
dim=H×W×K)之后,需要获得量化深度,以获得深度预测,也就是说,“close"应该投影到"1m”。我们在这些相似分数s中应用温度softmax函数,得到线性组合权重。
W
=
e
S
:
,
:
,
i
∑
j
=
1
K
e
S
:
,
:
,
j
,
f
o
r
i
=
1
,
…
,
K
\mathbf{W}=\frac{e^{\mathbf{S}_{:,:,i}}}{\sum_{j=1}^Ke^{\mathbf{S}_{:,:,j}}},\quad\mathrm{for~}i=1,\ldots,K
W=∑j=1KeS:,:,jeS:,:,i,for i=1,…,K
使用幂函数是为了求导方便,相似分数是用来当一个占比,之后用来计算权重,获得连续值。因为如果预测具体的值过于繁琐,可能会造成模型复杂,出现过拟合现象。我们使用这样的权重线性组合深度箱
d
\mathbf{d}
d(
d
i
m
=
K
∗
1
,
l
i
k
e
[
d
1
=
1.00
m
,
d
2
=
2.00
m
,
d
3
=
3.00
m
,
.
.
.
]
dim=K*1, \mathrm{like}[d_{1} = 1.00\mathrm{m}, d_{2} = 2.00\mathrm{m}, d_{3} = 3.00\mathrm{m}, ...]
dim=K∗1,like[d1=1.00m,d2=2.00m,d3=3.00m,...]),得到最终特征图上每个点的深度预测
D
p
r
e
d
(
d
i
m
=
H
∗
W
∗
1
)
\mathrm{D}_{\mathbf{pred}}\left(dim=H*W*1\right)
Dpred(dim=H∗W∗1)。此时获得的深度预测与原始图像上的每个patch对齐。。
D
p
r
e
d
=
∑
i
=
1
K
W
:
,
:
,
i
∗
d
i
\mathrm{D}_{\mathrm{pred}}=\sum_{i=1}^K\mathrm{W}_{:,:,i}*\mathrm{d}_i
Dpred=i=1∑KW:,:,i∗di
其中 D p r e d i , j D_{pred_{i,j}} Dpredi,j是第i行,第j列块的深度,所有属于该patch的像素点将被表示为相同的深度预测 D p r e d i , j , w h e r e i ∈ [ 1 , H ] , j ∈ [ 1 , W ] . \mathrm{D}_{\mathrm{pred}_{i,j}},\mathrm{~where~}i\in[1,H],j\in[1,W]. Dpredi,j, where i∈[1,H],j∈[1,W].。
结论
在本文中,我们提出了DepthCLIP模型,通过CLIP模型进行零样本单目深度估计。它摈弃了对带有深度标签的训练和测试数据的需求,直接应用CLIP,获得了令人满意的效果。我们希望我们的工作能够阐明将语义视觉语言知识与定量视觉任务联系起来的研究,并为零样本深度估计开辟了新的研究。















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









