






 本文是一篇关于在Windows上部署langchain-chatchat和ChatGLM构建本地知识库的详细指南,涉及环境设置、模型配置和常见问题解决。
本文是一篇关于在Windows上部署langchain-chatchat和ChatGLM构建本地知识库的详细指南,涉及环境设置、模型配置和常见问题解决。
基于langchain-chatchat-chatglm构建本地离线知识库大模型
以前学习机器学习和神经网络,用我那1050ti的电脑勉强得行,如今大模型当道,想搞个大模型玩玩,以前的cpu和显卡已经带不动了,一狠心换了个电脑,之前因为cuda版本过低导致的各种问题终于解决了。
现在开源大模型有很多选择,LLaMA ,BLOOM ,baichuan,BERT,chatglm等等。这里我选择的是清华的chatglm,它对中文支持比较好,维护迭代也比较稳定,大模型根据自己的需求进行选择。
另外为了同时能构建本地知识库,我选择了目前开源的langchain-chatchat的方案。该项目支持目前市面上主流的大模型,你也可以加载自己的模型部署
1.操作系统
这里以windows为例,因为windows会遇到的问题比ubuntu更多,所以如果你的windows能顺利部署,ubuntu应该也会顺利
- 操作系统: win11
- cpu:i9-14900HX(没有必要和我一样,但是推荐至少要6核12线程)
- 内存: 32G(内存不能太小,最好不要少于24G)
- 显卡:4070(显卡型号没有必要一样,但是显卡型号最好3060以上,显存6G以上)
- 磁盘: 至少120G
2.下载langchain-chatchat相关代码和模型
-
我们选择使用langchain-chatchat来加载运行大模型,所以首先需要获取langchain-chatchat的代码
- github下载地址: https://github.com/chatchat-space/Langchain-Chatchat.git
- 如果你无法下载,可以下载我准备在网盘中的代码
链接:https://pan.baidu.com/s/1ZTY8CH-blvmb__yhtzZAfw
提取码:nkcu
-
下载llm模型:chatglm3-6b
- 下载地址: https://huggingface.co/THUDM/chatglm3-6b
- 下载超大文件需要安装git LFS
git lfs install - 访问huggingface需要魔法,如果不能访问,可以下载我准备在网盘中的文件,但缺点就是不会实时更新
- 网盘地址:
链接:https://pan.baidu.com/s/1Ho1y39EXRT1CVwyQDLIu1g
提取码:7akn
-
下载embedding模型:bge-large-zh
- 官方下载地址: https://huggingface.co/BAAI/bge-large-zh
- 网盘地址:
链接:https://pan.baidu.com/s/1y3fGljM-MekJ9OefgbdcFw
提取码:1ju3
3.运行环境准备
3.1安装CUDA和cudnn
-
安装CUDA
- 查看当前显卡支持的cuda版本,cmd命令行输入
nvidia-smi获取当前显卡型号和cuda版本

这里有两个参数,一个是Driver Version一个是CUDA Version, CUDA Version是你当前系统最大能安装的CUDA版本, 但是你不一定就必须要安装这个版本的CUDA的。目前torch最大支持12.1版本的cuda,所以我们这里安装12.1版本的CUDA。
当然每个人的显卡版本不同,不一定都能安装12.1版本,所以我们就需要查看Driver Version和CUDA版本之间的联系了,查看网址如下:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html

这里就是各个CUDA版本对应的Driver Version版本的要求 - 下载CUDA
地址: https://developer.nvidia.com/cuda-toolkit-archive
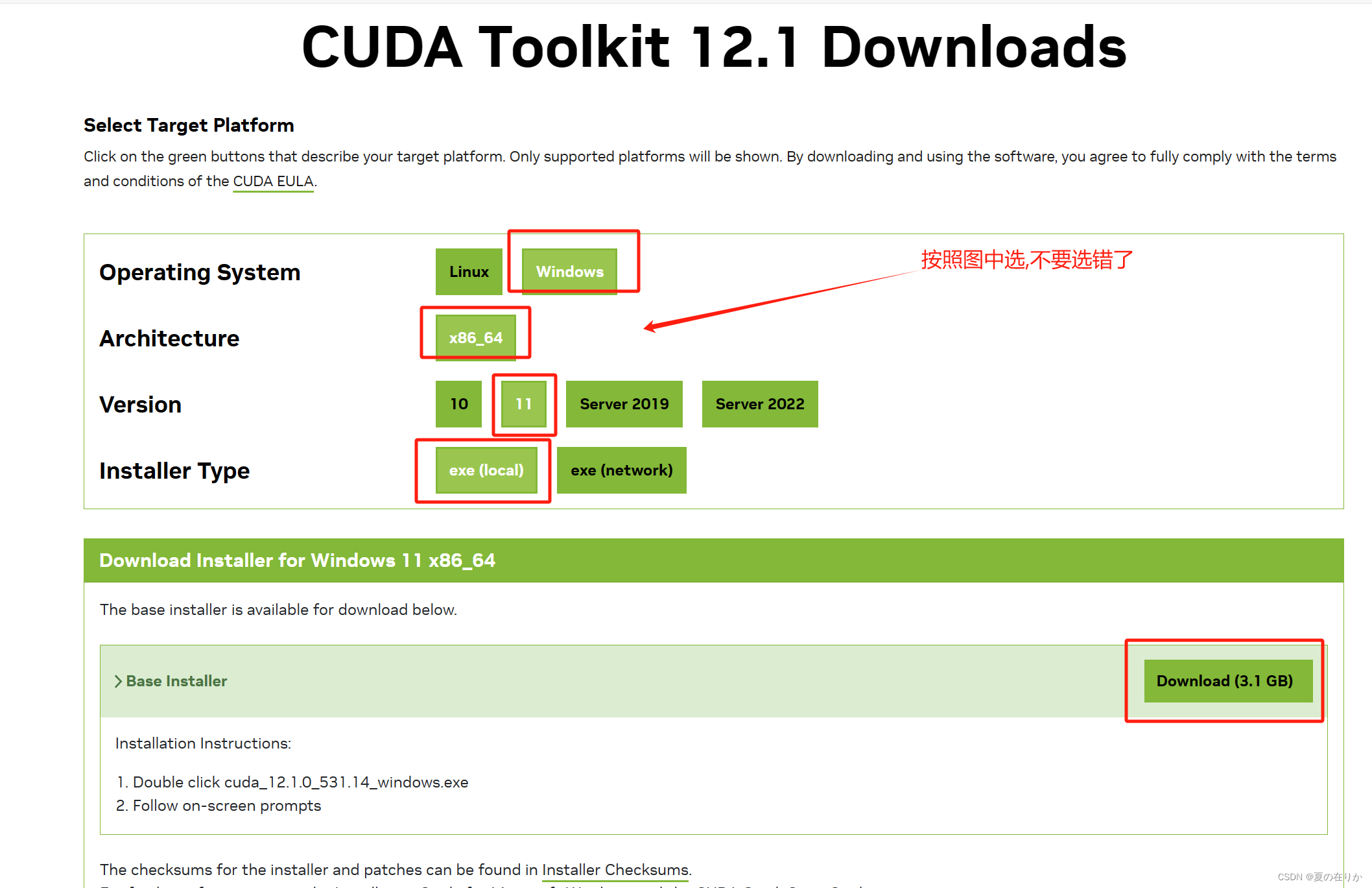
- 下载完安装即可,可以选择精简安装,记住安装路径,等会儿要将cudnn加载进去,并将路径配置到环境变量中
- 查看是否安装成功:
nvcc -V

- 查看当前显卡支持的cuda版本,cmd命令行输入
-
安装cudnn
某些软件可能需要cudnn加速,以防万一还是安装一个- 下载地址: https://developer.nvidia.com/rdp/cudnn-archive
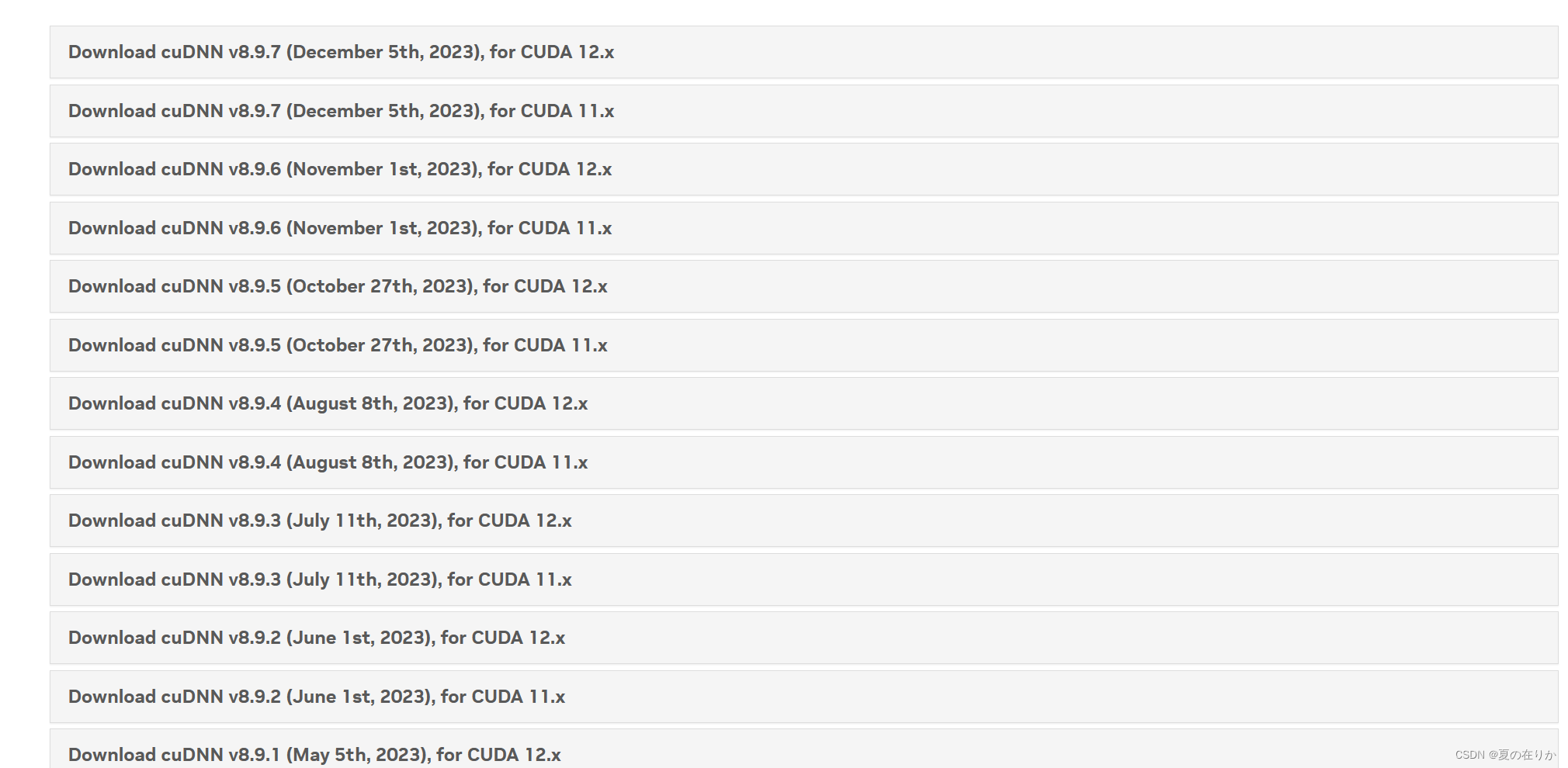
下载对应版本的cudnn到本地 - 解压下载的安装包,复制到cuda安装位置的根目录下,如下图所示
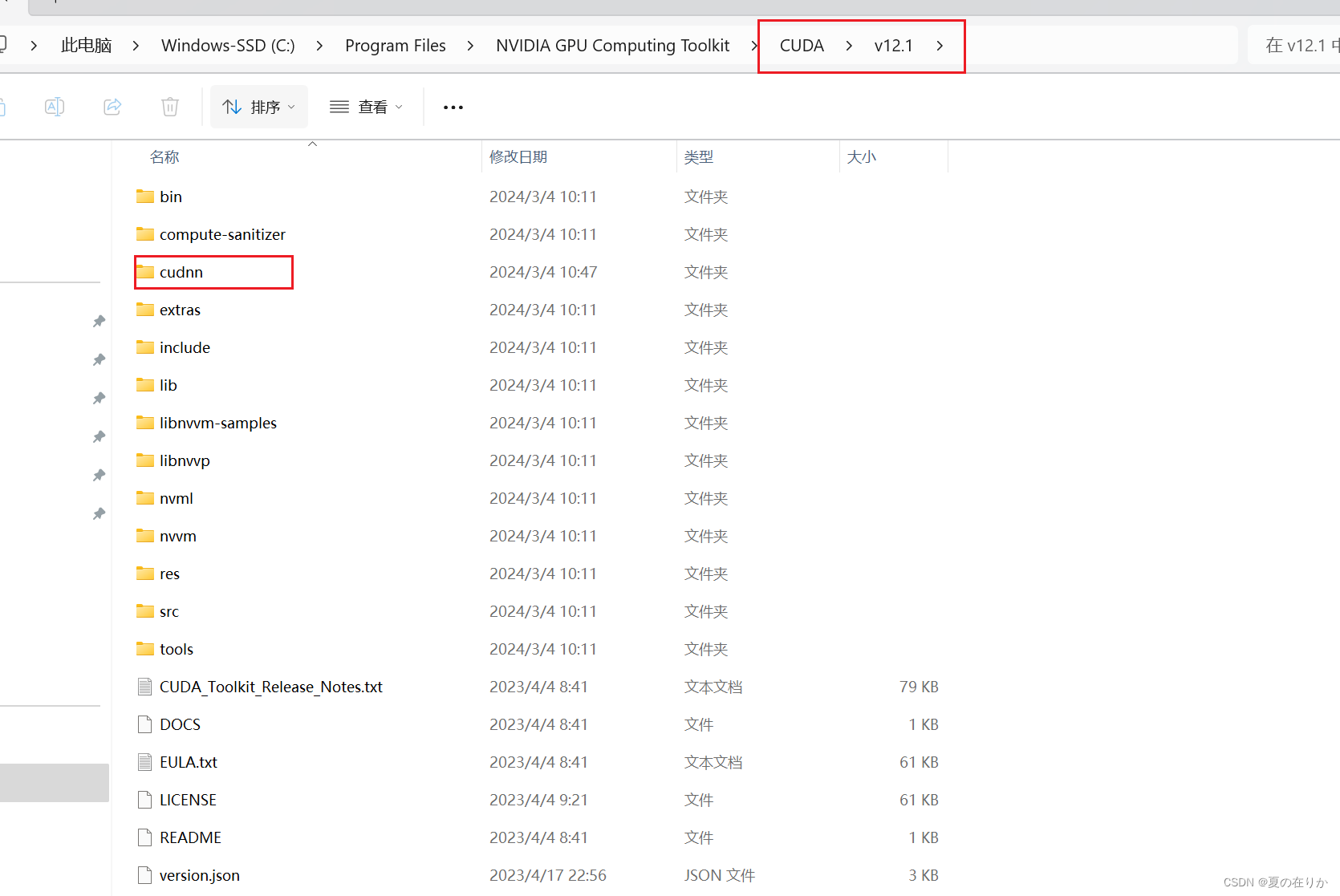
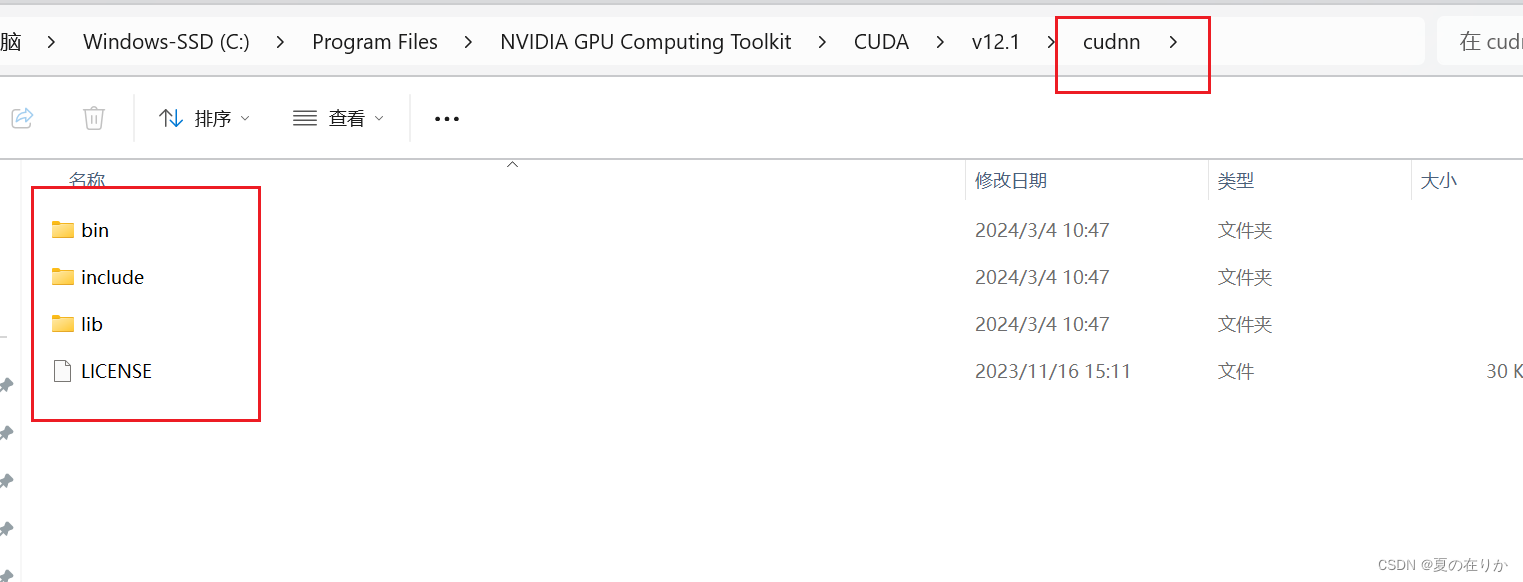
- 下载地址: https://developer.nvidia.com/rdp/cudnn-archive
-
配置环境变量
-
cuda基础的环境变量安装的时候已经被配置好了,只需要新增以下两个环境变量即可:
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\cudnn\bin
- C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\extras\CUPTI\lib64
!!注意,这里的路径改成你自己对应的路径
-
3.2创建虚拟环境
-
推荐使用anaconda,省心
-
虚拟环境python版本需要大于3.10,推荐使用3.11
conda create -n langchain-311 -
进入langchain的根目录,打开cmd,如果你使用pycharm,直接打开terminal也可以
-
使用conda虚拟环境
conda activate langchain-311 -
安装pytorch-gpu版本
- 官网地址: https://pytorch.org/get-started/locally/
- 我们使用的不是最新版本,是2.1.2版本,所以需要去历史版本中下载
https://pytorch.org/get-started/previous-versions/
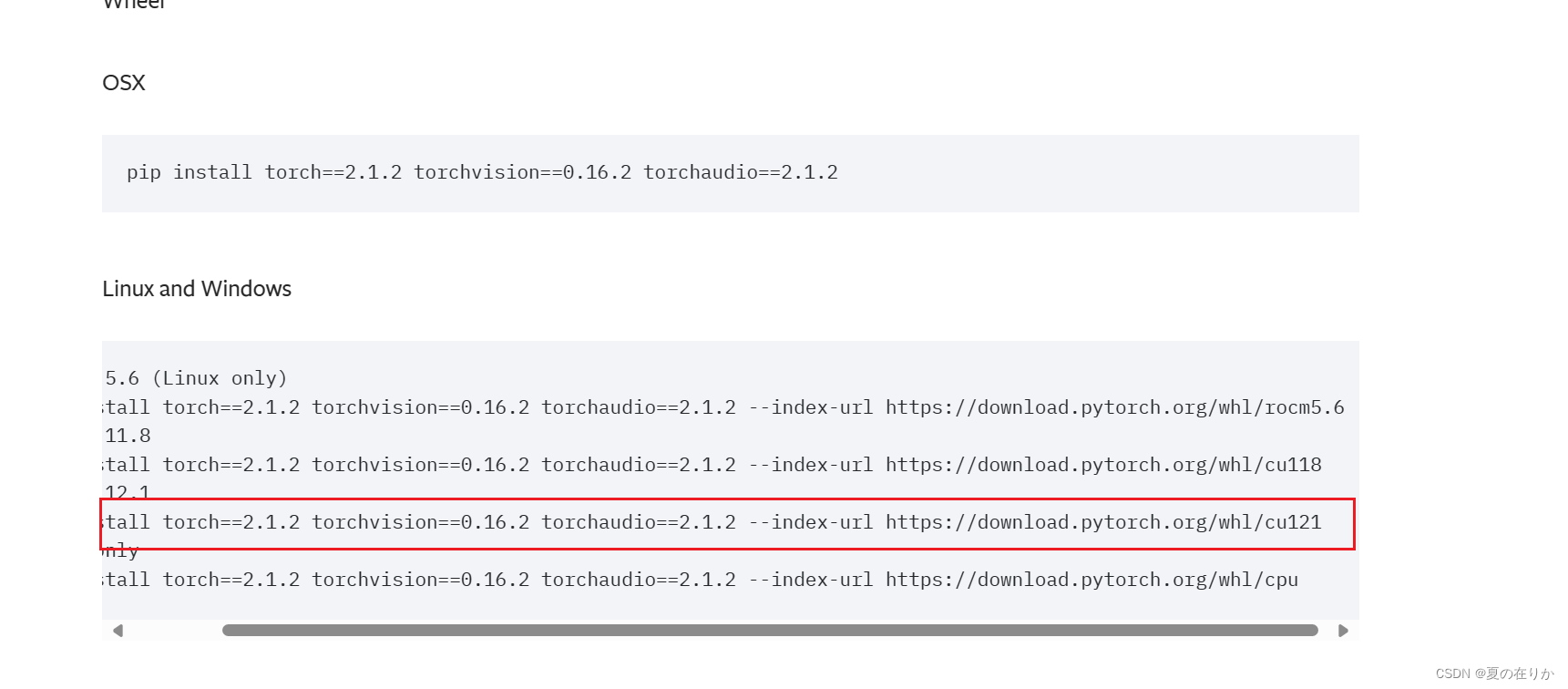
选择带cu的版本,cu121就是cuda12.1版本,根据需要选择你自己对应的cuda版本,复制命令行执行即可 - 查看是否安装成功
进入python解释器,cmd命令行执行python
执行以下代码python
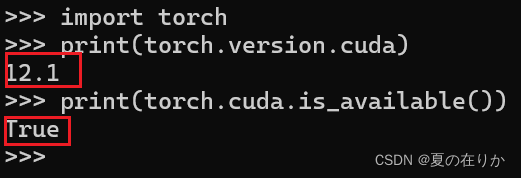
出现以下页面就是安装成功了import torch print(torch.version.cuda) print(torch.cuda.is_available())
-
安装项目依赖
# -i后面是国内镜像源,可以根据自己的需要选择,如果是内网安装的朋友只能自己手动下载wheel安装了 pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -r requirements-api.txt -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -r requirements-lite.txt -i https://pypi.tuna.tsinghua.edu.cn/simple pip install -r requirements-webui.txt -i https://pypi.tuna.tsinghua.edu.cn/simple注意:
这里requirements.txt中安装的torch默认是cpu版本的,为了防止安装时gpu版本因为各种情况被覆盖,再次查看一下自己安装的torch是否为gpu版,如果不是重新安装torch-cudapip list installed | findstr torch
没有问题继续下一步
3.3 初始化
- 初始化配置文件
python copy_config_example.py - 初始化知识库
注意:如果这里出错找不到1_Pooling/config.json,可能是下载的bge-large-zh的1_Pooling下的文件名称与代码中不同,重命名为config.json即可python copy_config_example.py
3.4 修改配置文件
刚才初始化的配置文件都在configs目录下
-
model_config.py
- 这个文件是用来配置,模型路径和启用哪个模型的
- 重点配置:
-
MODEL_ROOT_PATH: 模型存放的根路径
默认为空,就是和项目同级别,你也可以修改为自己存放的model的根路径,相对路径和绝对路径都可以,比如刚才下载的chatglm-6b和bge-large-zh你放在了"/app/models"下,那么你这里就配置"/app/models"。
我是直接放在项目根路径下,所以这个值没有修改 -
EMBEDDING_MODEL:选用的 Embedding模型名称
这个名称不是随便定义的,是和MODEL_PATH下的embed_model绑定的
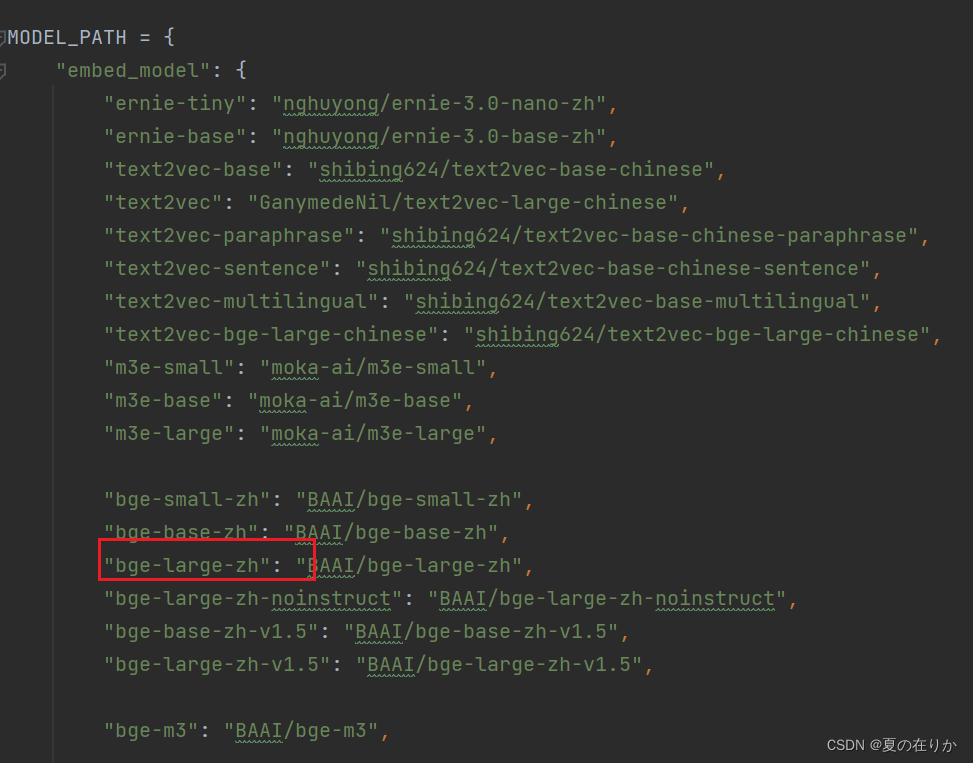
我们这里的embedding模型用的是bge-large-zh,所以修改成bge-large-zh就可以了
注意: 我们看到这里配置的bge-large-zh模型路径是BAAI/bge-large-zh,所以你的模型路径一定是要有BAAI的,如果你刚才的MODEL_ROOT_PATH配置的是"/app/models",那你的bge-large-zh模型就要放在"/app/models/BAAI"下 -
LLM_MODELS: 启用的大语言模型
默认就有chatglm3-6b,所以不用修改
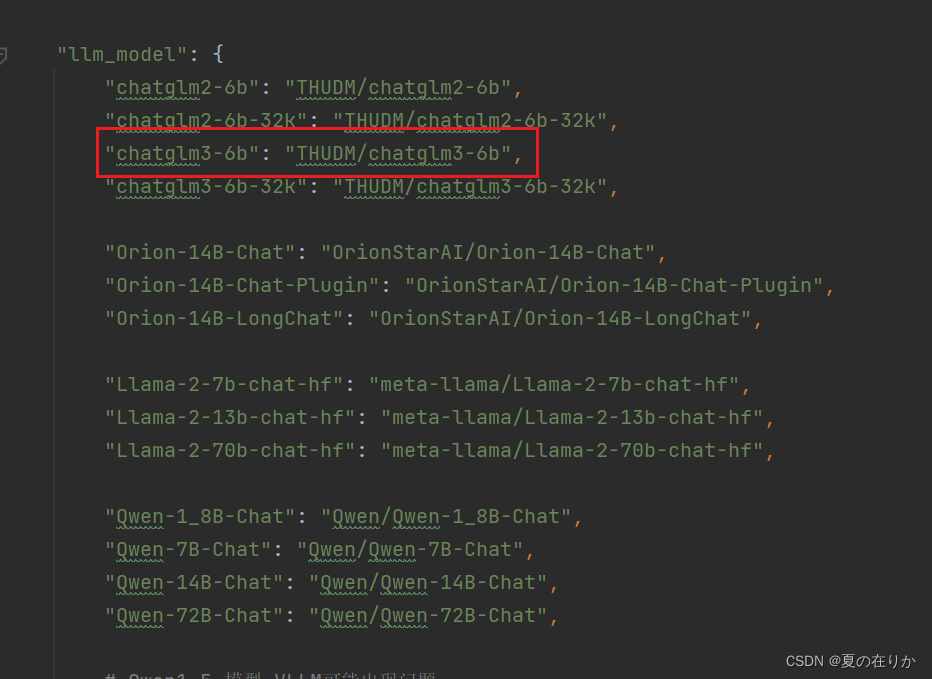
注意:chatglm3-6b存放路径同样需要根据model_path中的要求存放
如果model没有按照这里存放的路径存放的话,是无法启动的
-
-
basic_config.py
这里是配置日志格式和路径 -
kb_config.py
知识库参数配置 -
prompt_config.py
提示词配置- llm_chat: 基础的对话提示词,默认直接是用户输入的内容,没有系统提示词
- knowledge_base_chat: 与知识库对话的提示词,用户输入提示词切换到知识库对话
- agent_chat: 与Agent对话的提示词
-
server_config.py
后端系统配置,包括启动ip, 端口,多显卡配置,gpu/cpu切换等
3.5 windows部署注意
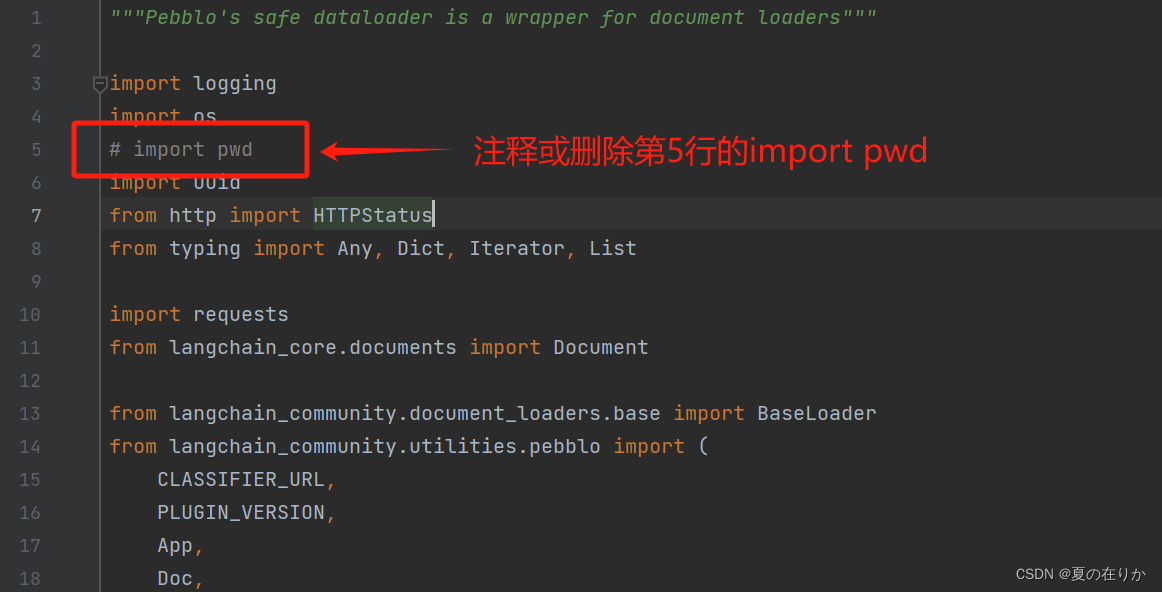
这里只有windows部署的用户需要注意, 这个版本引用的langchain_community版本是有bug的。langchain_community/document_loaders/pebblo.py中在全局引用了pwd模块,这个模块在windows下是没有的,所以windows下启动会报错。
解决方法有两个:
- 升级langchain版本到0.1.8,但是这个可能会因为版本不匹配有其他潜在的错误(不建议)
- 修改site-packages中的源码:
- 路径:
langchain_community\document_loaders\pebblo.py - 修改内容
-
注释或删除第5行的
import pwd
-
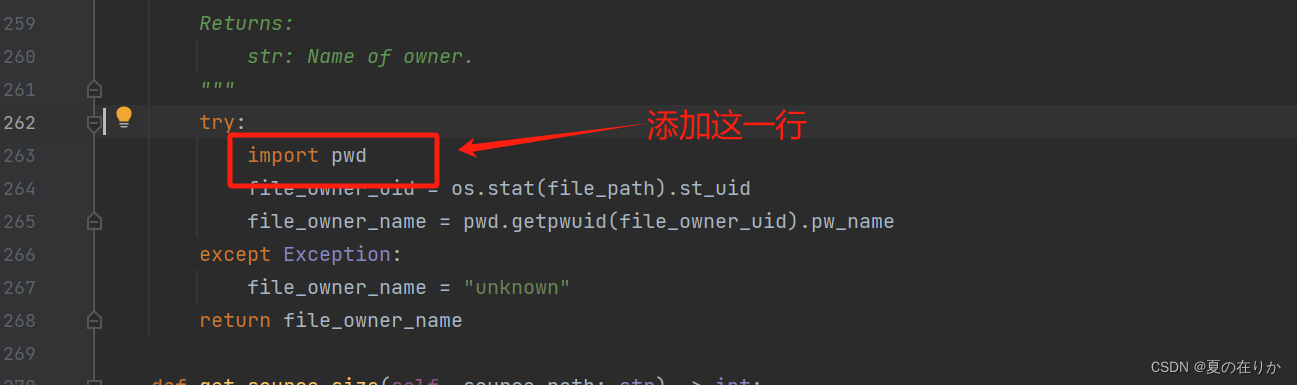
将import pwd放到262行下的try中
-
- 路径:
3.6 快速启动
执行python startup.py -a
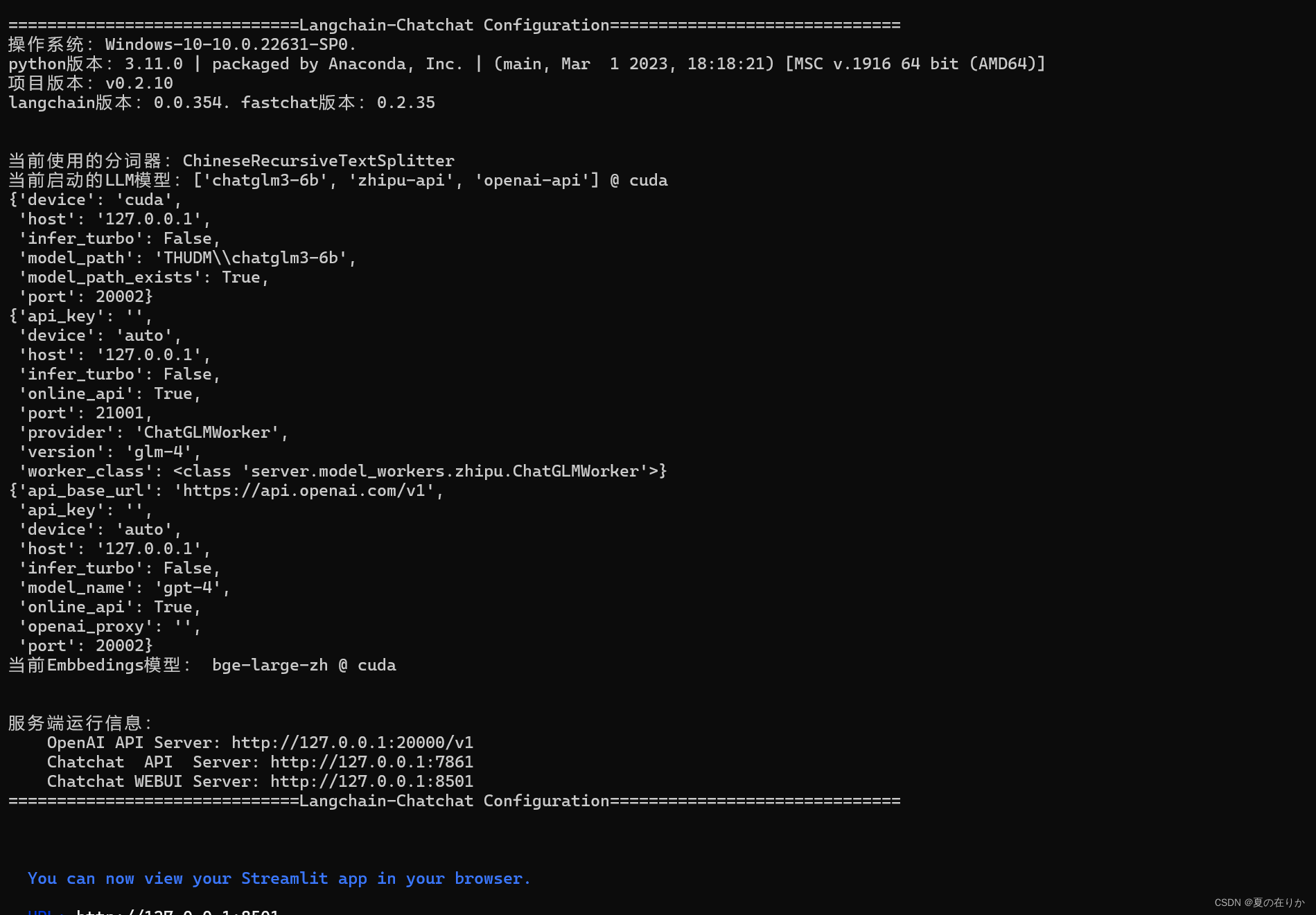
顺利执行完会出现这样界面
webui的端口默认是8501
成功启动后访问如果无法访问webui,请在启动命令行中回车一下然后再次访问webui即可
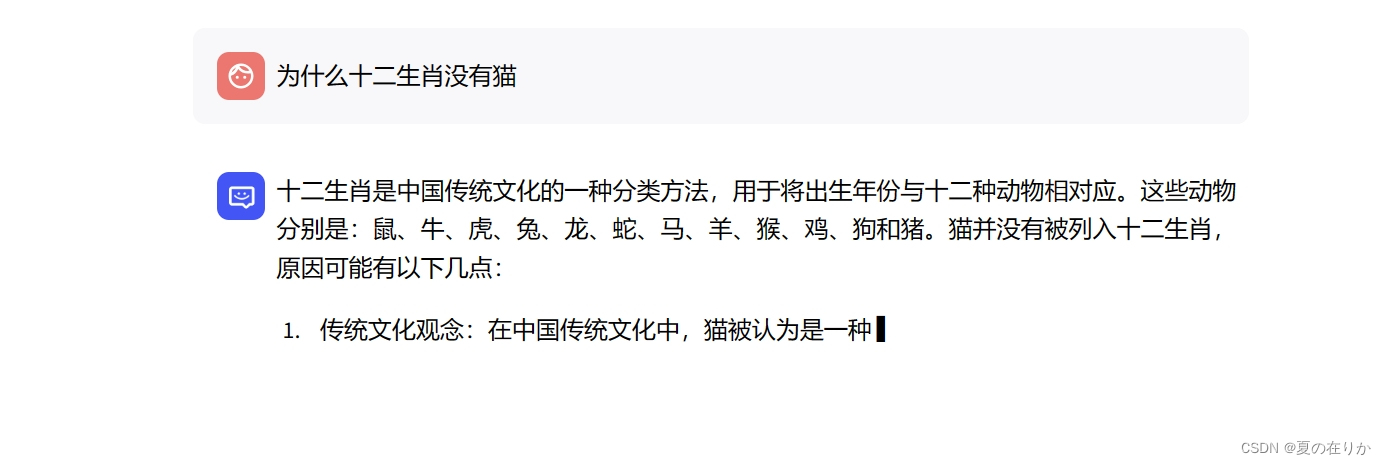
这是webui默认的llm对话界面,用户也可以上传自己的知识库,然后使用知识库对话
比如我传的小说到知识库,得到的结果:
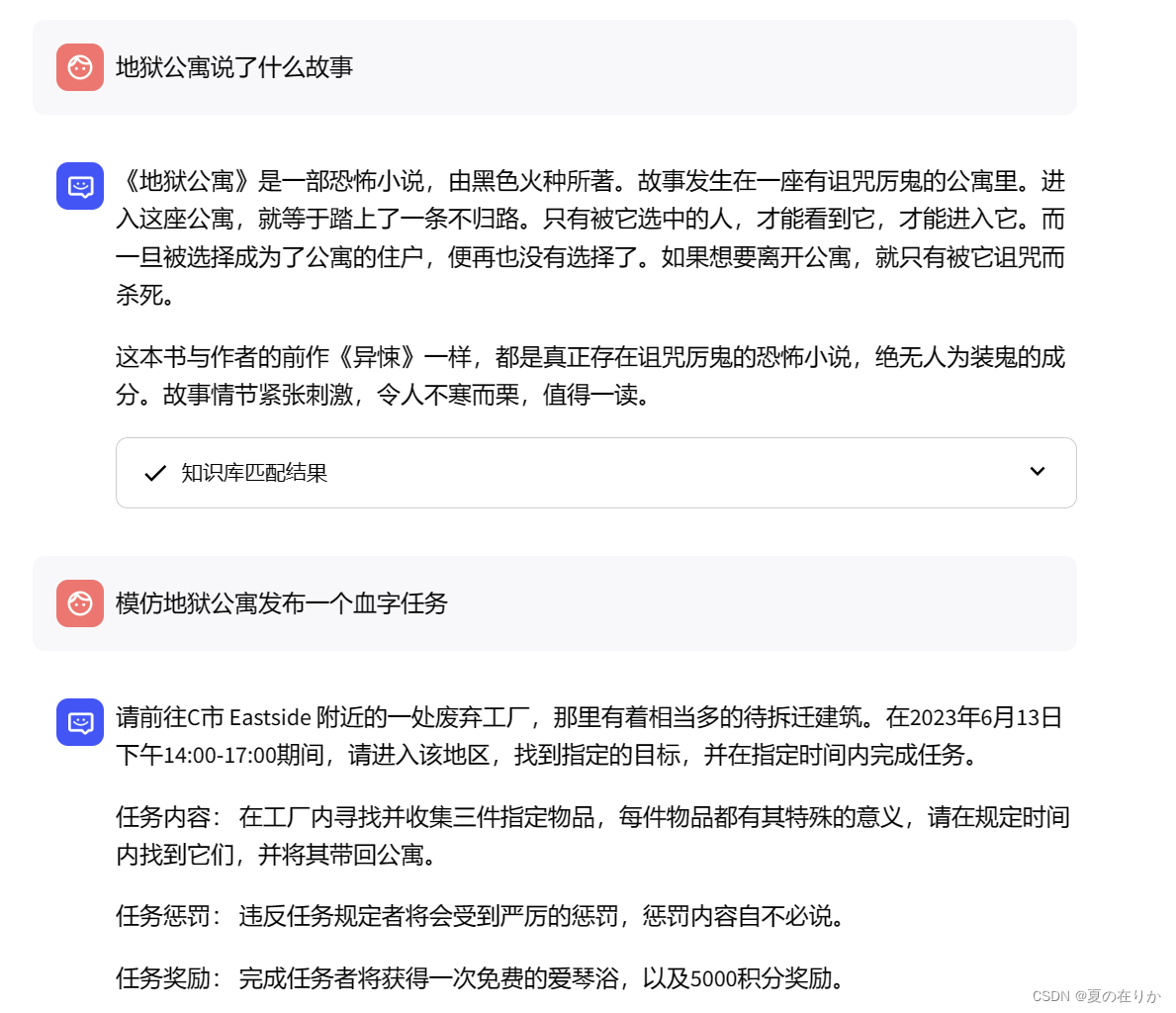
总结
部署过程中几个需要注意的点总结一下:
- 安装完所有依赖后最好查看一下安装的torch版本,如果默认安装的torch版本是cpu的,如果你安装的torch不带gpu,那么需要移除cpu的torch,重新安装gpu版本的
- 注意model_config.py中配置的model路径和你下载的路径是否相同,条件允许的情况下推荐将你下载model文件夹放到配置文件中配置的位置
- 修改model_config.py中EMBEDDING_MODEL,将其修改为自己使用的model名称,model名称和下面的model路径配置保持一致
- 执行python init_database.py --recreate-vs如果报错找不到config.json,可能是下载的bge-large-zh的1_Pooling下的文件名称与代码中不同,重命名为config.json即可
- windows下部署注意,如果出现no module named pwd的问题的话,可以更换修改site-packages\langchain_community\document_loaders\pebblo.py下的代码
- 删除第5行的import pwd
- 将import pwd放到262行下的try中
- 成功启动后访问如果无法访问webui,请在启动命令行中回车一下然后再次访问webui即可
- 修改端口,多个gpu显卡配置,cpu和gpu切换在configs/server_config.py下
如果觉得写的还不错的话麻烦点个赞吧

















 8491
8491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









