







1 - Prioritizing What to Work On 众多的改进方法中该选哪一个?
以 Spam classification 为例来说明问题。
识别垃圾邮件的基本方法:从大量的邮件中选取出最频繁出现的 n 个词语(包括垃圾邮件关键词和非垃圾邮件关键词,n可取10,000 to 50,000)作为关键词。然后对新邮件进行处理,生成 n x 1维向量 X 作为分类器的输入。
降低误差的方法(Brain Storm):
- 收集大量数据(例如:使用honeypot蜜罐诱导垃圾邮件发送者的邮件)
- 根据邮件的routing information(from email header)信息开发算法(有些垃圾邮件的发送地址有一些明显的特征)
- 根据邮件文本特征开发算法:
- ”discount” 和 “discounts”是否应该视为同一个词汇?
- 那么 “deal” 和 “Dealer” 呢?
- 标点符号的特征?(如大量的使用感叹号!)
- 根据邮件中的拼写错误开发特定算法
2 - Error Analysis 误差分析
推荐的途径:
- 从一个简单的易实现的模型上手。实现它并用cross-validation data来测试。
- 画出 learning curves,从而判断是否需要更多数据、更多features等信息。
- Error analysis:
人工检查在交叉验证数据集中出错的数据,看看是否在某类数据上都较大误差,等等。
- discount/discounts/discounted/discounting是否应该被视为同意词语?
使用词干分词软件(如Porter stemmer,应用最为广泛的、中等复杂程度的、基于后缀剥离的词干提取算法)
- Numerical evaluation:从数值上给一个统一的判定标准(如cross validation error)来估计算法的性能。
- discount/discounts/discounted/discounting是否应该被视为同意词语?
3 - Error Metrics for Skewed Classes 倾斜分类问题中的误差衡量方法
例如:Cancer classification问题
训练logistic regression模型 (y=1患癌症,y=0没有癌症)来预测是否患有癌症。
- 如果过你的模型在测试集上有1%的误差(99%的估计是正确的),那么能说这个模型很好吗?
- 事实上只有0.50%的病人患有癌症,而99.5%的病人没有癌症。
- 如果直接估计所有的病人都没有癌症,那么准确率可达99.5%!!!
Precision/Recall准确率与召回率:
(注意通常令哪种出现可能性较小的类别的y=1,比如令患癌的y=1)
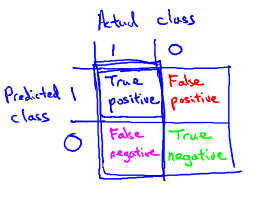
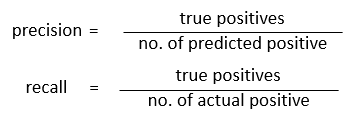
其中:
True/false代表预测正确/错误
positive/negative代表预测患癌症/不患癌症
4 - Trading Off Precision and Recall 准确率与召回率之间的权衡
在Cancer classification问题,你可能会想到要改变cancer与not cancer之间的threshhold:
- Predict 1 if hθ(x) >= 0.5 , 0.7 ,0.9 ,0.3
- Predict 0 if hθ(x) < 0.5,0.7,0.9 ,0.3
这其中的区别在于:
如果你觉得只能在非常确定时才能预测 y =1(患癌症),那么:
- threshhold应该设置的比较高,例如 0.7 或 0.9
- 此时:准确率提高了,但是召回率却比较低
如果过你不想让本来患有癌症的人被错误的估计成没有癌症,那么:
- threshhold应该设置的相对较小,如 0.3 或 0.5
- 此时:准确率较低,但是召回率较高
在多个方案的准确率、召回率之间如何做选择:
F1 Score(F score):
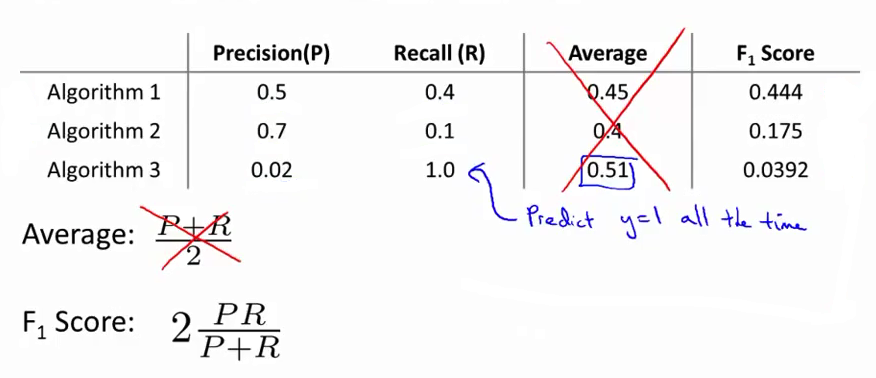
5 - Data For Machine Learning
要点:
- 需要有足够多的feature,保证low bias
- 足够大的training set,得到low variance















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









