









yolov4网络结构
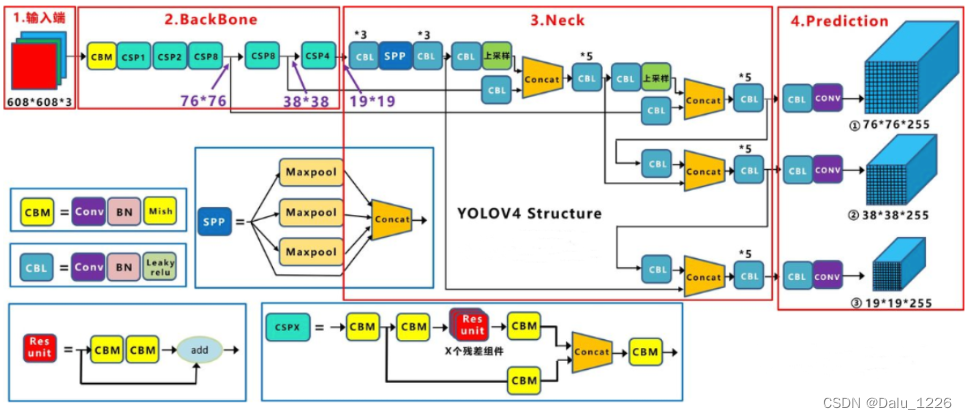
yolov4损失函数设计
CIOU_loss-目标检测任务的损失函数一般由分类损失函数和回归损失函数两部分构成,回归损失函数的发展过程主要包括:最原始的Smooth L1 Loss函数、2016年提出的IoU Loss、2019年提出的GIoU Loss、2020年提出的DIoU Loss和最新的CIoU Loss函数。
3.1.1 IOU Loss
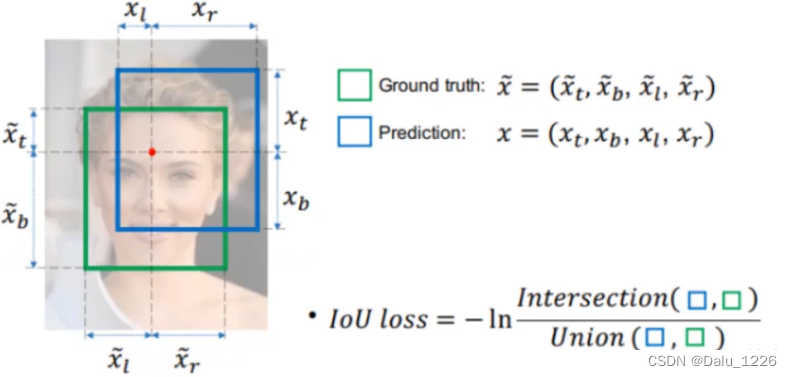
IoU Loss-所谓的IoU Loss,即预测框与GT框之间的交集/预测框与GT框之间的并集。这种损失会存在一些问题,具体的问题如下图所示,(1)如状态1所示,当预测框和GT框不相交时,即IOU=0,此时无法反映两个框之间的距离,此时该 损失函数不可导,即IOU_Loss无法优化两个框不相交的情况。(2)如状态2与状态3所示,当两个预测框大小相同时,那么这两个IOU也相同,IOU_Loss无法区分两者相交这种情况。

3.1.2 CIOU Loss
L
C
I
o
U
=
1
−
I
o
U
+
ρ
2
(
b
,
b
g
t
)
c
2
+
α
ν
L_{CIoU} = 1-IoU + \frac{\rho^2(b,b^{gt})}{c^2}+\alpha\nu
LCIoU=1−IoU+c2ρ2(b,bgt)+αν
ν
=
4
π
2
(
arctan
ω
g
t
h
g
t
−
arctan
ω
h
)
2
\nu=\frac{4}{\pi^2}(\arctan\frac{\omega^{gt}}{h^{gt}}-\arctan\frac{\omega}{h})^2
ν=π24(arctanhgtωgt−arctanhω)2
α
=
ν
(
1
−
I
o
U
)
+
ν
\alpha=\frac{\nu}{(1-IoU)+\nu}
α=(1−IoU)+νν
一个好的损失函数要考虑3方面因素:重叠面积,中心点距离,长宽比
在DIOU的时候已经把重叠面积和中心点距离考虑进去了,现在还差一个长宽比
ν
\nu
ν。当真实框长宽比
ω
g
t
h
g
t
\frac{\omega^{gt}}{h^{gt}}
hgtωgt与预测框长宽比
ω
h
\frac{\omega}{h}
hω一直时最后一项为0,其中
α
\alpha
α可以看做权重参数。
总而言之,IOU_Loss主要考虑了检测框和GT框之间的重叠面积;GIOU_Loss在IOU的基础上,解决边界框不重合时出现的问题;DIOU_Loss在IOU和GIOU的基础上,同时考虑了边界框中心点距离信息;CIOU_Loss在DIOU的基础上,又考虑了边界框宽高比的尺度信息。
作品展示
yolo目标检测
开源代码
百度网盘:链接:https://pan.baidu.com/s/1C7ObZZbVGpRO3gf7Vhdx5A?pwd=k19z
提取码:k19z
更多代码 加微信 AI_xiaoao
回复题目【基于XXXX的XXXX系统设计】免费获取源代码
所有代码均可远程部署安装+代码调试讲解
















 5737
5737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









