







1 - Unsupervised Learning Introduction 无监督学习
数据事先没有标记分类。
应用:
- Market segmentation 市场分割
- Social network analysis 社交网络分析
- Organize computing clusters 计算集群组织
- Astronomical data analysis 天文数据分析
2 - K-Means Algorithm
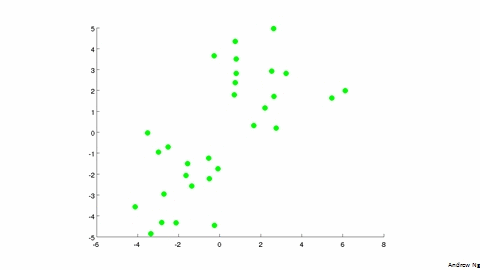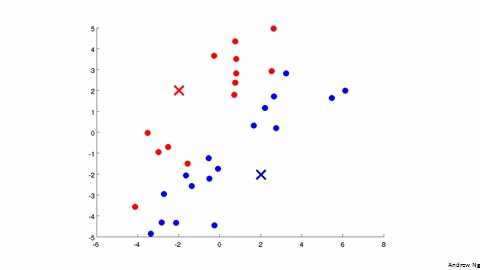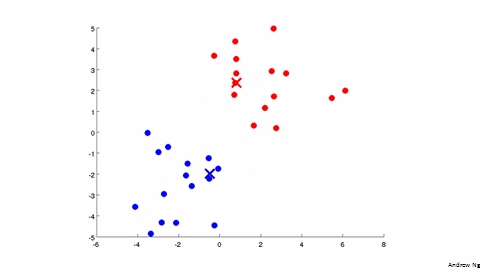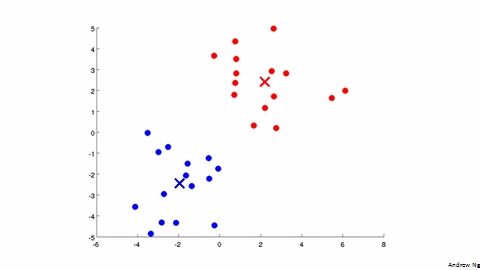
输入:
- 簇数目:K
- 训练数据集: {x(1),x(2),…,x(m)},x(i)∈Rn(注意不再考虑x0=1)
算法步骤:
- 随机的选择 K 个 cluster centroids
μ1,μ2,…,μK∈Rn
Repeat{fori=1tomc(i):=indexofcentroidclosesttox(i)fork=1toKμk:=averageofpointsassignedtoclusterk}
3 - Optimization Objective 优化目标
约定的符号:
- c(i) :训练数据 x(i) 当前所属的簇的编号
- μk :第 k 个簇的中心点
- μc(i) :数据 x(i) 所在簇的中心点
Optimiation Objective:
minJ(c(1),…,c(m),μ1,…,μK)=1m∑i=1m∥x(i)−μc(i)∥2
4 - Random Initialization 中心点的随机初始化
条件:
- 簇数量 K 应该小于样本数 m:K < m
选取方法:
- 从训练集中随机选取 K 个点作为 cluster centroid
- 为了避免陷入 Local optima,应该重复选取多次,最后取 J 最小的情况
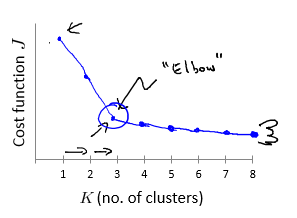
5 - Choosing the Number of Clusters 聚类数目 K 的选择
Elbow method:
Evaluate K-means based on a metric for how well it performs for that later purpose.
例如 T-shirt 尺码的选择















 8948
8948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









