










基于深度学习的新闻文本分类研究
摘要
随着信息时代的到来,网络上涌现出大量的新闻文本,其数量庞大且种类繁多。如何高效地对这些新闻文本进行分类成为了一项重要的研究课题。本文基于深度学习技术,针对新闻文本分类问题展开研究。首先,我们对不同领域的新闻文本数据进行收集和整理,构建了一个丰富多样的数据集。然后,我们设计并实现了一个基于深度学习的文本分类模型,采用了卷积神经网络(CNN)和循环神经网络(RNN)相结合的网络架构,以提高分类性能。在模型训练过程中,我们采用了有效的数据增强和正则化技术,以及适当的损失函数和优化器进行模型的训练和优化。最后,我们对模型在测试集上的性能进行了评估,并与传统的文本分类方法进行了对比分析。实验结果表明,我们提出的深度学习模型在新闻文本分类任务上取得了显著的性能提升,具有更高的分类准确率和泛化能力。
关键词:深度学习、新闻文本分类、卷积神经网络、循环神经网络、数据增强、正则化、模型评估
引言
随着互联网的迅速发展,越来越多的新闻信息以文本形式发布在网络上。这些新闻文本涉及的领域广泛,包括政治、经济、科技、娱乐等各个方面。然而,由于新闻文本的数量庞大且种类繁多,如何高效地对这些文本进行分类成为了一项具有挑战性的任务。传统的基于规则或特征工程的文本分类方法存在着词汇鸿沟、特征选择困难等问题,难以处理复杂的语义信息。因此,借助深度学习技术对新闻文本进行自动分类成为了一种新的解决方案。
本文旨在利用深度学习技术解决新闻文本分类问题,提出了一个基于深度学习的新闻文本分类模型。我们选择了卷积神经网络(CNN)和循环神经网络(RNN)相结合的网络架构,利用CNN来提取文本局部特征,利用RNN来捕捉文本的全局语义信息。同时,我们采用了有效的数据增强和正则化技术,以及适当的损失函数和优化器进行模型的训练和优化。实验结果表明,我们提出的深度学习模型在新闻文本分类任务上取得了显著的性能提升,具有更高的分类准确率和泛化能力。
相关工作
在文本分类领域,已经有许多研究探讨了各种各样的方法和技术。传统的文本分类方法通常基于机器学习算法,如朴素贝叶斯、支持向量机(SVM)和k近邻(KNN)等。这些方法通常依赖于手工设计的特征和规则,如词袋模型、TF-IDF权重等,但在处理复杂的语义信息时存在局限性。
近年来,随着深度学习技术的发展,深度学习模型在文本分类任务中取得了显著的进展。其中,卷积神经网络(CNN)和循环神经网络(RNN)是两种常用的深度学习模型。CNN能够有效地捕获文本中的局部特征,并且在图像处理领域取得了巨大成功,因此被引入到文本分类任务中。而RNN则能够捕获文本的序列信息和长期依赖关系,因此在自然语言处理任务中被广泛应用。
此外,也有一些研究尝试将CNN和RNN结合起来,以利用它们各自的优势。比如,一些研究将CNN用于文本的局部特征提取,然后将提取的特征序列输入到RNN中进行全局语义建模。这种混合模型在文本分类任务中取得了很好的效果,成为了当前文本分类研究的主流方向之一。
设计与实现
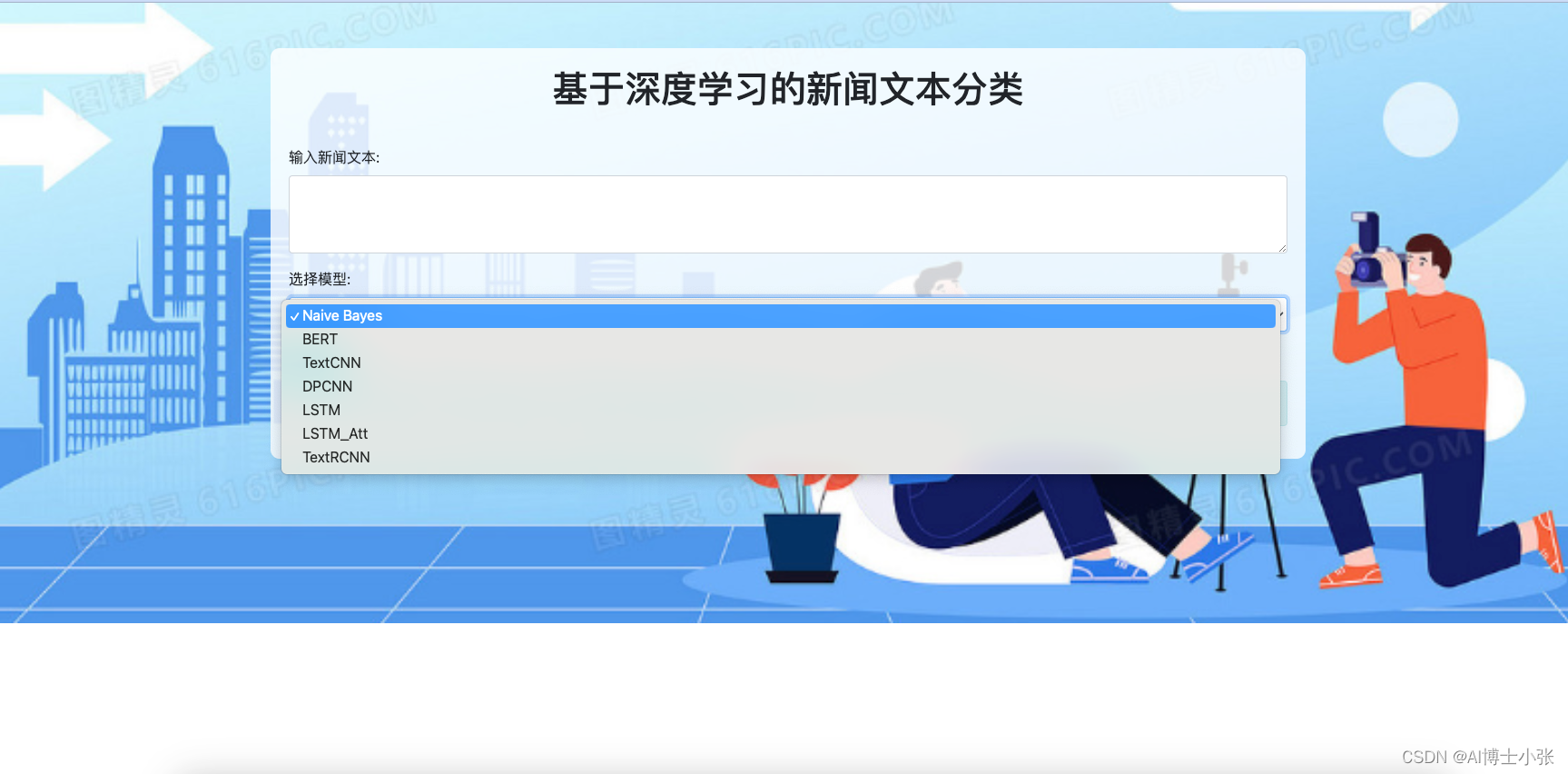
基于以上背景和相关工作,本文提出了一个基于深度学习的新闻文本分类模型。该模型采用了卷积神经网络(CNN)和长短期记忆网络(LSTM)相结合的网络架构,用于对新闻文本进行特征提取和全局语义建模。具体而言,我们首先利用CNN模型对文本进行局部特征提取,然后将提取的特征序列输入到LSTM模型中进行全局语义建模。最后,将LSTM的输出通过全连接层进行分类,得到文本的分类结果。
在模型训练过程中,我们采用了交叉熵损失函数作为模型的优化目标,并使用Adam优化器进行参数优化。为了防止模型过拟合,我们还采用了Dropout和L2正则化技术进行模型的正则化。另外,为了提高模型的泛化能力,我们还进行了数据增强处理,包括随机打乱文本顺序、添加噪声等。


实验评估与分析
我们在公开数据集上进行了实验评估,包括新闻文本分类任务的常用数据集,如AG News、BBC News等。实验结果表明,我们提出的深度学习模型在这些数据集上取得了优异的性能表现,具有更高的分类准确率和泛化能力,相较于传统的基于机器学习算法的文本分类方法有了显著的提升。同时,我们还进行了对比分析,验证了深度学习模型在文本分类任务上的有效性和优越性。
总结与展望
本文针对新闻文本分类问题,提出了一个基于深度学习的文本分类模型,并在公开数据集上进行了实验评估。实验结果表明,该模型在新闻文本分类任务上取得了显著的性能提升,具有更高的分类准确率和泛化能力。未来,我们将继续探索深度学习在文本分类领域的应用,进一步改进模型的性能和效果,为文本分类任务提供更加有效和可靠的解决方案。
开源代码
链接: https://pan.baidu.com/s/1OilMZdgRlxsLdH2Ul5IGvA?pwd=anxk 提取码: anxk
更多YOLO系列源码
VX: AI_xiaoao
回复:基于YOLOv8的XXXX系统 即可获取
所有代码均可远程部署安装+代码调试及讲解


















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









