







 文章介绍了R-CNN、FastR-CNN和FasterR-CNN三种目标检测算法的发展,从基于SelectiveSearch的R-CNN,改进为FastR-CNN的ROIpooling和共享特征,再到FasterR-CNN引入的区域提议网络(RPN)以提高速度和性能。这些算法逐步解决了效率和准确性的问题,对深度学习目标检测领域产生了重要影响。
文章介绍了R-CNN、FastR-CNN和FasterR-CNN三种目标检测算法的发展,从基于SelectiveSearch的R-CNN,改进为FastR-CNN的ROIpooling和共享特征,再到FasterR-CNN引入的区域提议网络(RPN)以提高速度和性能。这些算法逐步解决了效率和准确性的问题,对深度学习目标检测领域产生了重要影响。
论文链接
- R-CNN https://arxiv.org/abs/1311.2524
- Fast R-CNN https://arxiv.org/abs/1504.08083
- Faster R-CNN https://arxiv.org/abs/1506.01497
视频链接:1.1Faster RCNN理论合集_哔哩哔哩_bilibili
参考博客:一文读懂Faster RCNN(大白话,超详细解析)_风中一匹狼v的博客-CSDN博客
R-CNN
主体框架:
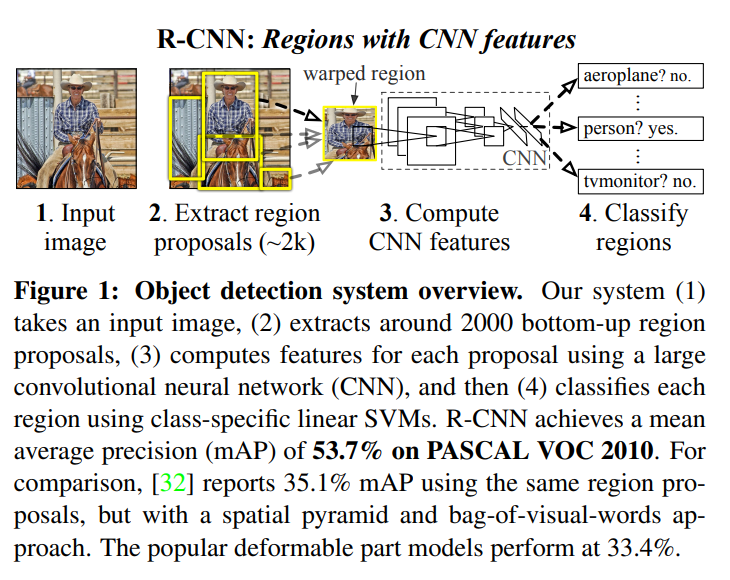
R-CNN算法流程分为四个步骤
- (采用Selective Search方法)在一张图片上生成2k个候选区域
- 对每个候选区域,使用深度网络提取特征,对于每一个候选区生成一个4096维的向量
- 特征向量送入每一类的SVM分类器,判别是否属于该类特征,其中SVM的维度是4069 x N ,N表示类别数
- 使用回归器精细修正候选框位置

R-CNN存在的问题
- 测试速度慢:一张图片内候选框之间存在大量重叠,提取特征操作冗余
- 训练速度慢:过程繁琐
- 训练所需空间大:对于SVM和bbox回归训练,需要从每个图片中的每个目标候选框提取特征,并写入磁盘用于计算。
两个创新点:
- 将高容量的卷积神经网络( CNNs )应用到自底向上的区域建议中,以定位和分割目标;
- 当有标记的训练数据稀缺时,对辅助任务进行有监督的预训练,然后进行特定领域的微调,产生显著的性能提升
根据研究表明,超过5400万的参数的全连接层并不是关键,他们中94%的参数省去,对测量的精度只有一些稍微的下降,但是卷积层会有丰富的特征。
Fast-RCNN
主体框架
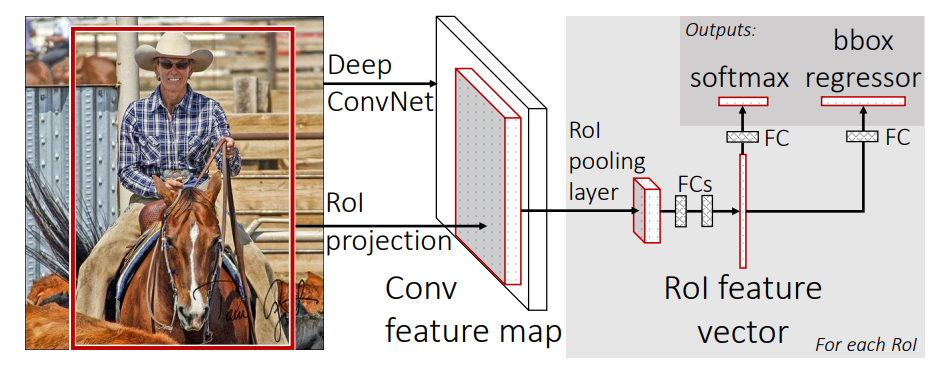
Fast-RCNN算法主要分为以下三个部分
- 采用SS算法将一张图片生成1K-2K个候选区域
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7X7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
如图所示,并联了两个全连接层,一个用于输出分类类别的概率(N+1 具有背景),另一个是输出边界框的回归参数(4(N+1))
在训练过程中并不是采用SS算法生成的所有候选区域,只是采样了一部分
ROI pooling结构
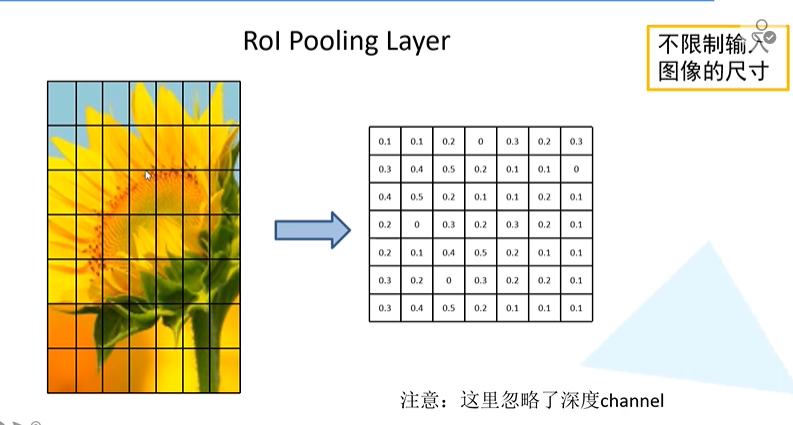
对于每个特征矩阵,我们将其划分成7X7的样式,对于每一个小的格子我们都可以进行maxpooling操作,此时不需要规定输入图片的尺寸,但是可以将其统一成大小一致的特征图。
Faster-RCNN
主体框架
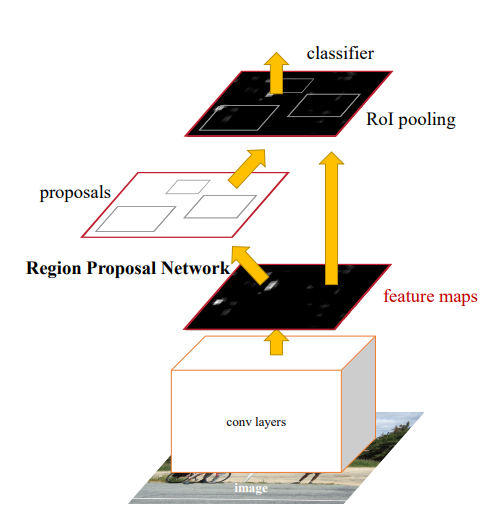
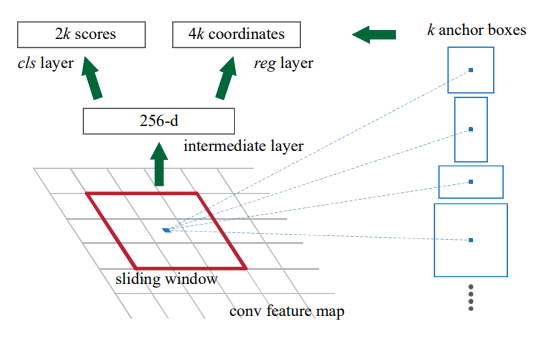
左图为Faster-RCNN的结构,右图是RPN网络
Faster-RCNN主要分为如下三个部分
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7X7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果。
256-d 是因为采用了ZF的骨干网络,当采用VGG16骨干网络时此时为512。
Faster RCNN 存在的问题
- 对小目标检测效果很差(通过特征图直接计算,抽象的层次较高)
- 模型大,检测速度较慢 (检测分为了两个步骤计算)
RPN网络

如图所示,红色圈出来的就是我们生成anchor的结构,对于经过骨干网络生成的特征图的每一个像素点,我们分别生成9个anchor。后续还会淘汰一批anchor并且修正anchor的位置。
RPN结构分为上下两条线,上面一条线,通过1x1的卷积操作生成2k个输出,分别预测是前景和背景的概率。下面一条线,通过1x1的卷积生成4k个输出,这里是每个anchor坐标的偏移量,并不是坐标本身。















 5389
5389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









