







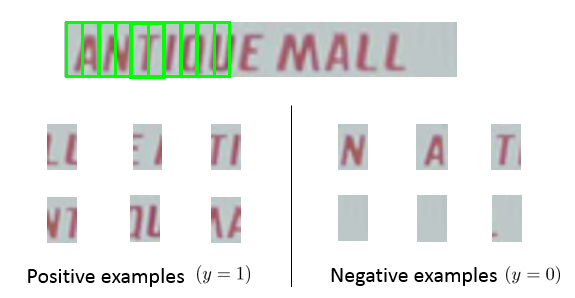
1 - Problem Description and Pipeline 问题描述与系统流水线

2 - Sliding Windows 滑动窗口检测
在 Text detection 和 Character segmentation 中需要用到滑动窗口。
Text detection 步骤:
- 首先用已有数据训练模型(如Neural network等) ,用于识别出图片内容是否为文本。

- 用不同大小的窗口分别对整幅图片进行滑动窗口扫描,识别出所有的文本区域

Character segmentation 步骤:
- 用已有数据训练模型,用于识别字母之间的分隔线:
- 用滑动窗口扫描已经识别出来的文本区域,找到其中的分割线。
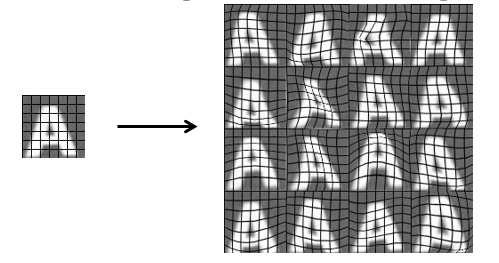
3 - Getting Lots of Data and Artificial Data 如何获取大量的数据、人工制造数据
示例:如何构造字母识别的数据

人工合成数据:利用已有字库,加上不同的背景即可构造大量数据。

引入扭曲/失真(distortion)来合成数据:
声音的人工合成:加入不同的背景声音。
关于人工合成数据的注意事项:
- Distortion introduced should be representation of the type of noise/distortions in the test set.(加入的混淆应该是真实存在有意义的)
- Usually does not help to add purely random/meaningless noise to your data.(如对图像的每一个点加入混淆)
关于获取大量数据的思考:
- 在尝试人工制造大量数据之前应该保证模型是 low bias 的(绘制 learning curve)
- 获取 10 倍于当前数据的成本如何?可选方法:
- Artificial data synthesis 人工数据合成
- Collect/label it yourself 自己收集
- “Crowd source” (E.g. Amazon Mechanical Turk) 众包方式
4 - Ceiling Analysis What Part of the Pipeline to Work on Next 关于系统优化的天花板分析
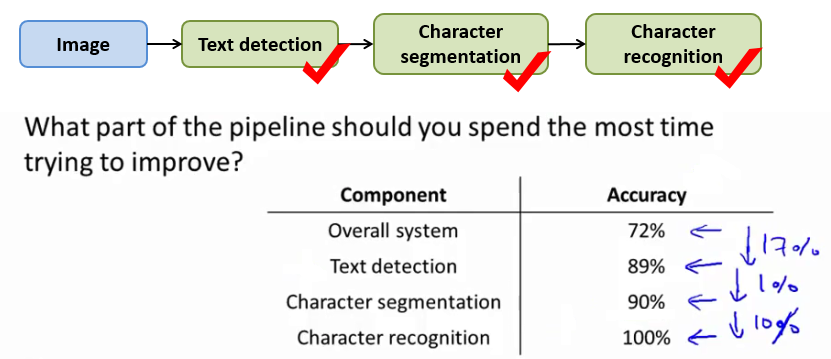
表中列举了改进系统各个部分至最优的情况下,能对系统的政体效率提高的程度,可见改进 Text detection 能对系统的改进有较大帮助改善,而改善 character segmentation 却没有太大必要,改进 Character recognition 也能起到较大提升作用。















 83
83

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









