







Datawhale干货
作者:李薇,上海人工智能实验室
前言
今天,我将向那些希望深入了解大模型的同学们,分享一些关于大模型时代的数据变革的知识。作为上海人工智能实验室OpenDataLab的产品主管,我会介绍我们在开放数据和大模型数据方面的工作,希望这些信息能对你们有所帮助。
大模型的发展与研究方向
首先,我简要介绍一下大模型的发展和研究方向。大模型之所以被称为"大",主要是因为它在参数规模上发生了巨大的变革。在大模型领域,一个重要的研究方向是"scaling law",即模型效果与模型的参数量、数据量和计算量之间存在一个平滑的幂律发展规律。

据此规律,随着模型参数量和训练数据量(通过token计算)的指数性增长,以及模型计算量的增加,模型在测试集上的loss会指数性地降低,模型效果就会越好。这个研究也表明,参数规模是模型能力的主要驱动力。在给定的计算量且参数规模较小的情况下,增大模型的参数量对模型的贡献远远高于数据量和训练的步数。这项于2020年由OpenAI进行的研究对后续大模型的训练方向产生了深远影响,包括后来的GPT-3等模型也得到了相应的验证。
随后,更多的研究机构加入到了大模型参数规模的探索中。例如,DeepMind在2022年进行了比OpenAI更加系统性的研究。他们通过定量实验计算出,模型训练的Loss在模型参数量和训练数据量的变化下,存在一个最优的平衡点。与GPT-3等千亿级模型对比,这些模型并没有达到其理论的最优点,可能只达到了百亿级模型的理论效果。
因此,DeepMind推出了Chinchilla模型,其参数规模是Gopher的四分之一,但训练数据量却是Gopher的四倍。在参数规模较小但训练量大的情况下,整个模型的效果优于参数规模大但数据量不足的模型。这也验证了我们应均衡地扩大参数规模和数据量的重要性。
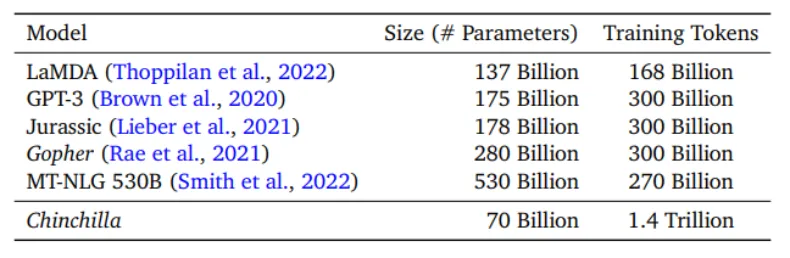 图 Chinchilla、Gopher等语言模型的参数数量,训练数据量 (来源:Deep Mind)
图 Chinchilla、Gopher等语言模型的参数数量,训练数据量 (来源:Deep Mind)
确实,我们可以看到大模型研究的发展趋势是寻求参数规模和数据量的最佳平衡。Meta公司在2023年推出了百亿级别的模型LLaMA,它的训练数据是GPT-3的4.7倍。该模型在各种下游任务上的表现均优于GPT-3。在训练过程中,Meta试验了从70亿到650亿不等的参数量,并发现在训练数据接近或超过万亿toke
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









