







Hierarchical Clustering,一如其字面意思,是层次化的聚类,得出来的是树形结构(计算机科学的树是一棵根在最上的树,:-D)。
Hierarchical vs Flat Clustering
平坦型聚类算法的一个共同点,也是缺陷,就是类别数目难以确定。层次聚类从某种意义上说解决了这个问题,不是它能给出类别数目,而是它在 Clustering 的时候不需要知道类别数。其得到的结果是一棵树,聚类完成之后,可在任意层次横切一刀,得到指定数目的 cluster。
agglomerative vs divisive
- agglomerative:自底向上
- divisive:自顶向下
先说,自底向上,一开始,每个数据点各自为一个类别,然后每一次迭代选取距离最近的两个类别,把它们合并,最后只剩一个类别(根节点)为止,至此一棵树形结构由此确立。
这牵涉到两个问题:
- (1)如何计算两个点的距离?这个通常是 problem dependent 的,一般情况下可以直接用一些比较通用的距离就可以了,比如欧氏距离等。
(2)如何计算两个类别之间的距离?一开始所有的类别都是一个点,计算距离只是计算两个点之间的距离,但是经过后续合并之后,一个类别里就不止一个点了,那距离又要怎样算呢?到这里又有三个变种:
- Single Linkage:又叫做 nearest-neighbor ,就是取两个集合中距离最近的两个点的距离作为这两个集合的距离,容易造成一种叫做 Chaining 的效果,两个 cluster 明明从“大局”上离得比较远,但是由于其中个别的点距离比较近就被合并了,并且这样合并之后 Chaining 效应会进一步扩大,最后会得到比较松散的 cluster 。
- Complete Linkage:这个则完全是 Single Linkage 的反面极端,取两个集合中距离最远的两个点的距离作为两个集合的距离。其效果也是刚好相反的,限制非常大,两个 cluster 即使已经很接近了,但是只要有不配合的点存在,就顽固到底,老死不相合并,也是不太好的办法。
- Group Average:这种方法看起来相对有道理一些,也就是把两个集合中的点两两的距离全部放在一起求一个平均值,相对也能得到合适一点的结果。
总的来说,一般都不太用 Single Linkage 或者 Complete Linkage 这两种过于极端的方法。整个 agglomerative hierarchical clustering 的算法就是这个样子,描述起来还是相当简单的,不过计算起来复杂度还是比较高的,要找出距离最近的两个点,需要一个双重循环,而且 Group Average 计算距离的时候也是一个双重循环。
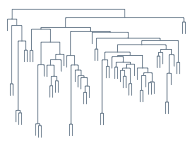
Dendrogram
本文一开始介绍的那个树状结构图,它有一个专门的名称,叫做 Dendrogram,维基百科对它的介绍为:
A dendrogram (from Greek dendro “tree” and gramma “drawing”) is a tree diagram frequently used to illustrate the arrangement of the clusters produced by hierarchical clustering. Dendrograms are often used in computational biology to illustrate the clustering of genes or samples.


















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











