






Datawhale干货
作者:张燚钧,单位:中国移动云能力中心
联系方式:yijzhangme@gmail.com
审校:黄元帅
最近,谷歌研究团队提出了 Imagic 模型,其具备基于文本对图像进行编辑的能力,效果堪比 PS。这种融合文本和图像的多模态模型在近几年发展迅猛,DALLE、DALLE-2、Imagen 等多模态模型层出不穷。
如图1所示,目前这些多模态模型生成图像的成像效果已经非常清晰、逼真。一些游戏厂商已经尝试使用文本生成图像技术生成二次元图像,插画师这一职业甚至在未来会被AI部分取代。“扩散模型”(Diffusion model)为这些多模态模型中图像生成能力作出了主要贡献。本文将从最传统的生成模型自动编码机开始,对扩散模型的原理进行梳理,并且参考几个多模态模型探索扩散模型和预训练大模型的融合方法。

▲ 图1 基于扩散模型的文本-图像生成模型效果展示

扩散模型原理
自动编码机(Auto Encoder,AE)是早期较为简单的生成模型,通过一个编码器将输入 编码成隐变量 ,再通过一个解码器将 解码成重构样本 。一般来说,优化目标是最小化 与 之间的误差。通过这个自动编码的过程,可以得到一个输入样本 的特征 ,也就是隐变量。
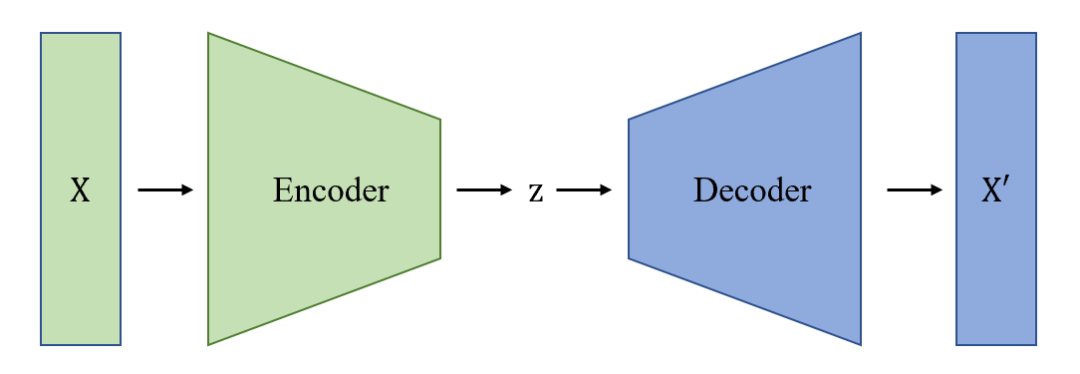
▲ 图2 自动编码机
通过神经网络可以学习到每个输入样本的特征,并根据此特征将输入还原出来。但是,这种固定特征,然后还原的实现方式导致 AE 容易过拟合。当模型遇到没有出现过的新样本时,有时得不到有意义的生成结果。
变分自动编码机(Variational Auto Encoder,VAE)则是在 AE 的基础上,对隐变量 施加限制。使得 符合一个标准正态分布[1]。这样的好处是,当隐变量 是趋向于一个分布时,对隐变量进行采样,其生成的结果可以是类似于输入样本,但是不完全一样的数据。这样避免了 AE 容易过拟合的问题。VAE 通常用于数据生成,一个典型的应用场景就是通过修改隐变量,生成整体与原样本相似,但是局部特征不同的新人脸数据。
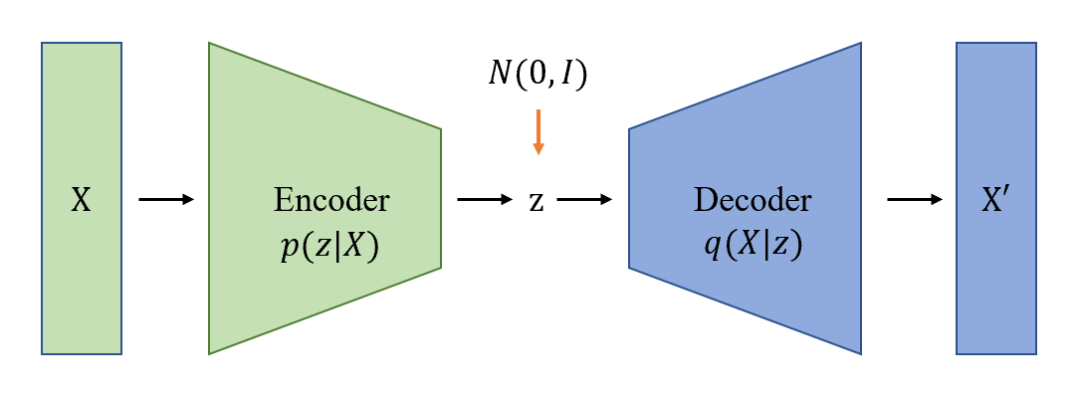
▲ 图3 变分自动编码机
具体来说,是通过变分推断这一数学方法将 和 后验概率设置为标准高斯分布,同时约束生成的样本尽量与输入样本相似。这样通过神经网络可以学习出解码器,也就是 。通过这样的约束训练之后,可以使得隐变量 符合标准高斯分布。当我们需要生成新的样本时,可以通过采样隐变量 让变分自动编码机生成多样同时可用的样本。
整个学习过程中,变分自动编码机都在进行“生成相似度”和“生成多样性”之间的一个 trade off。当隐变量 的高斯分布方差变小趋向为 0 时,模型接近 AE。此时模型的生成样本与输入样本相似度较高,但是模型的样本生成采样范围很小,生成新的可用样本的能力不足。
对抗生成网络(Generative Adversarial Networks,GAN)与 VAE 和 AE 的“编码器-解码器”结构不同。如图4中所示,GAN没有encoder这一模块(图中被阴影遮盖)。GAN 没有 encoder 这一模块。GAN 直接通过生成网络(这里可以理解为 decoder)和一个判别网络(discriminator)的对抗博弈,使得生成网络具有较强的样本生成能力。GAN 可以从随机噪声生成样本,这里可以把随机噪声按照 VAE 中的隐变量理解。
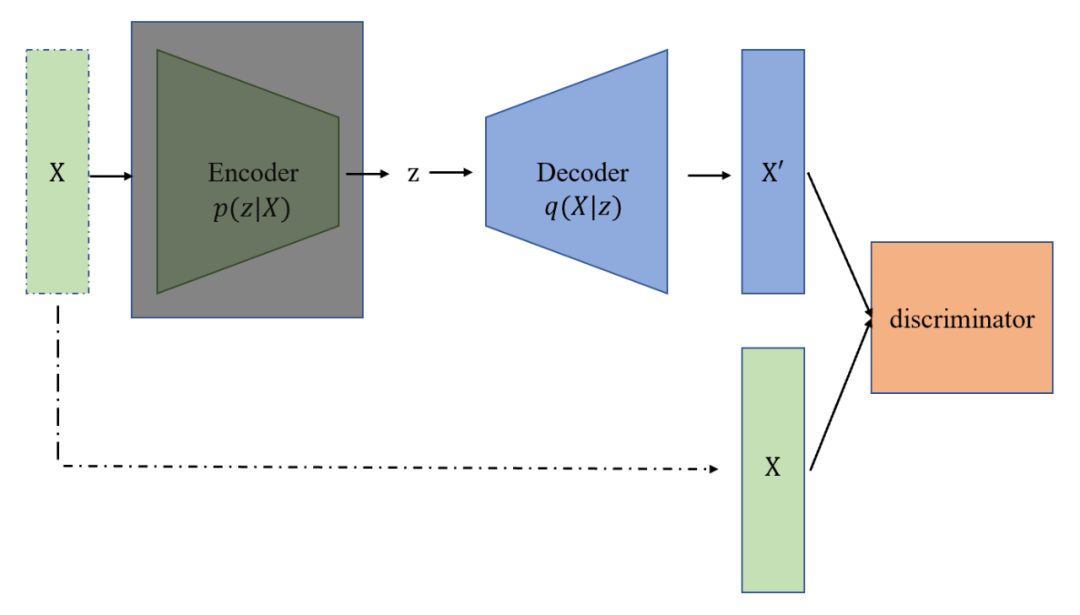
▲ 图4 对抗生成网络
而新出现的扩散模型(Denoising Diffusion Probabilistic Model,DDPM),其实在整体原理上与 VAE 更加接近 [2-7]。 是输入样本,比如是一张原始图片,通过 步前向过程(Forward process)采样变换,最后生成了噪声图像 ,这里可以理解为隐变量 。这个过程是通过马尔科夫链实现的。
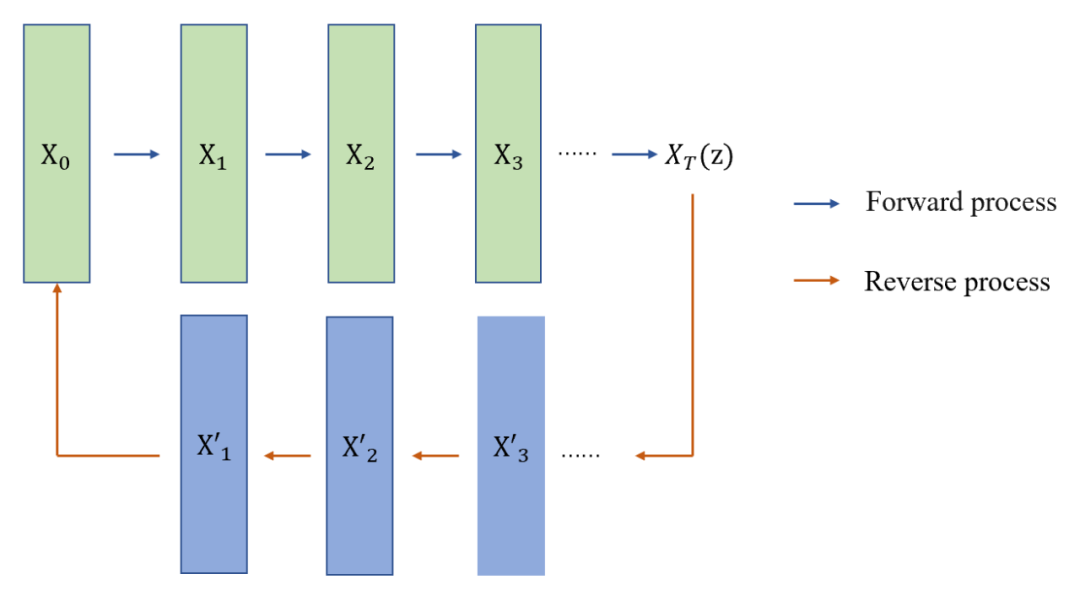
▲ 图5 扩散模型
在随机过程中,有这样一个定理。一个模型的状态转移如果符合马尔科夫链的状态转移矩阵时,当状态转移到一定次数时,模型状态最终收敛于一个平稳分布。这个过程也可以理解为溶质在溶液中溶解的过程,随着溶解过程的进行,溶质(噪声)最终会整体分布到溶液(样本)中。这个过程可以类比理解为 VAE 中的 encoder。而逆向过程(Reverse process)可以理解为 decoder。通过 步来还原到原始样本。
以上几种生成网络,都涉及了大量的数学推导过程。这里为了方便读者理解,只对模型整体结构功能进行解释。

应用:扩散模型与预训练模型结合
下面通过几个目前性能优秀的生成模型的例子,理解一下扩散模型与如何与其他预训练模型结合,实现模型优秀的生成能力的。
DALLE-1 模型
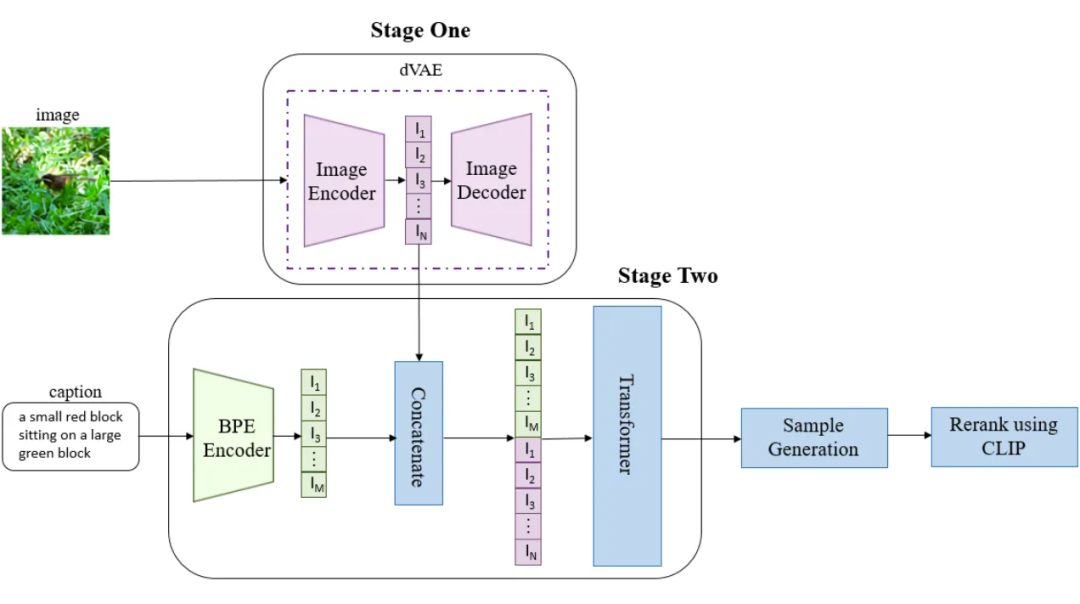
▲ 图6 DALLE-1模型图
DALLE-1[8] 模型结构如图所示,首先图像在第一阶段通过 dVAE(离散变分自动编码机)训练得到图像的 image tokens。文本 caption 通过文本编码器得到 text tokens。Text tokens 和 image tokens 会一起拼接起来用作 Transformer 的训练。这里 Transformer 的作用是将 text tokens 回归到 image tokens。当完成这样的训练之后,实现了从文本特征到图像特征的对应。
在生成阶段,caption 通过编码器得到 text tokens,然后通过 transformer 得到 image tokens,最后 image tokens 再通过第一阶段训练好的 image decoder 部分生成图像。因为图像是通过采样生成,这里还使用了 CLIP 模型对生成的图像进行排序,选择与文本特征相似度最高的图像作为最终的生成对象。
DALLE-2 模型
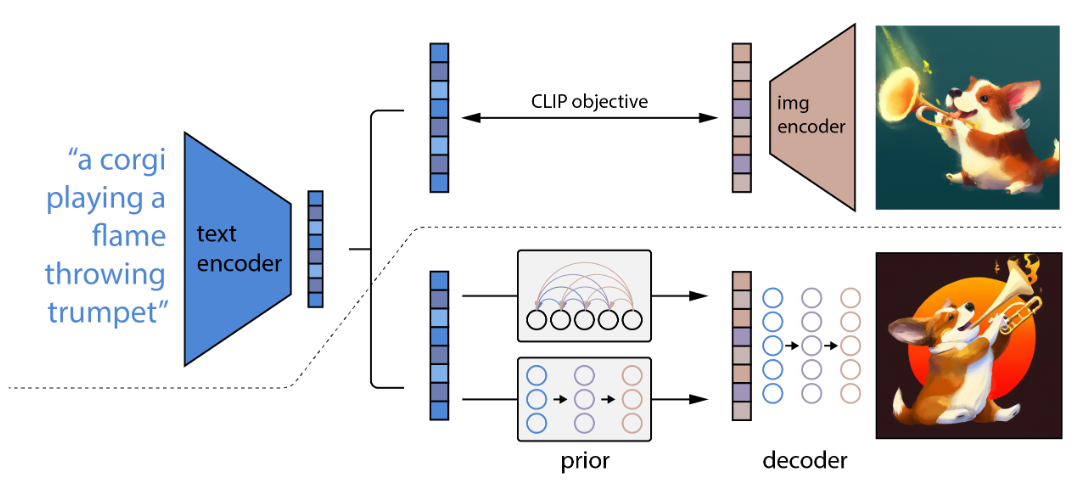
▲ 图7 DALLE-2模型图
DALLE-2[9]模型结构如图 6 所示。其中的 text encoder 和 image encoder 就是用 CLIP 中的相应模块。在训练阶段通过训练 prior 模块,将 text tokens 和 image tokens 对应起来。同时训练 GLIDE 扩散模型,这一步的目的是使得训练后的 GLIDE 模型可以生成保持原始图像特征,而具体内容不同的图像,达到生成图像的多样性。
当生成图像时,模型整体类似在 CLIP 模型中增加了 prior 模块,实现了文本特征到图像特征的对应。然后通过替换 image decoder 为 GLIDE 模型,最终实现了文本到图像的生成。
Imagen
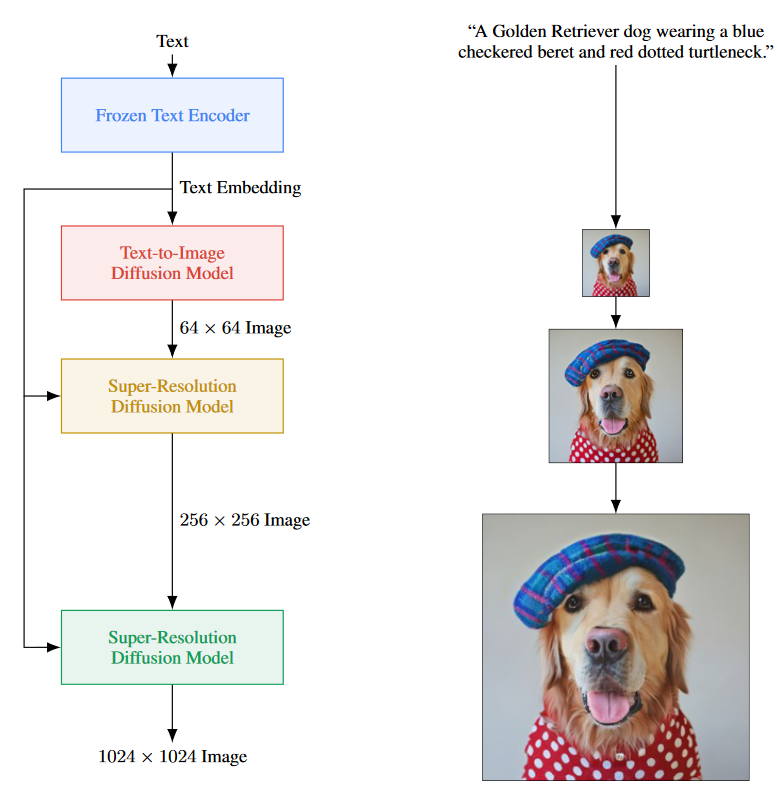
▲ 图8 Imagen模型结构图
Imagen [10] 生成模型还没有公布代码和模型,从论文中的模型结构来看,似乎除了文本编码器之外,是由一个文本-图像扩散模型来实现图像生成和两个超分辨率扩散模型来提升图像质量。
Imagic
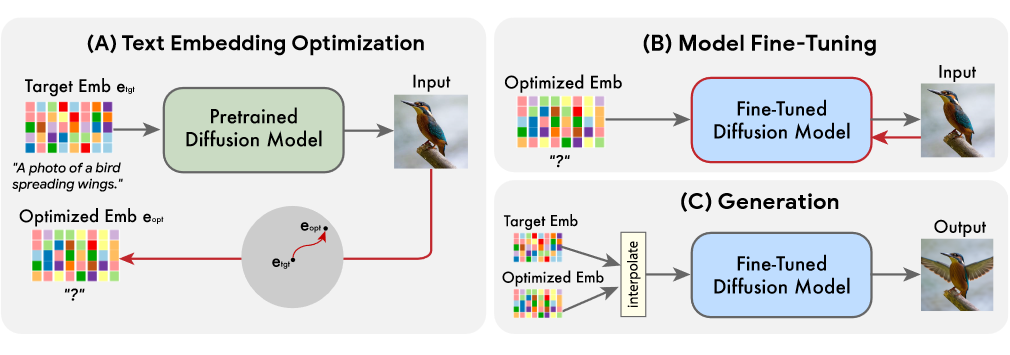
▲ 图9 Imagic原理图
最新的 Imagic 模型 [11]号称可以实现通过文本对图像进行 PS 级别的修改内容生成。目前没有公布模型和代码。从原理图来看,似乎是通过在文本-图像扩散模型的基础上,通过对文本嵌入的改变和优化来实现生成内容的改变。如果把扩散模型替换成简单的 encoder 和 decoder,有点类似于在 VAE 模型上做不同人脸的生成。只不过是扩散模型的生成能力和特征空间要远超过 VAE。
Stable diffusion
Stable diffusion [12]是由 Stability AI 公司开发并且开源的一个生成模型。图 10 是它的结构图。其实理解了扩散模型之后,对 Stable diffusion 模型的理解就非常容易了。
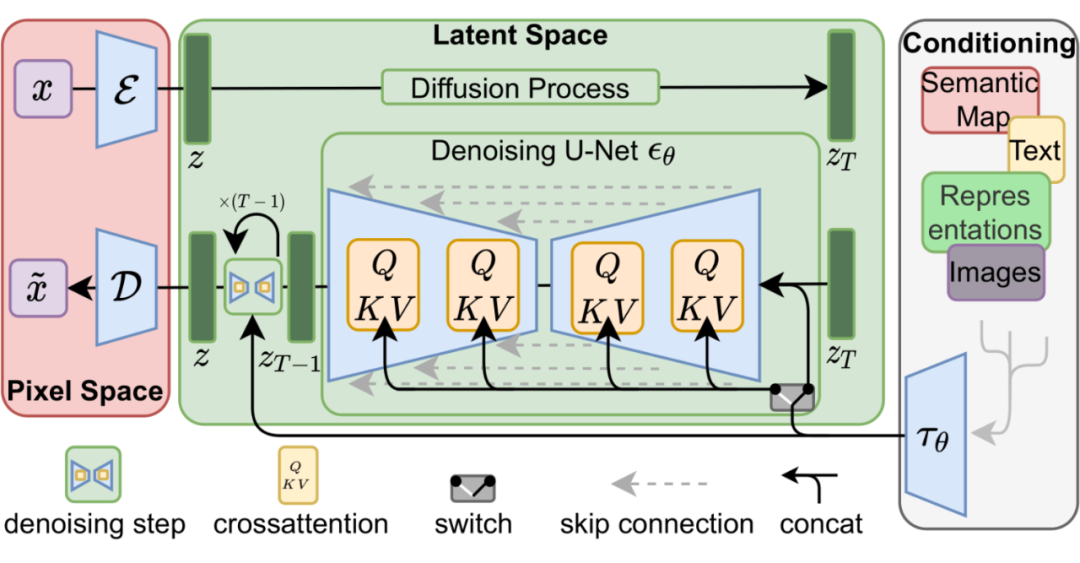
▲ 图10 Stable diffusion结构图
朴素的 DDPM 扩散模型,每一步都在对图像作“加噪”、“去噪”操作。而在 Stable diffusion 模型中,可以理解为是对图像进行编码后的 image tokens 作加噪去噪。而在去噪(生成)的过程中,加入了文本特征信息用来引导图像生成(也就是图中的右边 Conditioning 部分)。这部分的功能也很好理解,跟过去在 VAE 中的条件 VAE 和 GAN 中的条件 GAN 原理是一样的,通过加入辅助信息,生成需要的图像。

总结
如果略去比较复杂的数学推导部分,我们可以发现其实扩散模型以及目前这些基于扩散模型的生成模型,其整体结构的原理并不复杂。扩散模型为我们提供了一个通过大规模训练具备的极其丰富的特征空间、由此获得强大生成能力的模型(如图11所示)。

▲ 图11 随着模型参数量增大,生成图像的质量和语义相似度越来越高
同样受益于近年来大规模预训练NLP模型如BERT,多模态模型如CLIP等,研究人员可以在较为完备的图像特征空间中,将语义特征与图像特征对齐,从而实现多样、定制化的图像生成。目前基于扩散模型的生成模型还存在诸如面部细节、手部细节生成出错(图12),以及对一些文本在具体语境下的理解出错等问题[13]。未来,生成模型更加细粒度的定制化以及自然图像的精细生成仍是这个领域研究者们可以继续攀越的高峰。

▲ 图12 尝试用stable diffusion开源版本生成的图像

参考文献
[1] 苏剑林. 变分自编码器VAE:原来是这么一回事https://zhuanlan.zhihu.com/p/34998569.
[2] HeptaAI. 如何通俗理解扩散模型?https://zhuanlan.zhihu.com/p/563543020.
[3] 苏剑林. 生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼https://zhuanlan.zhihu.com/p/535042237.
[4] YANG L, ZHANG Z, SONG Y, et al. Diffusion Models: A Comprehensive Survey of Methods and Applications[Z]. arXiv, 2022(2022–10–23). DOI:10.48550/arXiv.2209.00796.
[5] ULHAQ A, AKHTAR N, POGREBNA G. Efficient Diffusion Models for Vision: A Survey[J]. arXiv, 2022(2022–10–20). DOI:10.48550/arXiv.2210.09292.
[6] CAO H, TAN C, GAO Z, et al. A Survey on Generative Diffusion Model[J]. arXiv, 2022(2022–10–19). DOI:10.48550/arXiv.2209.02646.
[7] CROITORU F-A, HONDRU V, IONESCU R T, et al. Diffusion Models in Vision: A Survey[J]. arXiv, 2022(2022–10–06). DOI:10.48550/arXiv.2209.04747.
[8] RAMESH A, PAVLOV M, GOH G, et al. Zero-Shot Text-to-Image Generation[J]. arXiv, 2021(2021–02–26). DOI:10.48550/arXiv.2102.12092.
[9] RAMESH A, DHARIWAL P, NICHOL A, et al. Hierarchical Text-Conditional Image Generation with CLIP Latents[J]. arXiv, 2022(2022–04–12). DOI:10.48550/arXiv.2204.06125.
[10] SAHARIA C, CHAN W, SAXENA S, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding[J]. arXiv, 2022(2022–05–23). DOI:10.48550/arXiv.2205.11487.
[11] KAWAR B, ZADA S, LANG O, et al. Imagic: Text-Based Real Image Editing with Diffusion Models[Z]. arXiv, 2022(2022–10–17). DOI:10.48550/arXiv.2210.09276.
[12] ROMBACH R, BLATTMANN A, LORENZ D, et al. High-Resolution Image Synthesis with Latent Diffusion Models[Z]. arXiv, 2022(2022–04–13). DOI:10.48550/arXiv.2112.10752.
[13] 地球人研究报告©. 为什么AI画不了美少女吃面?https://www.huxiu.com/article/696641.html.

整理不易,点赞三连↓















 7509
7509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









